KMP算法及next数组详解
2018-03-27 19:21
337 查看
最近整理笔记时,突然翻出几年前理解起来困难无比的看毛片(KMP)算法,笔记中详述了搜索过程,图文并茂,然而在最最重要的next数组部分却是一带而过,于是找出当年的教材,也只是写了getnext()函数,想着上网找一找图文并茂的举例,结果这一找彻底蒙比,众说纷纭,同样一个子串,处理得到的“next数组”全不一样,抛开数组以0开始还是以1开始这一问题,还有三种不同的结果。
事实上这三种“next数组”的结果都没有错,只是他们涉及到了KMP匹配过程的两种理解。在后文中将说明这三者之间的区别、转换以及所属的KMP匹配过程的演示。
第一部分 KMP算法与next数组的基本认识
设主串为T,带搜索的子串为S,i表示T遍历到了哪个字符,j表示S遍历到了哪个字符:
暴力查找方法通常会在T[i]!=S[j]时,j和j都回退,而KMP的核心就是主串不回退,即i只增不减,j相应的改变。而j依何改变?这就需要提前处理T子串,生成相应的next数组(这里所说的next数组其实并不完善,后文中将会提到改良版的nextval数组)。
那么next数组代表的是什么意思呢?通俗点说就是,这次没配上,下次找谁配。next数组里存的就是下次交配对象…不对,是匹配对象…
正是因为KMP只预处理子串,因此很适合这样一种问题的求解:给定一个S子串,和一群不同的T主串,问S是哪些T的子串。
第二部分 KMP算法的两种匹配过程
同我一样迷惑于许多博客中讲述的“互相矛盾的”匹配过程的童鞋请重点看这一部分,接下来我将说明,为何明明很好理解的主串不回退匹配过程会有那么多不同的声音,因为它们根..本..不..是..一..个..过..程..!!!
这也是为什么关于next数组会有那么多版本的不同解释,先约束下,本文中用到的数组以1开始(以0开始也一样整体减1就好了,网上next数组第一位为-1的就是数组以0开始的)。
下表中Lmax代表失配字符上一位字符所对应部分子串的最大前后缀共有元素长度,也就是部分匹配值,next代表存在一些瑕疵的next数组,nextval代表改良版的next数组。
第二行S=”abaabcac”就是带查找的子串,第三四五行是对S处理后得到Lmax、next、nextval数组(这三个数组是怎么得到的将在第三部分说明,这里为了演示两种不同的KMP匹配方法先直接给出)。
1.部分匹配值法
推荐博客:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html 详细且图文并茂(只可惜没有next数组什么事),能够帮助大家快速理解KMP到底要干什么。
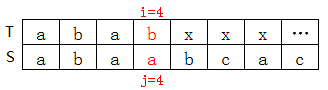
T[4]=b,S[4]=a,这里就不匹配了,而前三个“aba”是匹配的,最后一个匹配字符S[3]=a对应的Lmax[3]=1,因此按照下面的公式算出向后移动的位数:
移动位数=已匹配字符数-部分匹配值(即Lmax[i])=3-1=2
因此S向后移动2位:

注意,这里只是单纯的S子串向后移动两位,不涉及j变化成什么(可以推出j变为什么,但是不是Lmax直接赋值给j)
2.next数组法
推荐博客:http://blog.csdn.net/guo_love_peng/article/details/6618170 写的真心好,这个才是KMP算法中正宗的next数组。
同样是上图中的例子,接下来用到的是next/nextval数组法:
(1)next/nextval通用例子:
T[4]=b,S[4]=a,不匹配,查上表知nextval[4]=2(巧了next[4]也等于2,事实上大多数情况下二者都相等),因此j=nextval[4]=2,如下图:
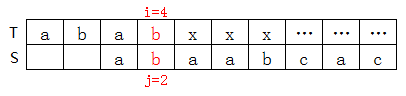
(2)证明next有瑕疵,nextval完美的例子
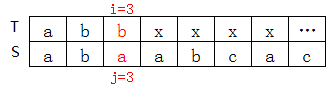
T[3]=b,S[3]=a,不匹配,查上表知nextval[3]=0(next[3]也等于1,不相等)
先看next[3]=1的情况:
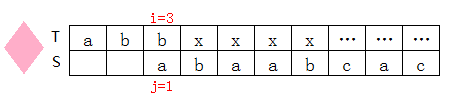
T[3]=b,S[1]=a,不匹配,查上表知next[1]=0,则j=next[1]=0:
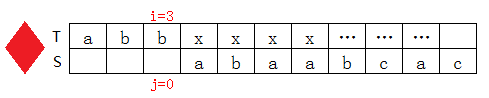
i++,j++,继续匹配:
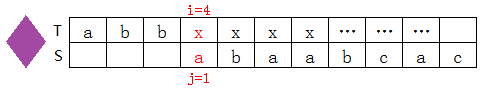
接下来是nextval[3]=0的情况:

next[3]=1需要经过步骤

,而nextval[3]=0只要一步

就搞定,为什么呢?
其实,既然T[3]=b不等于S[3]=a,而S[3]=S[1]=a,那么T[3]=b就一定不等于S[1]=a,既然如此,那么步骤

就多此一举了,这也就是next的瑕疵之所在,而nextval是在next基础上的一个改良版,避免了不必要的匹配过程。
第三部分 Lmax、next、nextval数组的获取方法及转换
1.最大共有元素长度(部分匹配值)Lmax
[java] view plain copy print?//伪代码如下
Lmax[1]=0;
j=0;
for i=2 to n do{
while j>0 and S[j+1]!=S[i]
do j=Lmax<span style=“font-size: 12px; font-family: Arial, Helvetica, sans-serif;”>[j];</span>
if S[j+1]=S[j]
then j++;
Lmax[i]=j;
}
2.next数组(改良前的)
获取方法:
(1)next[1]=0,next[2]=1 (固定)
(2)之后的每一位next值根据上一位进行比较,前一位值与其next值对应的内容相比较:
a.如果相等,则该位的next值就是前一位的next值加上1
b.如果不相等,向前继续找next值对应的内容与前一位进行比较,知道找到某一位内容的next值对应的内容与前一位相等,则此next值加上1即为该位的next值
c.如果找到第一位都没有与前一位相等的内容,那么该位next值为1
3.nextval数组(改良后的next)
[java] view plain copy<
b23e
/a> print?//伪代码如下 i=1; j=0; nextval[1]=0; while i<S[0]{ whlie j>0 and S[i]!=S[j] do j=nextval[j]; i++; j++; if S[i]=S[j] then nextval[i]=nextval[j]; else then nextval[i]=j; }
4.最大共有元素长度Lmax,next,nextval数组之间的转换
(1)Lmax->next:
右移一位,最左补-1,最右删去,整体加1
Lmax=”00112010” -> ”-10011201” -> “01122312”=next
(2)next->nextval:
<1>nextval[1]=0 (固定)
<2>从第二位开始(i=2),若要求nextval[i],将next[i]的值对应位的值与i的值进行比较:
a.若相等,则nextval[i]=nextval[next[i]]
b.若不相等,则nextval[i]=next[i]
根据此表中next数组的值,可推出nextval数组的值,可自行推导,这里不再赘述
事实上这三种“next数组”的结果都没有错,只是他们涉及到了KMP匹配过程的两种理解。在后文中将说明这三者之间的区别、转换以及所属的KMP匹配过程的演示。
第一部分 KMP算法与next数组的基本认识
设主串为T,带搜索的子串为S,i表示T遍历到了哪个字符,j表示S遍历到了哪个字符:
暴力查找方法通常会在T[i]!=S[j]时,j和j都回退,而KMP的核心就是主串不回退,即i只增不减,j相应的改变。而j依何改变?这就需要提前处理T子串,生成相应的next数组(这里所说的next数组其实并不完善,后文中将会提到改良版的nextval数组)。
那么next数组代表的是什么意思呢?通俗点说就是,这次没配上,下次找谁配。next数组里存的就是下次交配对象…不对,是匹配对象…
正是因为KMP只预处理子串,因此很适合这样一种问题的求解:给定一个S子串,和一群不同的T主串,问S是哪些T的子串。
第二部分 KMP算法的两种匹配过程
同我一样迷惑于许多博客中讲述的“互相矛盾的”匹配过程的童鞋请重点看这一部分,接下来我将说明,为何明明很好理解的主串不回退匹配过程会有那么多不同的声音,因为它们根..本..不..是..一..个..过..程..!!!
这也是为什么关于next数组会有那么多版本的不同解释,先约束下,本文中用到的数组以1开始(以0开始也一样整体减1就好了,网上next数组第一位为-1的就是数组以0开始的)。
下表中Lmax代表失配字符上一位字符所对应部分子串的最大前后缀共有元素长度,也就是部分匹配值,next代表存在一些瑕疵的next数组,nextval代表改良版的next数组。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| S | a | b | a | a | b | c | a | c |
| Lmax | 0 | 0 | 1 | 1 | 2 | 0 | 1 | 0 |
| next | 0 | 1 | 1 | 2 | 2 | 3 | 1 | 2 |
| nextval | 0 | 1 | 0 | 2 | 1 | 3 | 0 | 2 |
1.部分匹配值法
推荐博客:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html 详细且图文并茂(只可惜没有next数组什么事),能够帮助大家快速理解KMP到底要干什么。
T[4]=b,S[4]=a,这里就不匹配了,而前三个“aba”是匹配的,最后一个匹配字符S[3]=a对应的Lmax[3]=1,因此按照下面的公式算出向后移动的位数:
移动位数=已匹配字符数-部分匹配值(即Lmax[i])=3-1=2
因此S向后移动2位:
注意,这里只是单纯的S子串向后移动两位,不涉及j变化成什么(可以推出j变为什么,但是不是Lmax直接赋值给j)
2.next数组法
推荐博客:http://blog.csdn.net/guo_love_peng/article/details/6618170 写的真心好,这个才是KMP算法中正宗的next数组。
同样是上图中的例子,接下来用到的是next/nextval数组法:
(1)next/nextval通用例子:
T[4]=b,S[4]=a,不匹配,查上表知nextval[4]=2(巧了next[4]也等于2,事实上大多数情况下二者都相等),因此j=nextval[4]=2,如下图:
(2)证明next有瑕疵,nextval完美的例子
T[3]=b,S[3]=a,不匹配,查上表知nextval[3]=0(next[3]也等于1,不相等)
先看next[3]=1的情况:
T[3]=b,S[1]=a,不匹配,查上表知next[1]=0,则j=next[1]=0:
i++,j++,继续匹配:
接下来是nextval[3]=0的情况:
next[3]=1需要经过步骤
,而nextval[3]=0只要一步
就搞定,为什么呢?
其实,既然T[3]=b不等于S[3]=a,而S[3]=S[1]=a,那么T[3]=b就一定不等于S[1]=a,既然如此,那么步骤
就多此一举了,这也就是next的瑕疵之所在,而nextval是在next基础上的一个改良版,避免了不必要的匹配过程。
第三部分 Lmax、next、nextval数组的获取方法及转换
1.最大共有元素长度(部分匹配值)Lmax
[java] view plain copy print?//伪代码如下
Lmax[1]=0;
j=0;
for i=2 to n do{
while j>0 and S[j+1]!=S[i]
do j=Lmax<span style=“font-size: 12px; font-family: Arial, Helvetica, sans-serif;”>[j];</span>
if S[j+1]=S[j]
then j++;
Lmax[i]=j;
}
//伪代码如下
Lmax[1]=0;
j=0;
for i=2 to n do{
while j>0 and S[j+1]!=S[i]
do j=Lmax<span style="font-size: 12px; font-family: Arial, Helvetica, sans-serif;">[j];</span>
if S[j+1]=S[j]
then j++;
Lmax[i]=j;
}2.next数组(改良前的)
获取方法:
(1)next[1]=0,next[2]=1 (固定)
(2)之后的每一位next值根据上一位进行比较,前一位值与其next值对应的内容相比较:
a.如果相等,则该位的next值就是前一位的next值加上1
b.如果不相等,向前继续找next值对应的内容与前一位进行比较,知道找到某一位内容的next值对应的内容与前一位相等,则此next值加上1即为该位的next值
c.如果找到第一位都没有与前一位相等的内容,那么该位next值为1
3.nextval数组(改良后的next)
[java] view plain copy<
b23e
/a> print?//伪代码如下 i=1; j=0; nextval[1]=0; while i<S[0]{ whlie j>0 and S[i]!=S[j] do j=nextval[j]; i++; j++; if S[i]=S[j] then nextval[i]=nextval[j]; else then nextval[i]=j; }
//伪代码如下
i=1;
j=0;
nextval[1]=0;
while i<S[0]{
whlie j>0 and S[i]!=S[j]
do j=nextval[j];
i++;
j++;
if S[i]=S[j]
then nextval[i]=nextval[j];
else
then nextval[i]=j;
}4.最大共有元素长度Lmax,next,nextval数组之间的转换
(1)Lmax->next:
右移一位,最左补-1,最右删去,整体加1
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| S | a | b | a | a | b | c | a | c |
| Lmax | 0 | 0 | 1 | 1 | 2 | 0 | 1 | 0 |
| next | 0 | 1 | 1 | 2 | 2 | 3 | 1 | 2 |
| nextval | 0 | 1 | 0 | 2 | 1 | 3 | 0 | 2 |
(2)next->nextval:
<1>nextval[1]=0 (固定)
<2>从第二位开始(i=2),若要求nextval[i],将next[i]的值对应位的值与i的值进行比较:
a.若相等,则nextval[i]=nextval[next[i]]
b.若不相等,则nextval[i]=next[i]
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| S | a | b | a | a | b | c | a | c |
| Lmax | 0 | 0 | 1 | 1 | 2 | 0 | 1 | 0 |
| next | 0 | 1 | 1 | 2 | 2 | 3 | 1 | 2 |
| nextval | 0 | 1 | 0 | 2 | 1 | 3 | 0 | 2 |

相关文章推荐
- KMP算法的Next数组详解
- KMP算法next数组详解
- KMP算法的Next数组详解
- KMP算法的Next数组详解
- KMP算法的Next数组详解
- 转载 KMP算法中next数组详解
- KMP算法的Next数组详解
- 转载 KMP算法中next数组详解
- KMP算法详解, 关于NEXT数组及其改进
- 【详解KMP算法 next数组详解】
- KMP算法详细讲解,next数组构造详解
- KMP算法及next数组详解
- 详解KMP算法中Next数组的求法
- KMP算法-之next数组-详解
- KMP算法的Next数组详解
- KMP算法的Next数组详解(转)
- 详解KMP算法中Next数组的求法
- KMP算法 一般详解,NEXT数组 一般理解 k = next[k] ——综合转载
- KMP算法 Next数组详解
- KMP算法之next数组详解 (转载)