深度学习基石:一篇文章理解反向传播
2018-04-06 18:16
495 查看
原文地址:https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/

为了使用一些数字,下面是最初的权重,偏见和培训输入/输出:
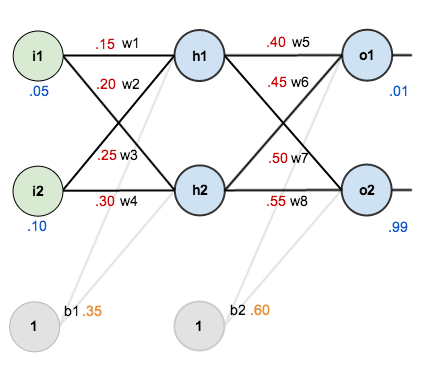
反向传播的目标是优化权重,以便神经网络可以学习如何正确映射任意输入到输出。对于本教程的其余部分,我们将使用单个训练集:给定输入0.05和0.10,我们希望神经网络输出0.01和0.99。
4000
里我们使用的逻辑功能),然后重复上述过程与输出层的神经元。总净输入也被称为只是净输入的一些消息来源。以下是我们计算总净投入的方法
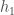
:


然后我们使用逻辑函数对其进行压缩以获得以下输出
:

执行相同的过程,
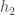
我们得到:

我们重复这个过程为输出层神经元,使用隐藏层神经元的输出作为输入。以下是输出

:

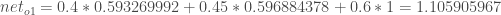
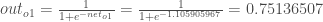
并执行相同的过程,

我们得到:


有些来源将目标称为理想,而输出则以实际为目标。这

是包括的,以便指数在我们稍后区分时被取消。无论如何,结果最终会乘以学习率,所以我们在这里引入一个常数并不重要[ 1 ]。例如,目标输出为
0.01,但神经网络输出为0.75136507,因此其误差为:

重复这个过程
(记住目标是0.99),我们得到:

神经网络的总误差是这些误差的总和:

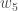
。我们想知道变化
会影响总误差,也就是说
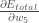
。

读作“部分的衍生物

相对于

”。你也可以说“关于梯度
”。通过应用链式规则,我们知道:

在视觉上,这是我们正在做的事情:

我们需要找出这个方程中的每一部分。首先,总误差相对于输出的变化有多大?



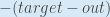
有时表达为
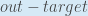
当我们取总偏差的偏导数时
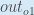
,数量

变为零,因为
它不影响它,这意味着我们正在取一个常数为零的导数。接下来,
相对于其总净投入的变化输出多少?逻辑函数的偏导数是输出乘以1减去输出:

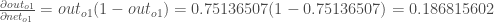
最后,关于

变化的总净投入是
多少?
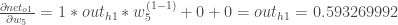
把它放在一起:


您经常会看到以delta规则的形式组合这个计算:

或者,我们有
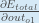
和

可以写成

,又名

(希腊字母三角洲)aka 节点三角洲。我们可以用它来重写上面的计算:


因此:

有些来源提取负号,
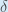
所以它会写成:
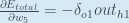
为了减少误差,我们从当前权重中减去这个值(可选地乘以一些学习率eta,我们将其设置为0.5):

有些 来源使用

(alpha)来表示学习率,其他来源使用
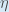
(eta),其他使用

(epsilon)。我们可以重复这个过程中获得新的权重
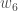
,
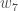
以及

:

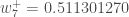
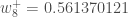
在我们将新权重引入隐含层神经元之后,我们执行神经网络中的实际更新(即,当我们继续下面的反向传播算法时,我们使用原始权重,而不是更新的权重)。
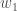
,
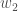
,

,和

。大图片,这是我们需要弄清楚的:

视觉:
我们将使用与输出层类似的过程,但略有不同,以说明每个隐藏层神经元的输出对多个输出神经元的输出(并因此产生误差)的贡献。我们知道这

影响到两者
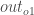
,

因此

需要考虑它对两个输出神经元的影响:

从以下开始

:

我们可以

使用我们之前计算的值来计算:

并且
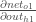
等于
:
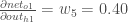
将它们插入:
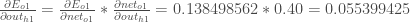
按照相同的过程

,我们得到:

因此:
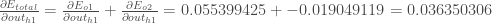
现在,我们有
,我们需要弄清楚
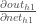
,然后

每一个权重:
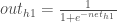

我们计算总净投入的偏导数,
与
我们对输出神经元所做的相同:
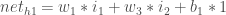

把它放在一起:

你也可以看到这写成:
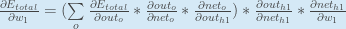


我们现在可以更新
:

重复这些
,
和
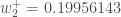

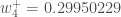
最后,我们已经更新了所有的重量!当我们最初输入0.05和0.1的输入时,网络上的误差为0.298371109。在第一轮反向传播之后,总误差现在降至0.291027924。它可能看起来并不多,但是在重复这个过程10,000次后,错误会直线下降到0.0000351085。此时,当我们提前0.05和0.1时,两个输出神经元产生0.015912196(vs 0.01目标)和0.984065734(vs 0.99目标)。如果你已经做到了这一点,并发现上述任何错误,或者可以想出任何方法使未来的读者更清楚,不要犹豫,给我一个笔记。谢谢!
逐步反向传播示例
背景
反向传播是训练神经网络的常用方法,之前对此一直了解的不够彻底,这篇文章算是让我彻底搞懂了反向传播的细节。概观
对于本教程,我们将使用具有两个输入,两个隐藏的神经元,两个输出神经元的神经网络。此外,隐藏和输出神经元将包括一个偏见。基本结构如下:为了使用一些数字,下面是最初的权重,偏见和培训输入/输出:
反向传播的目标是优化权重,以便神经网络可以学习如何正确映射任意输入到输出。对于本教程的其余部分,我们将使用单个训练集:给定输入0.05和0.10,我们希望神经网络输出0.01和0.99。
前进通行证
首先,让我们看看神经网络目前预测的是什么,给定0.05和0.10的权重和偏差。为此,我们将通过网络向前馈送这些输入。我们计算出净输入总到每个隐藏层神经元,壁球使用的总净输入激活功能(在这4000
里我们使用的逻辑功能),然后重复上述过程与输出层的神经元。总净输入也被称为只是净输入的一些消息来源。以下是我们计算总净投入的方法
:
然后我们使用逻辑函数对其进行压缩以获得以下输出
:
执行相同的过程,
我们得到:
我们重复这个过程为输出层神经元,使用隐藏层神经元的输出作为输入。以下是输出
:
并执行相同的过程,
我们得到:
计算总误差
现在我们可以使用平方误差函数来计算每个输出神经元的误差,并将它们相加得到总误差:有些来源将目标称为理想,而输出则以实际为目标。这
是包括的,以便指数在我们稍后区分时被取消。无论如何,结果最终会乘以学习率,所以我们在这里引入一个常数并不重要[ 1 ]。例如,目标输出为
0.01,但神经网络输出为0.75136507,因此其误差为:
重复这个过程
(记住目标是0.99),我们得到:
神经网络的总误差是这些误差的总和:
向后传递
我们使用反向传播的目标是更新网络中的每个权重,使它们使实际输出更接近目标输出,从而最大限度地减少每个输出神经元和整个网络的误差。输出层
考虑一下。我们想知道变化
会影响总误差,也就是说
。
读作“部分的衍生物
相对于
”。你也可以说“关于梯度
”。通过应用链式规则,我们知道:
在视觉上,这是我们正在做的事情:
我们需要找出这个方程中的每一部分。首先,总误差相对于输出的变化有多大?
有时表达为
当我们取总偏差的偏导数时
,数量
变为零,因为
它不影响它,这意味着我们正在取一个常数为零的导数。接下来,
相对于其总净投入的变化输出多少?逻辑函数的偏导数是输出乘以1减去输出:
最后,关于
变化的总净投入是
多少?
把它放在一起:
您经常会看到以delta规则的形式组合这个计算:
或者,我们有
和
可以写成
,又名
(希腊字母三角洲)aka 节点三角洲。我们可以用它来重写上面的计算:
因此:
有些来源提取负号,
所以它会写成:
为了减少误差,我们从当前权重中减去这个值(可选地乘以一些学习率eta,我们将其设置为0.5):
有些 来源使用
(alpha)来表示学习率,其他来源使用
(eta),其他使用
(epsilon)。我们可以重复这个过程中获得新的权重
,
以及
:
在我们将新权重引入隐含层神经元之后,我们执行神经网络中的实际更新(即,当我们继续下面的反向传播算法时,我们使用原始权重,而不是更新的权重)。
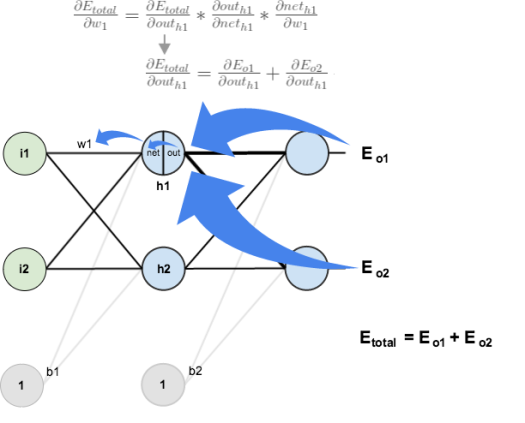
隐藏层
接下来,我们将继续为新的计算值,向后传递,
,
,和
。大图片,这是我们需要弄清楚的:
视觉:

我们将使用与输出层类似的过程,但略有不同,以说明每个隐藏层神经元的输出对多个输出神经元的输出(并因此产生误差)的贡献。我们知道这
影响到两者
,
因此
需要考虑它对两个输出神经元的影响:
从以下开始
:
我们可以
使用我们之前计算的值来计算:
并且
等于
:
将它们插入:
按照相同的过程
,我们得到:
因此:
现在,我们有
,我们需要弄清楚
,然后
每一个权重:
我们计算总净投入的偏导数,
与
我们对输出神经元所做的相同:
把它放在一起:
你也可以看到这写成:
我们现在可以更新
:
重复这些
,
和
最后,我们已经更新了所有的重量!当我们最初输入0.05和0.1的输入时,网络上的误差为0.298371109。在第一轮反向传播之后,总误差现在降至0.291027924。它可能看起来并不多,但是在重复这个过程10,000次后,错误会直线下降到0.0000351085。此时,当我们提前0.05和0.1时,两个输出神经元产生0.015912196(vs 0.01目标)和0.984065734(vs 0.99目标)。如果你已经做到了这一点,并发现上述任何错误,或者可以想出任何方法使未来的读者更清楚,不要犹豫,给我一个笔记。谢谢!

相关文章推荐
- 深度学习与计算机视觉系列(5)_反向传播与它的直观理解
- 深度学习与计算机视觉系列(5)_反向传播与它的直观理解
- 深度学习与计算机视觉系列(5)_反向传播与它的直观理解
- 深度学习与计算机视觉系列(5)_反向传播与它的直观理解
- 深度学习与计算机视觉系列(5)_反向传播与它的直观理解
- 深度学习与计算机视觉系列(5)_反向传播与它的直观理解
- 深度学习与计算机视觉系列(5)_反向传播与它的直观理解
- 深度学习与计算机视觉系列(5)_反向传播与它的直观理解
- 深度学习小白——反向传播
- 深度学习要另起炉灶,彻底抛弃反向传播
- TensorFlow 深度学习框架 (2)-- 反向传播优化神经网络
- TensorFlow 深度学习框架 (2)-- 反向传播优化神经网络
- UFLDL深度学习笔记 (一)反向传播与稀疏自编码
- 对生成对抗网络GANs原理、实现过程、应用场景的理解(附代码),另附:深度学习大神文章列表
- TensorFlow 深度学习框架 (2)-- 反向传播优化神经网络
- TensorFlow 深度学习框架 (2)-- 反向传播优化神经网络
- TensorFlow深度学习,一篇文章就够了
- TensorFlow深度学习,一篇文章就够了
- TensorFlow 深度学习框架 (2)-- 反向传播优化神经网络
- TensorFlow 深度学习框架 (2)-- 反向传播优化神经网络