Hadoop集群管理
1.简介
Hadoop是大数据通用处理平台,提供了分布式文件存储以及分布式离线并行计算,由于Hadoop的高拓展性,在使用Hadoop时通常以集群的方式运行,集群中的节点可达上千个,能够处理PB级的数据。
Hadoop各个模块剖析:https://www.geek-share.com/detail/2752506020.html
2.Hadoop集群架构图
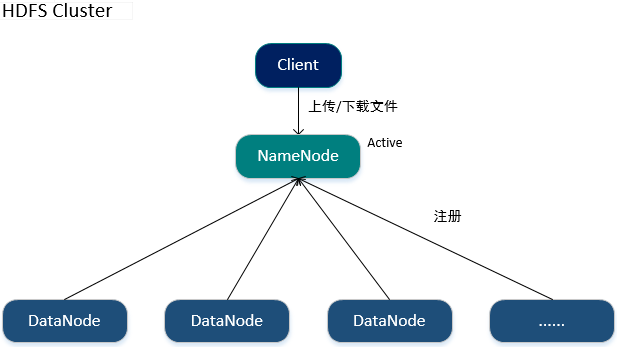
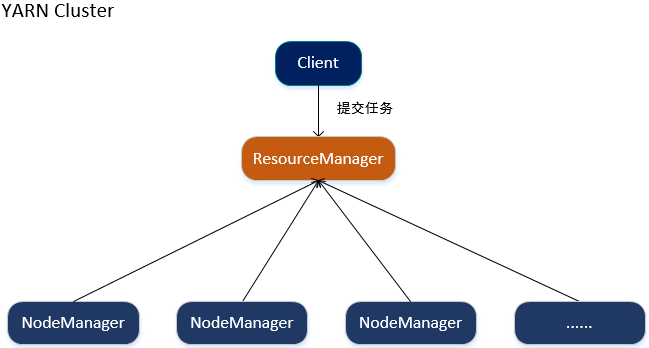
3.Hadoop集群搭建
3.1 修改配置
1.配置SSH以及hosts文件
由于在启动hdfs、yarn时都需要对用户的身份进行验证,且集群中NameNode、ResourceManager在启动时会通过SSH的形式通知其他节点,使其启动相应的进程,因此需要相互配置SSH设置免密码登录并且关闭防火墙或开启白名单。
//生成秘钥 ssh-keygen -t rsa //复制秘钥到本机和其他受信任的主机中,那么在本机可以直接通过SSH免密码登录到受信任的主机中. ssh-copy-id 192.168.1.80 ssh-copy-id 192.168.1.81 ssh-copy-id 192.168.1.82
编辑/etc/hosts文件,添加集群中主机名与IP的映射关系。

2.配置Hadoop公共属性(core-site.xml)
<configuration> <!-- Hadoop工作目录,用于存放Hadoop运行时NameNode、DataNode产生的数据 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/hadoop-2.9.0/data</value> </property> <!-- 默认NameNode --> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.1.80</value> </property> <!-- 开启Hadoop的回收站机制,当删除HDFS中的文件时,文件将会被移动到回收站(/usr/<username>/.Trash),在指定的时间过后再对其进行删除,此机制可以防止文件被误删除 --> <property> <name>fs.trash.interval</name> <!-- 单位是分钟 --> <value>1440</value> </property> </configuration>
*fs.defaultFS配置项用于指定HDFS集群中默认使用的NameNode。
3.配置HDFS(hdfs-site.xml)
<configuration> <!-- 文件在HDFS中的备份数(小于等于NameNode) --> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 关闭HDFS的访问权限 --> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> <!-- 设置NameNode的Web监控页面地址(主机地址需要与core-site.xml中fs.defaultFS配置的一致) --> <property> <name>dfs.namenode.http-address</name> <value>192.168.1.80:50070</value> </property> <!-- 设置SecondaryNameNode的HTTP访问地址 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.1.80:50090</value> </property> </configuration>
4.配置YARN(yarn-site.xml)
<configuration> <!-- 配置Reduce取数据的方式是shuffle(随机) --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 设置ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>192.168.1.80</value> </property> <!-- Web Application Proxy安全任务 --> <property> <name>yarn.web-proxy.address</name> <value>192.168.1.80:8089</value> </property> <!-- 开启日志 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志的删除时间 -1:禁用,单位为秒 --> <property> <name>yarn.log-aggregation。retain-seconds</name> <value>864000</value> </property> <!-- 设置yarn的内存大小,单位是MB --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>8192</value> </property> <!-- 设置yarn的CPU核数 --> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>8</value> </property> </configuration>
*yarn.resourcemanager.hostname配置项用于指定YARN集群中默认使用的ResourceManager。
5.配置MapReduce(mapred-site.xml)
<configuration> <!-- 让MapReduce任务使用YARN进行调度 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 设置JobHistory的服务地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.1.80:10020</value> </property> <!-- 指定JobHistory的Web访问地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>192.168.1.80:19888</value> </property> <!-- 开启Uber运行模式 --> <property> <name>mapreduce.job.ubertask.enable</name> <value>true</value> </property> </configuration>
*Hadoop的JobHistory记录了已运行完的MapReduce任务信息并存放在指定的HDFS目录下,默认未开启。
*Uber运行模式对小作业进行优化,不会给每个任务分别申请分配Container资源,这些小任务将统一在一个Container中按照先执行map任务后执行reduce任务的顺序串行执行。
6.配置Slave文件
#配置要运行DataNode、NodeManager的节点,值可以是主机名或IP地址。 192.168.1.80 192.168.1.81 192.168.1.82
*slave文件可以只在NameNode以及ResourceManager所在的节点中配置。
*在服务器中各种配置尽量使用主机名来代替IP。
3.2 启动集群
启动HDFS集群
1.分别格式化NameNode



2.在任意一台Hadoop节点中启动HDFS,那么整个HDFS集群将会一起启动。

分别通过jps命令查看当前启动的进程



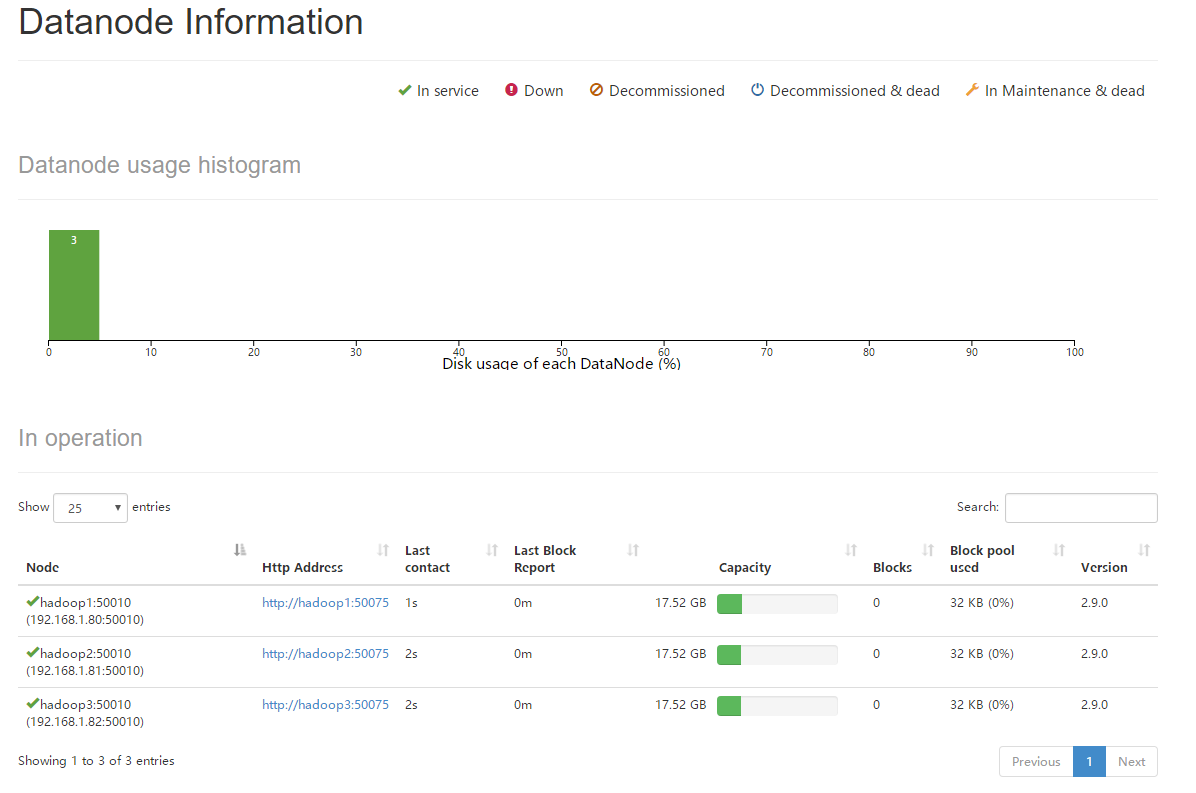
*当HDFS集群启动完毕后,由于NameNode部署在hadoop1机器上,因此可以访问http://192.168.1.80:50070进入HDFS的可视化管理界面,可以查看到当前HDFS集群中有3个存活的DataNode节点。
启动YARN集群
1.在yarn.resourcemanager.hostname配置项指定的节点中启动YARN集群。

分别通过jps命令查看当前启动的进程



*当YARN集群启动完毕后,由于ResourceManager部署在hadoop1机器上,因此可以访问http://192.168.1.80:50070进入YARN的可视化管理界面,可以查看到当前YARN集群中有3个存活的NodeManager节点。

2.在mapreduce.jobhistory.address配置项指定的节点中启动JobHistory。

*当启动JobHistory后,可以访问mapreduce.jobhistory.address配置项指定的地址进入JobHistory,默认是http://192.168.1.80:19888。
4.Hadoop集群管理
4.1 动态添加节点
1.修改各个节点的hosts文件,添加新节点的主机名与IP映射关系。

2.相互配置SSH,使可以通过SSH进行免密码登录。
3.修改NameNode和ResourceManager所在节点的Slave文件,添加新节点的主机名或IP地址。

4.单独在新节点中启动DataNode和NodeManager。

*进入HDFS管理页面,可以查看到当前HDFS集群中有4个存活的DataNode节点。
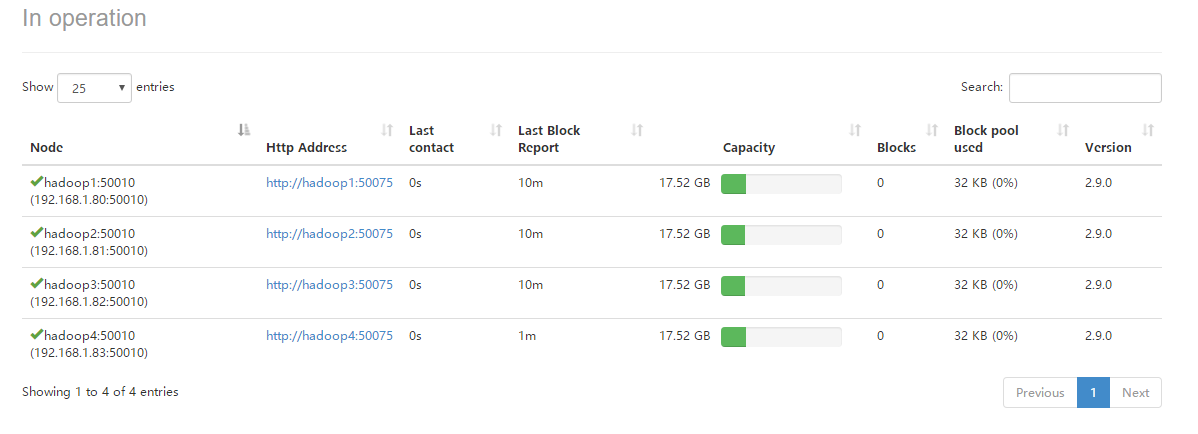
*进入YARN管理页面,可以查看到当前YARN集群中有4个存活的NodeManager节点。
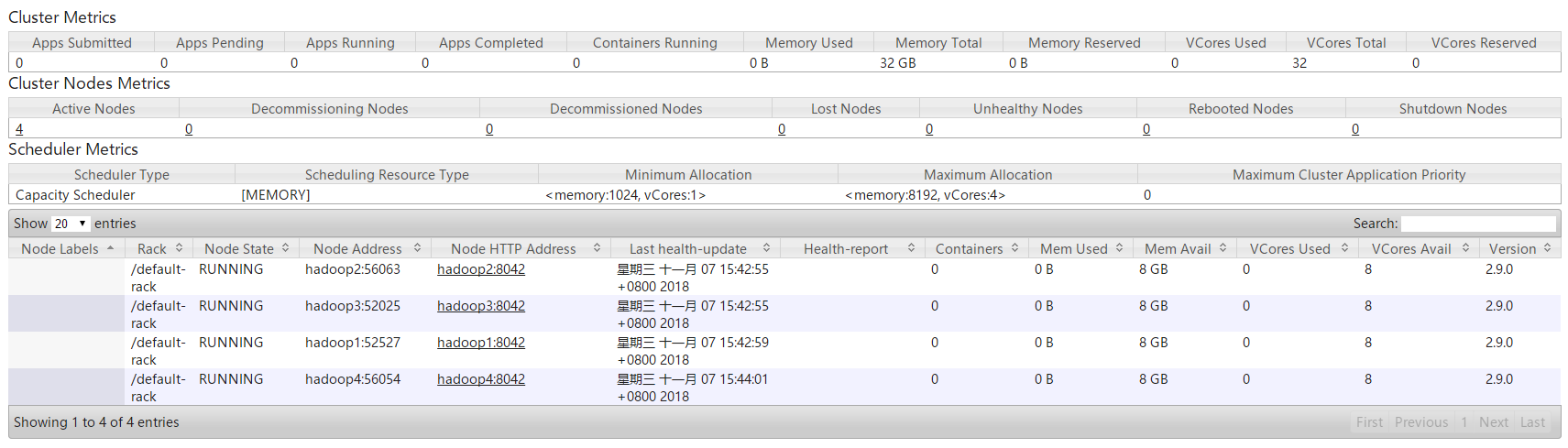
4.2 动态卸载节点
1.修改NameNode所在节点上的hdfs-site.xml配置文件。
<!-- 指定一个配置文件,使NameNode过滤配置文件中指定的host --> <property> <name>dfs.hosts.exclude</name> <value>/usr/hadoop/hadoop-2.9.0/etc/hadoop/hdfs.exclude</value> </property>
2.修改ResourceManager所在节点上的yarn-site.xml配置文件。
<!-- 指定一个配置文件,使ResourceManager过滤配置文件中指定的host --> <property> <name>yarn.resourcemanager.nodes.exclude-path</name> <value>/usr/hadoop/hadoop-2.9.0/etc/hadoop/yarn.exclude</value> </property>
3.分别刷新HDFS和YARN集群

查看HDFS管理页面,可见hadoop4的DataNode已被动态的剔除。
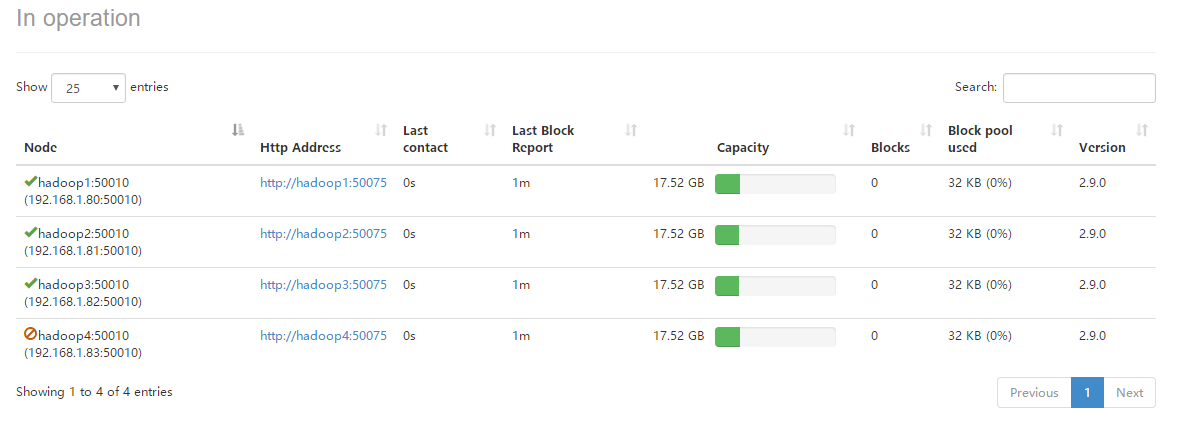
查看YARN管理页面,可见hadoop4的NodeManager已被动态的剔除。
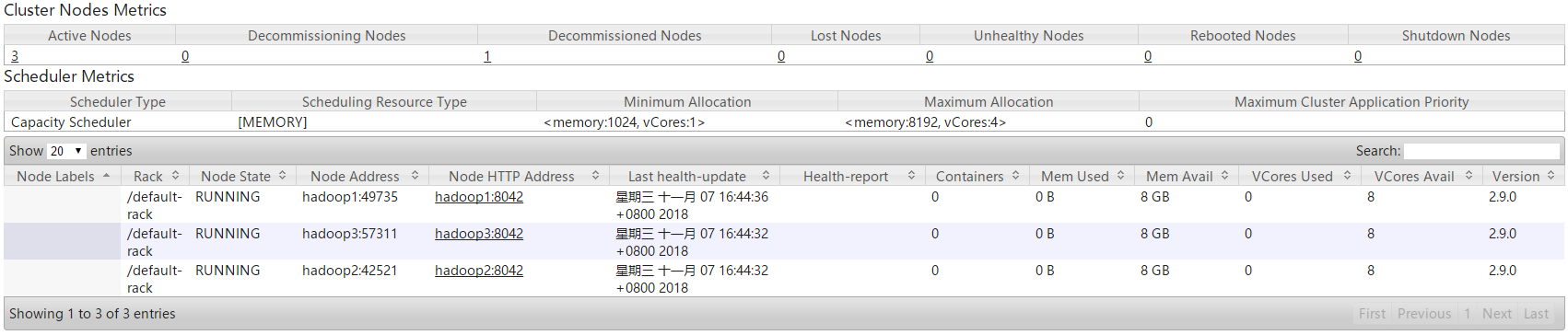
使用jps命令查看hadoop4中Hadoop进程,可以发现NodeManager进程已经被kill掉,只剩下DataNode进程,因此YARN集群在通过配置文件的形式动态过滤节点时,一旦节点被过滤,则NodeManager进程直接被杀死,不能动态的进行恢复,必须重启进程并在exclude.host文件中剔除,而HDFS集群在通过配置文件的形式动态过滤节点时可以动态的进行卸载和恢复。

*若第一次使用该配置则需要重启HDFS和YARN集群,使其重新读取配置文件,往后一旦修改过exclude.host配置文件则直接刷新集群即可。

- [hadoop读书笔记] 第十章 管理Hadoop集群
- 使用HUE来管理hadoop集群
- Linux7 下Hadoop集群用户管理方案之三 用户认证组件Kerberos安装
- 王家林的81门一站式云计算分布式大数据&移动互联网解决方案课程第三门课程:云计算分布式大数据Hadoop征服之旅:HDFS&MapReduce&HBase&Hive&集群管理
- 配置管理(可参考用于hadoop集群部署)
- 管理Hadoop集群的5大工具
- nginx反向代理hadoop集群管理页面
- Hadoop CDH5 集群管理
- Linux7 下Hadoop集群用户管理方案之四 CDH集成Kerberos
- hadoop集群管理之 SecondaryNameNode和NameNode
- Hadoop集群管理 fsimage和edits工作机制内幕
- hadoop集群管理之 SecondaryNameNode和NameNode
- RedHadoop创始人童小军在北京开讲“Hadoop2.0集群优化与管理”啦!
- hadoop-集群管理(4)——关键属性
- 第131讲:Hadoop集群管理工具均衡器Balancer 实战详解学习笔记
- 完全分布式hadoop集群安装之二:linux虚拟机安装及管理(centos 6.0 32位)
- Hadoop集群管理 Namenode的目录数据结构
- Hadoop - 浅谈Ambari集群管理剖析
- hadoop-集群管理(2)——内存设置
- Hadoop集群管理