内存管理之5:物理内存管理中的抽象
2018-07-14 11:33
176 查看
date: 2014-09-16 19:09
在软件设计时,我们一般要从需求中提取出抽象(类或者数据结构),然后围绕这些抽象设计相关的算法。内存管理自然也不能例外,这两节我们来看看为了管理为了物理内存以及整个虚存空间,linux提取哪些抽象,提取这些抽象背后的动机是什么?这些抽象之间的关联是什么?
注:本文展示的结构体定义来自2.6.24版本的内核。
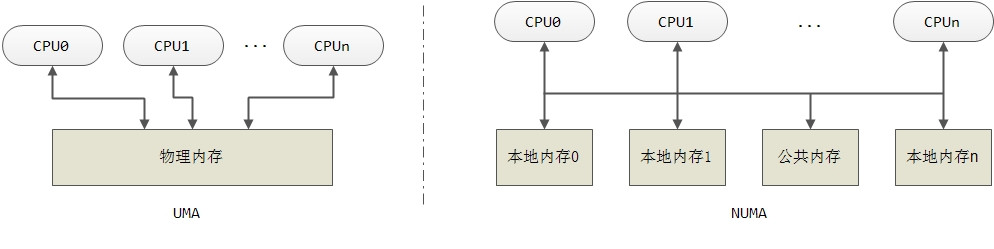
与NUMA相对的是UMA即一致性内存访问,在这种系统下,所有处理器对内存的访问具有相同的速度,有就是说整个内存质地是均匀的,因此只对应一个内存节点Node。传统的计算机中采用的就是UMA结构,本文主要分析UMA结构。
Node对应的数据结构为pglist_data,其定义如下(对定义进行了简化,去掉宏开关中的内容):
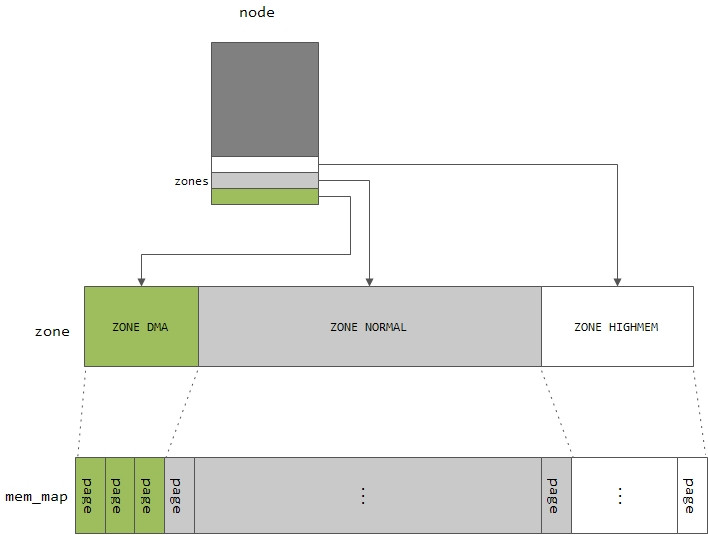
给你一整块地,你该怎么打理?当然是将整块地划分成不同的区域,某个区域用来盖房子,某个区域用来种农作物,其他的区域用来种经济作物。这里也一样,内存节点将整个内存再细分为区域Zone,结构体成员node_zones就表示内存节点所划分的内存区域,而nr_zones指示所分区域的数量。一般分为三个区:ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM,每个区域都有其特殊用途。ZONE_DMA在低端地址处,该区域主要是为ISA(Industry Standard Architecture)设备而设置;ZONE_NORMAL区域的物理内存通过某个固定的偏移映射到内核的虚拟地址空间;如果内存空间超过1G,则还会有ZONE_HIGHMEM,设置该区域的目的主要是为了使得内核可以访问1G以外的内存空间。在X86架构下,区域的划分一般如下:
ZONE_DMA First —— 16MiB of memory
ZONE_NORMAL —— 16MiB - 896MiB
ZONE_HIGHMEM —— 896 MiB - End
当需要申请一个内存页Page时,alloc_page的调用者一般会指定从哪个区域分配,但如果该区域内存不够该怎办,这时就需要指定“备选”区域,可以有多个备选区,优先级从高到底排列,表示当指定区域的内存不足时,优先从第一个备选区分配,如果第一个备选区仍然内存不足,则尝试第二个备选区,依次类推,这就是所谓的分配策略。结构体成员node_zonelists就表示这种策略组。
一个内存节点最终管理的还是物理内存的page,成员node_mem_map是一个page类型的指针,指向该内存节点所有的page数组。
管理区对应的结构体为zone,定义在同一文件中。
可见在SMP坏境下,ZONE_PADDING 定义了一个zone_padding类型的变量name;而zone_padding本身被定义成一个柔性数组,数组具体的大小会在编译时决定,以保证此前的的部分按照cache line(一般为16个字节)对齐。
为什么要按cache line进行对齐呢?ZONE_PADDING的注释说得很清楚了:因为zone结构体会被频繁访问到,在多核环境下,会有多个CPU同时访问同一个结构体,为了避免彼此间的干扰,必须对每次访问进行加锁。那么是不是要对整个zone加锁呢?一把锁锁住zone中所有的成员?这应该不是最有效的方法。我们知道zone结构体很大,访问zone最频繁的有两个两个场景,一是页面分配,二是页面回收,这两种场景各自访问结构体zone中不同的成员。如果一把锁锁住zone中所有成员的话,当一个cpu正在处理页面分配的事情,另一个cpu想要进行页面回收的处理,却因为第一个cpu锁住了zone中所有成员而只好等待。第二个CPU明知道此时可以“安全的”进行回收处理(因为第一个CPU不会访问与回收处理相关的成员)却也只能干着急。可见,我们应该将锁再细分。zone中定义了两把锁,lock以及lru_lock,lock与页面分配有关,lru_lock与页面回收有关。定义了两把锁,自然,每把锁所控制的成员最好跟锁呆在一起,最好是跟锁在同一个cache line中。当CPU对某个锁进行上锁处理时,CPU会将锁从内存加载到cache中,因为是以cache line为单位进行加载,所以与锁紧挨着的成员也被加载到同一cache line中。CPU上完锁想要访问相关的成员时,这些成员已经在cache line中了。
增加padding,会额外占用一些字节,但内核中zone结构体的实例并不会太多(UMA下只有三个),相比效率的提升,损失这点空间是值得的。
关于lowmem_reserve成员,为了避免某些区域的内存分配殆尽(比如ZONE_NORMAL)而另一些区域(比如ZONE_ HIGHMEM)却内存充沛,“旱的旱死涝的涝死”,每个区域都预留一些“压箱底”的内存。
为什么要将可用内存用一个数组来表示呢?这与伙伴系统有关。在内核中,内存管理的工作由伙伴系统来承担,伙伴系统分配的都是2^n个连续的页面。假定某个系统共有60个物理页,系统运行一段时间后,物理页面的分配情形如下:
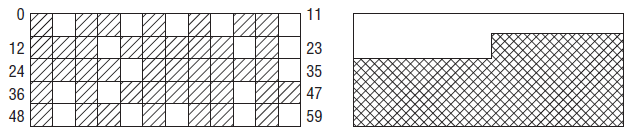
左侧的地址空间散布着空闲页,尽管空闲页超过25%,但伙伴系统能够分配的连续页面最大为一页,这就是内存碎片。注意这里的内存碎片只对内核有意义,这种碎片对用户空间没有影响,因为用户空间直接访问的是虚拟地址,通过页表映射到物理地址,即使物理空间不连续,其上的虚拟地址可以是连续的。
如果我们将空闲内存根据其连续页面的大小按照2的n次幂来进行分组,n的取值在[0, MAX_ORDER]闭区间中,则可以有效的减少内存碎片。如果需要分配连续8个页面,则到n=3的组中去找空闲内存,找到了则分配连续的8个页面;如果本组中已经没有空闲页面,则去更高一级n=4的组中去找空闲内存,该组中的空闲内存块都是连续的16个页面,如果该组中有空闲内存,则将空闲内存块一分为二,分成两个连续页面为8的空闲块,一块分配出去,一块并入n=3的组中。在释放内存页时,假定释放的内存为连续的8个页面,则将其归入n=3的空闲页面组中,如果发现该组中某两个内存款互为伙伴,即可将这两个块合并成一个连续16个页面的内存块,并归入到n=4的组中。这就是伙伴系统的工作过程。
struct free_area的定义在同一个文件中:
结构体free_area定义了一组队列头,这样,一个管理区的空闲内存就通过两个层次来管理:
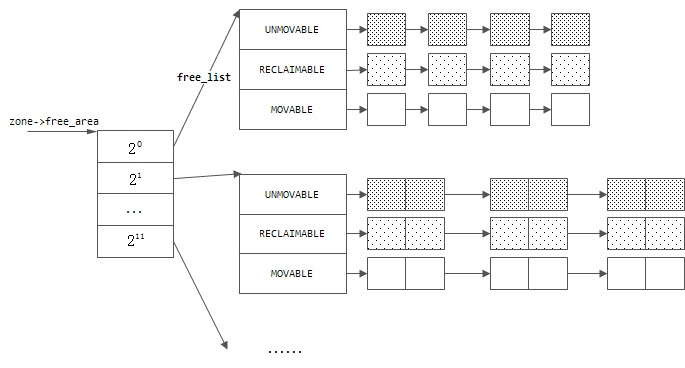
空闲内存已经按2的n次幂来进行了分组,对每个组内的内存块为何还要再分组?为了解释这个问题,我们需要知道内核将已经分配的页面按照可移动性分为下列三种:
MIGRATE_UNMOVABLE,不可移动页。页帧在内存中的位置固定,不可以移动,内核分配的大部分页面都属于该类型。
MIGRATE_RECLAIMABLE,可回收页。页帧不能直接移动,但可以删除。其内容可以从某些源重新生成。文件映射对应的内存属于该类。
MIGRATE_MOVABLE,可移动页,页帧可以随意移动,属于用户空间程序的页属于此类,页帧移动后,只需要更新相应的页表即可,用户空间的应用并不会感觉到这些移动。
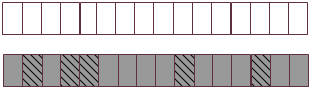
假定某个连续32页的内存块中,散落着不可移动页(深颜色部分)和可回收页(白色部分)。不可移动页已经被分出去5页(斜线部分)。

此时,虽然可回收页有16页,但最多可分4个连续的页。但如果我们将不可移动页和可回收页分组,如下图,则对于可回收页,最多可分连续的16页,减少了内存碎片。
可见,将内存按照可移动性分组,可以有效减少内存碎片。这就是在2.6.24版本的内核引入的“反碎片”技术的基础。
结构体free_area中的成员nr_free表示该区域空闲页面的总数。
读者可能会有疑问,前面说过内存碎片是对内核而言的,而内核中主要又使用不可移动页面。即使将内存页按移动性分组,可这对解决内核的碎片化又有什么帮助呢?内核仍然在不可移动页上分配,不可移动页上的碎片化并没有改善呀?你的想法是正确的,这里的反碎片技术其实是对用户空间程序有益的。大多数现代CPU都提供了使用巨型页的可能,这种巨型页比普通页大很多,这对内存密集型的应用有好处。用户空间通过页表映射访问内存,使用更大的页(这个页内的地址当然是连续的),则“地址转换/查找缓冲区”只需处理较少的项,并且可以降低TLB缓存(为了加快页面映射的速度,并不是每次都从内存中访问页面映射目录和页面映射表,而是将它们装入高速缓存中缓冲起来,这部分高速缓存称为TLB,即“地址转换/查找缓冲区”(Translation Lookaside Buffers))失效的可能性。而分配巨型页,就需要更多的连续内存页。用户空间的应用程序一般在可移动或者可回收内存页上分配,将内存按移动性分组后,我们就可以利用这种移动性,将小块空闲内存合并成大块空闲内存,给分配巨型页提供了可能。
如果内核无法满足针对某种移动性的分配请求,会怎么样?这与我们在Node定义时讨论的备选区的问题类似,内核的解决办法也是提供一个备选列表。其定义如下,其表达的意图不言自明。
zone中其他的成员的含义请参考注释。
由于一个page可能通过页表映射到了用户的虚拟地址空间中,也可能在内核中被slab分配器管理,所以结构体的定义中有很多的联合union。slab分配器的工作过程比较复杂,留待以后分析。后面的讲解将跳过slab分配相关的内容。
mapping为address_space类型的指针,在页面换入换出时会详细讲到。
当页面的内容来自一个文件时(比如mmap映射,或者时从交换文件中换入),index代表着该页面在文件中的序号;当页面的内容换出到交换设备上,但还保留着内容作为缓冲时,index指向了页面的去向。
为了便于后文中的情景分析,这里将2.4版本内核中page结构体的定义展示如下:
该版本的实现中,page有两个成员next_hash 和pprev_hash,该成员用来将page链到某个哈希表中。
page就像是物理页帧的户口,每一个物理页帧都对应一个page结构。如果一个物理页面没有对应的page结构,它就成了“黑户”了,系统就无法看到它,也就无法对它进行管理。系统在初始化时,会根据物理内存的大小建立一个全局的page结构体数组mem_map,作为物理页面的“户口簿”,里面的每一个元素代表一个物理的页帧,而数组的下标就是物理page的逻辑编号。
物理内存管理中的这三层抽象,示意如下:
在软件设计时,我们一般要从需求中提取出抽象(类或者数据结构),然后围绕这些抽象设计相关的算法。内存管理自然也不能例外,这两节我们来看看为了管理为了物理内存以及整个虚存空间,linux提取哪些抽象,提取这些抽象背后的动机是什么?这些抽象之间的关联是什么?
注:本文展示的结构体定义来自2.6.24版本的内核。
1 最顶层——节点 Node
Node(内存节点)是因为NUMA的出现而产生的抽象。NUMA(Non Uniform Memory Access)即非一致性内存访问,主要出现在大型机上。参考下图,在这种系统中,每个CPU都有本地内存,但也可以通过总线访问其他CPU的本地内存;总线上还有一个公共的内存模块,各CPU都可以通过系统总线访问。显然,对某个具体的CPU来说,其访问本地内存的速度是最快的,而通过总线访问其他CPU本地内存的速度要慢,而且还可能面临着竞争。可见,在这样的系统中,虽然内存的地址是连续的,但“质地”却不均匀,因此我们需要将这些质地不均匀的内存分开管理,每一个内存模块称之为一个内存节点Node。与NUMA相对的是UMA即一致性内存访问,在这种系统下,所有处理器对内存的访问具有相同的速度,有就是说整个内存质地是均匀的,因此只对应一个内存节点Node。传统的计算机中采用的就是UMA结构,本文主要分析UMA结构。
Node对应的数据结构为pglist_data,其定义如下(对定义进行了简化,去掉宏开关中的内容):
<include/linux/mmzone.h>
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
struct page *node_mem_map;
struct bootmem_data *bdata; /*自举内存分配器*/
unsigned long node_start_pfn; /*该节点的其实页帧逻辑编号,全局唯一*/
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id;
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd;
int kswapd_max_order;
} pg_data_t;给你一整块地,你该怎么打理?当然是将整块地划分成不同的区域,某个区域用来盖房子,某个区域用来种农作物,其他的区域用来种经济作物。这里也一样,内存节点将整个内存再细分为区域Zone,结构体成员node_zones就表示内存节点所划分的内存区域,而nr_zones指示所分区域的数量。一般分为三个区:ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM,每个区域都有其特殊用途。ZONE_DMA在低端地址处,该区域主要是为ISA(Industry Standard Architecture)设备而设置;ZONE_NORMAL区域的物理内存通过某个固定的偏移映射到内核的虚拟地址空间;如果内存空间超过1G,则还会有ZONE_HIGHMEM,设置该区域的目的主要是为了使得内核可以访问1G以外的内存空间。在X86架构下,区域的划分一般如下:
ZONE_DMA First —— 16MiB of memory
ZONE_NORMAL —— 16MiB - 896MiB
ZONE_HIGHMEM —— 896 MiB - End
当需要申请一个内存页Page时,alloc_page的调用者一般会指定从哪个区域分配,但如果该区域内存不够该怎办,这时就需要指定“备选”区域,可以有多个备选区,优先级从高到底排列,表示当指定区域的内存不足时,优先从第一个备选区分配,如果第一个备选区仍然内存不足,则尝试第二个备选区,依次类推,这就是所谓的分配策略。结构体成员node_zonelists就表示这种策略组。
一个内存节点最终管理的还是物理内存的page,成员node_mem_map是一个page类型的指针,指向该内存节点所有的page数组。
2 中间层——管理区Zone
在介绍节点Node时,我们已经介绍了管理区zone的概念,管理区分为如下几种类型:enum zone_type {
#ifdef CONFIG_ZONE_DMA
/* DMA内存域,一般为16M,用于ISA */
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
/* 在64位系统中,使用32位地址寻址、适合DMA的内存域 */
ZONE_DMA32,
#endif
/* 可直接映射到内核地址空间的内存区域 */
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/* 内核不能直接映射的内存域 */
ZONE_HIGHMEM,
#endif
/* 可移动内存区域 */
ZONE_MOVABLE,
MAX_NR_ZONES
};管理区对应的结构体为zone,定义在同一文件中。
/* 内存节点的内存域 */
struct zone {
/* Fields commonly accessed by the page allocator */
/* 水线相关字段 */
unsigned long pages_min, pages_low, pages_high;
unsigned long lowmem_reserve[MAX_NR_ZONES];
struct per_cpu_pageset pageset[NR_CPUS];
spinlock_t lock;
struct free_area free_area[MAX_ORDER];
ZONE_PADDING(_pad1_)
/* Fields commonly accessed by the page reclaim scanner */
spinlock_t lru_lock;
struct list_head active_list;
struct list_head inactive_list;
unsigned long nr_scan_active;
unsigned long nr_scan_inactive;
unsigned long pages_scanned; /* since last reclaim */
unsigned long flags; /* zone flags, see below */
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
int prev_priority;
ZONE_PADDING(_pad2_)
/* Rarely used or read-mostly fields */
wait_queue_head_t * wait_table;
unsigned long wait_table_hash_nr_entries;
unsigned long wait_table_bits;
struct pglist_data *zone_pgdat; /* 该内存域所属的节点 */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn; /* 该内存域第一个页帧号 */
unsigned long spanned_pages; /* total size, including holes */
unsigned long present_pages; /* amount of memory (excluding holes) */
/*
* rarely used fields:
*/
const char *name; /* 内存域名称 */
} ____cacheline_internodealigned_in_smp;2.1 padding
首先,该结构体被ZONE_PADDING“分割”成三部分,宏ZONE_PADDING的定义在同一个文件中:/*
* zone->lock and zone->lru_lock are two of the hottest locks in the kernel.
* So add a wild amount of padding here to ensure that they fall into separate
* cachelines. There are very few zone structures in the machine, so space
* consumption is not a concern here.
*/
#if defined(CONFIG_SMP)
struct zone_padding {
char x[0];
} ____cacheline_internodealigned_in_smp;
#define ZONE_PADDING(name) struct zone_padding name;
#else
#define ZONE_PADDING(name)
#endif可见在SMP坏境下,ZONE_PADDING 定义了一个zone_padding类型的变量name;而zone_padding本身被定义成一个柔性数组,数组具体的大小会在编译时决定,以保证此前的的部分按照cache line(一般为16个字节)对齐。
为什么要按cache line进行对齐呢?ZONE_PADDING的注释说得很清楚了:因为zone结构体会被频繁访问到,在多核环境下,会有多个CPU同时访问同一个结构体,为了避免彼此间的干扰,必须对每次访问进行加锁。那么是不是要对整个zone加锁呢?一把锁锁住zone中所有的成员?这应该不是最有效的方法。我们知道zone结构体很大,访问zone最频繁的有两个两个场景,一是页面分配,二是页面回收,这两种场景各自访问结构体zone中不同的成员。如果一把锁锁住zone中所有成员的话,当一个cpu正在处理页面分配的事情,另一个cpu想要进行页面回收的处理,却因为第一个cpu锁住了zone中所有成员而只好等待。第二个CPU明知道此时可以“安全的”进行回收处理(因为第一个CPU不会访问与回收处理相关的成员)却也只能干着急。可见,我们应该将锁再细分。zone中定义了两把锁,lock以及lru_lock,lock与页面分配有关,lru_lock与页面回收有关。定义了两把锁,自然,每把锁所控制的成员最好跟锁呆在一起,最好是跟锁在同一个cache line中。当CPU对某个锁进行上锁处理时,CPU会将锁从内存加载到cache中,因为是以cache line为单位进行加载,所以与锁紧挨着的成员也被加载到同一cache line中。CPU上完锁想要访问相关的成员时,这些成员已经在cache line中了。
增加padding,会额外占用一些字节,但内核中zone结构体的实例并不会太多(UMA下只有三个),相比效率的提升,损失这点空间是值得的。
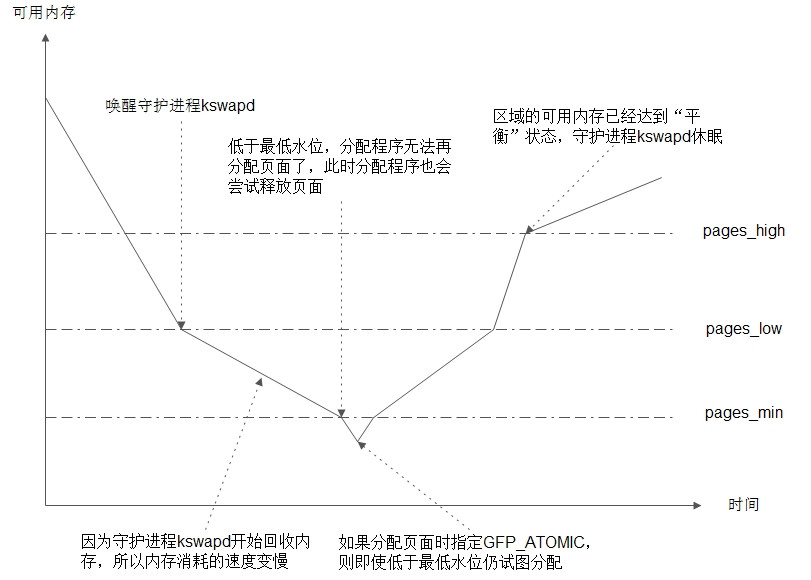
2.2 水位值
一个区域所包含的内存时有限的,如果任凭页面分配程序“予取予求”的话,内存总有耗尽的时刻,等到耗尽时再做补救的话为时已晚。所以我们需要未雨绸缪,这内存耗尽之前实施补救措施,也就是唤醒守护进程kswapd来回收一些内存页面。三个水位值pages_min、pages_low、pages_high与守护进程kswapd的“互动”如下图:关于lowmem_reserve成员,为了避免某些区域的内存分配殆尽(比如ZONE_NORMAL)而另一些区域(比如ZONE_ HIGHMEM)却内存充沛,“旱的旱死涝的涝死”,每个区域都预留一些“压箱底”的内存。
2.3 空闲内存
区域中到底有多少可用内存呢?由成员free_area来表示,这是一个struct free_area类型的数组,数组的尺寸MAX_ORDER的定义也在本文件中。如果没有定义CONFIG_FORCE_MAX_ZONEORDER宏的话,MAX_ORDER的值将为11。/* Free memory management - zoned buddy allocator. */ #ifndef CONFIG_FORCE_MAX_ZONEORDER #define MAX_ORDER 11 #else #define MAX_ORDER CONFIG_FORCE_MAX_ZONEORDER #endif
为什么要将可用内存用一个数组来表示呢?这与伙伴系统有关。在内核中,内存管理的工作由伙伴系统来承担,伙伴系统分配的都是2^n个连续的页面。假定某个系统共有60个物理页,系统运行一段时间后,物理页面的分配情形如下:
左侧的地址空间散布着空闲页,尽管空闲页超过25%,但伙伴系统能够分配的连续页面最大为一页,这就是内存碎片。注意这里的内存碎片只对内核有意义,这种碎片对用户空间没有影响,因为用户空间直接访问的是虚拟地址,通过页表映射到物理地址,即使物理空间不连续,其上的虚拟地址可以是连续的。
如果我们将空闲内存根据其连续页面的大小按照2的n次幂来进行分组,n的取值在[0, MAX_ORDER]闭区间中,则可以有效的减少内存碎片。如果需要分配连续8个页面,则到n=3的组中去找空闲内存,找到了则分配连续的8个页面;如果本组中已经没有空闲页面,则去更高一级n=4的组中去找空闲内存,该组中的空闲内存块都是连续的16个页面,如果该组中有空闲内存,则将空闲内存块一分为二,分成两个连续页面为8的空闲块,一块分配出去,一块并入n=3的组中。在释放内存页时,假定释放的内存为连续的8个页面,则将其归入n=3的空闲页面组中,如果发现该组中某两个内存款互为伙伴,即可将这两个块合并成一个连续16个页面的内存块,并归入到n=4的组中。这就是伙伴系统的工作过程。
struct free_area的定义在同一个文件中:
#define MIGRATE_UNMOVABLE 0
#define MIGRATE_RECLAIMABLE 1
#define MIGRATE_MOVABLE 2
#define MIGRATE_RESERVE 3
#define MIGRATE_ISOLATE 4 /* can't allocate from here */
#define MIGRATE_TYPES 5
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};结构体free_area定义了一组队列头,这样,一个管理区的空闲内存就通过两个层次来管理:
空闲内存已经按2的n次幂来进行了分组,对每个组内的内存块为何还要再分组?为了解释这个问题,我们需要知道内核将已经分配的页面按照可移动性分为下列三种:
MIGRATE_UNMOVABLE,不可移动页。页帧在内存中的位置固定,不可以移动,内核分配的大部分页面都属于该类型。
MIGRATE_RECLAIMABLE,可回收页。页帧不能直接移动,但可以删除。其内容可以从某些源重新生成。文件映射对应的内存属于该类。
MIGRATE_MOVABLE,可移动页,页帧可以随意移动,属于用户空间程序的页属于此类,页帧移动后,只需要更新相应的页表即可,用户空间的应用并不会感觉到这些移动。
假定某个连续32页的内存块中,散落着不可移动页(深颜色部分)和可回收页(白色部分)。不可移动页已经被分出去5页(斜线部分)。
此时,虽然可回收页有16页,但最多可分4个连续的页。但如果我们将不可移动页和可回收页分组,如下图,则对于可回收页,最多可分连续的16页,减少了内存碎片。
可见,将内存按照可移动性分组,可以有效减少内存碎片。这就是在2.6.24版本的内核引入的“反碎片”技术的基础。
结构体free_area中的成员nr_free表示该区域空闲页面的总数。
读者可能会有疑问,前面说过内存碎片是对内核而言的,而内核中主要又使用不可移动页面。即使将内存页按移动性分组,可这对解决内核的碎片化又有什么帮助呢?内核仍然在不可移动页上分配,不可移动页上的碎片化并没有改善呀?你的想法是正确的,这里的反碎片技术其实是对用户空间程序有益的。大多数现代CPU都提供了使用巨型页的可能,这种巨型页比普通页大很多,这对内存密集型的应用有好处。用户空间通过页表映射访问内存,使用更大的页(这个页内的地址当然是连续的),则“地址转换/查找缓冲区”只需处理较少的项,并且可以降低TLB缓存(为了加快页面映射的速度,并不是每次都从内存中访问页面映射目录和页面映射表,而是将它们装入高速缓存中缓冲起来,这部分高速缓存称为TLB,即“地址转换/查找缓冲区”(Translation Lookaside Buffers))失效的可能性。而分配巨型页,就需要更多的连续内存页。用户空间的应用程序一般在可移动或者可回收内存页上分配,将内存按移动性分组后,我们就可以利用这种移动性,将小块空闲内存合并成大块空闲内存,给分配巨型页提供了可能。
如果内核无法满足针对某种移动性的分配请求,会怎么样?这与我们在Node定义时讨论的备选区的问题类似,内核的解决办法也是提供一个备选列表。其定义如下,其表达的意图不言自明。
<mm/page_alloc.c>
static int fallbacks[MIGRATE_TYPES][MIGRATE_TYPES-1] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE,
MIGRATE_RESERVE },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE,
MIGRATE_RESERVE },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE,
MIGRATE_RESERVE },
[MIGRATE_RESERVE] = { MIGRATE_RESERVE, MIGRATE_RESERVE,
MIGRATE_RESERVE }, /* Never used */
};zone中其他的成员的含义请参考注释。
3 最底层——物理页帧Page
物理页帧是物理内存的最小管理单元,其对应的抽象为page,结构体定义如下:struct page {
/*用于描述页的属性。如PG_locked */
unsigned long flags;
/* 使用计数,表示内核中引用该页的次数 */
atomic_t _count; /* Usage count, see below. */
union {
/*
* 如果该页映射到用户空间虚拟地址上,则表示映射到页表pte的次数
* 每增加一个使用者,计数器加1
*/
atomic_t _mapcount;
/* 如果是内核slab使用的页,则表示其中的slab对象数目 */
unsigned int inuse;/* SLUB: Nr of objects */
};
union {
struct {
/*
* 私有数据指针。
* 如果页位于交换缓存,则指向存储swp_entry_t结构
*/
unsigned long private;
struct address_space *mapping;
};
struct kmem_cache *slab; /* SLUB: Pointer to slab */
struct page *first_page; /* Compound tail pages */
};
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* SLUB: freelist req. slab lock */
};
struct list_head lru; /*用于页面换出的链表,可能链接到活动页链表和不活动页链表 */
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if not kmapped,
ie. highmem) */
#endif
};由于一个page可能通过页表映射到了用户的虚拟地址空间中,也可能在内核中被slab分配器管理,所以结构体的定义中有很多的联合union。slab分配器的工作过程比较复杂,留待以后分析。后面的讲解将跳过slab分配相关的内容。
mapping为address_space类型的指针,在页面换入换出时会详细讲到。
当页面的内容来自一个文件时(比如mmap映射,或者时从交换文件中换入),index代表着该页面在文件中的序号;当页面的内容换出到交换设备上,但还保留着内容作为缓冲时,index指向了页面的去向。
为了便于后文中的情景分析,这里将2.4版本内核中page结构体的定义展示如下:
/*
* Try to keep the most commonly accessed fields in single cache lines
* here (16 bytes or greater). This ordering should be particularly
* beneficial on 32bit processors.
*
* The first line is data used in page cache lookup, the second line
* is used for linear searches (eg. clock algorithm scans).
*/
typedef struct page {
struct list_head list;
struct address_space *mapping;
unsigned long index;
struct page *next_hash;
atomic_t count;
unsigned long flags; /* atomic flags, some possibly updated asynchronously */
struct list_head lru;
unsigned long age;
wait_queue_head_t wait;
struct page **pprev_hash;
struct buffer_head * buffers;
void *virtual; /* nonNULL if kmapped */
struct zone_struct *zone;
} mem_map_t该版本的实现中,page有两个成员next_hash 和pprev_hash,该成员用来将page链到某个哈希表中。
page就像是物理页帧的户口,每一个物理页帧都对应一个page结构。如果一个物理页面没有对应的page结构,它就成了“黑户”了,系统就无法看到它,也就无法对它进行管理。系统在初始化时,会根据物理内存的大小建立一个全局的page结构体数组mem_map,作为物理页面的“户口簿”,里面的每一个元素代表一个物理的页帧,而数组的下标就是物理page的逻辑编号。
物理内存管理中的这三层抽象,示意如下:

相关文章推荐
- 内存管理之6:虚存管理中的抽象
- linux内核内存管理学习之二(物理内存管理--伙伴系统)
- linux内核内存管理学习之二(物理内存管理--伙伴系统)
- linux内核内存管理学习之二(物理内存管理--伙伴系统)
- 之五:物理内存管理中的抽象
- linux内核内存管理学习之二(物理内存管理--伙伴系统)
- linux内核内存管理学习之二(物理内存管理--伙伴系统)
- 内存管理---物理内存、虚拟内存
- 读书笔记-现代操作系统-3储存管理-3.1无储存器抽象3.2一种储存器抽象:地址空间
- 内存管理(1)物理内存描述
- Windows NT File System Internals》学习笔记之物理内存管理简介
- uc/os-iii学习笔记---存储管理(内存管理)
- 读深入理解Linux内核 (第8章 内存管理, 第一部分 --- 页的管理)
- objc使用什么机制管理对象内存(内存管理方式有哪些)
- Linux内核:IO设备的抽象管理方式
- 从资源池和管理的角度理解物理内存
- 物理内存的管理
- 内存管理之非连续分配管理方式
- 计算机底层知识拾遗(八)理解物理内存管理
- 存储管理——内存管理