Spark On Yarn
2018-06-03 20:53
309 查看
背景:
对于一些处于Hadoop向Spark迁移的过程中,可能一些老的应用还是在Yarn来资源调度的,那么此时用Spark如何来触发Yarn调度呢步骤:
1、将原Spark集群的node01集点的配置改成如下export JAVA_HOME=/usr/java/jdk1.8.0_162 export HADOOP_CONF_DIR=/usr/local/hadoop-2.6.4/etc/hadoop
2、启动yarn
start-yarn.sh
3、计算Pi值
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 1g --executor-memory 1g --executor-cores 2 --queue default lib/spark-examples*.jar 10
4、运行完成后如下图所示
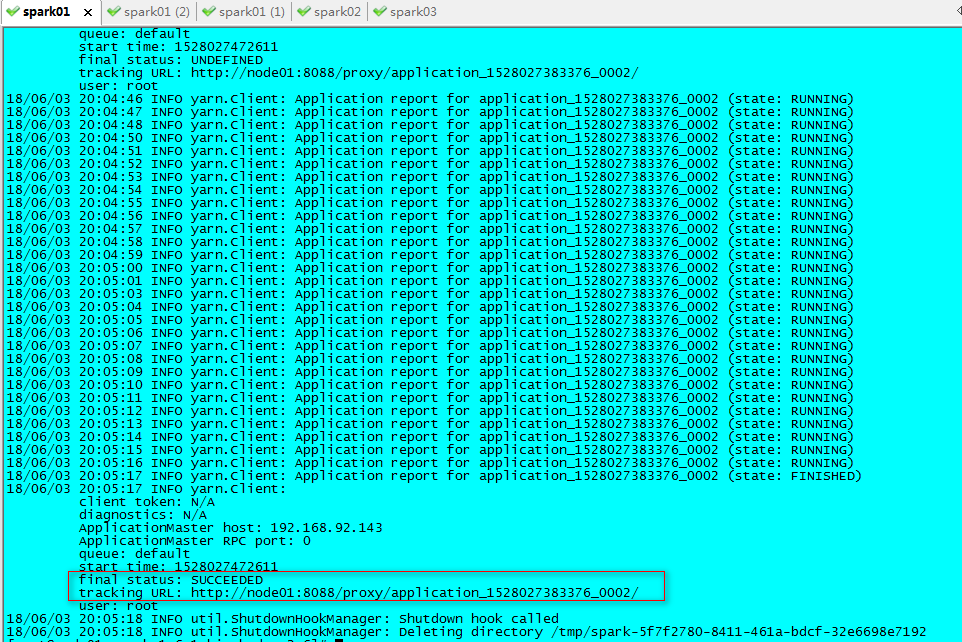
5、在控制台中观察结果:node01:8088的logs
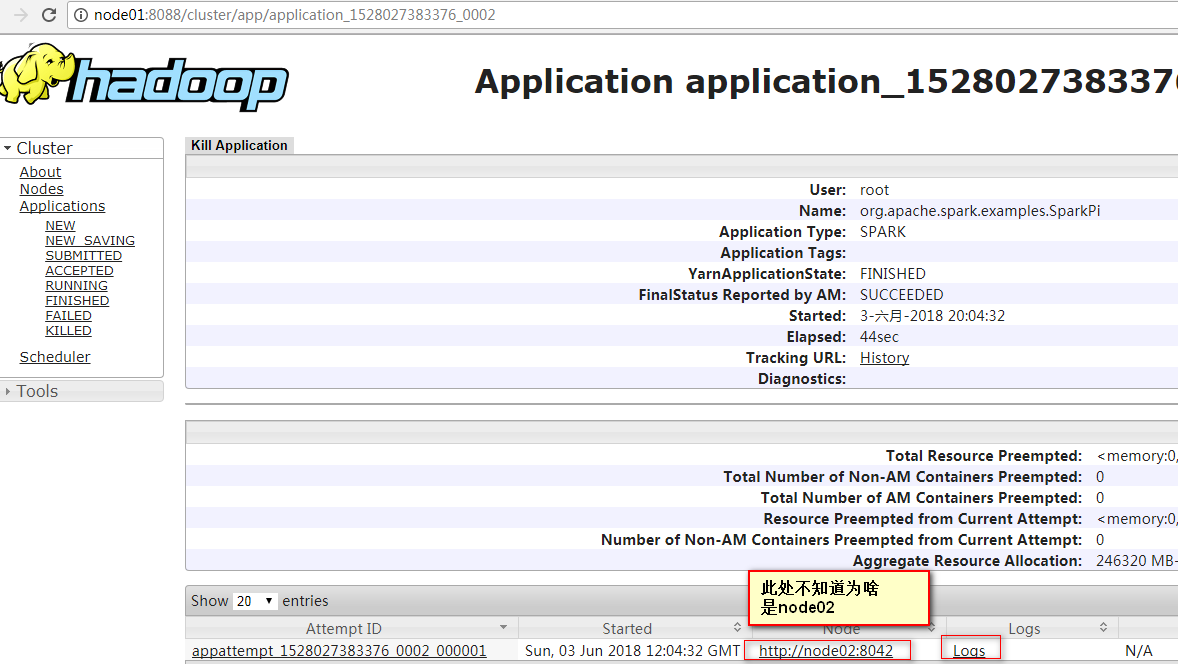
注意:但这个地方,不知道为什么Node节点显示的是node02,从Logs链接点进去后,即使强行将域名改成node01,也显示无日志,真是蛋疼
参考-yarn如何启动

相关文章推荐
- 基于Spark on Yarn的淘宝数据挖掘平台
- Spark on YARN两种运行模式介绍
- spark on yarn(zookeeper 配置)
- Spark On YARN部署模式下的内存分配情况
- spark on yarn启用动态分配
- sparkR在spark on yarn下的问题
- SparkSQL On Yarn with Hive,操作和访问Hive表
- spark on yarn-client 奇怪问题
- spark on yarn 执行过程介绍
- spark on yarn 报 org.apache.hadoop.util.Shell$ExitCodeException: 问题
- Spark Standalone与Spark on YARN的几种提交方式
- Spark on YARN集群模式作业运行全过程分析
- spark on yarn 详解
- spark on yarn(ERROR client.TransportClient: Failed to send RPC)
- spark on yarn中yarn-cluster与yarn-client区别
- Spark on Yarn的运行原理
- spark on yarn图形化任务监控利器:History-server帮你理解spark的任务执行过程
- day27:Spark on Yarn彻底解密
- SparkSQL On Yarn with Hive,操作和访问Hive表