内存管理之11:物理内存页面的分配
2018-07-15 22:53
204 查看
date: 2014-10-07 19:09
内核可以通过alloc_pages函数来进行内存页面的分配,函数的定义在mm.h文件中:
看来有两个版本的alloc_pages,另一个版本的实现在numa.c,编译时根据编译选项CONFIG_DISCONTIGMEM进行取舍。为什么要有这个取舍?这与之前讲到的NUMA相关。但这里的宏开关却不是CONFIG_NUMA而是CONFIG_DISCONTIGMEM,表示“非连续存储空间”。其实非连续存储空间是一种广义的NUMA,因为那表示在最低物理地址到最高物理地址之间存在空洞,既然存在空洞,质地当然是非均匀的了,从而也就要划分出若干质地均匀(地址连续)的“节点”了,从而也就有一个pg_data_t结构队列。
本文主要分析“连续存储空间”中的内存页面分配,这种情况下只有一个节点,意即只有一个pg_data_t结构contig_page_data。pg_data_t结构中的node_zonelists是一个数组,表示所有的分配策略,这里参数gfp_mask被用作数组下标;参数order表示要分配的连续的页面个数为2^order个。alloc_pages函数检查order之后调用__alloc_pages(内核中以“__”开头的函数表示仅供模块内部使用),下面主要梳理下__alloc_pages的流程。
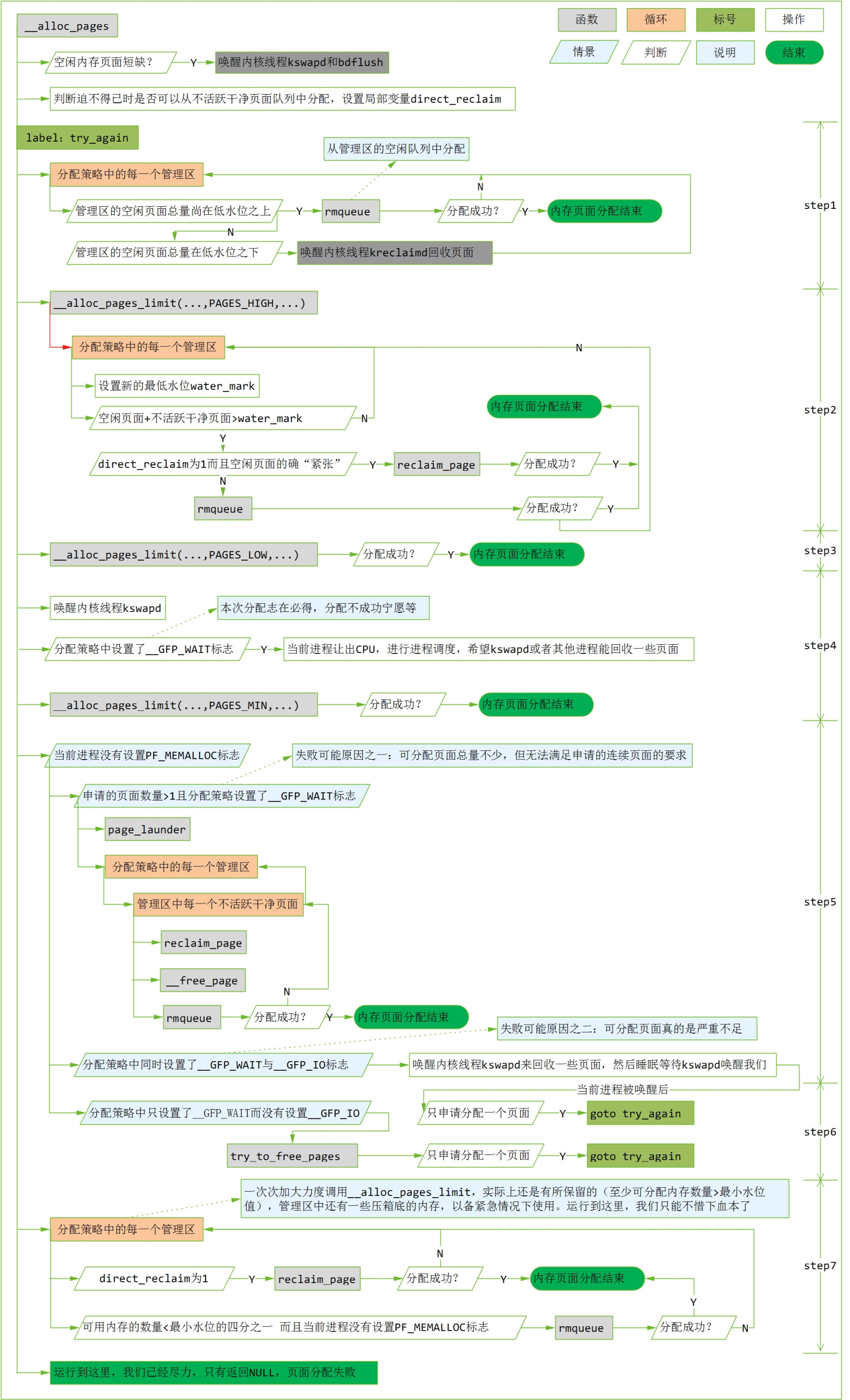
按流程顺序说明如下:
如果申请分配一个页面(因为不活跃干净页面队列中的页面是零散的不连续的,所以只有在申请一个页面时允许从该队列中分配),而分配策略要求等待分配完成,且当前进程不是“内存分配工作者”进程(即当前进程没有设置PF_MEMALLOC标志),那么万不得已时,可以从内存管理区中的不活跃干净队列中分配。
进程的PF_MEMALLOC标志。如果进程的task_struct结构中的flag字段设置了PF_MEMALLOC,那么表示该进程为“内存分配工作者”,一般是内核进程kswapd和kreclaimd。如果这两个进程要分配内存页面,那是为了执行公务,是为了使得其他进程更好地分配内存页面,所以它们比一般的进程要有更高的待遇。图中的step7就是在内存极端紧缺的情况下,试图满足这种进程的内存分配需求。
rmqueue用来在管理区的空闲队列中分配内存页面。前面讲过,为了减少内存碎片,管理区的空闲列表是按连续页面个数分开存放的。rmqueue在分配页面时,先根据申请的页面大小去相应的队列中找空闲的页面。如果相应的队列中没有可用的页面,则去更高一档的队列中去找。找到以后,将一半分配出去,将另一半链到低档的队列中。
要是分配策略中所有的管理区都分配失败,则要加大力度再试了。一方面将管理区中的不活跃干净页面考虑进去,一方面降低水位的要求。这就是__alloc_pages_limit函数所做的事情。先以参数“PAGES_HIGH”调用__alloc_pages_limit,如果还不行就再狠一点,以参数“PAGES_LOW”调用__alloc_pages_limit再试一次。
在__alloc_pages_limit 函数中会调用reclaim_page函数,后者直接从管理区的inactive_clean_list 队列中回收页面。
如果仍然不成功,则唤醒守护kswapd,让它设法换出一些页面。如果分配策略设置了__GFP_WAIT标志,表示本次分配志在必得,不成功毋宁等。当前进程主动让出CPU,并执行一次调度。这样,一来,kswapd有可能立即调度执行;二来即使其他的进程被调度运行,其他进程也可能释放出一些页面。当当前进程再次被调度运行后,或者分配策略表明不允许等待时,以参数“PAGES_MIN”在调一次__alloc_pages_limit,内核已经有了“破釜沉舟”的决心了。
如果还是分配不成功,那就要看当前进程是普通进程还是“内存分配工作者”。对于普通进程,失败的原因可能有两个。
原因之一,可分配页面总数还很多,但是比较零散,不满足申请连续页面的要求。这种情况下,可以将不活跃脏页面洗净(通过page_launder函数),使得这些页面转入内存管理区的不活跃干净页面队列。对于每个管理区,调用reclaim_page从不活跃干净队列中回收一个页面,再调用__free_page释放页面并试图将空闲页面拼凑成尽可能大的页面块,之后再调用rmqueue再试图从管理区的空闲队列中分配。值得注意的是,在page_launder执行期间把当前进程的PF_MEMALLOC标志置1,使其有了“执行公务”的特权,执行完成之后,再将其恢复成0。为什么这样做呢?因为在page_launder中也会要求分配一些临时性的工作页面,不提高它的权限的话,就有可能递归执行到这里。
原因之二,系统中的内存真的不足了。这种情况下,有两种处理:如果分配策略中同时设置了__GFP_WAIT和__GFP_IO,则唤醒kswapd,当前进程进入睡眠并等待kswapd唤醒我们,当前进程被唤醒后,可能kswapd已经设法回收了页面,再回到开头处(标号try_again处)从头再试;如果分配策略中没有指定__GFP_IO,那么我们就不能唤醒kswapd并等待被唤醒。因为守护进程kswapd在进行页面回收操作时需要IO操作,需要申请某些IO锁,而如果这些锁刚好被当前进程所hold,这样就造成了死锁。这种情况下,直接调用try_to_free_pages(原本该有kswapd进程调用)来试图释放些页面。
一次次加大力度调用__alloc_pages_limit,实际上还是有所保留的(至少可分配内存数量>最小水位值),管理区中还有一些压箱底的内存,以备紧急情况下使用。对于执行公务的进程,我们只能不惜下血本了。
流程图展示了内核为了分配内存页面所进行的艰苦卓绝的努力。当正常情况来讲,在step1即可分配成功。剩下的流程都是内核“屡战屡败”“屡败屡战”的结果,毕竟作为一个操作系统的内核,遇到困难它可不能简单的撂挑子,要绞尽脑汁去解决困难。
另,流程图中涉及到分配策略中的几个标志,简要解释如下:
__GFP_WAIT:等待页面分配完成,即申请页面的进程可以被阻塞,意味着调度器可以在分配期间调度另外一个进程运行。
__GFP_IO:内核在查找空闲页的过程中可以进行I/O操作,如此内核可以将换出的页面写到磁盘中,即将不活跃脏页面洗白。
内核可以通过alloc_pages函数来进行内存页面的分配,函数的定义在mm.h文件中:
<include/linux/mm.h>
#ifndef CONFIG_DISCONTIGMEM
static inline struct page * alloc_pages(int gfp_mask, unsigned long order)
{
/*
* Gets optimized away by the compiler.
*/
if (order >= MAX_ORDER)
return NULL;
return __alloc_pages(contig_page_data.node_zonelists+(gfp_mask), order);
}
#else /* !CONFIG_DISCONTIGMEM */
extern struct page * alloc_pages(int gfp_mask, unsigned long order);
#endif /* !CONFIG_DISCONTIGMEM */看来有两个版本的alloc_pages,另一个版本的实现在numa.c,编译时根据编译选项CONFIG_DISCONTIGMEM进行取舍。为什么要有这个取舍?这与之前讲到的NUMA相关。但这里的宏开关却不是CONFIG_NUMA而是CONFIG_DISCONTIGMEM,表示“非连续存储空间”。其实非连续存储空间是一种广义的NUMA,因为那表示在最低物理地址到最高物理地址之间存在空洞,既然存在空洞,质地当然是非均匀的了,从而也就要划分出若干质地均匀(地址连续)的“节点”了,从而也就有一个pg_data_t结构队列。
本文主要分析“连续存储空间”中的内存页面分配,这种情况下只有一个节点,意即只有一个pg_data_t结构contig_page_data。pg_data_t结构中的node_zonelists是一个数组,表示所有的分配策略,这里参数gfp_mask被用作数组下标;参数order表示要分配的连续的页面个数为2^order个。alloc_pages函数检查order之后调用__alloc_pages(内核中以“__”开头的函数表示仅供模块内部使用),下面主要梳理下__alloc_pages的流程。
按流程顺序说明如下:
如果申请分配一个页面(因为不活跃干净页面队列中的页面是零散的不连续的,所以只有在申请一个页面时允许从该队列中分配),而分配策略要求等待分配完成,且当前进程不是“内存分配工作者”进程(即当前进程没有设置PF_MEMALLOC标志),那么万不得已时,可以从内存管理区中的不活跃干净队列中分配。
进程的PF_MEMALLOC标志。如果进程的task_struct结构中的flag字段设置了PF_MEMALLOC,那么表示该进程为“内存分配工作者”,一般是内核进程kswapd和kreclaimd。如果这两个进程要分配内存页面,那是为了执行公务,是为了使得其他进程更好地分配内存页面,所以它们比一般的进程要有更高的待遇。图中的step7就是在内存极端紧缺的情况下,试图满足这种进程的内存分配需求。
rmqueue用来在管理区的空闲队列中分配内存页面。前面讲过,为了减少内存碎片,管理区的空闲列表是按连续页面个数分开存放的。rmqueue在分配页面时,先根据申请的页面大小去相应的队列中找空闲的页面。如果相应的队列中没有可用的页面,则去更高一档的队列中去找。找到以后,将一半分配出去,将另一半链到低档的队列中。
要是分配策略中所有的管理区都分配失败,则要加大力度再试了。一方面将管理区中的不活跃干净页面考虑进去,一方面降低水位的要求。这就是__alloc_pages_limit函数所做的事情。先以参数“PAGES_HIGH”调用__alloc_pages_limit,如果还不行就再狠一点,以参数“PAGES_LOW”调用__alloc_pages_limit再试一次。
在__alloc_pages_limit 函数中会调用reclaim_page函数,后者直接从管理区的inactive_clean_list 队列中回收页面。
如果仍然不成功,则唤醒守护kswapd,让它设法换出一些页面。如果分配策略设置了__GFP_WAIT标志,表示本次分配志在必得,不成功毋宁等。当前进程主动让出CPU,并执行一次调度。这样,一来,kswapd有可能立即调度执行;二来即使其他的进程被调度运行,其他进程也可能释放出一些页面。当当前进程再次被调度运行后,或者分配策略表明不允许等待时,以参数“PAGES_MIN”在调一次__alloc_pages_limit,内核已经有了“破釜沉舟”的决心了。
如果还是分配不成功,那就要看当前进程是普通进程还是“内存分配工作者”。对于普通进程,失败的原因可能有两个。
原因之一,可分配页面总数还很多,但是比较零散,不满足申请连续页面的要求。这种情况下,可以将不活跃脏页面洗净(通过page_launder函数),使得这些页面转入内存管理区的不活跃干净页面队列。对于每个管理区,调用reclaim_page从不活跃干净队列中回收一个页面,再调用__free_page释放页面并试图将空闲页面拼凑成尽可能大的页面块,之后再调用rmqueue再试图从管理区的空闲队列中分配。值得注意的是,在page_launder执行期间把当前进程的PF_MEMALLOC标志置1,使其有了“执行公务”的特权,执行完成之后,再将其恢复成0。为什么这样做呢?因为在page_launder中也会要求分配一些临时性的工作页面,不提高它的权限的话,就有可能递归执行到这里。
原因之二,系统中的内存真的不足了。这种情况下,有两种处理:如果分配策略中同时设置了__GFP_WAIT和__GFP_IO,则唤醒kswapd,当前进程进入睡眠并等待kswapd唤醒我们,当前进程被唤醒后,可能kswapd已经设法回收了页面,再回到开头处(标号try_again处)从头再试;如果分配策略中没有指定__GFP_IO,那么我们就不能唤醒kswapd并等待被唤醒。因为守护进程kswapd在进行页面回收操作时需要IO操作,需要申请某些IO锁,而如果这些锁刚好被当前进程所hold,这样就造成了死锁。这种情况下,直接调用try_to_free_pages(原本该有kswapd进程调用)来试图释放些页面。
一次次加大力度调用__alloc_pages_limit,实际上还是有所保留的(至少可分配内存数量>最小水位值),管理区中还有一些压箱底的内存,以备紧急情况下使用。对于执行公务的进程,我们只能不惜下血本了。
流程图展示了内核为了分配内存页面所进行的艰苦卓绝的努力。当正常情况来讲,在step1即可分配成功。剩下的流程都是内核“屡战屡败”“屡败屡战”的结果,毕竟作为一个操作系统的内核,遇到困难它可不能简单的撂挑子,要绞尽脑汁去解决困难。
另,流程图中涉及到分配策略中的几个标志,简要解释如下:
__GFP_WAIT:等待页面分配完成,即申请页面的进程可以被阻塞,意味着调度器可以在分配期间调度另外一个进程运行。
__GFP_IO:内核在查找空闲页的过程中可以进行I/O操作,如此内核可以将换出的页面写到磁盘中,即将不活跃脏页面洗白。

相关文章推荐
- Linux内存管理学习笔记--物理内存分配
- linux 内存管理 - 分配页面
- Linux内存管理--物理内存分配
- Linux内存管理--物理内存分配【转】
- Linux内存管理--物理内存分配【转】
- Linux内存管理之物理页面分配
- Linux内核源代码情景分析-内存管理之用户页面的分配
- linux 内存管理 - 分配页面
- kmalloc分配物理内存与高端内存映射--Linux内存管理(十八)
- 内存分配详解、指针与数组[C++][内存管理]
- Java内存管理 内存如何分配
- 图解 Linux 内存管理 -- 线性空间与物理内存
- 分配页面
- 高端内存映射之vmalloc分配内存中不连续的页--Linux内存管理(十九)
- 内存区划分、内存分配、常量存储区、堆、栈、自由存储区、全局区[C++][内存管理]
- Atom编辑器折腾记_(11)编辑器实时预览HTML页面(插件:Atom HTML Preview)
- OAF学习笔记-11-页面传值(传ID,显示为Name)
- 内存管理(1)物理内存描述
- 内存管理以及分配
- 解决 ios 11 和 h5 页面在 wkwebview 上显示, footer 设置 bottom 为 0 时, 顶部会出现留白