离线商品推荐系统(Hive)
2019-09-10 11:47
260 查看
1.前言
之前写的离线商品推荐系统,最后的结果是存储到HDFS中,接下来就是要把HDFS中的数据存储到数据仓库Hive中
2.下载Hive可视化工具
这里推荐的是dbeaver
官网下载地址:https://dbeaver.io/download/
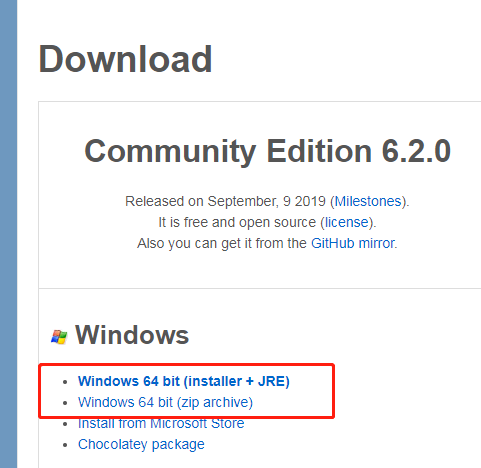
这两个选一个下载即可,第二个是免安装版
2.启动Hive
-
启动zookeeper,命令:zkServer.sh start
- 启动hadoop,命令:start-dfs.sh,start-yarn.sh(这个命令在resourcemanager节点运行)
- 启动hive远程连接,命令:hive --service hiveserver2 &
- 检查是否在hadoop的core-site.xml中配置了代理用户(如下所示)
<!-- root组可以代理其他所有用户(第一个表示),而且是在所有的hosts上都可以代理(第二个表示)--> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property>
3.dbeaver配置连接
- 数据库--新建连接---选择hive
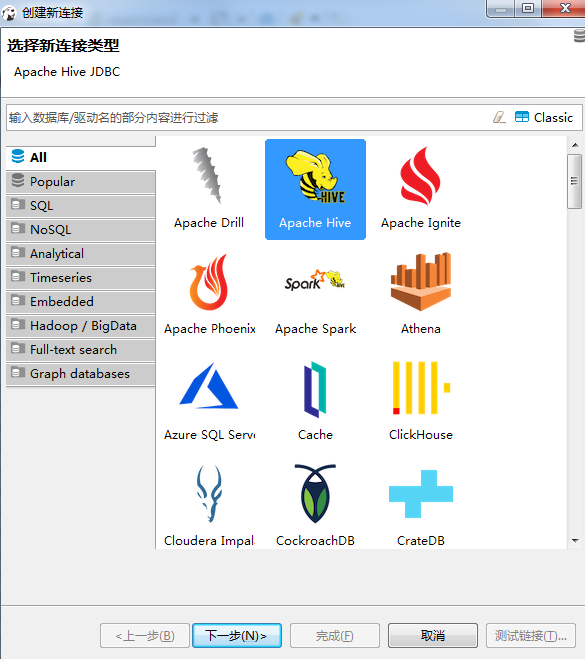
- 配置jdbc连接
- 主机可以直接写ip地址,如果已经配置了host名称,也可写名称
- 数据库就是填写你所要连接的数据库
- 用户名和密码就是在hive-site.xml中配置的账号密码
- 填写完后,选择编辑驱动设置
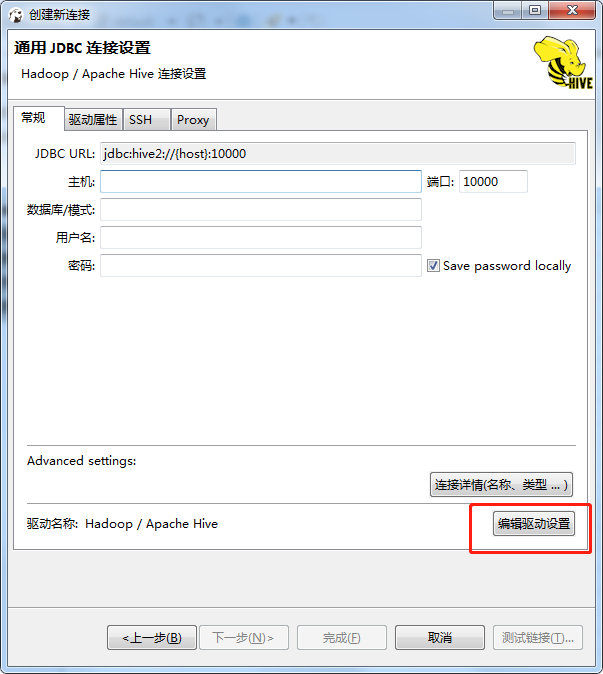
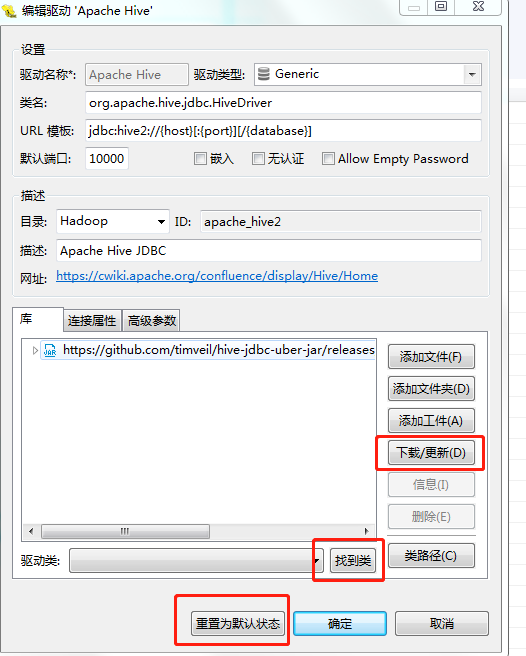
- 先点下载更新,安装驱动
- 然后选择找到类
- 如果不小心误删除库,可以恢复默认状态
- 点击测试连接,连接成功
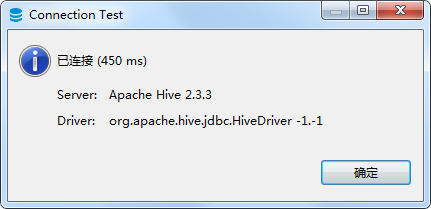
- 接下来可以在左侧看到已经连接到了数据库
- 然后打开sql编辑器,可以在这里面输入sql语句
- 稍微解释下这个sql语句,这个语句的意思是
- 创建一个外部表,表名是test,表里有两个字段,分别是string类型的 id 和string类型的 result
- 从HDFS上的这个路径/test/recommend/output/result_sort/中关联数据;
- 按照\t的规则进行分割
create external table test(id string, `result` string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' location '/test/recommend/output/result_sort/';
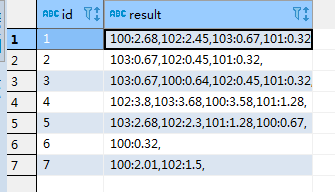
- 打开表,发现确实是跟HDFS上的数据一样
4.一些其他说明
- 创建一个外部表,如果删除表,只会删除matestore中的元数据,而HDFS上的数据还存在
- 如果删除HDFS上的数据,那么表中的数据就不会存在
- 由于离线商品推荐系统中的mapreduce部分是一天已执行,执行后前一天的HDFS中的数据会被覆盖
- 而外部表关联了HDFS上的数据,因此也会更新
- 关联的地址在表创建的时候就已经说明 即 /test/recommend/output/result_sort/
- 如果往这个目录下上传新的文件,这个表也会读取这个文件的内容

相关文章推荐
- 第1章:阿里云机器学习实践之路 / 第3节:推荐系统--基于协同过滤的商品推荐
- Flume+Hadoop+Hive的离线分析系统基本架构
- 京东商品推荐系统
- 实战:Hive在内容推荐系统中的应用(一)
- 推荐系统之UserCF2:用户对商品的感兴趣程度
- 商品用户推荐系统的研究
- 大数据推荐系统实时架构和离线架构
- 商品推荐系统的类型与原理
- 个性化推荐系统(九)--- 电商商品个性化推荐系统
- OpenVAS开源漏扫系统离线实施搭建 推荐
- Flume+Hadoop+Hive的离线分析系统基本架构
- Flume+Hadoop+Hive的离线分析系统基本架构
- 大数据推荐系统实时架构和离线架构
- 推荐系统遇上深度学习(四十六)-阿里电商推荐中亿级商品的embedding策略
- 【HiveETL】电商零售行业实例—推荐系统、用户细分
- [Manacher 线段树 离线] 2015 计蒜之道 初赛 第三场 商品推荐走马灯
- 商品搜索引擎---推荐系统设计
- 推荐系统 - 2 - 离线指标和其他指标
- 推荐系统---深度学习在电商商品推荐当中的应用
- 推荐系统-利用用户行为数据判断用户间或商品间相似性、分类和个性化推荐