CodeForces - 937D Sleepy Game (乘法逆元)
2018-03-29 15:24
260 查看
Fafa and Ancient Alphabettime limit per test2 secondsmemory limit per test256 megabytesinputstandard inputoutputstandard outputAncient Egyptians are known to have used a large set of symbols
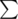
to write on the walls of the temples. Fafa and Fifa went to one of the temples and found two non-empty words S1 and S2 of equal lengths on the wall of temple written one below the other. Since this temple is very ancient, some symbols from the words were erased. The symbols in the set
have equal probability for being in the position of any erased symbol.Fifa challenged Fafa to calculate the probability that S1 is lexicographically greater than S2. Can you help Fafa with this task?You know that
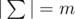
, i. e. there were m distinct characters in Egyptians' alphabet, in this problem these characters are denoted by integers from 1 to m in alphabet order. A word xis lexicographically greater than a word y of the same length, if the words are same up to some position, and then the word x has a larger character, than the word y.We can prove that the probability equals to some fraction
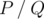
, where P and Q are coprime integers, and
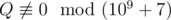
. Print as the answer the value
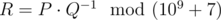
, i. e. such a non-negative integer less than 109 + 7, such that
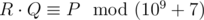
, where
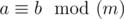
means that a and b give the same remainders when divided by m.InputThe first line contains two integers n and m (1 ≤ n, m ≤ 105) — the length of each of the two words and the size of the alphabet
, respectively.The second line contains n integers a1, a2, ..., an (0 ≤ ai ≤ m) — the symbols of S1. If ai = 0, then the symbol at position i was erased.The third line contains n integers representing S2 with the same format as S1.OutputPrint the value
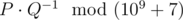
, where P and Q are coprime and
is the answer to the problem.ExamplesinputCopy
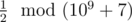
, that is 500000004, because
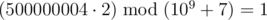
.In the second example, there is no replacement for the zero in the second word that will make the first one lexicographically larger. So, the answer to the problem is
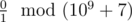
, that is 0.
题意:求S1>S2的概率,字符串某些位置可能为空,空的话,里面的字符可以是任意的。
解题思路:先把公式推出来,公式很好推。分三种情况讨论,a[i]==b[i],a[i]==0&&b[i]!=0,a[i]!=0&&b[i]==0 三种情况分别计算概率,然后相加即可!中间所有的除法,用乘法逆元代替!
#include <bits/stdc++.h>
using namespace std;
typedef long long int ll;
const int MOD=1e9+7;
ll qpow(ll a,ll b,ll c){
ll ans=1;
ll temp=a;
while(b!=0){
if(b%2)ans=ans*temp%c;
temp=temp*temp%c;
b/=2;
}
return ans;
}
ll a[100005];
ll b[100005];
int main()
{
ll N,M;
cin>>N>>M;
for(int i=0;i<N;i++)
cin>>a[i];
for(int i=0;i<N;i++)
cin>>b[i];
ll one=qpow(M,MOD-2,MOD);
ll two=qpow(M*M%MOD,MOD-2,MOD);
ll ans=0;
ll cur=1;
for(int i=0;i<N;i++){
if(a[i]==0&&b[i]==0){
ans=(ans+cur*((M*M-M)/2)%MOD*two%MOD)%MOD;
cur=cur*one%MOD;
}
else{
if(a[i]==0&&b[i]!=0){
ans=(ans+cur*(M-b[i])%MOD*one%MOD)%MOD;
cur=cur*one%MOD;
}
else{
if(a[i]!=0&&b[i]==0){
ans=(ans+cur*(a[i]-1)%MOD*one%MOD)%MOD;
cur=cur*one%MOD;
}
else{
if(a[i]>b[i]){
ans=(ans+cur)%MOD;
break;
}
else{
if(a[i]==b[i])
continue;
else
break;
}
}
}
}
}
cout<<ans<<endl;
return 0;
}
to write on the walls of the temples. Fafa and Fifa went to one of the temples and found two non-empty words S1 and S2 of equal lengths on the wall of temple written one below the other. Since this temple is very ancient, some symbols from the words were erased. The symbols in the set
have equal probability for being in the position of any erased symbol.Fifa challenged Fafa to calculate the probability that S1 is lexicographically greater than S2. Can you help Fafa with this task?You know that
, i. e. there were m distinct characters in Egyptians' alphabet, in this problem these characters are denoted by integers from 1 to m in alphabet order. A word xis lexicographically greater than a word y of the same length, if the words are same up to some position, and then the word x has a larger character, than the word y.We can prove that the probability equals to some fraction
, where P and Q are coprime integers, and
. Print as the answer the value
, i. e. such a non-negative integer less than 109 + 7, such that
, where
means that a and b give the same remainders when divided by m.InputThe first line contains two integers n and m (1 ≤ n, m ≤ 105) — the length of each of the two words and the size of the alphabet
, respectively.The second line contains n integers a1, a2, ..., an (0 ≤ ai ≤ m) — the symbols of S1. If ai = 0, then the symbol at position i was erased.The third line contains n integers representing S2 with the same format as S1.OutputPrint the value
, where P and Q are coprime and
is the answer to the problem.ExamplesinputCopy
1 2 0 1output
500000004inputCopy
1 2 1 0output
0inputCopy
7 26output
0 15 12 9 13 0 14
11 1 0 13 15 12 0
230769233NoteIn the first sample, the first word can be converted into (1) or (2). The second option is the only one that will make it lexicographically larger than the second word. So, the answer to the problem will be
, that is 500000004, because
.In the second example, there is no replacement for the zero in the second word that will make the first one lexicographically larger. So, the answer to the problem is
, that is 0.
题意:求S1>S2的概率,字符串某些位置可能为空,空的话,里面的字符可以是任意的。
解题思路:先把公式推出来,公式很好推。分三种情况讨论,a[i]==b[i],a[i]==0&&b[i]!=0,a[i]!=0&&b[i]==0 三种情况分别计算概率,然后相加即可!中间所有的除法,用乘法逆元代替!
#include <bits/stdc++.h>
using namespace std;
typedef long long int ll;
const int MOD=1e9+7;
ll qpow(ll a,ll b,ll c){
ll ans=1;
ll temp=a;
while(b!=0){
if(b%2)ans=ans*temp%c;
temp=temp*temp%c;
b/=2;
}
return ans;
}
ll a[100005];
ll b[100005];
int main()
{
ll N,M;
cin>>N>>M;
for(int i=0;i<N;i++)
cin>>a[i];
for(int i=0;i<N;i++)
cin>>b[i];
ll one=qpow(M,MOD-2,MOD);
ll two=qpow(M*M%MOD,MOD-2,MOD);
ll ans=0;
ll cur=1;
for(int i=0;i<N;i++){
if(a[i]==0&&b[i]==0){
ans=(ans+cur*((M*M-M)/2)%MOD*two%MOD)%MOD;
cur=cur*one%MOD;
}
else{
if(a[i]==0&&b[i]!=0){
ans=(ans+cur*(M-b[i])%MOD*one%MOD)%MOD;
cur=cur*one%MOD;
}
else{
if(a[i]!=0&&b[i]==0){
ans=(ans+cur*(a[i]-1)%MOD*one%MOD)%MOD;
cur=cur*one%MOD;
}
else{
if(a[i]>b[i]){
ans=(ans+cur)%MOD;
break;
}
else{
if(a[i]==b[i])
continue;
else
break;
}
}
}
}
}
cout<<ans<<endl;
return 0;
}

相关文章推荐
- CodeForces - 937D Sleepy Game (深搜判环)
- CodeForces - 937D Sleepy Game [dfs+DP]
- Codeforces 937D - Sleepy Game 【博弈+判环】
- Codeforces 785D Anton and School - 2 (范德蒙恒等式+ 乘法逆元)
- Codeforces 521C 组合数取模(乘法逆元)
- Codeforces-936B:Sleepy Game(DP)
- codeforces 300C 乘法逆元 (乘法逆元模为素数的模板)
- Codeforces 327C 乘法逆元 + 费马小定理 || 等比数列二分求和取模
- CodeForces 300C Beautiful Numbers (乘法逆元+快速幂(含乘法逆元的讲解))
- Codeforces 543D. Road Improvement (树dp + 乘法逆元)
- Codeforces 543D Road Improvement(树形DP + 乘法逆元)
- CodeForces-696C Please(数学题,快速幂取模,乘法逆元)
- Codeforces 300C Beautiful Numbers 乘法逆元
- Codeforces 711E ZS and The Birthday Paradox(乘法逆元)
- CodeForces - 557A Ilya and Diplomas
- Codeforces 682C Alyona and the Tree【Dfs+YY思维】好题
- codeforces 322 B Ciel and Flowers
- #codeforces 546C# Soldier and Cards (模拟)
- Codeforces 314B(倍增)
- CodeForces 317 D.Game with Powers(博弈论)