进程调度之3:系统调用fork、vfork与clone
2018-07-15 23:26
369 查看
date: 2014-10-22 17:40
fork是全面的复制。
vfork创建一个线程,但主要用作创建进程的中间步骤。既然新的进程最终要调用execve执行新的目标程序,并与父进程分道扬镳,那么复制父进程的资源完全是多余的,于是vfork便应运而生,其创建一个线程并通过指针拷贝共享父进程的资源(这些资源会在execve中被替换)。
vfork与fork的另一个不同是,vfork会保证子进程先运行,在子进程执行execve或者exit之后,父进程才可能被调度运行。
clone可以用来创建一个线程,并可以指定子线程的用户空间堆栈的起始位置(child_stack参数)以及自线程的入口(参数fn)。同时clone也可以用来创建一个进程,有选择性的复制父进程的资源(由参数flag来指定)。
这几个系统调用在内核中的实现如下(2.4.0内核)
可见这几个系统调用最终都是以不同的参数调用do_fork。这三个函数参数中的pt_regs结构是系统调用陷入内核空间后,对用户空间中CPU各通用寄存器的备份。对sys_clone来说,regs.ebx保存的是clone的参数flag(flag是第三个参数,不是应该保存在edx中吗?),regs.ecx保存的就是clone的参数child_task。
do_fork函数的原型为:
第一个参数clone_flags包含两部分,第一部分为其最低的字节(8bit)表示信号类型,表示子进程去世时内核应该给其父进程发什么信号。fork和vfork设置的信号为SIGCHILD,而clone则由调用者决定发什么信号。
第二部分是一些表示资源或者特性的标志位,这些标志位定义在<include/linux/sched.h>文件中:
这里的标志位如果为1则表示对应的资源通过指针拷贝(“浅拷贝”)的方式与父进程共享,反之如果为0则要进行深度拷贝了。其中CLONE_PID有特殊的用途,它表示父子进程共用同一进程号PID,也就是说子进程虽然有其自己的task_struct结构,却使用父进程的PID,但是只有0号进程(0号进程不是init进程,init进程的进程号为1,0号进程空转进程即idle进程)被允许如此调用clone。
对于fork,这部分全为0,表示所有的资源都要复制(“深拷贝”);而对vfork,其设置了CLONE_VFORK和CLONE_VM标志,表示子进程(线程)共用父进程(用户空间的)虚存空间,并且当子进程释放其虚存区间时,要通知父进程;至于clone,这一部分也由调用者设定。
下面分析下do_fork的流程,如果读者理解浅拷贝和深拷贝,那么复制的过程很好理解。
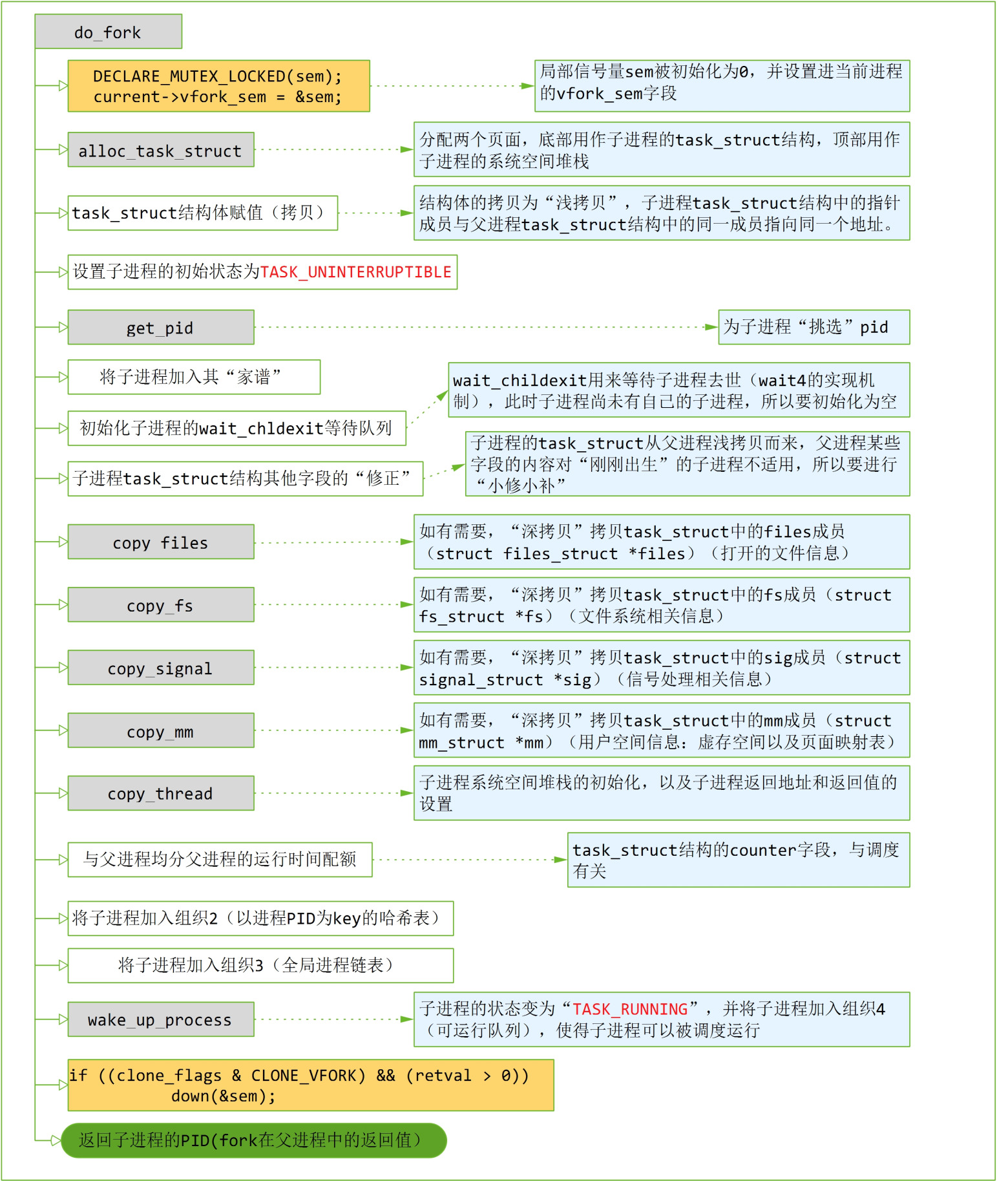
下面对流程中的重点函数进行详细介绍。
files_struct结构主要有三个部件:其一是个位图(指针)close_on_exec,表示在进程执行exce时需要close的文件描述符,初始指向结构体中另一个成员close_on_exec_init的地址;其二也是一个位图(指针)open_fds,初始指向结构体中另一成员open_fds_init的地址;其三为指向文件表项(struct file)指针数组的指针fd,指向进程打开的文件表项数组,初始指向结构体中另一成员fd_array的地址。由于位图(fd_set)能够表示最大文件描述符为1024(fd_set共有1024个bit),而fd_array数组的大小固定为NR_OPEN_DEFAULT,随着程序的运行,进程打开的文件数可能超过NR_OPEN_DEFAULT,或者fd_set(1024个bit)已经无法容纳最大的文件描述符,这个时候就需要对这个三个部件进行扩展,而这三个指针则指向结构体外的某个地址。
如有需要(clone_flag中对应的标志位为0,下同),copy_files将执行“深度拷贝”,这里“深度拷贝”主要是这三个部件的拷贝,在拷贝时要判断父进程的三个部件是否已进行过扩展,如果是则子进程的三个部件也要进行扩展。
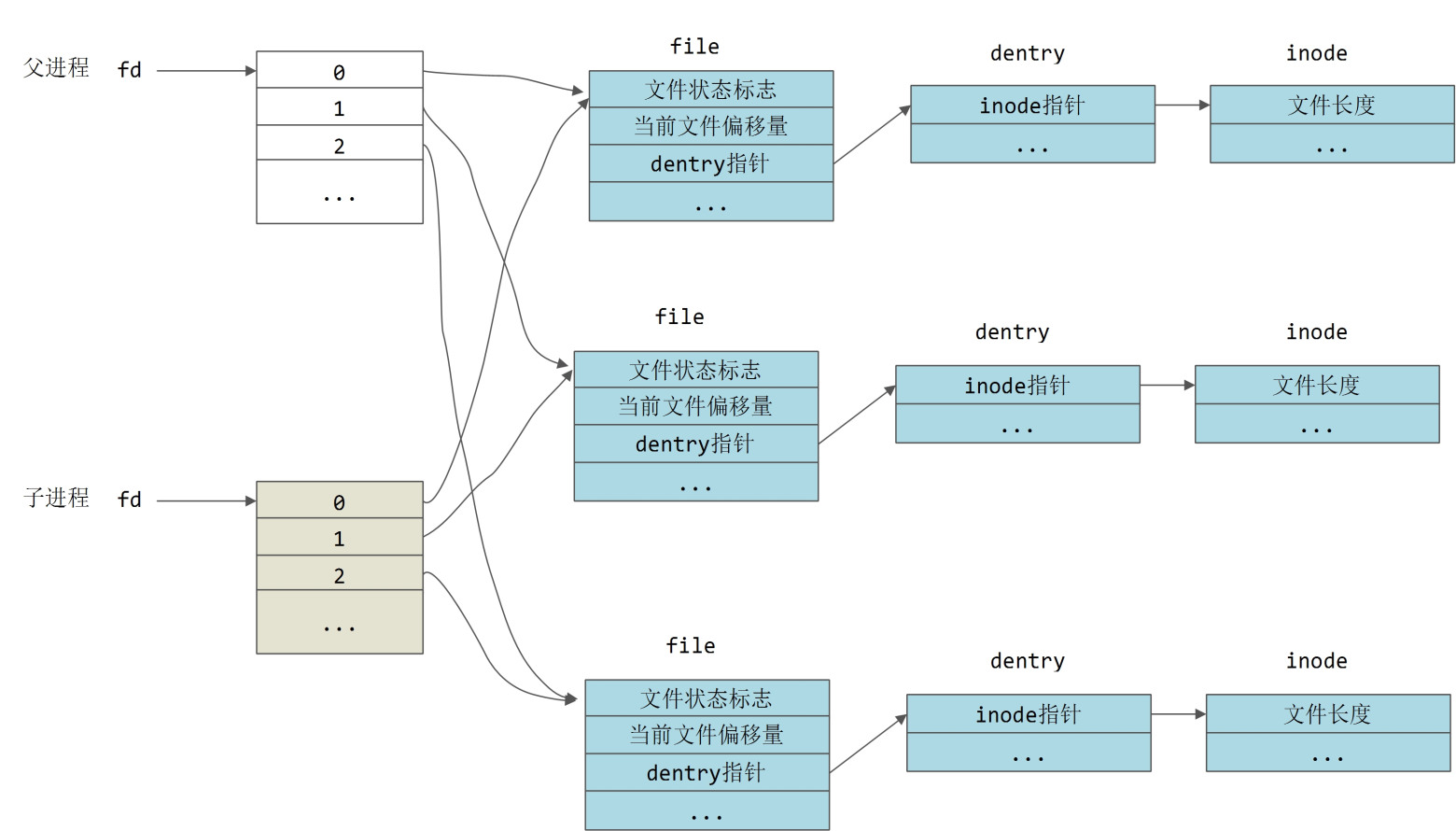
注意,这里所谓的“深度拷贝”只是中间层次的“深度拷贝”。以fd为例,fd为指向指针数组的指针,拷贝之后子进程有自己的一块存储空间,用来存放所有的文件表项(struct file)的指针,但是并未执行更深层次的拷贝,并没有对每个文件表项指针所指向的文件表项(struct file)进行拷贝。父子进程每个相同的文件描述符共享同一个文件表项 ,如下图所示:
可见,fork之后,当子进程通过lseek移动某个文件的“当前文件偏移量”时,由于这个偏移量记录在文件表项file中,父进程中对应文件的“当前文件偏移量”也会被更新,这就是在父子进程中同时往标准输出中打印信息时不会重叠的原因。罕见的,《情景分析》关于这一点的描述有误。
其核心成员action为一数组,指定了各个信号的处理方式。_NSIG即为信号的最大值64。copy_sighand所执行的深度拷贝就是将action数组拷贝一份到子进程。
注意,在拷贝页表时,只是为子进程的页表分配了存储空间,页面表项(pte_t)的内容与父进程一致。这意味着针对每一个页面表项,子进程并没有像我们想象的那样,重新申请一个page,从父进程那里拷贝一个page的内容,然后将新page的地址和保护属性写入页面表项。取而代之的做法是:子进程的页面表项仍然指向父进程中的page,只是将这个page的保护属性设置成“只读”,并将保护属性同时设置进父、子进程的页面表项中。这样的话,当不管父进程还是子进程企图写入这个页面时,都会触发异常页面异常,这种情况下,页面异常处理程序会重新分配一个page,并把内容复制过来,并更新父子进程的页面表项(将保护属性设置成可写),让父子进程拥有各自的物理page。这就是copy_on_write技术。linux之所以能快速的复制出一个进程,完全归功于copy on write技术(否则的话,在fork时,就得老老实实的分配一个一个的物理页面,并将页面的内容拷贝过来)。
pt_regs结构保存着进入内核前夕CPU各个寄存器的内容,这可是系统调用返回到用户空间的重要“现场”,对于刚刚出生的子进程,这些信息只能从父进程拷贝而来,也正因如此,父子进程才可以返回到用户空间的同一个地方。
copy_thread的代码比较有趣,我们来看看:
参数中的p指向新创建的子进程;而regs则来自父进程;esp指向进程用户空间的堆栈的栈顶,对fork与vfork而言,esp来自regs.esp即父进程的用户空间地址的栈顶,对clone而言,栈顶esp可有调用者指定。
首先,要确定在进程的系统空间中pt_regs结构的起始地址,这是535行的作用。逐步拆解如下:
(THREAD_SIZE + (unsigned long) p) 定位到子进程系统空间(8K)的上边界;
((struct pt_regs *) (THREAD_SIZE + (unsigned long) p)) 将系统空间的上边界强转成struct pt_regs类型的指针;
((struct pt_regs *) (THREAD_SIZE + (unsigned long) p)) – 1,在struct pt_regs类型的指针类型的指针上执行减1操作,指针后移sizeof(struct pt_regs)个存储单元,于是定位到pt_regs结构的起始地址。
其次,子进程的pt_regs拷贝自父进程(第536行),但也要进行些“修补”。第537行修改子进程在用户空间的返回值为0;第538行修改进程用户空间的栈顶esp。
另外,task_struct结构中有一个thread成员,其为struct thread_struct类型,里面存放着进程在切换时系统空间堆栈的栈顶esp、下一条指令eip(进程再次被切换运行时,将从这里开始运行)等关键信息。在复制task_struct结构时,这些内容原封不动从父进程拷贝过来,现在子进程有自己的系统空间堆栈了,所以要适当的加以调整。第540行将p->thread.esp设置成pt_regs结构的起始地址(注意堆栈是向下扩展的),从调度器的角度来看,就好像这个子进程以前曾经进入内核运行过,而在内核中的任务处理完毕(因此进程系统空间堆栈恢复平衡,变成“空”堆栈)准备返回用户空间时被切换了;而p->thread.esp0则应指向系统空间堆栈的顶端,表示这个进程进入0级(内核空间)运行时,其堆栈的位置。第543行,p->thread.eip被赋值为ret_from_fork,当子进程调度运行时(肯定先从系统空间运行),将从ret_from_fork处开始运行。
在子进程调用exec或者exit时,都会调用mm_release,在该函数中,up(tsk->p_opptr->vfork_sem)增加了父进程vfork_sem的计数,于是父进程被唤醒。
仔细想来,vfork保证子进程先运行,不见得是内核“精心”为linux用户实现的特性,倒像是内核的无奈之举。我们知道vfork系统调用,父子进程共享进程用户空间,子进程对用户空间的修改会反过来影响父进程,反之亦然。如果说父子进程各自修改数据区的数据是危险的话,那么修改堆栈那就是致命的了。而恰巧子进程紧接着就会调用exec(或者exit),而函数调用涉及到传参,涉及到设置返回地址这些都会修改堆栈。所以决不能让两个进程都回到用户空间并发的运行,必须扣留其中的一个,而只让一个返回到用户空间去运行,直到两个进程不再共享用户空间(子进程执行exec)或者其中之一消亡(必然是先返回用户空间的子进程)为止。
即使如此,也还是有危险,子进程绝对不能从调用vfork的那个函数(caller)中返回(比如vfork之后子进程调用return),因为函数返回时,栈会被恢复平衡,之前用来存放caller的函数参数和函数返回地址的内存单元被回收,之后,这些内存单元可能被用来存放其他的内容。等到子进程去世父进程开始运行时,虽然父进程虽然有自己的esp(保存在pt_regs中),但栈中保存的caller的返回地址被破坏了(esp之上的内容都被破坏),这是很危险的。所以vfork实际上是建立在子进程在创建后立即就会调用execve的前提之上的。
1 原型
前文已大致讲过fork、vfork与clone的区别,先来看看它们的原型:pid_t fork(void); pid_t vfork(void); int clone(int (*fn)(void *), void *child_stack, int flags, void* arg, ...);
fork是全面的复制。
vfork创建一个线程,但主要用作创建进程的中间步骤。既然新的进程最终要调用execve执行新的目标程序,并与父进程分道扬镳,那么复制父进程的资源完全是多余的,于是vfork便应运而生,其创建一个线程并通过指针拷贝共享父进程的资源(这些资源会在execve中被替换)。
vfork与fork的另一个不同是,vfork会保证子进程先运行,在子进程执行execve或者exit之后,父进程才可能被调度运行。
clone可以用来创建一个线程,并可以指定子线程的用户空间堆栈的起始位置(child_stack参数)以及自线程的入口(参数fn)。同时clone也可以用来创建一个进程,有选择性的复制父进程的资源(由参数flag来指定)。
这几个系统调用在内核中的实现如下(2.4.0内核)
<arch/kernel/process.c>
asmlinkage int sys_fork(struct pt_regs regs)
{
return do_fork(SIGCHLD, regs.esp, ®s, 0);
}
asmlinkage int sys_clone(struct pt_regs regs)
{
unsigned long clone_flags;
unsigned long newsp;
clone_flags = regs.ebx;
newsp = regs.ecx;
if (!newsp)
newsp = regs.esp;
return do_fork(clone_flags, newsp, ®s, 0);
}
asmlinkage int sys_vfork(struct pt_regs regs)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, regs.esp, ®s, 0);
}可见这几个系统调用最终都是以不同的参数调用do_fork。这三个函数参数中的pt_regs结构是系统调用陷入内核空间后,对用户空间中CPU各通用寄存器的备份。对sys_clone来说,regs.ebx保存的是clone的参数flag(flag是第三个参数,不是应该保存在edx中吗?),regs.ecx保存的就是clone的参数child_task。
do_fork函数的原型为:
int do_fork(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size);
第一个参数clone_flags包含两部分,第一部分为其最低的字节(8bit)表示信号类型,表示子进程去世时内核应该给其父进程发什么信号。fork和vfork设置的信号为SIGCHILD,而clone则由调用者决定发什么信号。
第二部分是一些表示资源或者特性的标志位,这些标志位定义在<include/linux/sched.h>文件中:
/* * cloning flags: */ #define CSIGNAL 0x000000ff /* signal mask to be sent at exit */ #define CLONE_VM 0x00000100 /* set if VM shared between processes */ #define CLONE_FS 0x00000200 /* set if fs info shared between processes */ #define CLONE_FILES 0x00000400 /* set if open files shared between processes */ #define CLONE_SIGHAND 0x00000800 /* set if signal handlers and blocked signals shared */ #define CLONE_PID 0x00001000 /* set if pid shared */ #define CLONE_PTRACE 0x00002000 /* set if we want to let tracing continue on the child too */ #define CLONE_VFORK 0x00004000 /* set if the parent wants the child to wake it up on mm_release */ #define CLONE_PARENT 0x00008000 /* set if we want to have the same parent as the cloner */ #define CLONE_THREAD 0x00010000 /* Same thread group? */ #define CLONE_SIGNAL (CLONE_SIGHAND | CLONE_THREAD)
这里的标志位如果为1则表示对应的资源通过指针拷贝(“浅拷贝”)的方式与父进程共享,反之如果为0则要进行深度拷贝了。其中CLONE_PID有特殊的用途,它表示父子进程共用同一进程号PID,也就是说子进程虽然有其自己的task_struct结构,却使用父进程的PID,但是只有0号进程(0号进程不是init进程,init进程的进程号为1,0号进程空转进程即idle进程)被允许如此调用clone。
对于fork,这部分全为0,表示所有的资源都要复制(“深拷贝”);而对vfork,其设置了CLONE_VFORK和CLONE_VM标志,表示子进程(线程)共用父进程(用户空间的)虚存空间,并且当子进程释放其虚存区间时,要通知父进程;至于clone,这一部分也由调用者设定。
下面分析下do_fork的流程,如果读者理解浅拷贝和深拷贝,那么复制的过程很好理解。
2 do_fork流程
2.1 总体流程图
下面对流程中的重点函数进行详细介绍。
2.2 get_pid
一般来讲,将上一个进程的PID加1即可得到新进程的PID,但系统中规定PID不能≥PID_MAX(PID_MAX 定义为0x8000,可见最大的PID号为0x7fff即32767)。如果PID≥PID_MAX,则要回过头去“捡漏”:某些进程已经去世了,之前分配给他们的PID可以重新利用了。注意捡漏要从PID为300开始扫描,因为300以内(0~299)的PID保留给系统进程使用(包括内核线程和各“守护神”进程)。如果扫描只为找到一个可用的PID,显然不划算,最好是能找到一个可用PID的区间(而不仅仅是找到第一个可用的PID)。这样下一次再创建进程时,直接从可用PID区间中取下一个PID即可。2.3 copy_files
task_struct结构有一个files成员,其为struct files_struct类型的指针,指向进程打开的文件的信息,copy_files函数完成该指针的深度拷贝。files_struct结构体的定义如下:/*
* Open file table structure
*/
struct files_struct {
atomic_t count;
rwlock_t file_lock;
int max_fds;
int max_fdset;
int next_fd;
struct file ** fd; /* current fd array */
fd_set *close_on_exec;
fd_set *open_fds;
fd_set close_on_exec_init;
fd_set open_fds_init;
struct file * fd_array[NR_OPEN_DEFAULT];
};files_struct结构主要有三个部件:其一是个位图(指针)close_on_exec,表示在进程执行exce时需要close的文件描述符,初始指向结构体中另一个成员close_on_exec_init的地址;其二也是一个位图(指针)open_fds,初始指向结构体中另一成员open_fds_init的地址;其三为指向文件表项(struct file)指针数组的指针fd,指向进程打开的文件表项数组,初始指向结构体中另一成员fd_array的地址。由于位图(fd_set)能够表示最大文件描述符为1024(fd_set共有1024个bit),而fd_array数组的大小固定为NR_OPEN_DEFAULT,随着程序的运行,进程打开的文件数可能超过NR_OPEN_DEFAULT,或者fd_set(1024个bit)已经无法容纳最大的文件描述符,这个时候就需要对这个三个部件进行扩展,而这三个指针则指向结构体外的某个地址。
如有需要(clone_flag中对应的标志位为0,下同),copy_files将执行“深度拷贝”,这里“深度拷贝”主要是这三个部件的拷贝,在拷贝时要判断父进程的三个部件是否已进行过扩展,如果是则子进程的三个部件也要进行扩展。
注意,这里所谓的“深度拷贝”只是中间层次的“深度拷贝”。以fd为例,fd为指向指针数组的指针,拷贝之后子进程有自己的一块存储空间,用来存放所有的文件表项(struct file)的指针,但是并未执行更深层次的拷贝,并没有对每个文件表项指针所指向的文件表项(struct file)进行拷贝。父子进程每个相同的文件描述符共享同一个文件表项 ,如下图所示:
可见,fork之后,当子进程通过lseek移动某个文件的“当前文件偏移量”时,由于这个偏移量记录在文件表项file中,父进程中对应文件的“当前文件偏移量”也会被更新,这就是在父子进程中同时往标准输出中打印信息时不会重叠的原因。罕见的,《情景分析》关于这一点的描述有误。
2.4 copy_sighand
task_struct结构中有一sig成员,其为struct signal_struct类型,后者的定义如下:struct signal_struct {
atomic_t count;
struct k_sigaction action[_NSIG];
spinlock_t siglock;
};其核心成员action为一数组,指定了各个信号的处理方式。_NSIG即为信号的最大值64。copy_sighand所执行的深度拷贝就是将action数组拷贝一份到子进程。
2.5 copy_mm
task_struct结构中有一个指针mm,相信大家已经很熟悉了,其为mm_struct结构类型,代表了进程的用户空间。mm_struct中用两个重要的成员,其一为vm_area_struct类型的指针mmap,代表着用户空间的所有“虚存空间”;其二为pgd,领衔着“虚存区间”的页面映射。相应的,copy_mm所执行的深度拷贝也包括两部分:“虚存区间”的拷贝和页面表的拷贝。注意,在拷贝页表时,只是为子进程的页表分配了存储空间,页面表项(pte_t)的内容与父进程一致。这意味着针对每一个页面表项,子进程并没有像我们想象的那样,重新申请一个page,从父进程那里拷贝一个page的内容,然后将新page的地址和保护属性写入页面表项。取而代之的做法是:子进程的页面表项仍然指向父进程中的page,只是将这个page的保护属性设置成“只读”,并将保护属性同时设置进父、子进程的页面表项中。这样的话,当不管父进程还是子进程企图写入这个页面时,都会触发异常页面异常,这种情况下,页面异常处理程序会重新分配一个page,并把内容复制过来,并更新父子进程的页面表项(将保护属性设置成可写),让父子进程拥有各自的物理page。这就是copy_on_write技术。linux之所以能快速的复制出一个进程,完全归功于copy on write技术(否则的话,在fork时,就得老老实实的分配一个一个的物理页面,并将页面的内容拷贝过来)。
2.6 copy_thread
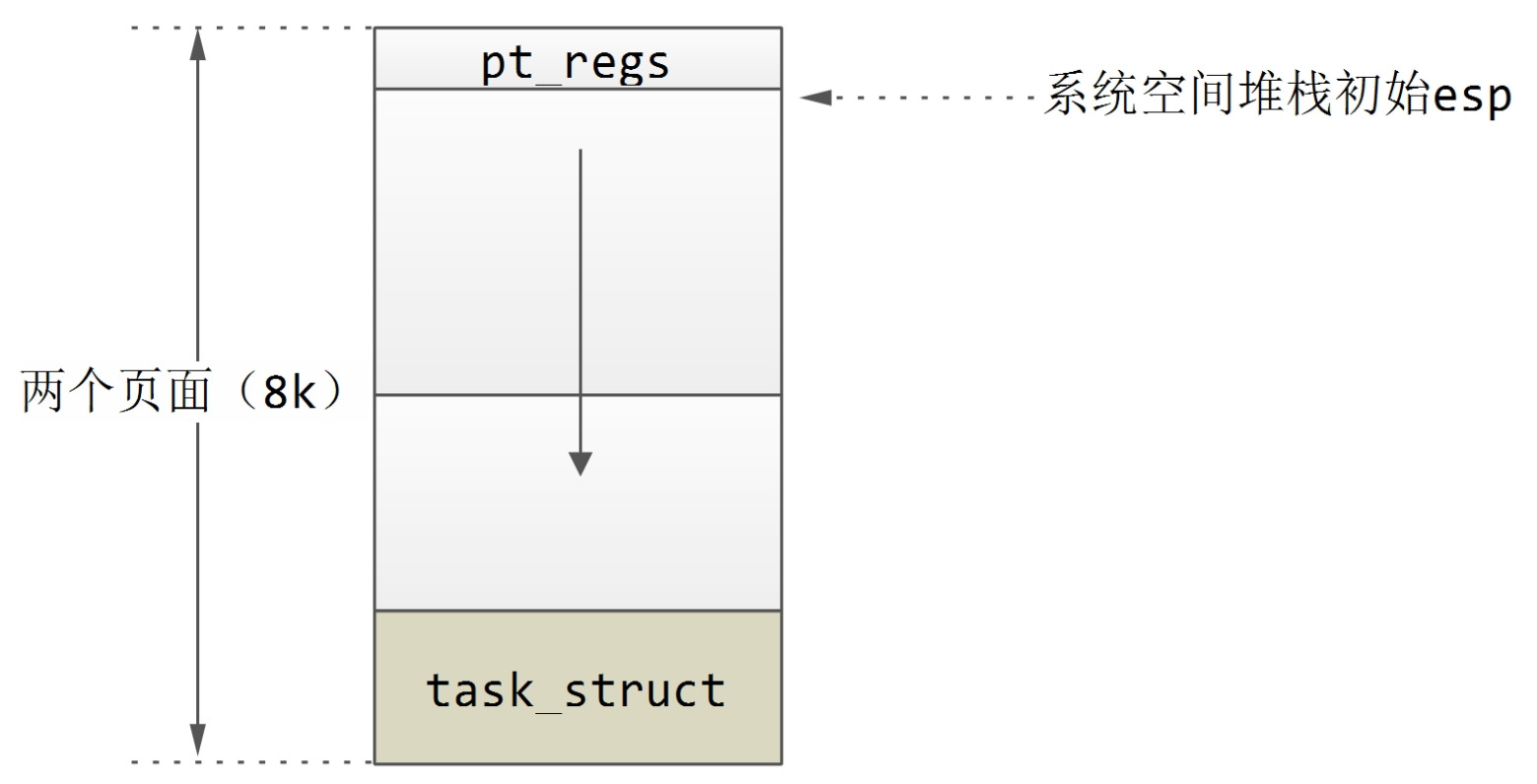
我们之前讲过进程的系统空间为两个页面即8K的空间,底端为task_struct结构,task_struct结构之上为系统空间堆栈。其实,在系统空间堆栈之上即8K空间的顶端,存放的是pt_regs结构,如下图所示:pt_regs结构保存着进入内核前夕CPU各个寄存器的内容,这可是系统调用返回到用户空间的重要“现场”,对于刚刚出生的子进程,这些信息只能从父进程拷贝而来,也正因如此,父子进程才可以返回到用户空间的同一个地方。
copy_thread的代码比较有趣,我们来看看:
<arch/kernel/process.c>
529 int copy_thread(int nr, unsigned long clone_flags, unsigned long esp,
530 unsigned long unused,
531 struct task_struct * p, struct pt_regs * regs)
532 {
533 struct pt_regs * childregs;
534
535 childregs = ((struct pt_regs *) (THREAD_SIZE + (unsigned long) p)) - 1;
536 struct_cpy(childregs, regs);
537 childregs->eax = 0;
538 childregs->esp = esp;
539
540 p->thread.esp = (unsigned long) childregs;
541 p->thread.esp0 = (unsigned long) (childregs+1);
542
543 p->thread.eip = (unsigned long) ret_from_fork;
544
545 savesegment(fs,p->thread.fs);
546 savesegment(gs,p->thread.gs);
547
548 unlazy_fpu(current);
549 struct_cpy(&p->thread.i387, ¤t->thread.i387);
550
551 return 0;
552 }参数中的p指向新创建的子进程;而regs则来自父进程;esp指向进程用户空间的堆栈的栈顶,对fork与vfork而言,esp来自regs.esp即父进程的用户空间地址的栈顶,对clone而言,栈顶esp可有调用者指定。
首先,要确定在进程的系统空间中pt_regs结构的起始地址,这是535行的作用。逐步拆解如下:
(THREAD_SIZE + (unsigned long) p) 定位到子进程系统空间(8K)的上边界;
((struct pt_regs *) (THREAD_SIZE + (unsigned long) p)) 将系统空间的上边界强转成struct pt_regs类型的指针;
((struct pt_regs *) (THREAD_SIZE + (unsigned long) p)) – 1,在struct pt_regs类型的指针类型的指针上执行减1操作,指针后移sizeof(struct pt_regs)个存储单元,于是定位到pt_regs结构的起始地址。
其次,子进程的pt_regs拷贝自父进程(第536行),但也要进行些“修补”。第537行修改子进程在用户空间的返回值为0;第538行修改进程用户空间的栈顶esp。
另外,task_struct结构中有一个thread成员,其为struct thread_struct类型,里面存放着进程在切换时系统空间堆栈的栈顶esp、下一条指令eip(进程再次被切换运行时,将从这里开始运行)等关键信息。在复制task_struct结构时,这些内容原封不动从父进程拷贝过来,现在子进程有自己的系统空间堆栈了,所以要适当的加以调整。第540行将p->thread.esp设置成pt_regs结构的起始地址(注意堆栈是向下扩展的),从调度器的角度来看,就好像这个子进程以前曾经进入内核运行过,而在内核中的任务处理完毕(因此进程系统空间堆栈恢复平衡,变成“空”堆栈)准备返回用户空间时被切换了;而p->thread.esp0则应指向系统空间堆栈的顶端,表示这个进程进入0级(内核空间)运行时,其堆栈的位置。第543行,p->thread.eip被赋值为ret_from_fork,当子进程调度运行时(肯定先从系统空间运行),将从ret_from_fork处开始运行。
2.7 vfork是如何保证子进程先运行的
前文提到,vfork会保证子进程先运行,在子进程执行execve或者exit之后,父进程才可能被调度运行。为了实现这个需求,task_struct结构中有一个信号量(struct semaphore)类型的指针vfork_sem。在do_fork函数开始位置,初始化了一个局部信号量sem,并将sem的地址赋给父进程的task_struct.vfork_sem(流程图中黄色标注的部分)。信号量的初始计数为0,意味着此时对信号量执行down操作,进程将被阻塞。do_fork在完成子进程的“复制”以后,调用wake_up_process唤醒子进程,而自己则调用down(&sem)进入睡眠。在子进程调用exec或者exit时,都会调用mm_release,在该函数中,up(tsk->p_opptr->vfork_sem)增加了父进程vfork_sem的计数,于是父进程被唤醒。
void mm_release(void)
{
struct task_struct *tsk = current;
/* notify parent sleeping on vfork() */
if (tsk->flags & PF_VFORK) {
tsk->flags &= ~PF_VFORK;
up(tsk->p_opptr->vfork_sem);
}
}仔细想来,vfork保证子进程先运行,不见得是内核“精心”为linux用户实现的特性,倒像是内核的无奈之举。我们知道vfork系统调用,父子进程共享进程用户空间,子进程对用户空间的修改会反过来影响父进程,反之亦然。如果说父子进程各自修改数据区的数据是危险的话,那么修改堆栈那就是致命的了。而恰巧子进程紧接着就会调用exec(或者exit),而函数调用涉及到传参,涉及到设置返回地址这些都会修改堆栈。所以决不能让两个进程都回到用户空间并发的运行,必须扣留其中的一个,而只让一个返回到用户空间去运行,直到两个进程不再共享用户空间(子进程执行exec)或者其中之一消亡(必然是先返回用户空间的子进程)为止。
即使如此,也还是有危险,子进程绝对不能从调用vfork的那个函数(caller)中返回(比如vfork之后子进程调用return),因为函数返回时,栈会被恢复平衡,之前用来存放caller的函数参数和函数返回地址的内存单元被回收,之后,这些内存单元可能被用来存放其他的内容。等到子进程去世父进程开始运行时,虽然父进程虽然有自己的esp(保存在pt_regs中),但栈中保存的caller的返回地址被破坏了(esp之上的内容都被破坏),这是很危险的。所以vfork实际上是建立在子进程在创建后立即就会调用execve的前提之上的。

相关文章推荐
- 【进程管理】系统调用fork(),vfork()与clone()
- fork(),clone()系统调用进行进程创建的过程
- linux系统调用fork()、vfork()、clone()讲解
- linux系统调用fork, vfork, clone
- 系统调用fork()、vfork()与clone()
- linux系统调用fork, vfork, clone
- [转]linux系统调用fork, vfork, clone
- linux进程创建:fork、vfork和clone联系与区别
- 进程控制天字第1号系统调用——fork
- linux 进程创建clone、fork与vfork
- linux进程创建:fork、vfork和clone联系与区别
- Linux系统进程控制编程(二)——fork系统调用
- Operating Systems: Three Easy Pieces(操作系统:三个简单方面)5穿插章节:进程API/5.1系统调用:fork()
- linux 系统调用fork vfork clone
- Linux 系统调用之 fork()——进程的创建
- malloc()后进行fork()系统调用,父子进程空间关系如何
- linux系统调用fork, vfork, clone
- Head First C 第九章 进程与系统调用 用fork()+exec()运行子进程
- 进程控制——fork系统调用学习笔记
- linux 进程创建clone、fork与vfork