大数据-Hadoop生态(8)-HDFS的读写数据流程以及机架感知
1. HDFS的写数据流程

1.客户端通过fs模块向NameNode申请文件上传,NameNode检查请求是否合法,如用户权限,目标文件是否已存在,父目录是否存在等等
2.NameNode返回是否可以上传,如果是的话,建立连接通道
3.客户端通过FSDataOutputStream模块请求上传block,NameNode根据网络拓扑距离计算返回的节点,dn1,dn2,dn3
4.客户端与dn1建立连接通道,dn1收到请求后会向dn2发起连接请求,dn2收到请求后会向dn3发起请求.请求通道全部打通后,会从后逐次向前应答,最后应答到客户端,通道建立成功
5.客户端开始上传block,block以packet为单位进行传输,大小为64k,dn1接收到packet后,将packet放入buffer缓冲中,一边往本地磁盘写,一边发送给dn2,dn2接收到后,以同样的方式进行处理和传输给dn3,dn3也进行同样的处理
6.等到block发送完毕后,本次传输结束
2.HDFS的读数据流程
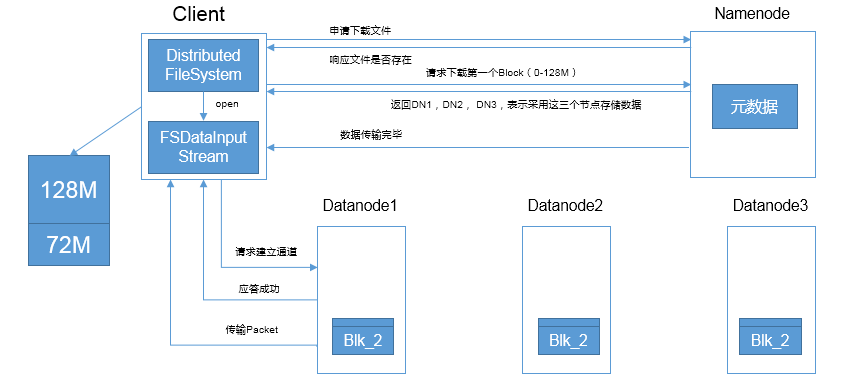
1. 客户端向NameNode申请文件下载,NameNode检查请求的合法性.如果请求合法,返回可以下载的相应,建立连接通道
2. 客户端请求下载文件,NameNode查询元数据,返回DataNode节点,DataNode节点以拓扑距离排序
3. 客户端请求连接第一个DataNode,应答成功后,DataNode开始以Packet传输数据.
4. 客户端接收Packet,边接收边写入磁盘.
5. 文件传输完成,关闭连接.
3.机架感知

通常情况下,如果有三份备份(replication)的话,HDFS的策略是第一个replication在客户端所处的节点上,如果客户端在集群外,从拓扑网络的距离近的节点上随机选一个,第二个replication和第一个replication是同一机架上随机的节点.第三个replication是不同机架上随机的节点

- Hadoop分布式文件系统——HDFS概念以及hdfs读写数据
- 大数据【二】HDFS部署及文件读写(包含eclipse hadoop配置)
- Hadoop_HDFS文件读写代码流程解析和副本存放机制
- HDFS上读写数据的流程解释
- Hdfs读写数据流程
- Hadoop2.x环境搭建之搭建伪分布模式以及运行wordcount案例【HDFS上的数据】
- 【HDFS】hadoop的机架感知策略是啥?
- Hadoop DataNode的读和写流程 选择datanode方法 机架感知
- hadoop(三):hdfs 机架感知
- Hadoop大数据视频教程-第一季:真实电商数据仓库全流程开发详解
- Hadoop2.6.0学习笔记(七)HDFS读写流程
- hadoop学习之使用命令行以及javaAPI管理 hdfs中的数据
- 大数据开发之Hadoop篇----hdfs写流程
- 大数据生态系统基础:Hadoop(五):Hadoop 3.0.0 HDFS读写及编程基础
- Hadoop之HDFS分布式文件系统读写流程详解
- Hadoop学习日记之hdfs读写流程
- HDFS的存储结构以及写入、读取hdfs数据操作流程简单总结
- 【大数据系列】Hadoop DataNode读写流程
- Hadoop -- HDFS 读写数据
- Java操作HDFS开发环境搭建以及HDFS的读写流程