Spark入门学习——要点1
2018-09-14 16:45
465 查看
1、collect() 函数
RDD 还有一个collect() 函数,可以用来获取整个RDD 中的数据。如果你的程序把RDD 筛选到一个很小的规模,并且你想在本地处理这些数据时,就可以使用它。记住,只有当你的整个数据集能在单台机器的内存中放得下时,才能使用collect(),因此,collect() 不能用在大规模数据集上。使用collect() 使得RDD 的值与预期结果之间的对比变得很容易。由于需要将数据复制到驱动器进程中,collect() 要求所有数据都必须能一同放入单台机器的内存中。2、Java标准函数接口
| 函数名 | 实现的方法 | 用途 |
| Function<T,R> | R call(T) | 接收一个输入值并返回一个输出值,用于类似map() 和filter() 等操作中 |
| Function2<T1, T2, R> | R call(T1, T2) | 接收两个输入值并返回一个输出值,用于类似aggregate()和fold() 等操作中 |
| FlatMapFunction<T, R> | Iterable<R> call(T) | 接收一个输入值并返回任意个输出,用于类似flatMap()这样的操作中 |
3、常见的转化操作和action操作
对一个数据为{1,2,3,3}的RDD进行基本的RDD转化操作| 函数名 | 目的 | 示例 | 结果 |
| map() | 将函数应用于Rdd中每个元素,将返回值构成新的RDD | rdd.map(x->x+1) | {2, 3, 4, 4} |
| flatMap() | 将函数应用于RDD 中的每个元 素,将返回的迭代器的所有内 容构成新的RDD。通常用来切 分单词 | rdd.flatMap(x => x.to(3)) | {1, 2, 3, 2, 3, 3, 3} |
| filter() | 返回一个由通过传给filter() 的函数的元素组成的RDD | rdd.filter(x => x != 1) | {2, 3, 3} |
| distinct() | 去重 | rdd.distinct() | {1, 2, 3} |
| sample(withReplacement, fraction, [seed]) | 对RDD 采样,以及是否替 | rdd.sample(false, 0.5) | 非确定的 |
| 函数名 | 目的 | 示例 | 结果 |
| union() | 生成一个包含两个RDD 中所有元 素的RDD | rdd.union(other) | {1, 2, 3, 3, 4, 5} |
| intersection() | 求两个RDD 共同的元素的RDD | rdd.intersection(other) | {3} |
| subtract() | 移除一个RDD 中的内容(例如移 除训练数据) | rdd.subtract(other) | {1, 2} |
| cartesian() | 与另一个RDD 的笛卡儿积 | rdd.cartesian(other) | {(1, 3), (1, 4), ... (3, 5)} |
| 行动 | 涵义 |
|---|---|
| reduce(func) | 使用传入的函数参数 func 对数据集中的元素进行汇聚操作 (两两合并). 该函数应该具有可交换与可结合的性质, 以便于能够正确地进行并行计算. |
| collect() | 在 driver program 上将数据集中的元素作为一个数组返回. 这在执行一个 filter 或是其他返回一个足够小的子数据集操作后十分有用. |
| count() | 返回数据集中的元素个数 |
| first() | 返回数据集中的第一个元素 (与 take(1) 类似) |
| take(n) | 返回数据集中的前 n 个元素 |
| takeSample(withReplacement, num, [seed]) | 以数组的形式返回数据集中随机采样的 num 个元素. |
| takeOrdered(n, [ordering]) | 以其自然序或使用自定义的比较器返回 RDD 的前 n 元素 |
| saveAsTextFile(path) | 将数据集中的元素写入到指定目录下的一个或多个文本文件中, 该目录可以存在于本地文件系统, HDFS 或其他 Hadoop 支持的文件系统. Spark 将会对每个元素调用 toString 将其转换为文件的一行文本. |
| saveAsSequenceFile(path)(Java and Scala) | 对于本地文件系统, HDFS 或其他任何 Hadoop 支持的文件系统上的一个指定路径, 将数据集中的元素写为一个 Hadoop SequenceFile. 仅适用于实现了 Hadoop Writable 接口的 kay-value pair 的 RDD. 在 Scala 中, 同样适用于能够被隐式转换成 Writable 的类型上 (Spark 包含了对于 Int, Double, String 等基本类型的转换). |
| saveAsObjectFile(path)(Java and Scala) | 使用 Java 序列化将数据集中的元素简单写为格式化数据, 可以通过 SparkContext.objectFile() 进行加载. |
| countByKey() | 仅适用于 (K, V) 类型的 RDD. 返回每个 key 的 value 数的一个 hashmap (K, int) pair. |
| foreach(func | 对数据集中的每个元素执行函数 func. 这通常用于更新一个 Accumulator 或与外部存储系统交互时的副作用. 注意: 修改 foreach() 外的非 Accumulator 变量可能导致未定义的行为. 更多细节请查看 Understanding closures. |
4、distinct()函数
我们的RDD 中最常缺失的集合属性是元素的唯一性,因为常常有重复的元素。如果只要唯一的元素,我们可以使用RDD.distinct() 转化操作来生成一个只包含不同元素的新RDD。不过需要注意,distinct() 操作的开销很大,因为它需要将所有数据通过网络进行混洗(shuffle),以确保每个元素都只有一份。5、Spark RDD缓存/持久化策略
为了避免多次计算同一个RDD,可以让Spark 对数据进行持久化。出于不同的目的,我们可以为RDD 选择不同的持久化级别(如表3-6 所示)。在Scala(见 例3-40)和Java 中,默认情况下persist() 会把数据以序列化的形式缓存在JVM 的堆空间中。在Python 中,我们会始终序列化要持久化存储的数据,所以持久化级别默认值就是以序列化后的对象存储在JVM 堆空间中。当我们把数据写到磁盘或者堆外存储上时,也总是使用序列化后的数据。
表3-6:org.apache.spark.storage.StorageLevel和pyspark.StorageLevel中的持久化级别;如有必要,可以通过在存储级别的末尾加上“_2”来把持久化数据存为两份
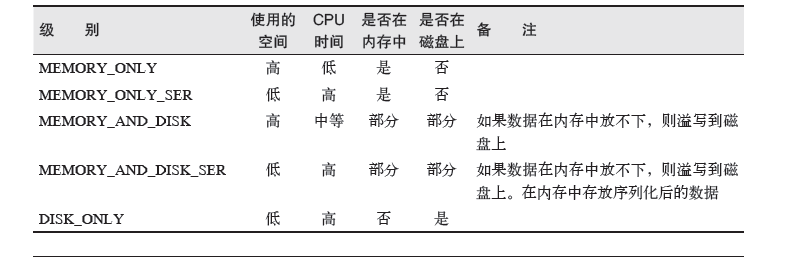
如果在调用RDD的action的操作之前调用了persist()操作,并不会马上出发强制求值机制,仍然是懒加载的机制。
如果缓存的数据过多,内存中放不下,Spark会自动利用最近最少使用(LRU)缓存策略进行数据分区移除。对于仅把数据存放在内存中的缓存级别,下一次要用到已经被移除的分区,这些分区需要重新计算。但是对于内存+磁盘模式的缓存级别的分区来说,被移除的分区都会被写入磁盘。
RDD还有一个方法叫做UNpersist(),调用该方法可以手动把持久化的RDD从缓存中删除。

相关文章推荐
- Spark入门学习——要点3
- Spark入门学习——要点2
- Spark 学习入门教程
- PS入门学习须要注意的十个要点
- Spark学习笔记:(一)入门 glance
- Spark 学习入门教程
- Spark 学习入门教程
- Spark入门学习
- 菜鸟入门:Java语言学习六大要点
- Spark入门学习
- Spark 入门学习
- 学习Spark的入门教程——《Spark大数据实例开发教程》
- Spark2.x学习笔记:1、Spark2.2快速入门(本地模式)
- JAVA入门--语言学习六大要点
- Spark入门之REPL/CLI/spark shell 快速学习
- Spark 学习入门教程
- 菜鸟入门Java程序学习的要点 (2012-08-14 11:23:00)
- java入门、java学习:菜鸟入门Java程序学习的要点
- spark学习笔记总结-spark入门资料精化
- 深度学习Deeplearning4j 入门实战(2):Deeplearning4j 手写体数字识别Spark实现