统计自然语言处理书籍阅读心得四
2018-04-11 14:41
281 查看
1:困惑度:我们通常用困惑度(perplexity)来代替交叉熵 衡量语言模型的好坏。同样,语言模型设计的任务就是寻找困惑度最小的模型,使其最接 近真实语言的情况。在自然语言处理中,我们所说的语言模型的困惑度 通常是指语言模型对于测试数据的困惑度。一般情况下将所有数据分成 两部分,一部分作为训练数据,用于估计模型的参数;另一部分作为测 试数据,用于评估语言模型的质量。2:噪声信道模型
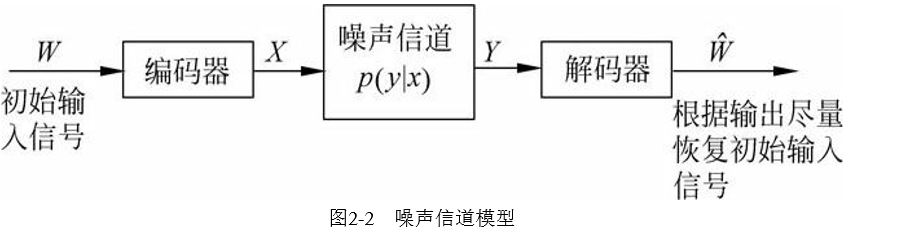
其目标就是优化噪声信道中信号传 输的吞吐量和准确率,其基本假设是一个信道的输出以一定的概率依赖 于输入。一般情况下,在信号传输的过程中都要进行双重性处理:一方 面要对编码进行压缩,尽量消除所有的冗余;另一方面又要通过增加一 定的可控冗余以保障输入信号经过噪声信道传输以后可以很好地恢复原 状。这样,信息编码时要尽量少占用空间,但又必须保持足够的冗余以 便能够检测和校验传输造成的错误。信道输出信号解码后应该尽量恢复 到原始输入状态。过程如下图:
3:支持向量机支持向量机(support vector machine, SVM)〔1〕是近几年来发展起 来的新型分类方法,是在高维特征空间使用线性函数假设空间的学习系 统,在分类方面具有良好的性能。近几年来,支持向量机在模式识别、 知识发现等理论研究,计算机视觉与图像识别、生物信息学以及自然语 言处理等相关技术研究中得到了广泛应用。在自然语言处理中,SVM广 泛应用于短语识别、词义消歧、文本自动分类和信息过滤等方面。
3-1:线性分类:通过执行如下操作进行:当f(x)≥0 时,将输入x=(x1,x2,…,xn)′赋予正类,否则,将其赋予负类。当 f(x)(x∈X)是线性函数时,f(x)可以写成如下形式:

其实就是一个线性函数,如果他的值>0那么此时他的自变量是正类。该分类方法的几何解释是,方程式〈w·x〉+b=0定义的超平面将 输入空间X分成两半,一半为负类,一半为正类,如图2-5所示:
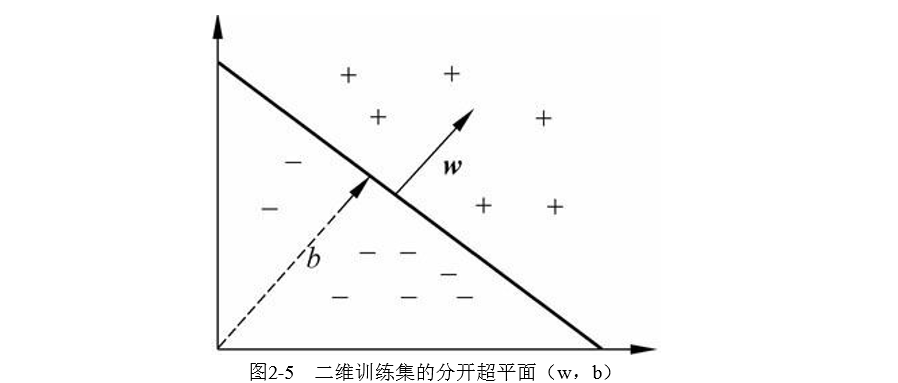
可以理解为图2-5中的黑斜线表示超平面当b的值变化时,超平面平行移动。因此,如果想表达 中所有 可能的超平面,一般要包括n+1个可调参数的表达式。如果训练数据可以被无误差地划分,那么,以最大间隔分开数据的 超平面称为最优超平面,如图2-6所示。
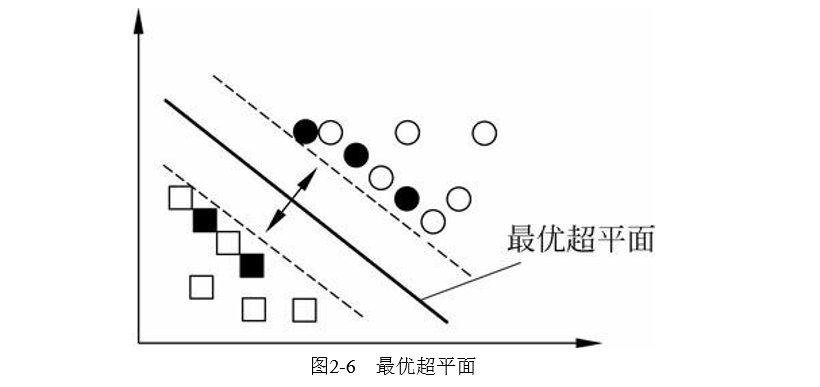
目前个人理解的是,先用两条平行线使正负集分隔开同时时这两条线之间距离最大,然后最优超平面就是这两条线中间的那条平行线。
3-2:线性不可分:建立非线性分类器需要分两步:首先使用一个非线性映射函数将数据变换到一个特征空间F,然后在这个特征空间上使用线性分类器。线性分类器的一个重要性质是可以表示成对偶形式,这意味着假设 可以表达为训练点和线性组合,因此,决策规则(分类函数)可以用测 试点和训练点的内积来表示:
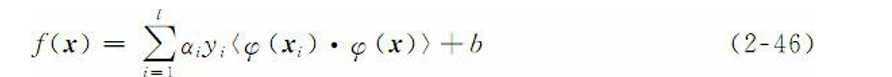
其中,l是样本数目;αi是个正值导数,可通过学习获得;yi为类别标 记。如果有一种方法可以在特征空间中直接计算内积,就像在原始输入点的函数中一样,那么,就有可能将两个步 骤融合到一起建立一个非线性分类器。这样,在高维空间内实际上只需 要进行内积运算,而这种内积运算是可以利用原空间中的函数实现的, 我们甚至没有必要知道变换的形式。这种直接计算的方法称为核 (kernel)函数方法。3-3:核函数的构造:
核是一个函数K,对所有x, z∈X,满足:

其中
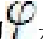
是从X到(内积)特征空间F的映射。同时核函数要适合某个特征空间必须是对称的,即
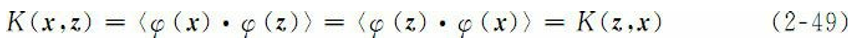
并且需要满足
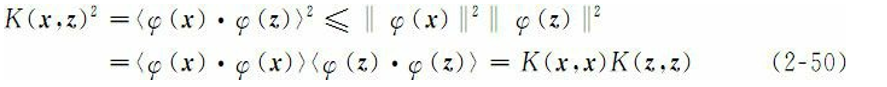
但是,这些条件对于保证特征空间的存在是不 充分的,还必须满足Mercer定理的条件,对X的任意有限子集,相应的 矩阵是半正定的。也就是说,令X是有限输入空间,K(x, z)是X上的 对称函数。那么,K(x, z)是核函数的充分必要条件是矩阵
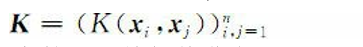
是半正定的(即特征值非负)。
其目标就是优化噪声信道中信号传 输的吞吐量和准确率,其基本假设是一个信道的输出以一定的概率依赖 于输入。一般情况下,在信号传输的过程中都要进行双重性处理:一方 面要对编码进行压缩,尽量消除所有的冗余;另一方面又要通过增加一 定的可控冗余以保障输入信号经过噪声信道传输以后可以很好地恢复原 状。这样,信息编码时要尽量少占用空间,但又必须保持足够的冗余以 便能够检测和校验传输造成的错误。信道输出信号解码后应该尽量恢复 到原始输入状态。过程如下图:
3:支持向量机支持向量机(support vector machine, SVM)〔1〕是近几年来发展起 来的新型分类方法,是在高维特征空间使用线性函数假设空间的学习系 统,在分类方面具有良好的性能。近几年来,支持向量机在模式识别、 知识发现等理论研究,计算机视觉与图像识别、生物信息学以及自然语 言处理等相关技术研究中得到了广泛应用。在自然语言处理中,SVM广 泛应用于短语识别、词义消歧、文本自动分类和信息过滤等方面。
3-1:线性分类:通过执行如下操作进行:当f(x)≥0 时,将输入x=(x1,x2,…,xn)′赋予正类,否则,将其赋予负类。当 f(x)(x∈X)是线性函数时,f(x)可以写成如下形式:
其实就是一个线性函数,如果他的值>0那么此时他的自变量是正类。该分类方法的几何解释是,方程式〈w·x〉+b=0定义的超平面将 输入空间X分成两半,一半为负类,一半为正类,如图2-5所示:
可以理解为图2-5中的黑斜线表示超平面当b的值变化时,超平面平行移动。因此,如果想表达 中所有 可能的超平面,一般要包括n+1个可调参数的表达式。如果训练数据可以被无误差地划分,那么,以最大间隔分开数据的 超平面称为最优超平面,如图2-6所示。
目前个人理解的是,先用两条平行线使正负集分隔开同时时这两条线之间距离最大,然后最优超平面就是这两条线中间的那条平行线。
3-2:线性不可分:建立非线性分类器需要分两步:首先使用一个非线性映射函数将数据变换到一个特征空间F,然后在这个特征空间上使用线性分类器。线性分类器的一个重要性质是可以表示成对偶形式,这意味着假设 可以表达为训练点和线性组合,因此,决策规则(分类函数)可以用测 试点和训练点的内积来表示:
其中,l是样本数目;αi是个正值导数,可通过学习获得;yi为类别标 记。如果有一种方法可以在特征空间中直接计算内积,就像在原始输入点的函数中一样,那么,就有可能将两个步 骤融合到一起建立一个非线性分类器。这样,在高维空间内实际上只需 要进行内积运算,而这种内积运算是可以利用原空间中的函数实现的, 我们甚至没有必要知道变换的形式。这种直接计算的方法称为核 (kernel)函数方法。3-3:核函数的构造:
核是一个函数K,对所有x, z∈X,满足:
其中
是从X到(内积)特征空间F的映射。同时核函数要适合某个特征空间必须是对称的,即
并且需要满足
但是,这些条件对于保证特征空间的存在是不 充分的,还必须满足Mercer定理的条件,对X的任意有限子集,相应的 矩阵是半正定的。也就是说,令X是有限输入空间,K(x, z)是X上的 对称函数。那么,K(x, z)是核函数的充分必要条件是矩阵
是半正定的(即特征值非负)。

相关文章推荐
- 什么是一本出色的linux内核书籍(我的代码阅读心得体会)
- 自然语言处理入门心得——书籍、课程推荐
- 用户研究_书籍阅读心得(一)
- 自然语言处理入门心得——书籍、课程推荐
- 统计自然语言处理书籍阅读心得三
- 一些关于机器学习和统计方面值得阅读的书籍
- 统计自然语言处理书籍阅读心得一
- 统计自然语言处理书籍阅读心得五
- 统计自然语言处理书籍阅读心得二
- Java生成二维码实现扫描次数统计并转发到某个地址 分类: 二维码 Java 2015-01-08 10:38 408人阅读 评论(0) 收藏
- Java程序员的推荐阅读书籍
- 【论文阅读心得】图像识别中一个常用词的中英文释义——artifact
- 数学书籍阅读
- 编程书籍阅读随谈(第一篇)
- 2015070904 - 阅读后的书籍有着落了
- 图书馆推荐阅读:香港大学推荐的44本经典书籍
- Java程序员到架构师的推荐阅读书籍
- uboot Stage1阅读的一些心得
- 全栈工程师体能备战--阅读的书籍
- 如何阅读软件测试书籍(一), the little black book on test design