进程调度之6:进程的调度与切换
2018-07-16 19:17
211 查看
date: 2014-10-31 12:16
切换的时机:在什么时候进行切换
调度策略(policy):根据什么准则挑选下一个进行运行的进程
调度的方式:是可剥夺(preemptive)还是不可剥夺(nonpreemptive)。当正在运行的进程没有觉悟自愿放弃对CPU的使用权时,是否可以强制性的暂时剥夺其使用权,停止其运行而给其他进程一个机会?如果可剥夺,是否任何条件下都可剥夺,有没有例外?
那么linux内核的调度机制是怎样的呢?先来看看进程状态转换关系示意图:
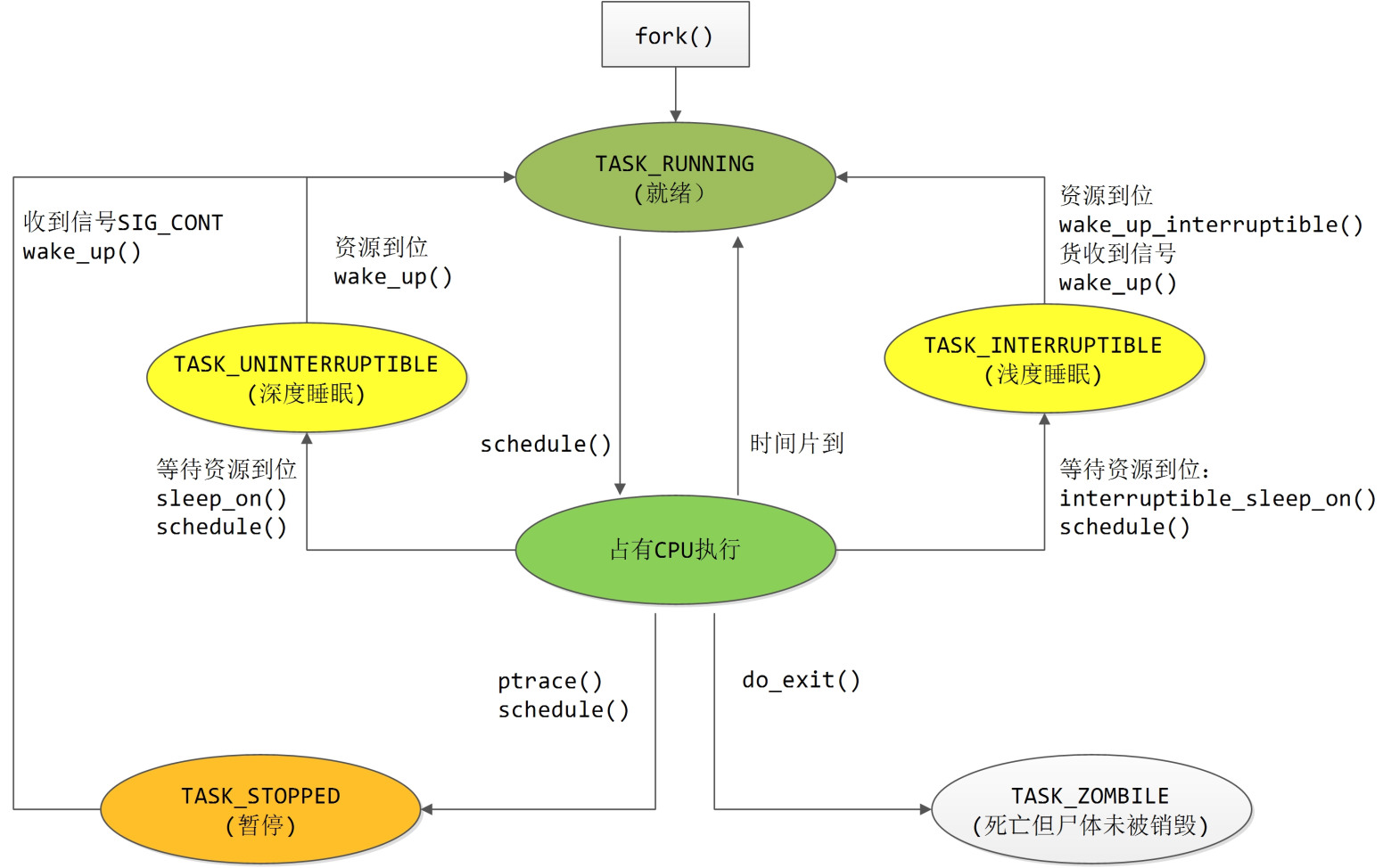
此外,如果一个进程运行太长时间,调度器可能会进行一次强制调度。非自愿的被强制的调度(发生在每次从系统调用返回到用户空间的前夕,以及每次从中断或异常处理返回到用户空间的前夕。注意这里的“返回到用户空间的前夕”的限定,对系统调用来说,肯定是返回到用户空间了;对中断或异常来说,它有可能发生在用户空间(当进程在用户空间运行时中断来了),也可能发生在内核空间(即当进程陷入内核后,中断来了),那么中断有可能返回到用户空间也有可能返回到内核空间。有了这个限定以后,只有当在用户空间发生的中断,其返回到用户空间前夕,才会进行一次强制调度;而在内核空间发生的中断,其返回时不会进行强转调度。这就给内核的设计与实现带来了便利。想想看,如果没有这个限定的话,在内核空间中,当前进程可能因为中断而被强转换出,其正在使用的资源可能会被新运行的进程所修改,这样一来,所有在进程间共享的数据都要通过互斥来保护了,这种多进程共享的数据何其多矣,加不胜加呀。
还要指明,强制调度还有一个条件,那就是当前进程task_struct结构的need_resched字段被置1(前面讲fork流程时,父进程将自己的need_resched置1,因此,从fork返回时会发生一次强制性调度),那么谁来设置该字段了,自然只有内核了,用户空间无法访问到task_struct结构的。什么情况下设置该字段呢?其一,在某些系统调用的内核实现中设置,比如系统调用pause、fork中,还有其他调用可能受阻的系统调中;其二在时钟中断服务程序中,发现当前进程运行太久时设置;其三,内核中因某种原因唤醒一个进程时。
那么,剥夺式的调用发生在什么时候呢?同样是进程从系统空间返回用户空间的前夕。
其实,这里讨论“有条件可剥夺”与前面的调度时机是密切相关的,剥夺式的调度即非自愿的强制调度,它剥夺当前进程的运行权利而让其他进程运行。
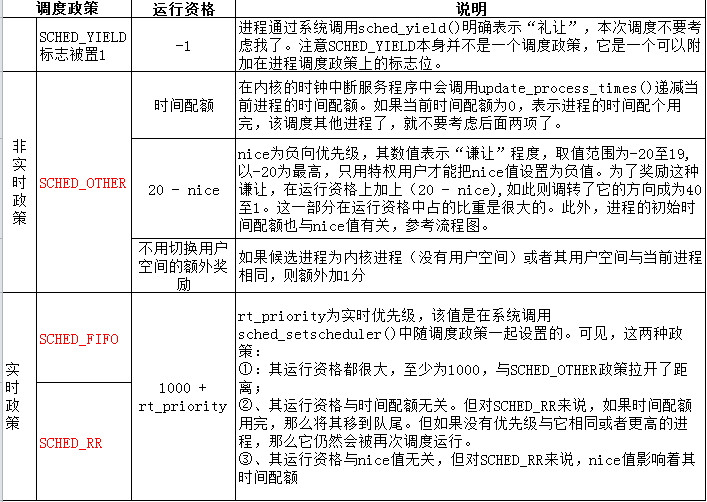
为了适应不同的需求,内核实现了三种不同的政策:SCHED_FIFO、SCHED_RR以及SCHED_OTHER。SCHED_FIFO适应于实时性要求比较强、而每次运行的耗时又比较短的进程;SCHED_RR适用于实时性要求较高但每次运行耗时较长的进程,其中的RR表示“Round Robin”即轮流之意,意即当多个进程具有同一优先级时,轮流调度运行;SCHED_OTHER则为传统的调度政策,适用与交互式的分时应用。
既然每个进程都有自己使用的调度政策,那么在计算运行资格时涉及到“归一化”的问题,即在计算资格时将政策也考虑进去,就像高考时,给符合某条件的考生加分一样。计算资格的函数为goodness,我们在后面会详细讲到。
本小节我们来看看schedule的流程,其定义在<kernel/sched.c>文件中,流程图如下(源代码里用了大量的goto 语句,这里为了描述方便,在不影响流程的情况下,省略对这些跳转描述):
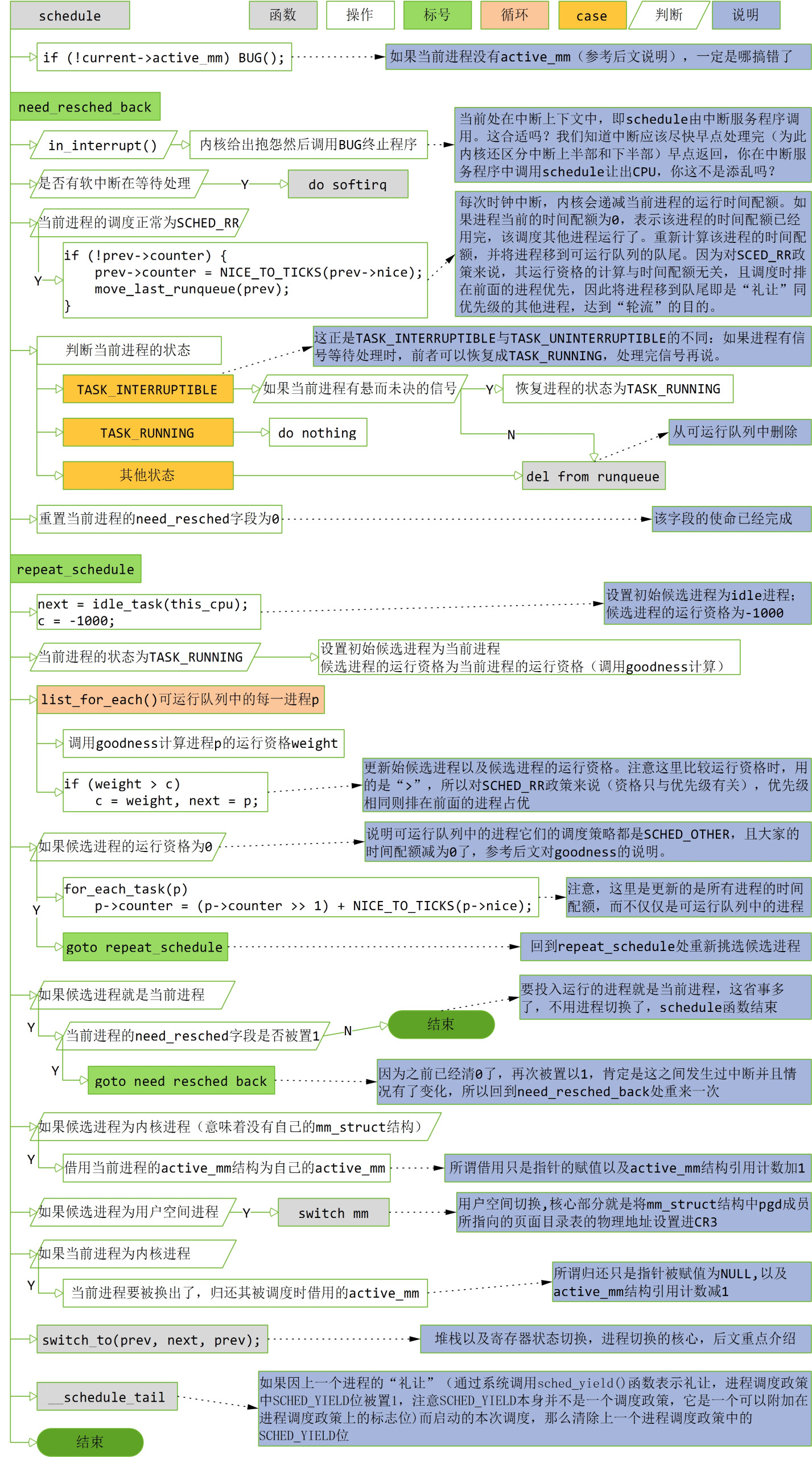
为什么必须要有一个active_mm?因为指向页面映射目录表的指针pgd就在这个结构中,内核进程不是没有用户空间吗,它要pgd何用?不要忘了,目录表中除了有用户空间的虚存页面映射,还有内核空间的虚存页面映射,参考第2章第6节。
在单CPU系统中,__cpu为0。在中断服务的入口和出口出,分别会调用irq_enter()和irq_exit()来递增和递减计数器local_irq_count[__cpu],只要这个计数器非0,就说明CPU在中断服务程序中还未离开。类似的,只要计数器local_bh_count[__cpu]非0就说明CPU在执行某个bh函数。就像停车场,每开入一辆车计算加1,每开出一辆车计数器减1,如果这个计数器非0,则说明停车场内还有车。
这个函数比较简单,不同调度政策运行资格的计算可参考如下表格:
回到流程图中,如果遍历完可运行队列中所有的进程,那么候选进程的运行资格c的值有如下几种可能:

为进程重新分配时间配的代码如下:
宏NICE_TO_TICKS的定义如下。参考注释,作者的意图是希望NICE_TO_TICKS得到的时间片在50ms左右,因此需要根据时钟频率HZ来定义。比如,如果HZ为200,表示每秒中断200次,那么一个滴答tick为5ms,20-(nice)的取值为[1 ,40],平均值为20,将20右移1位即除以2为10,10个滴答即50ms。当时钟频率HZ越高,每个滴答所代表的时间越短,NICE_TO_TICKS分配的滴答数越多,但最大只是20-(nice)的值左移2位即乘以4,极大值为160,这是无法与实时调度政策中最低运行资格为1000相抗衡的。
另外,需要说明,在重新计算时间配额时,对所有进程都进行了更新。而且更新是将原有配额除以2再加上NICE_TO_TICKS。那么那些不在可运行队列中的调度政策为SCHED_OTHER的进程,会因此获得较高的时间配额,在将来的调度中会占一定的优势。但这种更新方式也决定了更新后的时间配额不会超过两倍的NICE_TO_TICKS。因此即使调度政策为SCHED_OTHER的进程经过长期的“韬光养晦”,其运行资格也无法超过实时调度政策的进程。
switch_to()有三个参数,schedule()调用它时,第一个和第三个参数传入的是当前进程,即要被调度器换出的进程,设为进程A,第二个参数传入的是候选进程,及要被调度器调度运行的进程,设为进程B,我们用三步法来分析下这段代码:
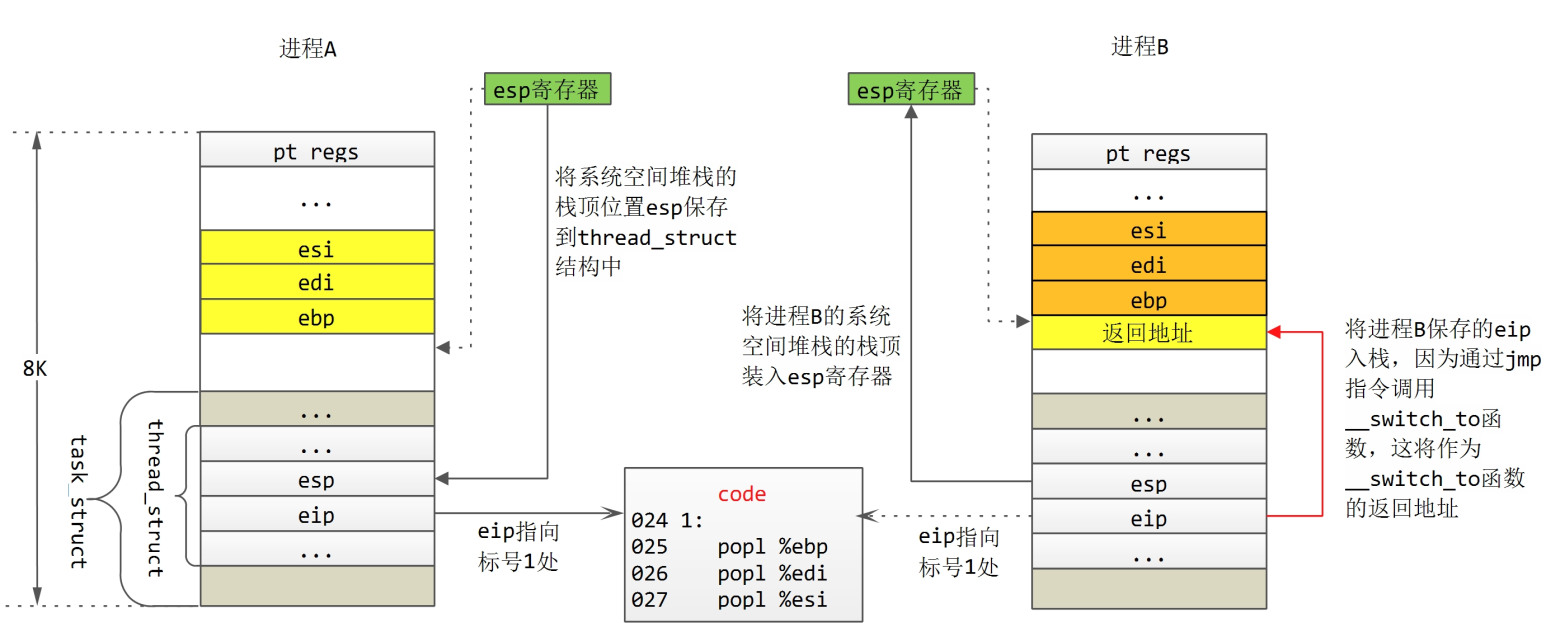
代码的意图请参考注释。这段代码对进程A与进程B的操作如下图所示:
我们再来逐行说明下:
第16~18行,备份寄存器esi、edi与ebp到进程A的系统空间堆栈中;第19行,将进程A系统空间堆栈的栈顶位置备份到其task_struct结构下属的thread_struct结构中;
第20行,将进程B备份的系统空间堆栈栈顶位置装载进esp寄存器,这样便完成了系统空间堆栈的切换,此时current宏所代表的进程就是进程B了。我们以动态的眼光来看,进程B之前肯定也被换出过,也曾做过“进程A”,意即也曾“趟过”第16~19行代码,那么其系统空间堆栈中肯定已经备份了寄存器esi、edi与ebp,而其esp指向备份寄存器后的栈顶(这里有一例外,就是fork产生的子进程初次运行时,见后文分析)。
第21行,设置进程A系统空间的eip(同样存储在task_struct结构下属的thread_struct结构中)为标号1的地址。进程A被暂停运行,下一次被调度运行,将从标号1处开始执行(参考后续分析)。
第22行,进程B的eip入栈。同样,用动态的眼光来看,进程B的备份的eip也指向标号1处。注意,这里有一个例外,那就是fork产生的子进程。还记得fork系统调用中的copy_thread()函数吗,在该函数中将子进程的eip设置为ret_from_fork(定义在<arch/i386/kernel/entry.s>中的第179行)。
第23行,通过jmp指令调用__switch_to()函数,由于不是通过call指令来调用子函数(call指令调用子函数时,会将子函数的返回地址即call指令的下一条指令的地址入栈),那么第22行入栈的eip即为__switch_to()函数的返回地址。那么当从__switch_to()返回后,进程B接着从标号1处开始执行。
我们来看看B进程的执行路径:
25行~27行,寄存器出栈,这与16~18行相对应。由于switch_to()本身是个宏,编译后“内嵌”到schedule()函数中。所以接下来进程B继续在schedule()函数中执行,直到schedule()函数结束后返回。
进程B从schedule()函数返回时,要从B进程的系统空间堆栈弹出返回地址。用动态的眼光来看,B进程当初被暂停运行时,肯定也曾调用过schedule(有一个特例,fork系统调用产生的子进程,下文详述),系统空间堆栈中肯定保存着schedule()的返回地址。如果进程B当初在内核代码中主动调用schecule(),那么现在将回到schedule()的下一条代码执行;
如果进程B当初是在从系统空间返回用户空间前夕被强制调用了schedule(),那么这时将会回到<arch/i386/kernel/entry.s>中的第289行(见下),调用ret_from_sys_call恢复进程B用户空间的现场(从进程B系统空间堆栈顶部的pt_regs处恢复),进程B就回到它的用户空间继续运行了。
我们再来看看fork产生的子进程首次被调度运行时的运行路线:
第22行,进程B的eip入栈。进程的eip被设置为ret_from_fork();
第23行,通过jmp指令调用__switch_to()函数。__switch_to()函数的返回地址即为ret_from_fork()函数的入口,那么当从__switch_to()函数返回时,直接跳转到ret_from_fork()处执行,继而跳转到ret_from_sys_call处,到达ret_with_reschedule时,由于子进程的need_resched字段为0,那么就直接返回到用户空间了。这部分代码在<arch/i386/kernel/entry.s>中第205行到223行。
fork产生的子进程初次被调度时,没有执行switch_to()的第25行到27行,也不涉及从schedule()函数中返回,它“抄了一段近路”直接到跳转至ret_from_fork(),然后返回到用户空间。
至于函数__switch_to(),那只是内核“应付”intel的“硬”任务切换。intel支持由CPU硬件来实施任务切换(核心是TSS),但linux并不买账。因为这个“大而全”硬件切换一是缺少灵活性,二是切换速度不一定快(因为有很多多余的切换动作)。
1 linux的调度机制
在讨论进程的调度与切换时,我们关注如下几个问题:切换的时机:在什么时候进行切换
调度策略(policy):根据什么准则挑选下一个进行运行的进程
调度的方式:是可剥夺(preemptive)还是不可剥夺(nonpreemptive)。当正在运行的进程没有觉悟自愿放弃对CPU的使用权时,是否可以强制性的暂时剥夺其使用权,停止其运行而给其他进程一个机会?如果可剥夺,是否任何条件下都可剥夺,有没有例外?
那么linux内核的调度机制是怎样的呢?先来看看进程状态转换关系示意图:
1.1 调度的时机分两种情况
首先自愿的调度随时都可以进行。在内核空间中,一个进程可以随时通过调用schedule来启动一次调度。在用户空间中,进程可以通过系统调用pause来自愿让出cpu从而启动一次调度。从应用的角度来看,只有在用户空间自愿放弃(pause系统调用以及nanosleep系统调用,注意sleep不是系统调用而是C库函数)这一举动是可见的;而进程陷入内核后的自愿放弃行为是不可见的,它隐藏在其他可能受阻的系统调用,比如open、read、write等。进程因这些系统调用而陷入内核,如果这些调用被阻塞,总不能让CPU阻塞在这里啥都不干吧,于是内核就替进程做主,自愿放弃CPU启动一次调度。此外,如果一个进程运行太长时间,调度器可能会进行一次强制调度。非自愿的被强制的调度(发生在每次从系统调用返回到用户空间的前夕,以及每次从中断或异常处理返回到用户空间的前夕。注意这里的“返回到用户空间的前夕”的限定,对系统调用来说,肯定是返回到用户空间了;对中断或异常来说,它有可能发生在用户空间(当进程在用户空间运行时中断来了),也可能发生在内核空间(即当进程陷入内核后,中断来了),那么中断有可能返回到用户空间也有可能返回到内核空间。有了这个限定以后,只有当在用户空间发生的中断,其返回到用户空间前夕,才会进行一次强制调度;而在内核空间发生的中断,其返回时不会进行强转调度。这就给内核的设计与实现带来了便利。想想看,如果没有这个限定的话,在内核空间中,当前进程可能因为中断而被强转换出,其正在使用的资源可能会被新运行的进程所修改,这样一来,所有在进程间共享的数据都要通过互斥来保护了,这种多进程共享的数据何其多矣,加不胜加呀。
还要指明,强制调度还有一个条件,那就是当前进程task_struct结构的need_resched字段被置1(前面讲fork流程时,父进程将自己的need_resched置1,因此,从fork返回时会发生一次强制性调度),那么谁来设置该字段了,自然只有内核了,用户空间无法访问到task_struct结构的。什么情况下设置该字段呢?其一,在某些系统调用的内核实现中设置,比如系统调用pause、fork中,还有其他调用可能受阻的系统调中;其二在时钟中断服务程序中,发现当前进程运行太久时设置;其三,内核中因某种原因唤醒一个进程时。
1.2 调度方式为“有条件可剥夺”方式
当进程在用户空间中运行时,不管自愿不自愿,一旦有必要(比如运行太长时间),内核就可以暂时剥夺其运行转而调度其他进程运行。可是,一旦进程进入内核空间,就像进入“安全地带”,这时,尽管内核知道要调度了,也只能干等着,等待进程离开“安全地带”返回用户空间前夕将其剥夺。因此说,linux的调度方式是可剥夺的,但由于剥夺时机的限制而变成有条件可剥夺的了。那么,剥夺式的调用发生在什么时候呢?同样是进程从系统空间返回用户空间的前夕。
其实,这里讨论“有条件可剥夺”与前面的调度时机是密切相关的,剥夺式的调度即非自愿的强制调度,它剥夺当前进程的运行权利而让其他进程运行。
1.3 调度政策
调度政策为以优先级为基础的调度。内核为每个进程计算出一个反应其运行资格的权值,然后挑选权值最高的进程投入运行。而资格的运算则是以优先级为基础。为了适应不同的需求,内核实现了三种不同的政策:SCHED_FIFO、SCHED_RR以及SCHED_OTHER。SCHED_FIFO适应于实时性要求比较强、而每次运行的耗时又比较短的进程;SCHED_RR适用于实时性要求较高但每次运行耗时较长的进程,其中的RR表示“Round Robin”即轮流之意,意即当多个进程具有同一优先级时,轮流调度运行;SCHED_OTHER则为传统的调度政策,适用与交互式的分时应用。
既然每个进程都有自己使用的调度政策,那么在计算运行资格时涉及到“归一化”的问题,即在计算资格时将政策也考虑进去,就像高考时,给符合某条件的考生加分一样。计算资格的函数为goodness,我们在后面会详细讲到。
2 schedule函数流程以及进程切换过程
2.1 主要流程
在exit一节中,一个即将去世的进程在do_exit中的最后一件事就是调用schedule自愿让出CPU,这是自愿调度的情形;此外,每当系统调用(或者是中断)返回到用户空间的前夕,内核会检查当前进程的need_resched字段,如果该字段非0,则调用schedule()进行一次强制性调度(这部分代码在<arch/i386/kernel/entry.s>中),这是强制调度的情形。本小节我们来看看schedule的流程,其定义在<kernel/sched.c>文件中,流程图如下(源代码里用了大量的goto 语句,这里为了描述方便,在不影响流程的情况下,省略对这些跳转描述):
2.2 active_mm
进程的task_struct结构中有两个mm_struct结构指针:一个是mm,指向进程的用户空间,另一个是active_mm。对于具有用户空间的进程这两个指针是一致的(比如在execve系统调用中会设置成一致,参考exec_mmap函数的详细代码);但是当一个不具备用户空间的内核进程被调度运行时,要求它必须有一个active_mm,所以只好借用一个。问谁借呢,最简单就是为借用当前进程(即将被换出的进程)的active_mm(当前进程也可能是是个内核进程,它的active_mm也可能是借来的),因为这样可以省去用户空间切换的开销,而在该进程被换成停止运行时,要记得归还它借来的active_mm。为什么必须要有一个active_mm?因为指向页面映射目录表的指针pgd就在这个结构中,内核进程不是没有用户空间吗,它要pgd何用?不要忘了,目录表中除了有用户空间的虚存页面映射,还有内核空间的虚存页面映射,参考第2章第6节。
2.3 中断上下文
schedule只能由进程在内核空间中主动调用,或者在当进程从系统空间返回到用户空间前夕被动地调用,而不能在一个中断服务程序内部调用。即使一个中断服务程序有调度的要求,也只能通过设置当前进程的need_resched字段为1来表达这种需求,而不能直接调用schedule。那么怎么判断当前处在中断上下文(即在中断服务程序里还没出来)呢?我们来看看in_interrupt的定义。<include/asm/hardirq.h>
20 /*
21 * Are we in an interrupt context? Either doing bottom half
22 * or hardware interrupt processing?
23 */
24 #define in_interrupt() ({ int __cpu = smp_processor_id(); \
25 (local_irq_count(__cpu) + local_bh_count(__cpu) != 0); })在单CPU系统中,__cpu为0。在中断服务的入口和出口出,分别会调用irq_enter()和irq_exit()来递增和递减计数器local_irq_count[__cpu],只要这个计数器非0,就说明CPU在中断服务程序中还未离开。类似的,只要计数器local_bh_count[__cpu]非0就说明CPU在执行某个bh函数。就像停车场,每开入一辆车计算加1,每开出一辆车计数器减1,如果这个计数器非0,则说明停车场内还有车。
2.4 goodness函数以及进程运行资格的计算
/*
* This is the function that decides how desirable a process is..
* You can weigh different processes against each other depending
* on what CPU they've run on lately etc to try to handle cache
* and TLB miss penalties.
*
* Return values:
* -1000: never select this
* 0: out of time, recalculate counters (but it might still be selected)
* +ve: "goodness" value (the larger, the better)
* +1000: realtime process, select this.
*/
static inline int goodness(struct task_struct * p, int this_cpu, struct mm_struct *this_mm)
{
int weight;
/*
* select the current process after every other
* runnable process, but before the idle thread.
* Also, dont trigger a counter recalculation.
*/
weight = -1;
if (p->policy & SCHED_YIELD)
goto out;
/*
* Non-RT process - normal case first.
*/
if (p->policy == SCHED_OTHER) {
/*
* Give the process a first-approximation goodness value
* according to the number of clock-ticks it has left.
*
* Don't do any other calculations if the time slice is
* over..
*/
weight = p->counter;
if (!weight)
goto out;
/* .. and a slight advantage to the current MM */
if (p->mm == this_mm || !p->mm)
weight += 1;
weight += 20 - p->nice;
goto out;
}
/*
* Realtime process, select the first one on the
* runqueue (taking priorities within processes
* into account).
*/
weight = 1000 + p->rt_priority;
out:
return weight;
}这个函数比较简单,不同调度政策运行资格的计算可参考如下表格:
回到流程图中,如果遍历完可运行队列中所有的进程,那么候选进程的运行资格c的值有如下几种可能:
为进程重新分配时间配的代码如下:
for_each_task(p) p->counter = (p->counter >> 1) + NICE_TO_TICKS(p->nice);
宏NICE_TO_TICKS的定义如下。参考注释,作者的意图是希望NICE_TO_TICKS得到的时间片在50ms左右,因此需要根据时钟频率HZ来定义。比如,如果HZ为200,表示每秒中断200次,那么一个滴答tick为5ms,20-(nice)的取值为[1 ,40],平均值为20,将20右移1位即除以2为10,10个滴答即50ms。当时钟频率HZ越高,每个滴答所代表的时间越短,NICE_TO_TICKS分配的滴答数越多,但最大只是20-(nice)的值左移2位即乘以4,极大值为160,这是无法与实时调度政策中最低运行资格为1000相抗衡的。
/* * Scheduling quanta. * * NOTE! The unix "nice" value influences how long a process * gets. The nice value ranges from -20 to +19, where a -20 * is a "high-priority" task, and a "+10" is a low-priority * task. * * We want the time-slice to be around 50ms or so, so this * calculation depends on the value of HZ. */ #if HZ < 200 #define TICK_SCALE(x) ((x) >> 2) #elif HZ < 400 #define TICK_SCALE(x) ((x) >> 1) #elif HZ < 800 #define TICK_SCALE(x) (x) #elif HZ < 1600 #define TICK_SCALE(x) ((x) << 1) #else #define TICK_SCALE(x) ((x) << 2) #endif #define NICE_TO_TICKS(nice) (TICK_SCALE(20-(nice))+1)
另外,需要说明,在重新计算时间配额时,对所有进程都进行了更新。而且更新是将原有配额除以2再加上NICE_TO_TICKS。那么那些不在可运行队列中的调度政策为SCHED_OTHER的进程,会因此获得较高的时间配额,在将来的调度中会占一定的优势。但这种更新方式也决定了更新后的时间配额不会超过两倍的NICE_TO_TICKS。因此即使调度政策为SCHED_OTHER的进程经过长期的“韬光养晦”,其运行资格也无法超过实时调度政策的进程。
2.5 switch_to
任务切换的核心为switch_to,这是一段嵌入式汇编代码,定义在<include/asm/system.h>文件中:#define switch_to(prev,next,last) do { \
asm volatile("pushl %%esi\n\t" \
"pushl %%edi\n\t" \
"pushl %%ebp\n\t" \
"movl %%esp,%0\n\t" /* save ESP */ \
"movl %3,%%esp\n\t" /* restore ESP */ \
"movl $1f,%1\n\t" /* save EIP */ \
"pushl %4\n\t" /* restore EIP */ \
"jmp __switch_to\n" \
"1:\t" \
"popl %%ebp\n\t" \
"popl %%edi\n\t" \
"popl %%esi\n\t" \
:"=m" (prev->thread.esp),"=m" (prev->thread.eip), \
"=b" (last) \
:"m" (next->thread.esp),"m" (next->thread.eip), \
"a" (prev), "d" (next), \
"b" (prev)); \
} while (0)switch_to()有三个参数,schedule()调用它时,第一个和第三个参数传入的是当前进程,即要被调度器换出的进程,设为进程A,第二个参数传入的是候选进程,及要被调度器调度运行的进程,设为进程B,我们用三步法来分析下这段代码:
;伪寄存器 ; prev->thread.esp --> r0 ; prev->thread.eip --> r1 ; last --> r2 ; next->thread.esp --> r3 ; next->thread.eip --> r4 ;伪寄存器与通用寄存器结合的"建议" ; prev --> eax ; netx --> edx ; prev --> ebx 016 pushl %esi /*在A进程的系统空间堆栈中进行入栈操作*/ 017 pushl %edi 018 pushl %ebp 019 movl %esp, r0 /*保存A进程系统空间堆栈的栈顶指针esp到其task_struct 结构的thread成员中*/ 020 movl r3, %esp /*从B进程task_struct结构的thread成员中恢复B进程的 系统空间堆栈esp,执行该指令之后,系统空间堆栈已经切换 到了B进程的系统空间堆栈 */ 021 move $lf, r1 /*设置A进程下一次调度执行时系统空间eip为标号1的地址 (保存到A进程task_struct结构的thread成员中)*/ 022 push r4 /*B进程系统空间的eip入栈(此时,当然是B进程的系统空间 堆栈) */ 023 jmp __switch_to /*这里通过jmp而不是call调用函数__switch_to,于是 __switch_to函数的返回地址就上上条指令压入的r4,即 进程B系统空间的eip*/ 024 1: 025 popl %ebp /*在B进程的系统空间堆栈中进行出栈操作*/ 026 popl %edi 027 popl %esi
代码的意图请参考注释。这段代码对进程A与进程B的操作如下图所示:
我们再来逐行说明下:
第16~18行,备份寄存器esi、edi与ebp到进程A的系统空间堆栈中;第19行,将进程A系统空间堆栈的栈顶位置备份到其task_struct结构下属的thread_struct结构中;
第20行,将进程B备份的系统空间堆栈栈顶位置装载进esp寄存器,这样便完成了系统空间堆栈的切换,此时current宏所代表的进程就是进程B了。我们以动态的眼光来看,进程B之前肯定也被换出过,也曾做过“进程A”,意即也曾“趟过”第16~19行代码,那么其系统空间堆栈中肯定已经备份了寄存器esi、edi与ebp,而其esp指向备份寄存器后的栈顶(这里有一例外,就是fork产生的子进程初次运行时,见后文分析)。
第21行,设置进程A系统空间的eip(同样存储在task_struct结构下属的thread_struct结构中)为标号1的地址。进程A被暂停运行,下一次被调度运行,将从标号1处开始执行(参考后续分析)。
第22行,进程B的eip入栈。同样,用动态的眼光来看,进程B的备份的eip也指向标号1处。注意,这里有一个例外,那就是fork产生的子进程。还记得fork系统调用中的copy_thread()函数吗,在该函数中将子进程的eip设置为ret_from_fork(定义在<arch/i386/kernel/entry.s>中的第179行)。
第23行,通过jmp指令调用__switch_to()函数,由于不是通过call指令来调用子函数(call指令调用子函数时,会将子函数的返回地址即call指令的下一条指令的地址入栈),那么第22行入栈的eip即为__switch_to()函数的返回地址。那么当从__switch_to()返回后,进程B接着从标号1处开始执行。
我们来看看B进程的执行路径:
25行~27行,寄存器出栈,这与16~18行相对应。由于switch_to()本身是个宏,编译后“内嵌”到schedule()函数中。所以接下来进程B继续在schedule()函数中执行,直到schedule()函数结束后返回。
进程B从schedule()函数返回时,要从B进程的系统空间堆栈弹出返回地址。用动态的眼光来看,B进程当初被暂停运行时,肯定也曾调用过schedule(有一个特例,fork系统调用产生的子进程,下文详述),系统空间堆栈中肯定保存着schedule()的返回地址。如果进程B当初在内核代码中主动调用schecule(),那么现在将回到schedule()的下一条代码执行;
如果进程B当初是在从系统空间返回用户空间前夕被强制调用了schedule(),那么这时将会回到<arch/i386/kernel/entry.s>中的第289行(见下),调用ret_from_sys_call恢复进程B用户空间的现场(从进程B系统空间堆栈顶部的pt_regs处恢复),进程B就回到它的用户空间继续运行了。
287 reschedule: 288 call SYMBOL_NAME(schedule) # test 289 jmp ret_from_sys_call
我们再来看看fork产生的子进程首次被调度运行时的运行路线:
第22行,进程B的eip入栈。进程的eip被设置为ret_from_fork();
第23行,通过jmp指令调用__switch_to()函数。__switch_to()函数的返回地址即为ret_from_fork()函数的入口,那么当从__switch_to()函数返回时,直接跳转到ret_from_fork()处执行,继而跳转到ret_from_sys_call处,到达ret_with_reschedule时,由于子进程的need_resched字段为0,那么就直接返回到用户空间了。这部分代码在<arch/i386/kernel/entry.s>中第205行到223行。
fork产生的子进程初次被调度时,没有执行switch_to()的第25行到27行,也不涉及从schedule()函数中返回,它“抄了一段近路”直接到跳转至ret_from_fork(),然后返回到用户空间。
至于函数__switch_to(),那只是内核“应付”intel的“硬”任务切换。intel支持由CPU硬件来实施任务切换(核心是TSS),但linux并不买账。因为这个“大而全”硬件切换一是缺少灵活性,二是切换速度不一定快(因为有很多多余的切换动作)。

相关文章推荐
- 进程调度与切换简单总结
- linux进程调度、进程切换原理详解
- Linux进程调度和切换过程分析
- x86体系结构下Linux-2.6.26的进程调度和切换
- Linux 进程调度、切换的分析
- x86体系结构下Linux-2.6.26的进程调度和切换
- Linux进程上下文切换过程context_switch详解--Linux进程的管理与调度(二十一)
- 时间系统、进程的调度与切换
- 【进程管理】进程的调度与切换
- Linux进程调度切换和虚拟空间管理深入分析
- Linux进程调度和切换过程分析
- 通过gdb跟踪进程调度分析进程切换的过程
- Linux进程调度和切换过程分析
- 初学Linux中进程调度与进程切换过程
- Linux进程调度与切换
- 操作系统--进程状态切换以及cpu调度(转)
- linux 进程调度切换过程分析
- 通过gdb跟踪进程调度分析进程切换的过程
- linux进程管理之调度与切换
- Linux内核分析:实验八--Linux进程调度与切换