联合索引优化多条件查询
2018-03-29 11:38
357 查看
联合索引是由多个字段组成的组合索引。若经常需要使用多个字段的多条件查询(WHERE col1 = … AND col2 = … AND col3 = …),可以考虑使用联合索引。
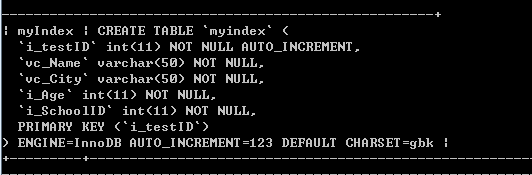
现在数据表myIndex中i_testID是主键列,其他列无任何索引:
多条件查找名字为xiaoming,城市为beijing,年龄为21的人:
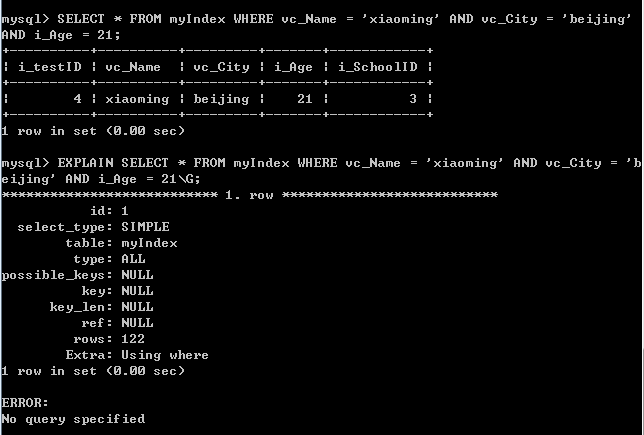
返回了一行数据,从执行计划中看到,查询没有使用任何索引,进行了全表扫描,磁盘IO大。
为vc_Name建立索引:

进行同样的查询并查看执行计划:
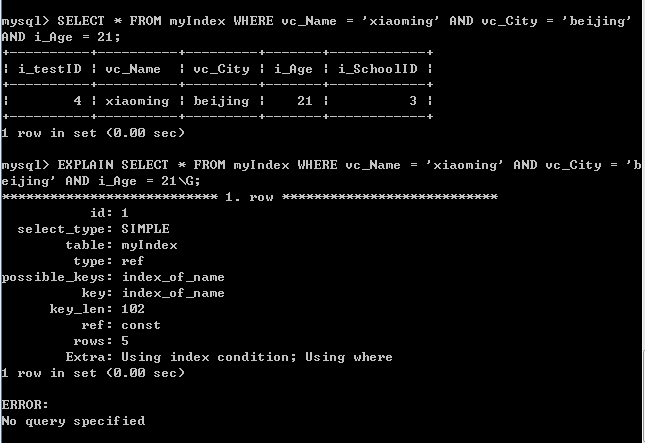
返回了相同的结果,分析执行计划:SQL通过刚刚建立的index_of_name索引,不再进行全表扫描,而是先在索引中查找满足节点值为xiaoming的节点(有5个),再指向数据库中相应的行,返回一个初步结果集后再由另外两个条件进行一步步筛选得到最终结果。大大减少了磁盘IO,查询效率也高于前者。
虽然在 vc_Name 上建立了索引,查询时MYSQL不用扫描整张表,效率有所提高,但离我们的要求还有一定的距离。同样的,在 vc_City 和 i_Age 分别建立的MySQL单列索引的效率相似。为了进一步榨取 MySQL 的效率,就要考虑建立组合索引。
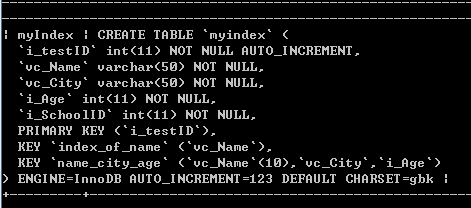
为多条件涉及的列建立联合索引:

值得注意的是,建立索引的时候应该根据需要规定索引长度,例如一个人的名字长度应该不会超过10个字符,通过vc_Name(10)规定索引长度后一定长度可以减少索引所占内存。
现在表中的结构:
进行相同的查询并查看执行计划:
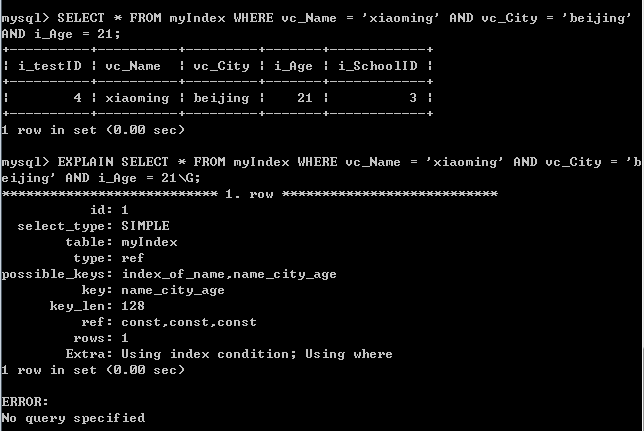
返回相同的结果,从执行计划可以看到:本次查询使用了联合索引name_city_age,在遍历索引时就确定了只有一个节点满足条件,直接指向数据库表进行查询(rows:1)。有更少的磁盘IO,所用时间更少!
使用联合索引应该注意:
MySQL使用联合索引只能使用左侧的部分,例如INDEX(a,b,c),当条件为a或a,b或a,b,c时都可以使用索引,但是当条件为b,c时将不会使用索引。这好比一本先根据姓,再根据名进行排序的电话簿,当查找的时候有姓的条件,效率会比没有任何条件高;如果在姓的基础上还有名的条件,效率会更高;但若只有名的条件,电话簿将不起作用。
离散度更高的索引应该放在联合索引的前面,因为离散度高索引的可选择性高。考虑一种极端的情况,数据表中有100条记录,若INDEX(a,b)中a只有两种情况,而b有100种情况。这样对于查询唯一记录a = …,b = …时,先遍历全部索引看满足a条件的有50个索引节点,接下来还要再一个个遍历这50个索引节点。如果是INDEX(b,a),先遍历全部索引发现满足b条件的索引节点只有一个,再遍历这个节点发现也满足a条件。虽然最后都能找到那个唯一的索引节点,但是第二种索引顺序对引擎遍历索引效率有很大的提高(用电话薄的思想去思考问题)。
查看列的离散程度:
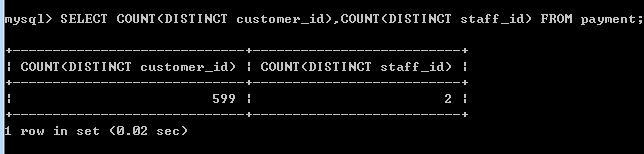
customer_id列的离散程度更高,建联合索引时应该INDEX(customer_id,staff_id);
原创地址:https://blog.csdn.net/qq_33290787/article/details/51950256
现在数据表myIndex中i_testID是主键列,其他列无任何索引:
多条件查找名字为xiaoming,城市为beijing,年龄为21的人:
返回了一行数据,从执行计划中看到,查询没有使用任何索引,进行了全表扫描,磁盘IO大。
为vc_Name建立索引:
进行同样的查询并查看执行计划:
返回了相同的结果,分析执行计划:SQL通过刚刚建立的index_of_name索引,不再进行全表扫描,而是先在索引中查找满足节点值为xiaoming的节点(有5个),再指向数据库中相应的行,返回一个初步结果集后再由另外两个条件进行一步步筛选得到最终结果。大大减少了磁盘IO,查询效率也高于前者。
虽然在 vc_Name 上建立了索引,查询时MYSQL不用扫描整张表,效率有所提高,但离我们的要求还有一定的距离。同样的,在 vc_City 和 i_Age 分别建立的MySQL单列索引的效率相似。为了进一步榨取 MySQL 的效率,就要考虑建立组合索引。
为多条件涉及的列建立联合索引:
值得注意的是,建立索引的时候应该根据需要规定索引长度,例如一个人的名字长度应该不会超过10个字符,通过vc_Name(10)规定索引长度后一定长度可以减少索引所占内存。
现在表中的结构:
进行相同的查询并查看执行计划:
返回相同的结果,从执行计划可以看到:本次查询使用了联合索引name_city_age,在遍历索引时就确定了只有一个节点满足条件,直接指向数据库表进行查询(rows:1)。有更少的磁盘IO,所用时间更少!
使用联合索引应该注意:
MySQL使用联合索引只能使用左侧的部分,例如INDEX(a,b,c),当条件为a或a,b或a,b,c时都可以使用索引,但是当条件为b,c时将不会使用索引。这好比一本先根据姓,再根据名进行排序的电话簿,当查找的时候有姓的条件,效率会比没有任何条件高;如果在姓的基础上还有名的条件,效率会更高;但若只有名的条件,电话簿将不起作用。
离散度更高的索引应该放在联合索引的前面,因为离散度高索引的可选择性高。考虑一种极端的情况,数据表中有100条记录,若INDEX(a,b)中a只有两种情况,而b有100种情况。这样对于查询唯一记录a = …,b = …时,先遍历全部索引看满足a条件的有50个索引节点,接下来还要再一个个遍历这50个索引节点。如果是INDEX(b,a),先遍历全部索引发现满足b条件的索引节点只有一个,再遍历这个节点发现也满足a条件。虽然最后都能找到那个唯一的索引节点,但是第二种索引顺序对引擎遍历索引效率有很大的提高(用电话薄的思想去思考问题)。
查看列的离散程度:
customer_id列的离散程度更高,建联合索引时应该INDEX(customer_id,staff_id);
原创地址:https://blog.csdn.net/qq_33290787/article/details/51950256

相关文章推荐
- 联合索引优化多条件查询
- 联合索引优化多条件查询
- SQL查询优化联合索引 与 单一列的索引
- 浅析MySQL中的Index Condition Pushdown (ICP 索引条件下推)和Multi-Range Read(MRR 索引多范围查找)查询优化
- 四、优化数据库,将不同功能的表分别建立在不同的库中,尽量避免表的联合查询,重视索引
- 浅析MySQL中的Index Condition Pushdown (ICP 索引条件下推)和Multi-Range Read(MRR 索引多范围查找)查询优化
- sql大数据多条件查询索引优化
- 联合两个索引查询,已解决: 还有个进行多条件搜索 and 与 or 的操作
- MySQL数据库优化总结如果索引多个字段,第一个字段要是经常作为查询条件的。如果只有第二个字段作为查询条件,这个索引不会起到作用;
- mysql5.7在多列索引 in条件查询的优化
- mysql性能优化-慢查询分析、优化索引和配置
- 使用索引统计信息(Index Statistics)优化查询语句,提高查询效率
- 浅析TPCH对查询Q4的优化-正确改写子查询与强制使用索引优化
- SQL Server 查询优化之二_索引的遍历与维护
- mysql性能优化-慢查询分析、优化索引和配置
- Hive 文件格式 & Hive操作(外部表、内部表、区、桶、视图、索引、join用法、内置操作符与函数、复合类型、用户自定义函数UDF、查询优化和权限控制)
- mysql使用索引优化查询效率
- sqlserver索引与查询优化
- 提高mysql千万级大数据SQL查询优化30条经验(Mysql索引优化注意)
- SQL Server 查询性能优化——覆盖索引(一)