Hadoop示例程序之——WordCount
2018-07-27 16:18
573 查看
尝试一下Hadoop的Demo,熟悉下相关的MapReducer的计算框架
hadoop fs -mkdir hdfs://localhost:9000/user/input --创建Hadoop存放文件的路径
hadoop fs -put FileTest1.txt hdfs://localhost:9000/user/input --上传文件至Hdfs 具体的相关原理后期再讲
hadoop fs -ls hdfs://localhost:9000/user/inout --查看hdfs中相关上传的文件
1、进入到相关的jar包所在路径下 此处我的jar包应该是打成FirstTry.jar,因此进入到FirstTry.jar的路径下 执行以下相关命令
hadoop jar FirstTry.jar hdfs://localhost:9000/user/input hdfs://localhost:9000/user/output
如果出现提示:Exception in thread "main" java.io.IOException: Mkdirs failed to create ..... 需要将jar包中的META-INF/LICENSE文 件夹删除,找到相关的jar -shift+delete 删除相关的目录
2、由于我的jar包是FirstTry.jar 而我的main函数的class是WordCount,因此需要制定下相关的class,因此相关的Hadoop命令改成这样,
hadoop jar FirstTry.jar hadoop.job.WordCount hdfs://locahost:9000/user/input hdfs://localhost:9000/user/output
然后你会看见下面的流程:
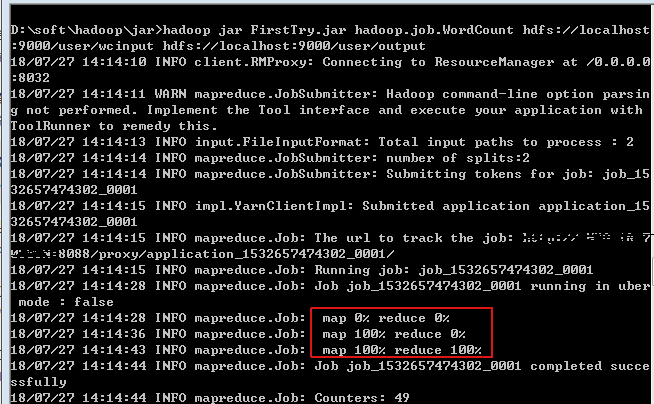
说明我们的第一个demo执行成功。
查看文件内容 hadoop fs -cat hdfs://localhost:9000/user/output/part-r-00000
1、创建Mapper类
package hadoop.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String wordline = value.toString();
StringTokenizer st = new StringTokenizer(wordline);
while (st.hasMoreTokens()) {
word.set(st.nextToken());
context.write(word, new IntWritable(1));
}
}
}2、创建Reducer类
package hadoop.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}3、配置相关的Job作业
package hadoop.job;
import hadoop.mr.WordCountMapper;
import hadoop.mr.WordCountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class WordCount {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration config = new Configuration();
Job job = new Job(config);
job.setJarByClass(WordCount.class);
job.setJobName("wordCount-Job");
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath((JobConf) job.getConfiguration(), new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}4、引入相关依赖
由于我这边使用的是ide编辑器来进行编码的,并且是创建的相关的maven工程进行项目的管理,因此需要引入一下的依赖<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.5.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.5.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.5.2</version> </dependency> </dependencies>
5、打成jar包
<groupId>FirstTry</groupId> <artifactId>FirstTry</artifactId> <version>1.0-SNAPSHOT</version>
6、由于使用hdfs进行文件的上传
相关命令如下:hadoop fs -mkdir hdfs://localhost:9000/user/input --创建Hadoop存放文件的路径
hadoop fs -put FileTest1.txt hdfs://localhost:9000/user/input --上传文件至Hdfs 具体的相关原理后期再讲
hadoop fs -ls hdfs://localhost:9000/user/inout --查看hdfs中相关上传的文件
7、运行jar包,执行相关的作业
相关命令如下:1、进入到相关的jar包所在路径下 此处我的jar包应该是打成FirstTry.jar,因此进入到FirstTry.jar的路径下 执行以下相关命令
hadoop jar FirstTry.jar hdfs://localhost:9000/user/input hdfs://localhost:9000/user/output
如果出现提示:Exception in thread "main" java.io.IOException: Mkdirs failed to create ..... 需要将jar包中的META-INF/LICENSE文 件夹删除,找到相关的jar -shift+delete 删除相关的目录
2、由于我的jar包是FirstTry.jar 而我的main函数的class是WordCount,因此需要制定下相关的class,因此相关的Hadoop命令改成这样,
hadoop jar FirstTry.jar hadoop.job.WordCount hdfs://locahost:9000/user/input hdfs://localhost:9000/user/output
然后你会看见下面的流程:
说明我们的第一个demo执行成功。
8、查询相关的结果
hadoop fs -ls hdfs://localhost:9000/user/output 查看输出文件part-r-00000查看文件内容 hadoop fs -cat hdfs://localhost:9000/user/output/part-r-00000
9、计算单词数量成功
第一个小程序OK啦。
相关文章推荐
- Hadoop示例程序WordCount编译运行
- hadoop示例程序wordcount的运行
- Hadoop安装配置、运行第一个WordCount示例程序
- hadoop 集群运行WordCount示例程序
- Hadoop示例程序WordCount运行及详解
- Hadoop示例程序WordCount详解及实例
- 运行Hadoop示例程序WordCount
- Hadoop示例程序WordCount详解及实例
- Hadoop示例程序WordCount详解
- 运行Hadoop的示例程序WordCount-Running Hadoop Example
- Hadoop示例程序WordCount详解及实例
- Hadoop示例程序WordCount运行及详解
- Hadoop示例程序WordCount详解及实例 .
- Hadoop示例程序WordCount详解及实例
- Hadoop示例程序WordCount详解及实例
- Hadoop系列--Hadoop自带程序wordcount运行示例
- Hadoop的安装与配置及示例程序wordcount的运行
- Hadoop Map/Reduce 示例程序WordCount
- wordcount示例程序运行全过程(Hadoop-1.0.0)
- (转载)Hadoop示例程序WordCount详解