ElasticSearch 入门第二章
2019-06-21 18:18
465 查看

-
elasticsearch 是面向文档的
面向文档
在应用程序中对象很少只是一个简单的键和值的列表。通常,它们拥有更复杂的数据结构,可能包括日期、地理信息、其他对象或者数组等。
也许有一天你想把这些对象存储在数据库中。使用关系型数据库的行和列存储,这相当于是把一个表现力丰富的对象挤压到一个非常大的电子表格中:你必须将这个对象扁平化来适应表结构--通常一个字段>对应一列--而且又不得不在每次查询时重新构造对象。
Elasticsearch 是 面向文档 的,意味着它存储整个对象或 文档_。Elasticsearch 不仅存储文档,而且 _索引 每个文档的内容使之可以被检索。在 Elasticsearch 中,你 对文档进行索引、检索、排序和过滤--而不是对行列数据。这是一种完全不同的思考数据的方式,也是 Elasticsearch 能支持复杂全文检索的原因。
JSON编辑
Elasticsearch 使用 JavaScript Object Notation 或者 JSON 作为文档的序列化格式。JSON 序列化被大多数编程语言所支持,并且已经成为 NoSQL 领域的标准格式。 它简单、简洁、易于阅读。
-
通过kibana 进行操作
请参考 https://www.elastic.co/guide/cn/elasticsearch/guide/current/_indexing_employee_documents.html 中的操作 将 HTTP 命令由 PUT 改为 GET 可以用来检索文档,同样的,可以使用 DELETE 命令来删除文档,以及使用 HEAD 指令来检查文档是否存在。如果想更新已存在的文档,只需再次 PUT
-
常用的操作
GET _search { "query": { "match_all": {} } } GET /_count?pretty { "query": { "match_all": {} } } #添加数据 PUT /megacorp/employee/1 { "first_name" : "John", "last_name" : "Smith", "age" : 25, "about" : "I love to go rock climbing", "interests": [ "sports", "musicxx" ] } GET /megacorp/_doc/1 GET /megacorp/_search PUT /megacorp/_doc/1 { "first_name" : "John", "last_name" : "Smith", "age" : 25, "about" : "I love to go rock climbing and swimming", "interests": [ "sports", "music" ], "homw":"shanghai" } PUT /megacorp/employee/1 { "first_name" : "John", "last_name" : "Smith", "age" : 25, "about" : "I love to go rock climbing and swimming", "interests": [ "sports", "music" ], "homw":"shanghai" } PUT /megacorp/employee/2 { "first_name" : "Jane", "last_name" : "Smith", "age" : 32, "about" : "I like to collect rock albums", "interests": [ "music" ] } PUT /megacorp/employee/3 { "first_name" : "Douglas", "last_name" : "Fir", "age" : 35, "about": "I like to build cabinets", "interests": [ "forestry" ] } PUT /megacorp/employee/4 { "first_name" : "wendeng", "last_name" : "xing", "age" : 18, "about": "I like to play basketball", "interests": [ "musics" ], "hometomn":"anhui province" } # 局部更新 POST 方式 + _update 标示 POST /megacorp/_doc/4/_update { "doc": { "tags":["testing"], "views":0, "title":"ok" } } GET /megacorp/_doc/4 # 脚本更新 POST /megacorp/_doc/4/_update { "script" : "ctx._source.tags+=new_tag", "params" : { "new_tag" : "search" } } # upsert 初始化值 POST /megacorp/_doc/4/_update { "script" : "ctx._source.views+=1", "upsert": { "views": 1 } } # retry_on_conflict 遇到冲突重试 POST /megacorp/_doc/100/_update?retry_on_conflict=3 { "script" : "ctx._source.views+=1", "upsert": { "views": 0 } } #mget 批量多文档检索 POST /_mget { "docs" : [ { "_index" : "website", "_type" : "blog", "_id" : 2 }, { "_index" : "website", "_type" : "pageviews", "_id" : 1, "_source": "views" } ] } POST /megacorp/_doc/_mget { "ids":[123] } POST /megacorp/_doc/_mget { "ids":[1,2,3,212] } POST /_bulk { "delete": { "_index": "website", "_type": "blog", "_id": "123" }} { "create": { "_index": "website", "_type": "blog", "_id": "123" }} { "title": "My first blog post" } { "index": { "_index": "website", "_type": "blog" }} { "title": "My second blog post" } { "update": { "_index": "website", "_type": "blog", "_id": "123", "retry_on_conflict" : 3} } { "doc" : {"title" : "My updated blog post"} } GET /_search #分页查询. from 表示下标 ,size 表示数量 GET /_search?size=2 GET /_search?size=2&from=2 GET /_search?size=2&from=4 #获取所有数据 _search GET /megacorp/employee/_search #删除 ID=2的数据 DELETE /megacorp/employee/200 #判断ID=2的数据是否存在 HEAD /megacorp/employee/2 #过滤查询_search?q=XX, last_name 条件 GET /megacorp/employee/_search?q=last_name:Smith #过滤查询_search?q=XX, interests 条件 GET /megacorp/employee/_search?q=interests:music #过滤查询包装形式 GET /megacorp/employee/_search { "query":{ "match": { "interests": "music" } } } #过滤查询 #单个匹配 match GET /megacorp/employee/_search { "query": { "match": { "interests": "music" } } } #短语匹配 match_phrase GET /megacorp/employee/_search { "query": { "match_phrase": { "about": "rock albums" } }, "highlight": { "fields" : { "about" : {} } } } #过滤查询带有范围的 GET /megacorp/employee/_search { "query" : { "bool": { "must": { "match" : { "last_name" : "smith" } }, "filter": { "range" : { "age" : { "gte": 10, "lte": 30 } } } } } } #全文搜索,查询结果是相关性的 GET /megacorp/employee/_search { "query" : { "match" : { "about" : "rock albums" } } } #短语搜索,通过 match_phrase GET /megacorp/employee/_search { "query": { "match_phrase": { "about": "rock albums" } } } #查询结果高亮显示 highlight,排序 order GET megacorp/employee/_search { "query": { "match_phrase": { "about": "rock" } }, "highlight": { "fields": { "about":{ "fragment_size": 20, "number_of_fragments": 5 } }, "order": "score" } } #映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型(string, number, booleans, date等)。 #分析(analysis)机制用于进行全文文本(Full Text)的分词,以建立供搜索用的反向索引。 #分析 GET /megacorp/employee/_search { "aggs" : { "avg_age" : { "avg" : { "field" : "age" } } } } GET /megacorp/employee/_search { "aggs": { "terms": { "field": "interests" } } } POST /tt/gb/ { "tweet": "Elasticsearch is very flexible", "user": { "id": "@johnsmith", "gender": "male", "age": 26, "name": { "full": "John Smith", "first": "John", "last": "Smith" } } } GET /tt/gb/_search { "from": 0, "size": 10 } GET /index_2014*/type1,type2/_search {} #集群健康 GET /_cluster/health GET /_cluster/state PUT /blogs { "settings": { "number_of_shards": 13, "number_of_replicas" : 2 } } PUT /blogs/_settings { "number_of_replicas" : 2 } PUT /xing { "settings": { "number_of_shards": 3, "number_of_replicas":2 } } GET /xing POST /megacorp/schools PUT /movies/movie/1 { "title": "The Godfather", "director": "Francis Ford Coppola", "year": 1972, "genres": ["Crime", "Drama"] } PUT /movies/_doc/1 { "title": "The Godfather", "director": "Francis Ford Coppola", "year": 1972, "genres": ["Crime", "Drama2"] } PUT /movies/_doc/10 { "title": "The Godfather10", "director": "Francis Ford Coppola", "year": 1990, "genres": ["Crime10", "Drama2"] } GET movies/_search GET /movies/movie/_search { "query": { "match": { "title": "lover" } } } PUT /movies/movie/2 { "title":"my lover", "desc":"This is very good", "time":"1999" } GET /movies/movie/2 GET /movies/movie/_search { "query": { "query_string": { "default_field": "desc", "query": "1999" } } } PUT company/_doc/1 { "title":"lieni", "address":"shanghaixuhui", "number":101 } PUT company/_doc/2 { "title":"dipont", "address":"shanghaihongkou", "number":200, "tele":"123456" } PUT company/_doc/6 { "title":"qingke", "address":"shanghaixuhui", "number":300, "tele":"12321", "people":1000 } POST company/_doc/ { "title":"qiniu", "address":"shanghaixuhui", "number":800, "tele":"123521", "people":6000 } GET company/_doc/1?_source=title,address GET company/_doc/1?_source GET company/_doc/1/_source GET company/_search # 判断是否存在 HEAD HEAD company/_doc/1 PUT /schools GET /schools DELETE /schools PUT /schools/_bulk { "index":{ "_index":"schools", "_type":"school", "_id":"1" } } PUT /schools/_bulk { "index":{ "_index":"schools", "_type":"school", "_id":"1" } } POST /xing,wen,deng/_search POST /_all/_search POST /index1,index2,index3/_search GET _cat/nodes?v GET _cat/shards POST users/_doc { "user":"Mike", "post_data":"2019-07-01", "message":"trying out Kibana" } PUT users/_doc/crhBrWsBPyIZBrqJA4UR?op_type=create { "user":"Tom", "post_data":"2019-07-02", "message":"trying out Kibana2" } #查询 GET users/_doc/crhBrWsBPyIZBrqJA4UR #更新并覆盖 PUT users/_doc/crhBrWsBPyIZBrqJA4UR { "user":"jack" } #批量操作 POST _bulk {"index":{"_index":"test","_id":"1"}} { "field1":"value1"} {"delete":{"_index":"test","_id":"2"}} {"create":{"_index":"test2","_id":"3"}} {"field":"value3"} {"update":{"_id":"1","_index":"test"}} {"doc":{"field2":"value2"}} GET _mget { "docs":[ {"_index":"test","_id":"1"}, {"_index":"test2","_id":"3"} ] } #分词 GET _analyze { "analyzer": "standard", "text": "2 running Qucik brown-foxes leap over lazy dogs in the summer evening." } #语言分词 GET _analyze { "analyzer": "english", "text": "2 running Qucik brown-foxes leap over lazy dogs in the summer evening." } POST _analyze { "analyzer": "standard", "text":"她说的确实在理" } POST _analyze { "analyzer": "english", "text":"她说的确实在理" } POST _analyze { "analyzer": "icu_analyzer", "text":"她说的确实在理" } POST _analyze { "analyzer": "ik_smart", "text":"她说的确实在理" } POST _analyze { "analyzer": "ik_max_word", "text":"她说的确实在理" } #添加数据 POST customer/_doc/1?pretty { "city": "北京", "useragent": "Mobile Safari", "sys_version": "Linux armv8l", "province": "北京", "event_id": "", "log_time": 1559191912, "session": "343730" } GET customer/_doc/1?pretty POST customer/_doc/_search?typed_keys=true&ignore_unavailable=false&expand_wildcards=open&allow_no_indices=true&search_type=query_then_fetch&batched_reduce_size=512 GET /_count?pretty { "query": { "match_all": {} } } #结构化查询 GET /_search { "query": { "match_all": {} } } #过滤查询 GET /megacorp/employee/_search { "post_filter": { "range":{ "age":{ "gte":20, "lt":30 } } } } #排序 GET /megacorp/employee/_search { "post_filter": { "exists": { "field": "age" } }, "sort": [ { "age": { "order": "asc" } }, { "_id": { "order": "asc" } } ] } GET megacorp/employee/_search?sort=date:desc&sort=_score&q=search GET posts/product/1 GET demo-2019.07.19/demo/5 GET cc_problem/_doc/1 GET cc/_mapping GET cc/_settings DELETE cc #所有 GET cc/_search { "query": { "match_all": {} } } GET cc/_search { "query": { "match": { "knowledgePoint": "5" } } } #排序 GET cc/_search { "query": { "match": { "code": "AMC8" } }, "sort": [ { "createTime": { "order": "asc" } } ] } #分页 GET cc/_search { "query": { "match_all": {} }, "sort": [ { "createTime": { "order": "desc" } } ], "from": 0, "size": 2 } GET cc/_search { "sort": { "_script": { "script": "Math.random()", "type": "number", "order": "asc" } } } #指定结果字段 GET cc/_search { "query": { "match_all": {} }, "_source": ["id","code","knowledgePoint"] } #过滤查询 GET cc/_search { "query": { "bool": { "must": [ {"match": { "code": "amc8" }} ], "filter": { "range": { "questionLevelId": { "gte": 2, "lte": 10 } } } } } } GET cc/_search { "query": { "match": { "FIELD": "AMC8" } } } GET cc/_search { "query": { "match_phrase": { "code": "1998" } } } GET cc/_search { "query": { "term": { "code.keyword": "NCSL3-2016-1" } } } GET cc/_search { "query": { "term": { "code.keyword": { "value": "AMC8" } } } } DELETE cc # html 剥离 POST _analyze { "tokenizer": "keyword", "char_filter": ["html_strip"], "text": "<b>hello world</b>" } POST _analyze { "tokenizer": "standard", "char_filter": [ { "type":"mapping", "mappings":["- => _"] } ], "text": "123-234,I-test ! test-990 650-12" } POST _analyze { "tokenizer": "standard", "char_filter": [ { "type":"mapping", "mappings":[":) => happy"] } ], "text": "I fell :)" } # 正则表达式 POST _analyze { "tokenizer": "standard", "char_filter": [ { "type":"pattern_replace", "pattern":"http://(.*)", "replacement":"$1" } ], "text": "http://www.baidu.co" } #路径 POST _analyze { "tokenizer": "path_hierarchy", "text": "/user/soft/es/bin/es" } GET _analyze { "tokenizer": "whitespace", "filter": ["stop"], "text": ["The rain in Spain fail"] } GET cc/_mapping GET cc GET cc/_search { "query": { "match_all": {} } } DELETE cc GET cc PUT cc { "mappings" : { "cc_question" : { "properties" : { "answer" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "category" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "code" : { "type" : "completion", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "content" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "createTime" : { "type" : "long" }, "deleted" : { "type" : "boolean" }, "id" : { "type" : "long" }, "knowledgePoint" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "properties" : { "type" : "nested", "properties" : { "examinationPaperCode" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "questionNumber" : { "type" : "long" } } }, "questionLevelId" : { "type" : "long" }, "questionSourceId" : { "type" : "long" }, "subjectId" : { "type" : "long" }, "type" : { "type" : "long" }, "updateTime" : { "type" : "long" } } } } } DELETE products PUT products { "settings": { "number_of_shards": 1 } } POST products/_doc/_bulk { "index": { "_id": 1 }} { "productID" : "XHDK-A-1293-#fJ3","desc":"iPhone" } { "index": { "_id": 2 }} { "productID" : "KDKE-B-9947-#kL5","desc":"iPad" } { "index": { "_id": 3 }} { "productID" : "JODL-X-1937-#pV7","desc":"MBP" } GET products GET products/_search { "query": { "match_all": {} } } GET products/_search { "query": { "term": { "productID.keyword": { "value": "XHDK-A-1293-#fJ3" } } } } # constant_score 跳过算分 GET products/_search { "query": { "constant_score": { "filter": {"term": { "productID.keyword": "XHDK-A-1293-#fJ3" }} } } } # 返回结果过滤 GET cc/_search { "query": { "match": { "content": { "query": "'desc':'B'", "operator": "and" } } }, "_source": { "excludes": ["id","subjectId","content"], "includes": ["knowledgePoint"] } } DELETE cc GET _search { "query": { "match_all": {} } } GET cc GET cc/cc_question/mapping GET cc/_search { "query": { "match_all": {} } } GET cc/_search { "query": { "bool": { "must": [ {"match": { "knowledgePoint": "1" }},{ "match": { "questionLevelId": "1" } },{ "match": { "questionSourceId": "1" } } ] } }, "from": 0, "size": 20 } GET cc/_search { "query": { "match": { "properties.questionNumber": 6 } } } GET cc/_search { "query": { "match": { "knowledgePoint": "2" } }, "sort": { "_script": { "script": "Math.random()", "type": "number", "order": "asc" } }, "from": 0, "size": 2 } GET cc/_search { "query": { "match": { "questionSourceId": "3" } } } GET cc/_search { "query": { "match": { "id": "256" } } } GET cc/_search { "query": { "match": { "subjectId": "1" } } } GET cc/_search { "query": { "bool": { "filter": { "term": { "knowledgePoint": "1" } } } } } # must 必须满足(影响算分的),must_not 必须不满足,should 必须满足其中一条,filter 必须满足(不影响算分) GET cc/_search { "size": 3, "query": { "bool": { "must": [ {"term": { "subjectId": { "value": "1" } }}, {"term": { "type": { "value": "1" } }} ], "must_not": [ {"term": { "questionSourceId": { "value": "23" } }} ], "should": [ {"term": { "category": { "value": "2" } }}, { "term": { "category": { "value": "1" } } } ] } } } GET cc/_search { "query": { "match": { "questionSourceId": "3" } }, "aggs": { "all": { "terms": { "field": "questionSourceId" } } } } GET cc/_search { "query": { "match": { "subjectId": "1" } }, "aggs": { "all": { "terms": { "field": "questionLevelId" } } } } GET cc/_search { "aggs": { "all_interests": { "terms": { "field": "questionLevelId" }, "aggs": { "NAME": { "terms": {"field":"questionSourceId"} } } } } } GET cc/_search { "aggs": { "questionSourceIds": { "terms": { "field": "questionSourceId" }, "aggs": { "questionLevelIds": { "terms": {"field":"questionLevelId"} } } } } , "from": 0, "size": 0 } GET cc/_search { "aggs": { "questionSourceIds": { "terms": { "field": "questionSourceId" }, "aggs": { "questionLevelIds": { "terms": {"field":"questionLevelId"} } } } } , "from": 0, "size": 0 } GET cc/_search { "size": 0, "aggs": { "NAME": { "terms": { "field": "questionSourceId", "size": 10 }, "aggs": { "ava": { "avg": { "field": "questionLevelId" } } } } } } #ik_max_word #ik_smart #hanlp: hanlp默认分词 #hanlp_standard: 标准分词 #hanlp_index: 索引分词 #hanlp_nlp: NLP分词 #hanlp_n_short: N-最短路分词 #hanlp_dijkstra: 最短路分词 #hanlp_crf: CRF分词(在hanlp 1.6.6已开始废弃) #hanlp_speed: 极速词典分词 POST _analyze { "analyzer": "hanlp_standard", "text": ["剑桥分析公司多位高管对卧底记者说,他们确保了唐纳德·特朗普在总统大选中获胜"] } GET _cluster/health GET _cluster/health?level=indices DELETE cc GET _cluster/state/unassigned_shards GET /_cat/shards/cc POST cc/_flush/synced GET cc PUT cc/_settings { "number_of_replicas": 1 } #用于自动补全的字段 PUT music { "mappings": { "_doc" : { "properties" : { "suggest" : { "type" : "completion" }, "title" : { "type": "keyword" } } } } } PUT music/_doc/1?refresh { "suggest" : { "input": [ "Nevermind", "Nirvana" ], "weight" : 34 } } PUT music/_doc/1?refresh { "suggest" : [ { "input": "Nevermind", "weight" : 10 }, { "input": "Nirvana", "weight" : 3 } ]} PUT music/_doc/2?refresh { "suggest" : { "input": [ "Nevermind", "Nirvana" ], "weight" : 20 } } POST music/_search?pretty { "suggest": { "song-suggest" : { "prefix" : "nir", "completion" : { "field" : "suggest" } } } } POST music/_search?pretty { "suggest": { "song-suggest" : { "prefix" : "nir", "completion" : { "field" : "suggest", "skip_duplicates": true } } }} # 短语 PUT music/_doc/3?refresh { "suggest" : { "input": [ "lucene solr", "lucene so cool","lucene elasticsearch" ], "weight" : 20 } } PUT music/_doc/4?refresh { "suggest" : { "input": ["lucene solr cool","lucene elasticsearch" ], "weight" : 10 } } GET music POST music/_search?pretty { "suggest": { "song-suggest" : { "prefix" : "lucene s", "completion" : { "field" : "suggest" , "skip_duplicates": true } } } } POST cc/_search?pretty { "suggest": { "song-suggest" : { "prefix" : "lucene s", "completion" : { "field" : "content" , "skip_duplicates": true } } } } GET cc/_search { "suggest": { "YOUR_SUGGESTION": { "text": "AMC", "completion": { "field": "codes", "size": 20 } } }, "_source": "" } GET cc/_search { "query": { "query_string": { "query": "2" } }, "_source": ["id","code","knowledgePoint"] } DELETE cc GET cc/_search { "query": { "match_all": {} } }
-
springBoot2 + spring-data-elasticsearch 整合
整合如下:
1. 整合之前看看版本对应(https://github.com/spring-projects/spring-data-elasticsearch)
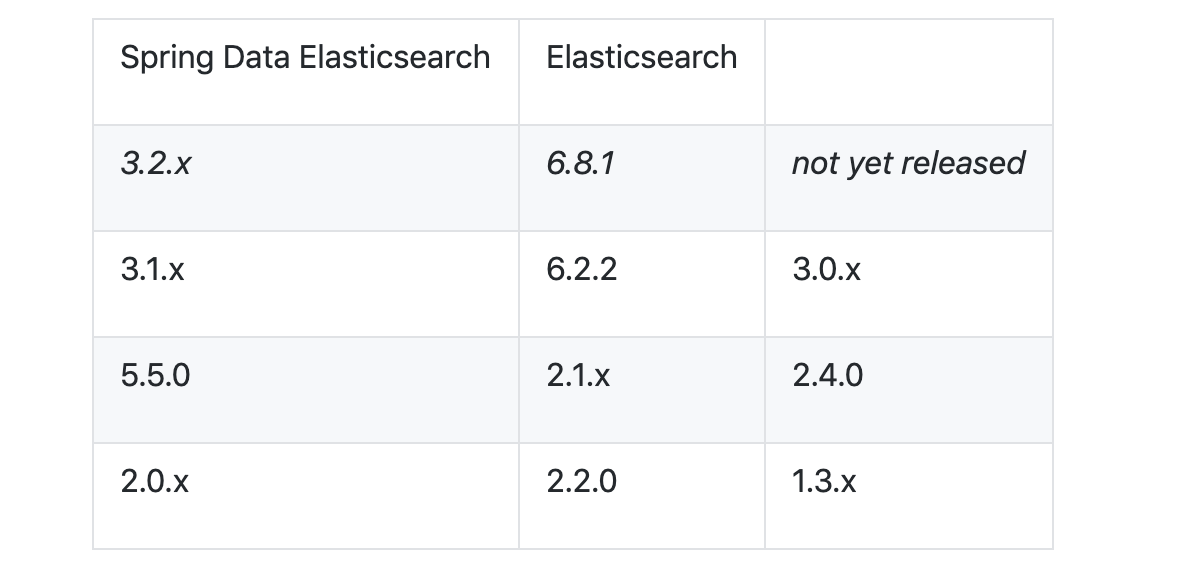
我安装的es版本是 6.8.1 ,所以整合的时候选中spring-data-es 是3.2.X版本的,同时我的springboot 版本是2.0.6
2. 创建项目

maven 中pom.xml 引入spring-data-es 的整合包

3. 创建存入到es 中的实体类
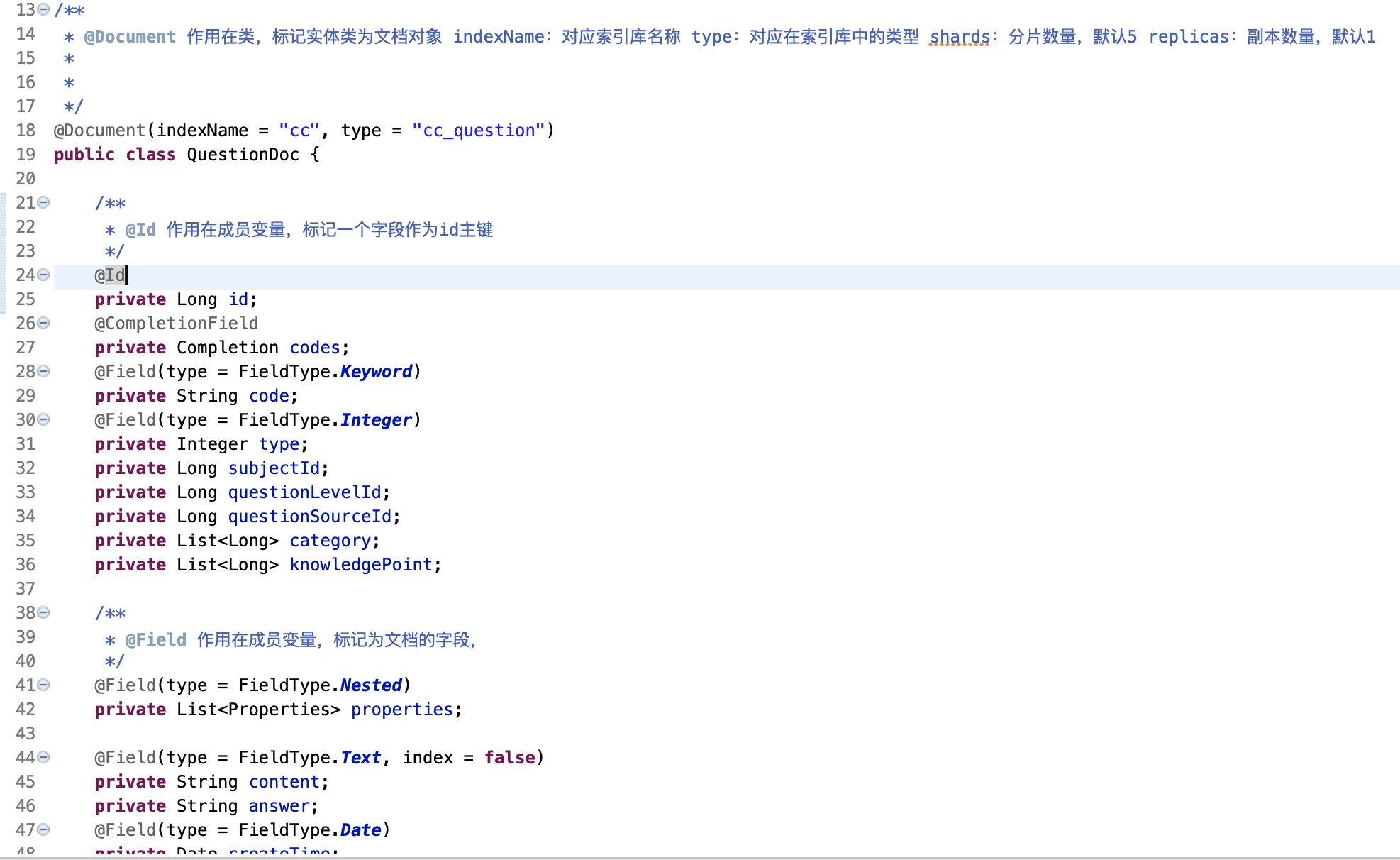
继承类 ElasticsearchRepository

常见操作:

配置文件: application.yml


相关文章推荐
- Storm入门 第二章 构建Topology
- Elasticsearch快速入门案例
- Elasticsearch 数据搜索篇·【入门级干货】
- ElasticSearch入门 附.Net Core例子
- HTML入门第一和第二章
- ElasticSearch 菜鸟笔记 (一)ElasticSearch 入门简介
- Elasticsearch顶尖高手系列-快速入门篇
- Elasticsearch 入门:Elasticsearch 5.0 安装 kibana 5.0
- 《读书报告 -- Elasticsearch入门 》--简单使用(2)
- ElasticSearch入门
- C#4.0入门 第二章 任务并行库—第一页 只使用双核(转)
- 史上最简单的Elasticsearch教程-第二章:初识Kibana(ES的辅助监测工具)
- ElasticSearch入门(2) —— 基础概念
- 在 Java 应用程序中使用 Elasticsearch: 高性能 RESTful 搜索引擎和文档存储快速入门指南
- ElasticSearch入门介绍之安装部署(二)
- 第二章:2.0 Django 入门和开发环境
- Linux入门学习-ubuntu基本命令_第二章
- Jenkins入门系列之——02第二章 Jenkins安装与配置
- 简单入门正则表达式 - 第二章 正则表达式应用范围
- Elasticsearch5.20 快速入门 并安装elasticsearch-head插件