深入分析Kubernetes Scheduler的NominatedPods
2018-05-26 00:12
585 查看
Author: xidianwangtao@gmail.com
在Kubernetes 1.8抢占式调度Preemption源码分析中,有好几处我们提到了NominatedPods,当时没有给出足够的分析,今天我们就重点分析一下NominatedPods的意义和原理。
为了尽量避免从preemptor抢占资源到真正再次执行调度这个时间段的scheduler能感知到那些资源已经被抢占,在scheduler调度其他更低优先级的Pods时考虑这些资源已经被抢占,因此在抢占阶段,为给preemptor设置
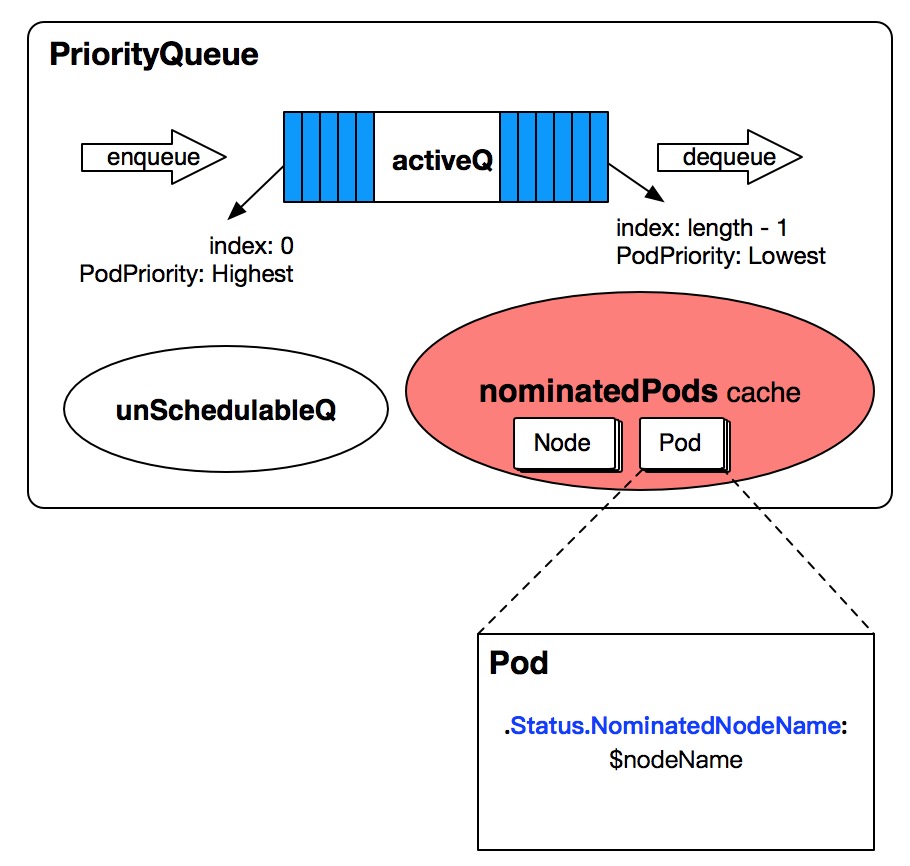
PriorityQueue中缓存了每个node上的NominatedPods,这些NominatedPods表示已经被该node提名的,期望调度在该node上的,但是又还没最终成功调度过来的Pods。
invoke ScheduleAlgorithm.Preempt进行资源抢占,返回抢占发生的node,victims,nominatedPodsToClear。
node:抢占发生的最佳node;
victims:待删除的pods,以释放资源给preemptor;
nominatedPodsToClear:那些将要被删除
如果抢占成功(node非空),则调用
无论抢占是否成功(node是否为空),nominatedPodsToClear都可能不为空,都需要遍历nominatedPodsToClear内的所有Pods,调用
一共会尝试进行两次predicate:
第一次predicate时,调用
第二次predicate时,如果前面的predicate逻辑有失败的情况,或者前面的podsAdded为false(如果在
第二次predicate时,如果前面的predicate逻辑都成功,并且podAdded为true的情况下,那么需要触发真正的第二次predicate逻辑,因为nominatedPods的添加成功,可能会Inter-Pod Affinity会影响predicate结果。
下面是addNominatedPods的代码,负责生成临时的schedulercache.NodeInfo和algorithm.PredicateMetadata,提供给具体的predicate Function进行预选处理。
addNominatedPods的逻辑如下:
调用WaitingPodsForNode获取PriorityQueue中的该node上的nominatedPods cache数据,如果nominatedPods为空,则返回podAdded为false,addNominatedPods流程结束。
克隆出PredicateMeta和NodeInfo对象,遍历nominatedPods,逐个将优先级不低于待调度pod的nominated pod加到克隆出来的NodeInfo对象中,并更新到克隆出来的PredicateMeta对象中。这些克隆出来的NodeInfo和PredicateMeta对象,最终会传入到predicate Functions中进行预选处理。遍历完成后,返回podAdded(true)和NodeInfo和PredicateMeta对象。
当往PriorityQueue中unSchedulableQ queue添加Pod后,会调用addNominatedPodIfNeeded相应的将待添加的pod添加/更新到PriorityQueue nominatedPods Cache中。
注意将pod添加到nominatedPods cache中的前提是该pod的
updateNominatedPod更新PriorityQueue nominatedPods Cache的逻辑是:先删除oldPod,再添加newPod进去。
deleteNominatedPodIfExists时,先检查该pod的
如果为空,则不做任何操作,直接return结束流程。
如果不为空,则遍历nominatedPods cache,一旦找到UID匹配的pod,就说明nominatedPods中存在该pod,然后就从cache中删除该pod。如果删除后,发现该pod对应的NominatedNode上没有nominatePods了,则把整个node的nominatedPods从map cache中删除。
在Kubernetes 1.8抢占式调度Preemption源码分析中,有好几处我们提到了NominatedPods,当时没有给出足够的分析,今天我们就重点分析一下NominatedPods的意义和原理。
NominatedPods是什么?
当enable PodPriority feature gate后,scheduler会在集群资源资源不足时为preemptor抢占低优先级的Pods(成为victims)的资源,然后preemptor会再次入调度队列,等待下次victims的优雅终止并进行下一次调度。为了尽量避免从preemptor抢占资源到真正再次执行调度这个时间段的scheduler能感知到那些资源已经被抢占,在scheduler调度其他更低优先级的Pods时考虑这些资源已经被抢占,因此在抢占阶段,为给preemptor设置
pod.Status.NominatedNodeName,表示在NominatedNodeName上发生了抢占,preemptor期望调度在该node上。
PriorityQueue中缓存了每个node上的NominatedPods,这些NominatedPods表示已经被该node提名的,期望调度在该node上的,但是又还没最终成功调度过来的Pods。
抢占调度时发生了什么?
我们来重点关注下scheduler进行preempt时相关的流程。func (sched *Scheduler) preempt(preemptor *v1.Pod, scheduleErr error) (string, error) {
...
node, victims, nominatedPodsToClear, err := sched.config.Algorithm.Preempt(preemptor, sched.config.NodeLister, scheduleErr)
...
var nodeName = ""
if node != nil {
nodeName = node.Name
err = sched.config.PodPreemptor.SetNominatedNodeName(preemptor, nodeName)
if err != nil {
glog.Errorf("Error in preemption process. Cannot update pod %v annotations: %v", preemptor.Name, err)
return "", err
}
...
}
// Clearing nominated pods should happen outside of "if node != nil". Node could
// be nil when a pod with nominated node name is eligible to preempt again,
// but preemption logic does not find any node for it. In that case Preempt()
// function of generic_scheduler.go returns the pod itself for removal of the annotation.
for _, p := range nominatedPodsToClear {
rErr := sched.config.PodPreemptor.RemoveNominatedNodeName(p)
if rErr != nil {
glog.Errorf("Cannot remove nominated node annotation of pod: %v", rErr)
// We do not return as this error is not critical.
}
}
return nodeName, err
}invoke ScheduleAlgorithm.Preempt进行资源抢占,返回抢占发生的node,victims,nominatedPodsToClear。
node:抢占发生的最佳node;
victims:待删除的pods,以释放资源给preemptor;
nominatedPodsToClear:那些将要被删除
.Status.NominatedNodeName的Pods列表,这些Pods是首先是属于PriorityQueue中的nominatedPods Cache中的Pods,并且他们的Pod Priority要低于preemptor Pod Priority,意味着这些nominatedPods已经不再适合调度到之前抢占时选择的这个node上了。
func (g *genericScheduler) Preempt(pod *v1.Pod, nodeLister algorithm.NodeLister, scheduleErr error) (*v1.Node, []*v1.Pod, []*v1.Pod, error) {
...
candidateNode := pickOneNodeForPreemption(nodeToVictims)
if candidateNode == nil {
return nil, nil, nil, err
}
nominatedPods := g.getLowerPriorityNominatedPods(pod, candidateNode.Name)
if nodeInfo, ok := g.cachedNodeInfoMap[candidateNode.Name]; ok {
return nodeInfo.Node(), nodeToVictims[candidateNode].Pods, nominatedPods, err
}
return nil, nil, nil, fmt.Errorf(
"preemption failed: the target node %s has been deleted from scheduler cache",
candidateNode.Name)
}
func (g *genericScheduler) getLowerPriorityNominatedPods(pod *v1.Pod, nodeName string) []*v1.Pod {
pods := g.schedulingQueue.WaitingPodsForNode(nodeName)
if len(pods) == 0 {
return nil
}
var lowerPriorityPods []*v1.Pod
podPriority := util.GetPodPriority(pod)
for _, p := range pods {
if util.GetPodPriority(p) < podPriority {
lowerPriorityPods = append(lowerPriorityPods, p)
}
}
return lowerPriorityPods
}如果抢占成功(node非空),则调用
podPreemptor.SetNominatedNodeName设置preemptor的
.Status.NominatedNodeName为该node name,表示该preemptor期望抢占在该node上。
func (p *podPreemptor) SetNominatedNodeName(pod *v1.Pod, nominatedNodeName string) error {
podCopy := pod.DeepCopy()
podCopy.Status.NominatedNodeName = nominatedNodeName
_, err := p.Client.CoreV1().Pods(pod.Namespace).UpdateStatus(podCopy)
return err
}无论抢占是否成功(node是否为空),nominatedPodsToClear都可能不为空,都需要遍历nominatedPodsToClear内的所有Pods,调用
podPreemptor.RemoveNominatedNodeName将其
.Status.NominatedNodeName设置为空。
func (p *podPreemptor) RemoveNominatedNodeName(pod *v1.Pod) error {
if len(pod.Status.NominatedNodeName) == 0 {
return nil
}
return p.SetNominatedNodeName(pod, "")
}Preemptor抢占成功后,发生了什么?
Premmptor抢占成功后,该Pod会被再次加入到PriorityQueue中的Unschedulable Sub-Queue队列中,等待条件再次出发调度。关于这部分内容更深入的解读,请参考我的博客深入分析Kubernetes Scheduler的优先级队列。preemptor再次会通过podFitsOnNode对node进行predicate逻辑处理。func podFitsOnNode(
pod *v1.Pod,
meta algorithm.PredicateMetadata,
info *schedulercache.NodeInfo,
predicateFuncs map[string]algorithm.FitPredicate,
ecache *EquivalenceCache,
queue SchedulingQueue,
alwaysCheckAllPredicates bool,
equivCacheInfo *equivalenceClassInfo,
) (bool, []algorithm.PredicateFailureReason, error) {
var (
eCacheAvailable bool
failedPredicates []algorithm.PredicateFailureReason
)
predicateResults := make(map[string]HostPredicate)
podsAdded := false
for i := 0; i < 2; i++ {
metaToUse := meta
nodeInfoToUse := info
if i == 0 {
podsAdded, metaToUse, nodeInfoToUse = addNominatedPods(util.GetPodPriority(pod), meta, info, queue)
} else if !podsAdded || len(failedPredicates) != 0 { // 有问题吧?应该是podsAdded,而不是!podsAdded
break
}
// Bypass eCache if node has any nominated pods.
// TODO(bsalamat): consider using eCache and adding proper eCache invalidations
// when pods are nominated or their nominations change.
eCacheAvailable = equivCacheInfo != nil && !podsAdded
for _, predicateKey := range predicates.Ordering() {
var (
fit bool
reasons []algorithm.PredicateFailureReason
err error
)
func() {
var invalid bool
if eCacheAvailable {
...
}
if !eCacheAvailable || invalid {
// we need to execute predicate functions since equivalence cache does not work
fit, reasons, err = predicate(pod, metaToUse, nodeInfoToUse)
if err != nil {
return
}
...
}
}()
...
}
}
}
return len(failedPredicates) == 0, failedPredicates, nil
}一共会尝试进行两次predicate:
第一次predicate时,调用
addNominatedPods,遍历PriorityQueue nominatedPods中所有Pods,将那些PodPriority大于等于该调度Pod的优先级的所有nominatedPods添加到SchedulerCache的NodeInfo中,意味着调度该pod时要考虑这些高优先级nominatedPods进行预选,比如要减去它们的resourceRequest等,并更新到PredicateMetadata中,接着执行正常的predicate逻辑。
第二次predicate时,如果前面的predicate逻辑有失败的情况,或者前面的podsAdded为false(如果在
addNominatedPods时,发现该node对应nominatedPods cache是空的,那么返回值podAdded为false),那么第二次predicate立马结束,并不会触发真正的predicate逻辑。
第二次predicate时,如果前面的predicate逻辑都成功,并且podAdded为true的情况下,那么需要触发真正的第二次predicate逻辑,因为nominatedPods的添加成功,可能会Inter-Pod Affinity会影响predicate结果。
下面是addNominatedPods的代码,负责生成临时的schedulercache.NodeInfo和algorithm.PredicateMetadata,提供给具体的predicate Function进行预选处理。
// addNominatedPods adds pods with equal or greater priority which are nominated
// to run on the node given in nodeInfo to meta and nodeInfo. It returns 1) whether
// any pod was found, 2) augmented meta data, 3) augmented nodeInfo.
func addNominatedPods(podPriority int32, meta algorithm.PredicateMetadata,
nodeInfo *schedulercache.NodeInfo, queue SchedulingQueue) (bool, algorithm.PredicateMetadata,
*schedulercache.NodeInfo) {
if queue == nil || nodeInfo == nil || nodeInfo.Node() == nil {
// This may happen only in tests.
return false, meta, nodeInfo
}
nominatedPods := queue.WaitingPodsForNode(nodeInfo.Node().Name)
if nominatedPods == nil || len(nominatedPods) == 0 {
return false, meta, nodeInfo
}
var metaOut algorithm.PredicateMetadata
if meta != nil {
metaOut = meta.ShallowCopy()
}
nodeInfoOut := nodeInfo.Clone()
for _, p := range nominatedPods {
if util.GetPodPriority(p) >= podPriority {
nodeInfoOut.AddPod(p)
if metaOut != nil {
metaOut.AddPod(p, nodeInfoOut)
}
}
}
return true, metaOut, nodeInfoOut
}
// WaitingPodsForNode returns pods that are nominated to run on the given node,
// but they are waiting for other pods to be removed from the node before they
// can be actually scheduled.
func (p *PriorityQueue) WaitingPodsForNode(nodeName string) []*v1.Pod {
p.lock.RLock()
defer p.lock.RUnlock()
if list, ok := p.nominatedPods[nodeName]; ok {
return list
}
return nil
}addNominatedPods的逻辑如下:
调用WaitingPodsForNode获取PriorityQueue中的该node上的nominatedPods cache数据,如果nominatedPods为空,则返回podAdded为false,addNominatedPods流程结束。
克隆出PredicateMeta和NodeInfo对象,遍历nominatedPods,逐个将优先级不低于待调度pod的nominated pod加到克隆出来的NodeInfo对象中,并更新到克隆出来的PredicateMeta对象中。这些克隆出来的NodeInfo和PredicateMeta对象,最终会传入到predicate Functions中进行预选处理。遍历完成后,返回podAdded(true)和NodeInfo和PredicateMeta对象。
如何维护PriorityQueue NominatedPods Cache
深入分析Kubernetes Scheduler的优先级队列中分析了scheduler中podInformer、nodeInformer、serviceInformer、pvcInformer等注册的EventHandler中对PriorityQueue的操作,其中跟NominatedPods相关的EventHandler如下。Add Pod to PriorityQueue
当往PriorityQueue中active queue添加Pod后,会调用addNominatedPodIfNeeded相应的将待添加的pod先从PriorityQueue nominatedPods Cache中删除,删除后再重新添加到nominatedPods cache中。// Add adds a pod to the active queue. It should be called only when a new pod
// is added so there is no chance the pod is already in either queue.
func (p *PriorityQueue) Add(pod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
err := p.activeQ.Add(pod)
if err != nil {
glog.Errorf("Error adding pod %v to the scheduling queue: %v", pod.Name, err)
} else {
if p.unschedulableQ.get(pod) != nil {
glog.Errorf("Error: pod %v is already in the unschedulable queue.", pod.Name)
p.deleteNominatedPodIfExists(pod)
p.unschedulableQ.delete(pod)
}
p.addNominatedPodIfNeeded(pod)
p.cond.Broadcast()
}
return err
}
func (p *PriorityQueue) addNominatedPodIfNeeded(pod *v1.Pod) {
nnn := NominatedNodeName(pod)
if len(nnn) > 0 {
for _, np := range p.nominatedPods[nnn] {
if np.UID == pod.UID {
glog.Errorf("Pod %v/%v already exists in the nominated map!", pod.Namespace, pod.Name)
return
}
}
p.nominatedPods[nnn] = append(p.nominatedPods[nnn], pod)
}
}当往PriorityQueue中unSchedulableQ queue添加Pod后,会调用addNominatedPodIfNeeded相应的将待添加的pod添加/更新到PriorityQueue nominatedPods Cache中。
func (p *PriorityQueue) AddUnschedulableIfNotPresent(pod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
if p.unschedulableQ.get(pod) != nil {
return fmt.Errorf("pod is already present in unschedulableQ")
}
if _, exists, _ := p.activeQ.Get(pod); exists {
return fmt.Errorf("pod is already present in the activeQ")
}
if !p.receivedMoveRequest && isPodUnschedulable(pod) {
p.unschedulableQ.addOrUpdate(pod)
p.addNominatedPodIfNeeded(pod)
return nil
}
err := p.activeQ.Add(pod)
if err == nil {
p.addNominatedPodIfNeeded(pod)
p.cond.Broadcast()
}
return err
}注意将pod添加到nominatedPods cache中的前提是该pod的
.Status.NominatedNodeName不为空。
Update Pod in PriorityQueue
当更新PriorityQueue中Pod后,会接着调用updateNominatedPod更新PriorityQueue中nominatedPods Cache。// Update updates a pod in the active queue if present. Otherwise, it removes
// the item from the unschedulable queue and adds the updated one to the active
// queue.
func (p *PriorityQueue) Update(oldPod, newPod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
// If the pod is already in the active queue, just update it there.
if _, exists, _ := p.activeQ.Get(newPod); exists {
p.updateNominatedPod(oldPod, newPod)
err := p.activeQ.Update(newPod)
return err
}
// If the pod is in the unschedulable queue, updating it may make it schedulable.
if usPod := p.unschedulableQ.get(newPod); usPod != nil {
p.updateNominatedPod(oldPod, newPod)
if isPodUpdated(oldPod, newPod) {
p.unschedulableQ.delete(usPod)
err := p.activeQ.Add(newPod)
if err == nil {
p.cond.Broadcast()
}
return err
}
p.unschedulableQ.addOrUpdate(newPod)
return nil
}
// If pod is not in any of the two queue, we put it in the active queue.
err := p.activeQ.Add(newPod)
if err == nil {
p.addNominatedPodIfNeeded(newPod)
p.cond.Broadcast()
}
return err
}updateNominatedPod更新PriorityQueue nominatedPods Cache的逻辑是:先删除oldPod,再添加newPod进去。
// updateNominatedPod updates a pod in the nominatedPods.
func (p *PriorityQueue) updateNominatedPod(oldPod, newPod *v1.Pod) {
// Even if the nominated node name of the Pod is not changed, we must delete and add it again
// to ensure that its pointer is updated.
p.deleteNominatedPodIfExists(oldPod)
p.addNominatedPodIfNeeded(newPod)
}Delete Pod from PriorityQueue
当从PriorityQueue中删除Pod前,会先调用deleteNominatedPodIfExists从PriorityQueue nominatedPods cache中删除该pod。// Delete deletes the item from either of the two queues. It assumes the pod is
// only in one queue.
func (p *PriorityQueue) Delete(pod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
p.deleteNominatedPodIfExists(pod)
err := p.activeQ.Delete(pod)
if err != nil { // The item was probably not found in the activeQ.
p.unschedulableQ.delete(pod)
}
return nil
}deleteNominatedPodIfExists时,先检查该pod的
.Status.NominatedNodeName是否为空:
如果为空,则不做任何操作,直接return结束流程。
如果不为空,则遍历nominatedPods cache,一旦找到UID匹配的pod,就说明nominatedPods中存在该pod,然后就从cache中删除该pod。如果删除后,发现该pod对应的NominatedNode上没有nominatePods了,则把整个node的nominatedPods从map cache中删除。
func (p *PriorityQueue) deleteNominatedPodIfExists(pod *v1.Pod) {
nnn := NominatedNodeName(pod)
if len(nnn) > 0 {
for i, np := range p.nominatedPods[nnn] {
if np.UID == pod.UID {
p.nominatedPods[nnn] = append(p.nominatedPods[nnn][:i], p.nominatedPods[nnn][i+1:]...)
if len(p.nominatedPods[nnn]) == 0 {
delete(p.nominatedPods, nnn)
}
break
}
}
}
}总结
本文对NominatedPods和NominatedNode的作用进行了阐述,并从源码角度分析了抢占调度时及抢占调度后,NominatedPods都有哪些变更操作,最后分析了PriorityQueue中Pod的Add/Update/Delete操作对PriorityQueue NominatedPods Cache的影响,希望有助于读者加深对scheduler抢占调度和优先级队列的理解。
相关文章推荐
- 自定义UIViewController与xib文件关系深入分析
- USB协议深入分析
- 属性动画(Property Animation)深入分析(原理、源码、实践)
- Android 动画animation 深入分析
- android6.0 adbd深入分析(五)adbd处理adb root的一个bug
- 深入分析ConcurrentHashMap
- 中文乱码深入分析
- 深入分析Java I/O 的工作机制
- Android FrameWork深入分析DreamManagerService实现自己的系统屏保
- Android情景分析之深入解析zygote
- 精通八大排序算法系列:一之续、快速排序算法的深入分析
- Java 多线程 死锁 隐性死锁 数据竞争 恶性数据竞争 错误解决深入分析 全方向举例
- Android 进阶学习:Android视图状态及重绘流程分析,带你一步步深入了解View(三)
- 聊聊并发(一)深入分析Volatile的实现原理
- 深入分析Java ClassLoader原理
- 深入php socket的讲解与实例分析
- 深入分析Java ClassLoader原理
- PHP远程DoS漏洞深入分析及防护方案
- 深入分析 Java 中的中文编码问题
- 深入分析字符数组、字符串与'\0'