Linux内核【链表】整理笔记(1)【转】
2018-04-03 00:14
204 查看
转自:http://blog.chinaunix.net/uid-23069658-id-4576255.html我们都知道Linux内核里的双向链表和学校里教给我们的那种数据结构还是些不一样。Linux采用了一种更通用的设计,将链表以及其相关操作函数从数据本身进行剥离,这样我们在使用链表的时候就不用自己去实现诸如节点的插入、删除、遍历等操作了。当然,Linux也是从2.1.x内核开始才对链表进行了这样的统一,和我们目前看到的样子几乎差不多:点击(此处)折叠或打开struct list_head {
struct list_head *next, *prev;
};
在2.6.21里这个数据结构定义在include/liinux/list.h头文件里,但是在3.4.1内核里,以及后面要介绍的哈希链表的定义都放在include/linux/types.h头文件里。而本文将以3.4.1内核为例进行介绍,其实对链表来说内核的版本号几乎没什么影响,只要掌握了Linux设计链表的精髓,万变不离其宗。
今天我们首先来聊聊链表。从上述定义代码我们可以看出,Linux内核的链表是双向链表,如果我们要将自己的数据结构以链表的形式进行组织,那么只要在我们自己的数据结构里,增加一个struct list_head{}类型的结构体成员对象就可以了,这样,我们就可以很方便地使用内核提供给我们的一组标准接口来对链表进行各种操作。
如果我们需要定义一个链表,内核有LIST_HEAD(name)这样的函数供我们使用:点击(此处)折叠或打开#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
其中#define LIST_HEAD_INIT(name) { &(name), &(name) },其实这样的代码已经太简单不过了。如果我们要定义一个名为student_list的链表,直接LIST_HEAD(student_list)就可以了,展开后等价于下面的代码:点击(此处)折叠或打开struct list_head student_list= { &(student_list), &(student_list) };
跟内核通
af1c
知链类似,如果我们已经有了一个链表对象student_list,INIT_LIST_HEAD()接口可以对它初始化。所以,LIST_HEAD(student_list)代码和下面的代码是等价的:点击(此处)折叠或打开struct list_head student_list;
INIT_LIST_HEAD (&student_list);
假如,我们现在要定义一个学生的结构体,并让其组织成链表的形式,可以这样做:点击(此处)折叠或打开#define NAME_MAX_SIZE 32
typedef struct student{
char name[NAME_MAX_SIZE]; /*姓名*/
unsigned char sex; /*性别:m-男生;f-女生*/
unsigned char age; /*年龄*/
struct list_head stu_list; /*所有的学生最终通过这个结构串成链表*/
}Student;
那么在写代码时,如果是通过kmalloc之类的函数动态创建节点,我们就可以用下面代码对链表节点进行初始化:点击(此处)折叠或打开Student *stu1;
stu1 = kmalloc(sizeof(*stu1), GFP_KERNEL);
strcpy(stu1->name,”xiaoming”);
stu1->sex = ‘m’;
stu1->age = 18;
INIT_LIST_HEAD(&stu1-> stu_list); /*和下面的用法注意区别*/
如果是静态定义结构体变量的话就更简单了:点击(此处)折叠或打开Student stu2={
.name={“xiaohong”},
.sex=’f’,
.age=18,
.stu_list = LIST_HEAD_INIT(stu2.stu_list); /*和上面的用法注意区别*/
};
有了数据节点,接下来就要对其进行操作了,内核提供了一组常用接口用于对双向链表操作,如下。
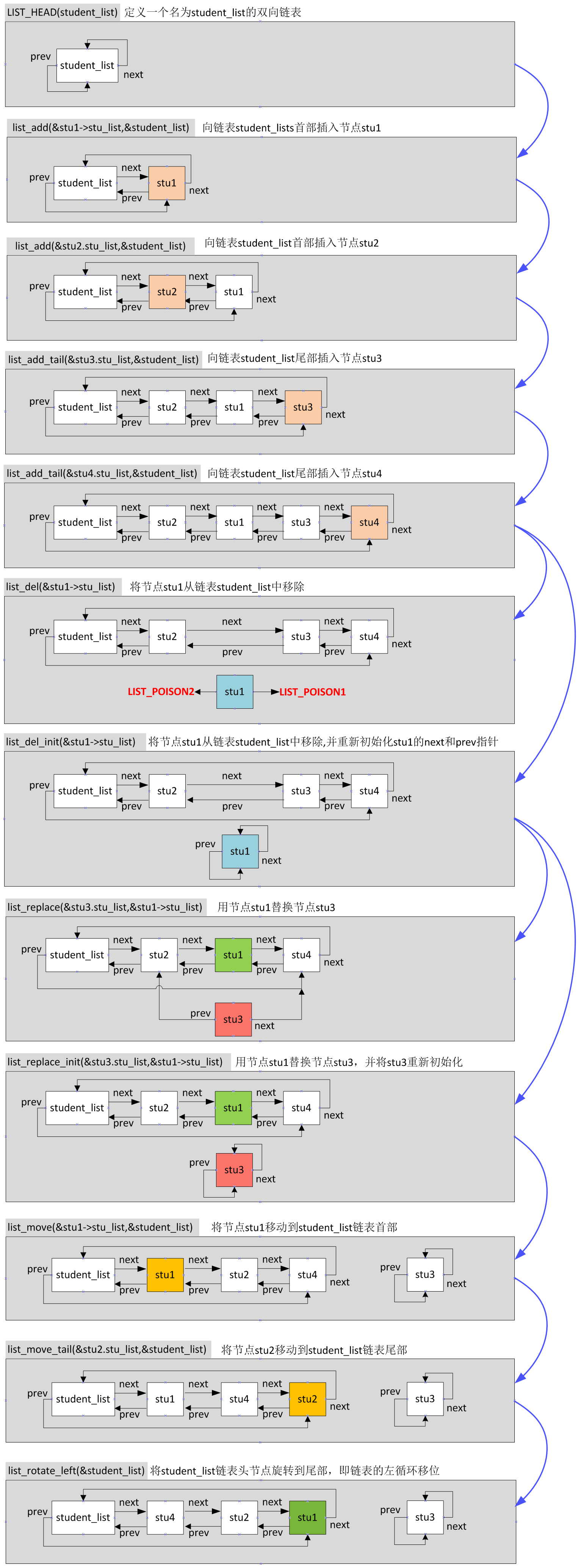
还有关于链表的分割list_cut_position(*list,*head,*entry)以及合并list_splice(*list,*head)、list_splice_init (*list,*head)、list_splice_tail (*list,*head)、list_splice_tail_init (*list,*head)这几个API用法也都非常简单,对照内核源码的注释很轻松就可以上手了。
通过上面的图我们可以看出来,在内核中当我们提及链表头的时候其实并没有牵扯到我们自己的结构体数据本身,链表头的next所指向的节点才是真正意义上的“链表头节点”,prev所指向的节点叫做“链表尾节点”。注意,不要把链表头和链表的头节点混为一谈。有了这个认识之后,我们就知道如果链表头的next和prev都指向链表头本身的话,那么这个链表其实就是空的,例如list_empty()或者list_empty_careful()所做的事情就是给定一个链表头,判断其是否为空,即是否包含任何有效的数据节点。同样地,如何判断链表是否只有一个节点呢?看看list_is_singular()的实现就豁然开朗了,真的是so easy。
最后,将前面提及的API总结到下表2.1中,方便大家查阅。
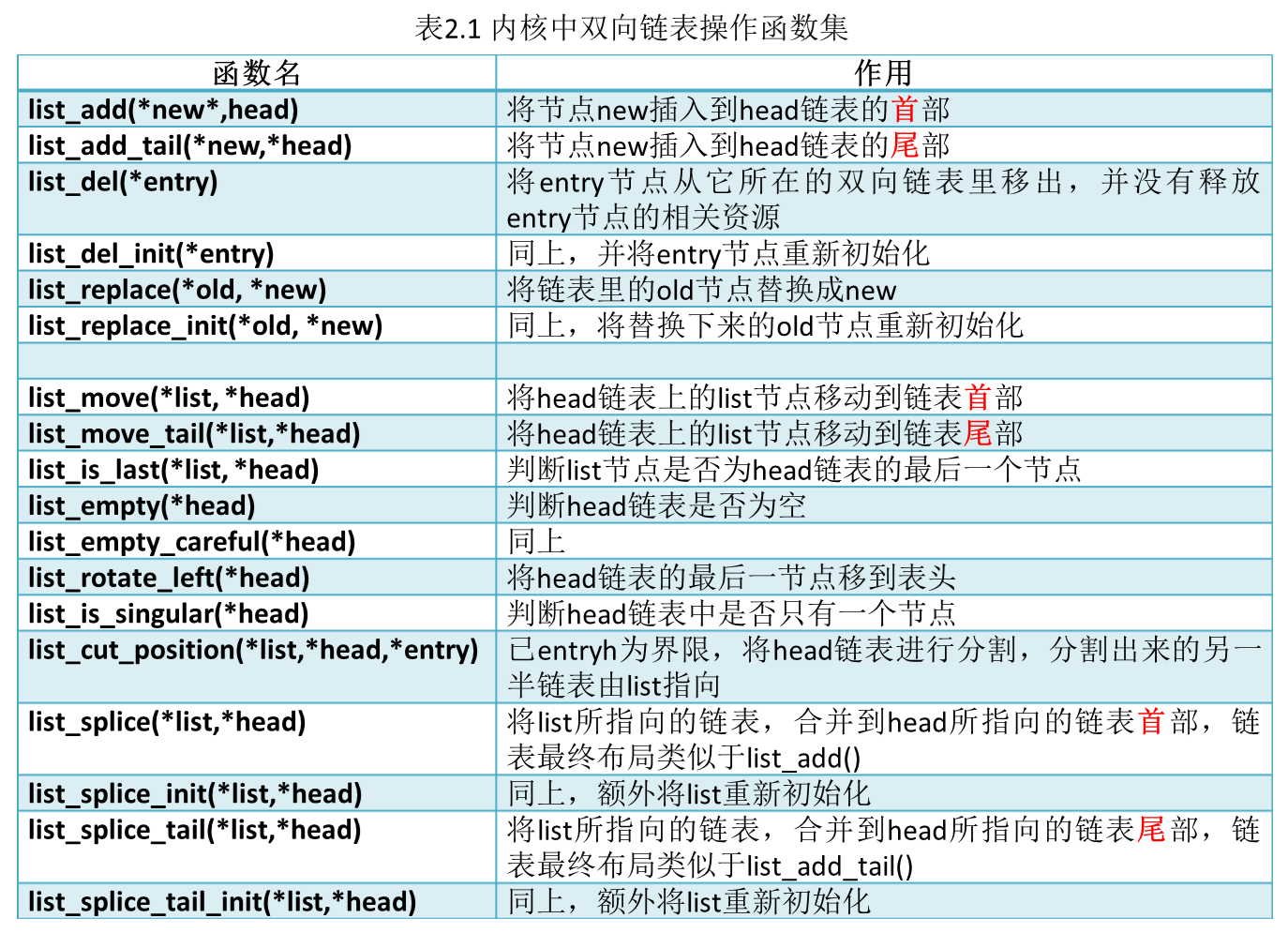
需要注意的是,上述所有链表操作函数的入参都是struct list_head{}的指针类型,这一点需要时刻牢记在心。
struct list_head *next, *prev;
};
在2.6.21里这个数据结构定义在include/liinux/list.h头文件里,但是在3.4.1内核里,以及后面要介绍的哈希链表的定义都放在include/linux/types.h头文件里。而本文将以3.4.1内核为例进行介绍,其实对链表来说内核的版本号几乎没什么影响,只要掌握了Linux设计链表的精髓,万变不离其宗。
今天我们首先来聊聊链表。从上述定义代码我们可以看出,Linux内核的链表是双向链表,如果我们要将自己的数据结构以链表的形式进行组织,那么只要在我们自己的数据结构里,增加一个struct list_head{}类型的结构体成员对象就可以了,这样,我们就可以很方便地使用内核提供给我们的一组标准接口来对链表进行各种操作。
如果我们需要定义一个链表,内核有LIST_HEAD(name)这样的函数供我们使用:点击(此处)折叠或打开#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
其中#define LIST_HEAD_INIT(name) { &(name), &(name) },其实这样的代码已经太简单不过了。如果我们要定义一个名为student_list的链表,直接LIST_HEAD(student_list)就可以了,展开后等价于下面的代码:点击(此处)折叠或打开struct list_head student_list= { &(student_list), &(student_list) };
跟内核通
af1c
知链类似,如果我们已经有了一个链表对象student_list,INIT_LIST_HEAD()接口可以对它初始化。所以,LIST_HEAD(student_list)代码和下面的代码是等价的:点击(此处)折叠或打开struct list_head student_list;
INIT_LIST_HEAD (&student_list);
假如,我们现在要定义一个学生的结构体,并让其组织成链表的形式,可以这样做:点击(此处)折叠或打开#define NAME_MAX_SIZE 32
typedef struct student{
char name[NAME_MAX_SIZE]; /*姓名*/
unsigned char sex; /*性别:m-男生;f-女生*/
unsigned char age; /*年龄*/
struct list_head stu_list; /*所有的学生最终通过这个结构串成链表*/
}Student;
那么在写代码时,如果是通过kmalloc之类的函数动态创建节点,我们就可以用下面代码对链表节点进行初始化:点击(此处)折叠或打开Student *stu1;
stu1 = kmalloc(sizeof(*stu1), GFP_KERNEL);
strcpy(stu1->name,”xiaoming”);
stu1->sex = ‘m’;
stu1->age = 18;
INIT_LIST_HEAD(&stu1-> stu_list); /*和下面的用法注意区别*/
如果是静态定义结构体变量的话就更简单了:点击(此处)折叠或打开Student stu2={
.name={“xiaohong”},
.sex=’f’,
.age=18,
.stu_list = LIST_HEAD_INIT(stu2.stu_list); /*和上面的用法注意区别*/
};
有了数据节点,接下来就要对其进行操作了,内核提供了一组常用接口用于对双向链表操作,如下。
还有关于链表的分割list_cut_position(*list,*head,*entry)以及合并list_splice(*list,*head)、list_splice_init (*list,*head)、list_splice_tail (*list,*head)、list_splice_tail_init (*list,*head)这几个API用法也都非常简单,对照内核源码的注释很轻松就可以上手了。
通过上面的图我们可以看出来,在内核中当我们提及链表头的时候其实并没有牵扯到我们自己的结构体数据本身,链表头的next所指向的节点才是真正意义上的“链表头节点”,prev所指向的节点叫做“链表尾节点”。注意,不要把链表头和链表的头节点混为一谈。有了这个认识之后,我们就知道如果链表头的next和prev都指向链表头本身的话,那么这个链表其实就是空的,例如list_empty()或者list_empty_careful()所做的事情就是给定一个链表头,判断其是否为空,即是否包含任何有效的数据节点。同样地,如何判断链表是否只有一个节点呢?看看list_is_singular()的实现就豁然开朗了,真的是so easy。
最后,将前面提及的API总结到下表2.1中,方便大家查阅。
需要注意的是,上述所有链表操作函数的入参都是struct list_head{}的指针类型,这一点需要时刻牢记在心。

相关文章推荐
- Linux内核【链表】整理笔记(2) 【转】
- Linux内核【链表】整理笔记(1)
- Linux内核【链表】整理笔记(1)
- Linux内核【链表】整理笔记(2)
- Linux内核【链表】整理笔记(1)
- Linux内核【链表】整理笔记(2)
- Linux内核【链表】整理笔记(2) 【转】
- Linux内核【链表】整理笔记(1)
- Linux内核【链表】整理笔记(1)
- C++链表AT&T代码,通过Ubuntu实现生成(Linux内核分析笔记)
- Linux内核【链表】整理笔记(1)
- 韩顺平_PHP程序员玩转算法公开课(第一季)11_双向链表在内存中存在形式剖析_学习笔记_源代码图解_PPT文档整理
- 韩顺平_PHP程序员玩转算法公开课(第一季)03_单链表crud操作之_水浒英雄排行算法_学习笔记_源代码图解_PPT文档整理
- 韩顺平_PHP程序员玩转算法公开课(第一季)05_使用单链表解决约瑟夫问题_学习笔记_源代码图解_PPT文档整理
- (笔记)Linux内核学习(九)之内核内存管理方式
- QML笔记整理——QML高级特性
- C++入门经典 笔记 (第十九章)使用链表存储信息
- 数据结构笔记整理第2章:线性表
- Deep Learning(深度学习)学习笔记整理系列之(五)
- SQL Server 笔记整理