python爬取电影并下载
2018-10-27 11:17
555 查看
一、概述
对于一个宅男,喜欢看电影,每次打开电影网站,各种弹出的广告,很是麻烦,还是要自己去复制下载链接到迅雷上粘贴并下载,这个过程中还有选择困难症;这一系列的动作让人甚是不爽,不如有下好的,点着看就好了;作为一个python爱好者,结合对爬虫的一点小了解,于是周末花了点时间用python写了一个爬取某电影网站上的最新电影板块;
思路:
爬虫针对某电影网站,收集电影名,下载链接,评分,等信息;当天更新的电影,特别的打印出来;同时通过评分调用迅雷下载,当然先判断下,是否已经下载过了,再决定是否下载;然后,就是可以看了~
本次版本是基于python3.x下通过,在windows上才能调用迅雷~linux平台只能获取相关信息!
python安装和相关的模块安装这里不讲述,如有不明白请留言我~
二、代码
废话不多说上代码吧~
# coding:utf-8
# version 20181027 by san
import re,time,os
from urllib import request
from lxml import etree # python xpath 单独使用导入是这样的
import platform
#爬虫电影之类
class getMovies:
def __init__(self,url,Thuder):
''' 实例初始化 '''
self.url = url
self.Thuder = Thuder
def getResponse(self,url):
url_request = request.Request(self.url)
url_response = request.urlopen(url_request)
return url_response #返回这个对象
def newMovie(self):
''' 获取最新电影 下载地址与url '''
http_response = self.getResponse(webUrl) #拿到http请求后的上下文对象(HTTPResponse object)
data = http_response.read().decode('gbk')
#print(data) #获取网页内容
html = etree.HTML(data)
newMovies = dict()
lists = html.xpath('/html/body/div[1]/div/div[3]/div[2]/div[2]/div[1]/div/div[2]/div[2]/ul/table//a')
for k in lists:
if "app.html" in k.items()[0][1] or "最新电影下载" in k.text:
continue
else:
movieUrl = webUrl + k.items()[0][1]
movieName = k.text.split('《')[1].split("》")[0]
newMovies[k.text.split('《')[1].split("》")[0]] = movieUrl = webUrl + k.items()[0][1]
return newMovies
def Movieurl(self,url):
''' 获取评分和更新时间 '''
url_request = request.Request(url)
movie_http_response = request.urlopen(url_request)
data = movie_http_response.read().decode('gbk')
if len(re.findall(r'豆瓣评分.+?.+users',data)): # 获取评分;没有评分的返回null
pingf = re.findall(r'豆瓣评分.+?.+users',data)[0].split('/')[0].replace("\u3000",":")
else:
pingf = "豆瓣评分:null"
times = re.findall(r'发布时间.*',data)[0].split('\r')[0].strip() # 获取影片发布时间
html = etree.HTML(data)
murl = html.xpath('//*[@id="Zoom"]//a')
for k in murl:
for l in k.items():
if "ftp://" in l[1]:
print
return l[1],times,pingf
def check_end(self,fiename,path):
''' 检测文件是否下载完成 '''
return os.path.exists(os.path.join(save_path,fiename))
def check_start(self,filename):
''' 检测文件是否开始下载 '''
cache_file = filename+".xltd"
return os.path.exists(os.path.join(save_path,cache_file))
def DownMovies(self,name,url):
''' windows下载 '''
PlatForm = platform.system()
print("即将下载的电影是:%s" %name)
if PlatForm == "Windows":
try:
print(r'"{0}" "{1}"'.format(self.Thuder,url))
os.system(r'"{0}" {1}'.format(self.Thuder,url))
except Exception as e:
print(e)
else:
print("当前系统平台不支持")
def Main(self):
''' 最终新电影存储在字典中 '''
NewMoveis = dict()
Movies = self.newMovie() # 获取电影的字典信息
for k,v in Movies.items():
NewMoveis[k] = self.Movieurl(v),v
return NewMoveis
def NewMoives(self):
''' 查看已经获取到的电影信息 '''
Today = time.strftime("%Y-%m-%d")
print("今天是:%s" %Today)
Movies = self.Main()
print("最近的 %s 部新电影:" % len(Movies.keys()))
for k,v in Movies.items():
# print(v[0][1].split(":")[0])
if Today in v[0][1].split(":")[0]:
print("++++++++++++++++今天刚更新++++++++++++++:","\n",k,"-->",v,"\n")
else:
print("========================================")
print(k,"-->",v,"\n")
if __name__ == '__main__':
# 以下依据您个人电影迅雷的相关信息填写即可
save_path="O:\迅雷下载" # 电影下载保存位置 (需要填写)
Thuder = "O:\Program\Thunder.exe" #Thuder: 迅雷Thuder.exe路径 (需要填写)
webUrl = 'http://www.dytt8.net' # 电影网站
test = getMovies(webUrl,Thuder) # 实例化
test.NewMoives()
Movie
5b4
s = test.Main()
for k,v in Movies.items():
movies_name = v[0][0].split('/')[3]
socre = v[0][2].split(":")[1]
check_down_status = test.check_end(movies_name,save_path)
# print(check_down_status)
if check_down_status:
print("电影: %s 已经下载" %movies_name)
continue
elif socre == 'null':
continue
elif float(socre) > 7.0:
print(movies_name,socre)
test.DownMovies(k,v[0][0])
time.sleep(10)
注意:以上代码是针对windows平台下,迅雷版本为非极速版本,本次使用的是9.14 如图:

另外需要勾选以下配置项,否则程序调用迅雷下载时会有提示框:
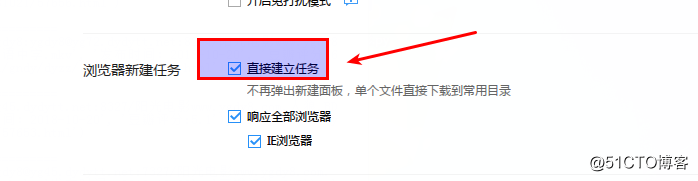
程序运行效果如图:

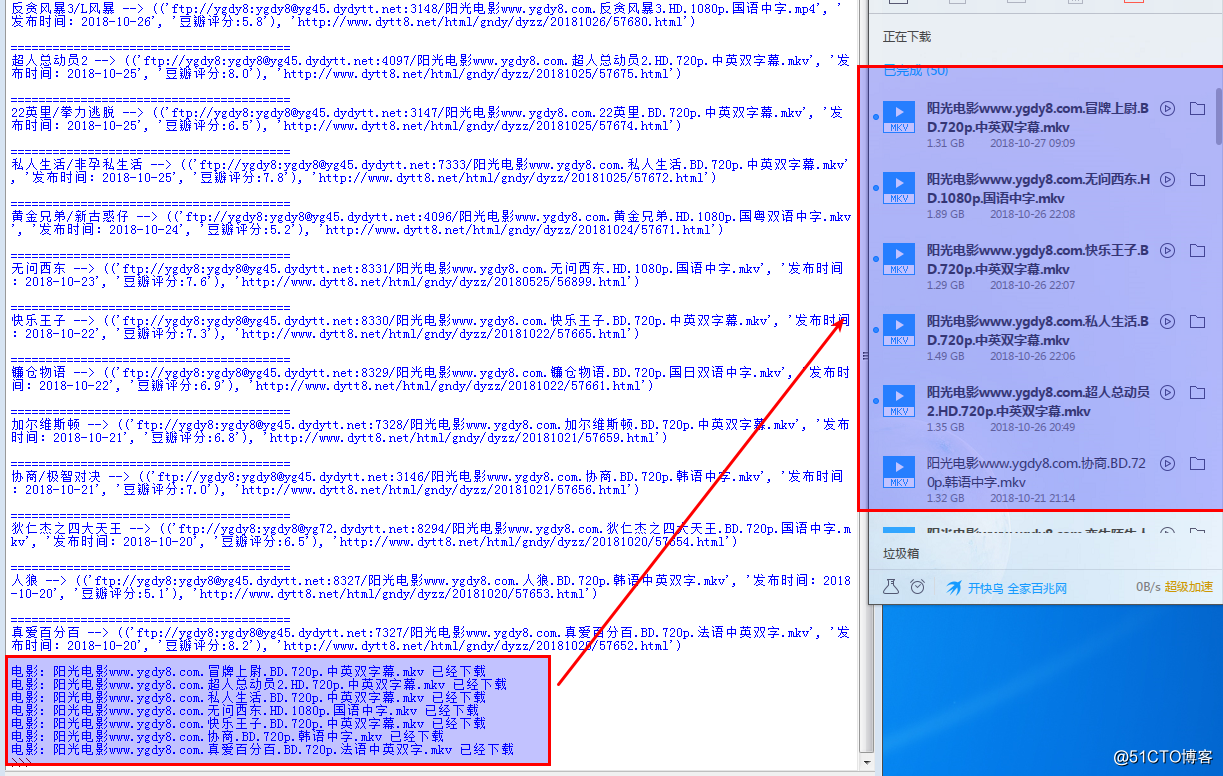
再看下O盘 下载的目录:
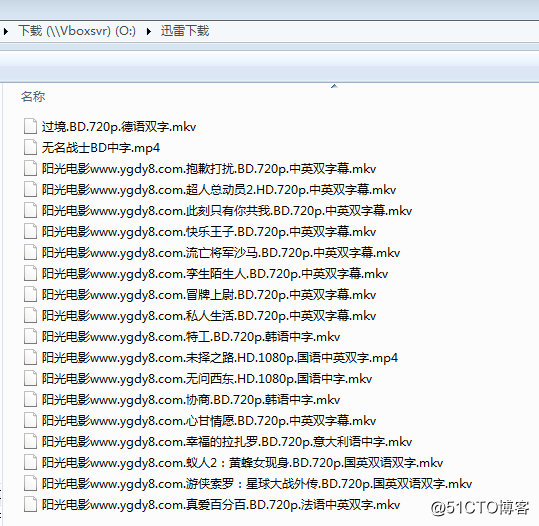
至此自动获取最新电影并下载指定评分电影完成~ 再也不用担心选择困难了,下好看就行了~
补充说明:
这只是一个基本的获取并下载电影的程序,也可能扩充成下载好发邮件,或不想下载,定时运行,有新电影发邮件提示的功能~更功能自行发挥吧,如有那位大牛知道linux下自行下载的方法,欢迎留言交流,谢谢~如果觉得还可以,不要忘记点个赞哦~

相关文章推荐
- [置顶] 【python 下载器】python下载电影&视频&电视剧
- python下载各大主流视频网站电影
- 用python来爬某电影网站的下载地址
- python 爬取电影下载链接
- Python爬虫之多线程下载豆瓣Top250电影图片
- 用python做一个可以下载电影天堂最新电影的爬虫
- Python批量下载电视剧电影--自己动手丰衣足食
- 去除下载电影和电视剧文件名中的多余字符[python实现]
- Python+Flask搭建一个电影下载网站
- Python自动化(二)使用Beautifu Soup爬取电影下载链接
- Python爬虫实战(八):爬取电影天堂的电影下载链接
- python爬虫实现下载电影天堂电影
- python实现去除下载电影和电视剧文件名中的多余字符的方法
- python3批量重命名电影(windows下下载的电视剧)
- Python 2.7_Second_try_爬取阳光电影网_获取电影下载地址并写入文件 20161207
- Python多线程爬虫获取电影下载链接
- python爬取电影天堂网各个电影下载地址
- python实现去除下载电影和电视剧文件名中的多余字符的方法
- 讨厌下载电影和电视剧文件名中的多余字符(如网址和广告字样),搞得文件名好长,可以使用下面的Python代码
- python学习1(下载、安装)