大数据Hadoop之HDFS读取过程总结
2018-07-27 20:44
134 查看
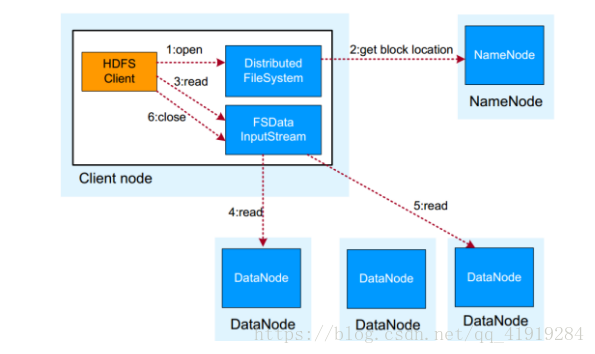
读取流程原理:
1.HDFS Client与NN通信,获取文件信息:
文件有多少块,分别在哪些DN上
2.业务调用read API 进行读写文件操作
3.HDFS Clien根据NN返回的元数据信息,与DN通信
此处Client采用就近原则读取数据,数据有多块时,不同DN,Client会同时与多个DN通信,获取数据块
4.数据读取完成以后,业务调用close关闭连接,读取结束
当Client与NN通信时,NN有验证机制,
验证1:Client发送的请求信息,是否存在
验证2:Client发送的请求,权限是否满足
NN验证机制通过以后,给Client返回的信息内容包含:
1.此文件分成了多少个块
2.这些快分别在哪些DN上,即DN的位置信息
Client读取数据的就近原则:
就近原则:近:响应请求的时间短
即:在两个或者多个副本时,Client会选择响应时间最短的那个副本进行读取操作,也就是选择最优的副本进行读写
HDFS架构其他关键设计要点说明:
1.统一的文件系统名字空间:
HDFS对外仅呈现一个统一的文件系统。
2.统一的通讯协议
统一采用RPC方式通信。 NameNode被动的接收Client, DataNode的RPC请求。
特殊:SN与NN的通讯协议为http
3.空间回收机制
支持回收站机制,以及副本数的动态设置机制。
副本数动态机制,只能增加,不能减少
4.数据组织
数据存储以数据块为单位,存储在操作系统的文件系统上。
分块时。最后一块的空间大小是文件的实际大小,并非128M
5.访问方式
提供JAVA API,HTTP方式,SHELL方式访问HDFS数据

相关文章推荐
- Hadoop学习总结之二:HDFS读写过程解析
- Hadoop学习总结之二:HDFS读写过程解析
- Hadoop学习总结之二:HDFS读写过程解析
- Hadoop学习总结之二:HDFS读写过程解析
- 2-7HDFS读取数据过程(Hadoop系列day02)
- Hadoop学习总结之二:HDFS读写过程解析
- Hadoop学习总结之二:HDFS读写过程解析
- Hadoop 学习总结之二:HDFS读写过程解析(转载)
- Hadoop学习总结之二:HDFS读写过程解析2(zz)
- Hadoop学习总结之二:HDFS读写过程解析
- Hadoop学习总结之二:HDFS读写过程解析
- HDFS读文件过程分析:读取文件的Block数据
- HDFS------hadoop fs -put 代码执行过程
- Spark在Hadoop的HDFS中读取数据
- Spark在Hadoop的HDFS中读取数据
- Hadoop学习总结之Map-Reduce的过程解析111
- Hadoop-->HDFS原理总结
- Hadoop学习过程中遇到的问题总结
- Hadoop的HDFS中的namenode和secondarynamenode的内容总结
- Hadoop中HDFS读取和写入的工作原理