Spark运行流程
2018-03-27 13:02
225 查看
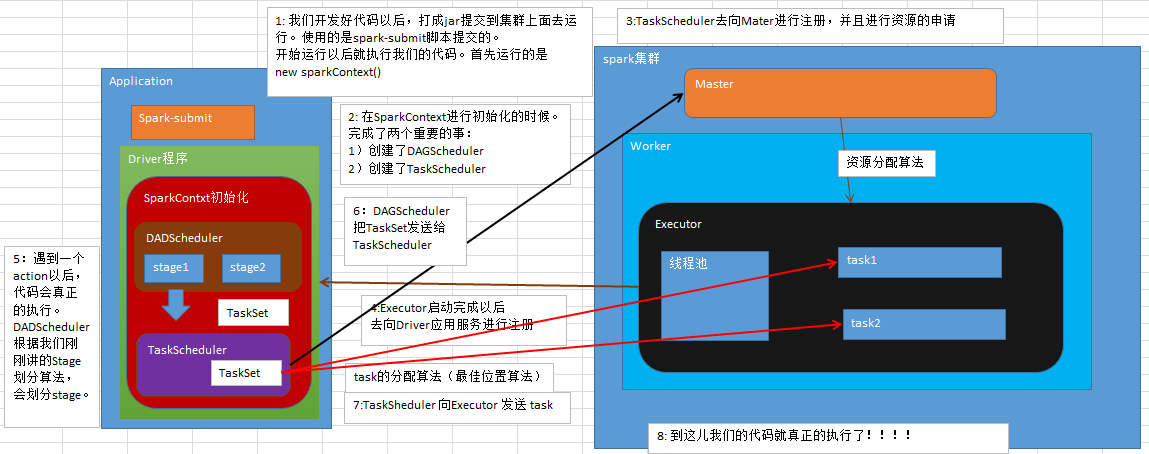
运行流程:
1.开发好代码以后打成jar包提交到集群上面去运行。使用的是Spark-submit脚本提交的。首先运行的就是new SparkContext()2.在SparkContext进行初始化的时候,完成了两个重要的事情:创建了DAGScheduler、TestScheduler
3.TaskScheduler去向master进行注册,并进行资源申请。
4.Executor启动完成以后,去向Driver应用服务进行注册
5.遇到一个action以后,代码才会真正的执行。DAGScheduler会根绝Stage划分算法,划分stage
6.DAGScheduler把TaskSet发送给TaskScheduler
7.TaskScheduler向Executor发送task
8.代码真正执行

相关文章推荐
- DT大数据梦工厂第三十五课 Spark系统运行循环流程
- 大数据IMF传奇行动绝密课程第35课:打通Spark系统运行内幕机制流程循环图
- SparkStreaming的运行流程解析(源码)
- SparkSteaming运行流程分析以及CheckPoint操作
- Spark on Yarn解密及运行流程
- spark核心术语和运行流程
- 重磅!Spark运行内幕 打通Spark系统运行内幕机制流程
- spark on yarn(Job的运行流程,可以对比mapreduce的yarn运行)
- spark运行流程
- 本地Spark程序提交到hadoop集群运行流程
- Spark Client和Cluster两种运行模式的工作流程
- SparkStreaming的运行流程解析(源码)
- Spark运行流程源码走读
- Spark运行流程
- Spark Client和Cluster两种运行模式的工作流程
- Spark 的运行流程原理
- spark应用运行大体流程
- Spark基本运行流程
- Spark系统运行内幕机制循环流程
- spark运行流程