TensorFlow+深度学习笔记Week1
2018-03-26 21:12
381 查看
TensorFlow+深度学习笔记1
由于博主参加了学校的科研实训,然后指导老师给的项目与深度学习有关,于是我将详细记录博主的学习经历。ps:博主也是初学者,如果哪里有错误请多多指教~
博主这阶段掌握的知识:
1 TensorFlow运行机制、Tensorflow一些函数的调用、深度学习初步;
2 CNN模型的构建与它的优点,成功使用python编写了一个识别MNIST字体库准确率达99.07%的代码;
3 RNN模型的基本特点、如何使用TensorFlow接口搭建自己的RNN模型;
4 机器学习的一些重要知识:损失函数、最优化问题等等;
5 成功运行了Github上面的基于VGG19网络的图像风格化转换的代码。
Task1: 了解Tensorflow
首先来看一下第一周的任务:1. 学习清单
1) Tensorflow 安装;
2) 了解 Tensorflow 基本概念、运行机制;
3) 了解深度学习基本概念
2. 参考资料
1) Tensorflow 安装尽量按照官程:英文官网教程好像需要翻墙才能上。如果上不了,找一下中官网。
2) Tensorflo基本概念与内容,可参考:
《Tensorflow 实战 Google 深度学习》(框重点推荐):百度云连接
神经网络与深度学习 教材:百度云连接
香港科技大学 TensorFlow 三天速成课件:知乎链接
3) 如果开始跑代码,一定要看下面两个链接!!!并按照链接添加代码,保证按需调用 GPU显存。原因是在默认情况下,TensorFlow 会占满所有显存,不管程序本身所需容量多少。实验室 GPU 资源有限,占用完两张卡所有的显存,这样其他同学就用不了 GPU 了:
github链接
stackoverflow链接
3. 周报内容
把实验室服务器虚拟机的配置、Tensorflow 安装过程到的问题、学习到的概念内容等,尽可能全部记录
由于博主在上学期某些课程的大项目中已经接触到深度学习的一些皮毛,并且已经在ubuntu下面配置好了Tensorflow-gpu版本,有关tensorflow的安装配置将会带过,读者可以参考《Tensorflow 实战 Google 深度学习》第二章给的步骤安装配置tensorflow,相对于cpu版本来说gpu的安装配置略显麻烦,但是我还是强烈建议安装gpu版本,因为在某些项目中使用gpu版本的几分钟就可以得到结果,而使用cpu版本要几个小时,更不用说训练模型了。
代码运行结果:
使用python编写了一个识别MNIST字体库准确率达99.07%的代码:(代码贴在CNN学习部分)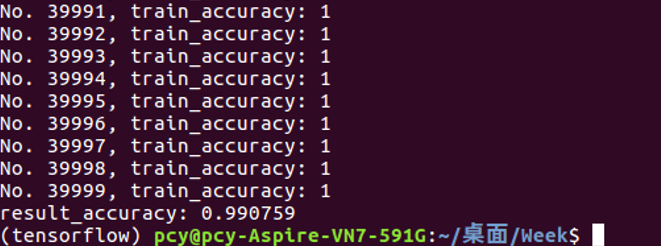
成功运行了Github上面的基于VGG19网络的图像风格化转换的代码:
Github链接为:neural-style
下面是我运行的结果:
首先放上风格图片(梵高的作品):

下面是我要转换的图片(东校区公教楼):

最终代码将东校区公教楼图片转换为梵高的风格:

Tips:强烈建议安装tensorflow-gpu版本,就单单这张图片如果使用gpu版本的tensorflow几分钟分钟就能运行结束,使用cpu版本的tensorflow的话需要近3个小时!
下面再多举一个例子:
小礼堂图片:

梵高风格的小礼堂:

下面简要介绍一下作者代码的算法:
首先要说的是作者的代码有3个py文件,运行的顺序是vgg.py->stylize.py->neural_style.py。
作者使用的是CNN,具体的网络结构是VGG19(CNN的一种)。VGG19结构图如下:
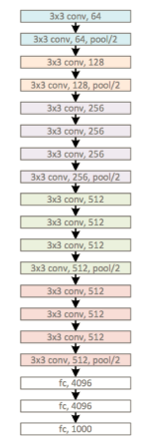
在vgg.py文件中我们也可以清楚看到这样的代码:
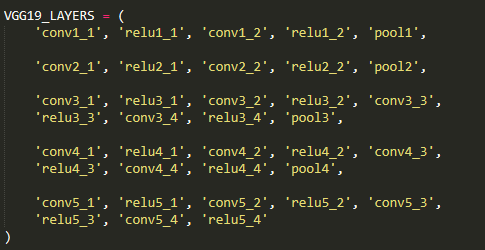
可以看到作者的网络结构正是VGG19,和上面的VGG19结构图是一摸一样的。
模型我是从作者给的链接下载的,该模型数据包含很多信息,我们需要的信息是每层神经网络的kernels和bias。kernels和bias的获取方式如下面代码所示:

vgg.py文件设计算法使用的网络模型、neural_style.py设计图像的读取和存储(图像操作)、stylize.py文件涉及风格化算法的具体流程。所以如果想要深入了解作者算法,就需要理解stylize.py文件的每一行代码。而stylize.py文件的核心又是stylize()函数,这个函数实现了风格话的具体算法。

下面是我学习的步骤:
1 课件《TF-UST-DAY1.5.pptx》,这个课件是介绍Deep Neural Network的。同一天的另一个课件是介绍Tensorflow的,不过那个课件有一些python代码,我建议还是把背后的数学背景弄清楚再去看介绍Tensorflow的课件。其中提到了Softmax Function 和 cross entropy(交叉熵)的概念,两个链接帮助你更好理解交叉熵、Softmax Function。对于Softmax Function,PPT上面的图貌似不太好理解,这里有一张更容易理解的图片:
图来自《一天搞懂深度学习》
关于交叉熵,仔细阅读连接就能大致理解。在机器学习中的分类算法中,我们总是最小化交叉熵,因为交叉熵越低,就证明由算法所产生的策略最接近最优策略,也间接证明我们算法所算出的非真实分布越接近真实分布。
总结一下这张PPT的重点:
首先是关于机器学习的几个知识点复习:
Linear Regression

Logistic Reression

Softmax Classification

Cost function: cross entropy

上图来自交叉熵(Cross-Entropy)
复习完之后接下来进入正题:
XOR with Logistic Regression
PPT从单个Logistic Regression来预测XOR产生的数据开始,说明这样预测得到的结果是不准确的,然后提出使用多个Logistic Regression单元组合起来的形式证明了这样会得到正确的结果,从而引出了神经网络的概念。提出了三种神经网络的模型:
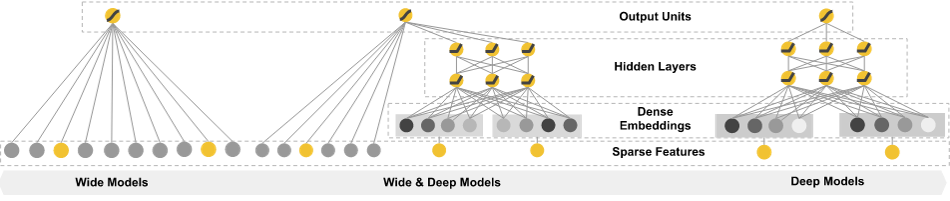
此外作者使用Deep NN得到了更好的XOR结果
如何最小化损失函数? 使用梯度下降算法
Solution: Deep Neural Net
关于反向传播算法,我在一篇博客学习到了很多一文弄懂神经网络中的反向传播法——BackPropagation
反向传播算法其实是神经网络的基础,本质上不是很难,就是一个链式求导法则反复运用的过程,改变神经网络里面的权重使得最终结果尽可能接近期望值。
Challenges of DNN
PPT最后比较了sigmoid激活函数和ReLU激活函数,从各项数据来看,ReLU的表现要优秀很多。
此外还需要考虑overfitting的问题,有三种方法来解决overfitting:
More training data
Reduce the number of features
Regularization : Dropout
2 课件《TF-UST-DAY1.pptx》
我觉得整个课件最核心的一张图是:
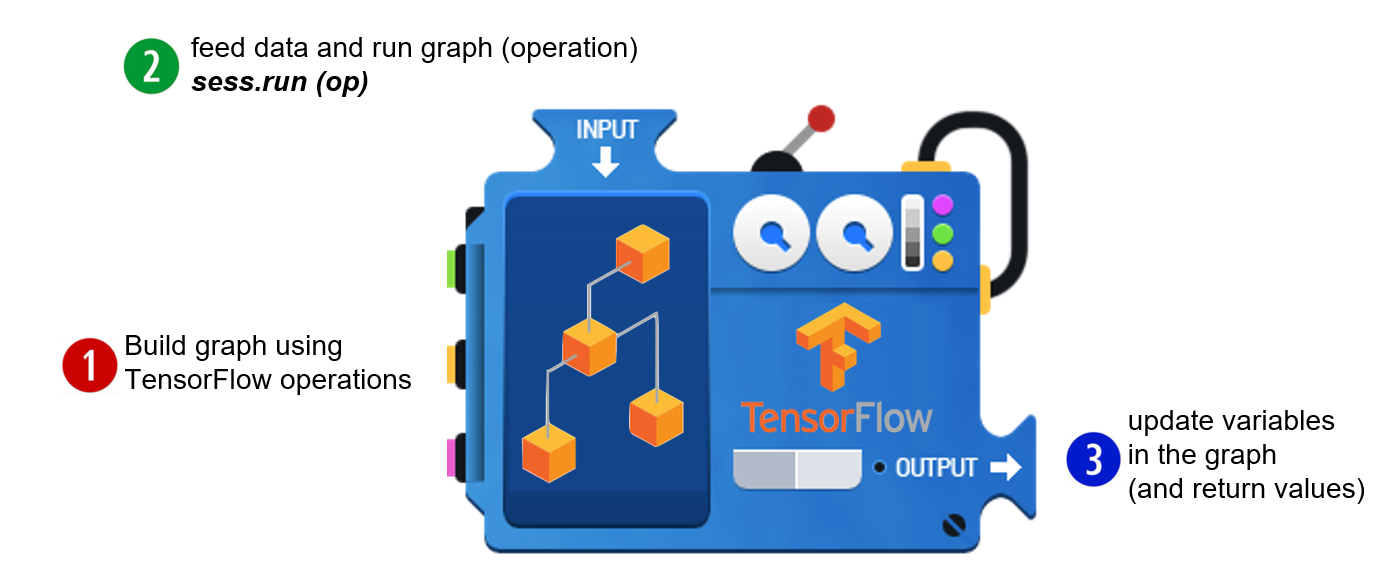
TensorFlow的大致流程有三个:
1. 使用Tensorflow的operations构图(Tensorflow是图驱动的)
2. 传入数据并运行图
3. 更新数据并返回结果
这样在理解Tensorflow的python代码的时候就比较清晰了:
接下来介绍了机器学习的一些回归知识,显然我们在上一个课件已经学到老很多,在这里就很轻松地理解(虽然应该是先看这张课件)。
我之前不是很理解下面这句代码:
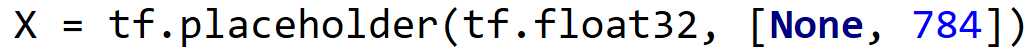
后再知道[None,784]中的None代表此张量的第一个维度可以是任何长度的。也就是说MNIST图片的每一个像素点的维度我们不需要考虑,只需要知道它的每一张图片是由784个像素点组成即可。
3 课件《TF-UST-DAY2.pptx》
这张课件主要讲解了CNN(卷积神经网络),在深入CNN之前我们首先来看看NN的一些tips:

这些tips同样试用于CNN,CNN是NN的一个种类,其中C代表Convolutional(卷积),是的,这就是数字图像处理里面的那个卷积。
下图可以帮助我们理解卷积:
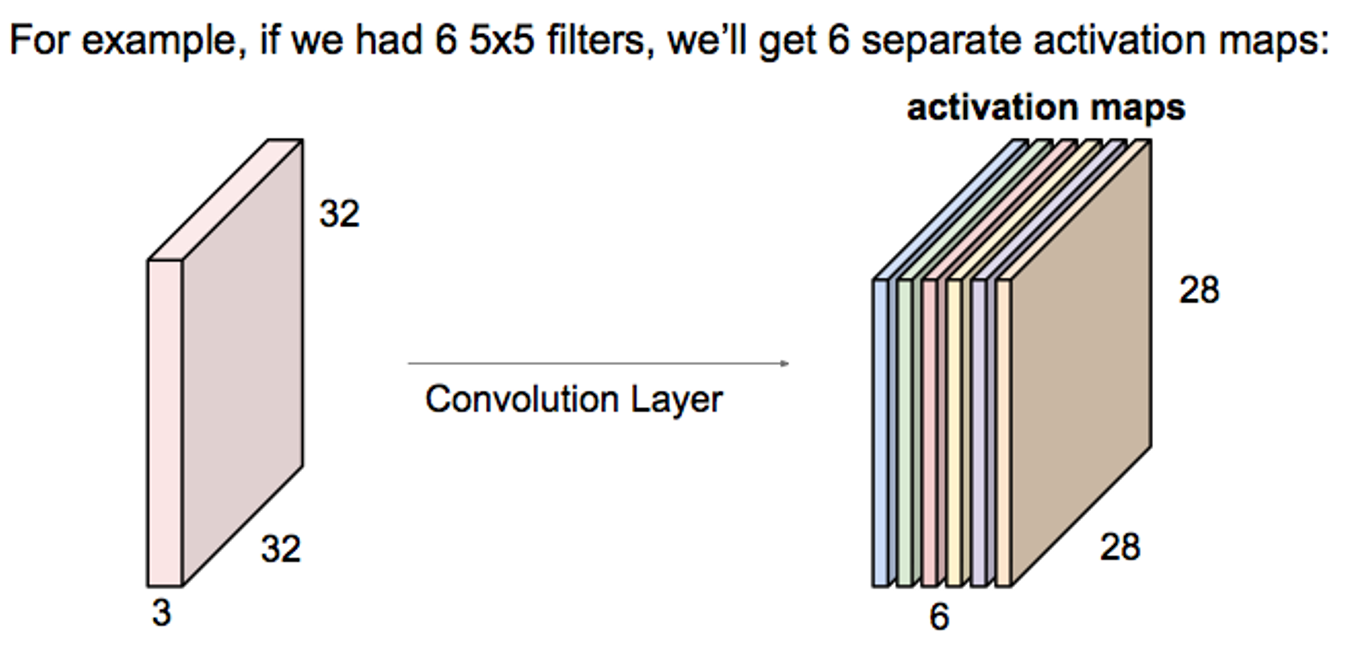
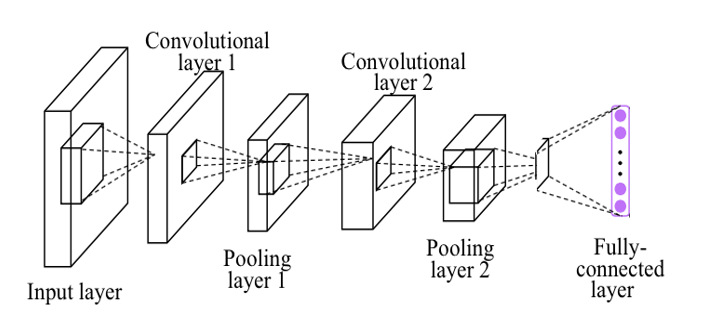
这里使用了6个5*5的filter对元数据(可以理解为32*32的图像,每个像素点占3个bit),每个小的filter对原图像进行卷积操作,由于原图像没有补上边界,并且步长为1,所以上下左右各有2个像素点被去除,于是卷积的结果是28*28的图像。由于使用了6个filter,所以卷积得到的图像有6个。

这是一个对图像分类的CNN模型,一共有3个卷积层(这是因为有3个POOL层),其中CONV代表卷积操作,前面已经论述,RELU代表非线性激活函数(和sigmoid函数一样,在前面的课件中也提到RELU的效果可能会更好)。POOL操作的话可以理解为下采样操作,这样的目的是为了使数据更小并且更便于管理。
在介绍完CNN之后,为了便于说明CNN的有用之处,PPT使用MNIST来说明。在没有使用CNN之前,得到的准确率只有90%出头(我的结果是92%),而使用了CNN之后准确率可以达到99%。下面贴上我参考官网实现的代码(需要翻墙):
#load MNIST
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
# session connnect with bank-end,Tensorflow depend on a C++ back-end to calculate
import tensorflow as tf
session = tf.InteractiveSession()
# define every layers of CNN
def weight_v(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_v(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_layer(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y_ = tf.placeholder(tf.float32, [None, 10])
# first conv layer
conv1_w = weight_v([5, 5, 1, 32])
conv1_b = bias_v([32])
x_image = tf.reshape(x, [-1, 28, 28, 1])
conv1_relu = tf.nn.relu(conv2d(x_image, conv1_w) + conv1_b)
max_pool_h = max_pool_layer(conv1_relu)
# second conv layer
conv2_w = weight_v([5, 5, 32, 64])
conv2_b = bias_v([64])
conv2_relu = tf.nn.relu(conv2d(max_pool_h, conv2_w) + conv2_b)
max_pool_h2 = max_pool_layer(conv2_relu)
# connected layer
full_connected_w = weight_v([7 * 7 * 64, 1024])
full_connected_b = bias_v([1024])
pool2_flat_h = tf.reshape(max_pool_h2, [-1, 7*7*64])
full_connected_h = tf.nn.relu(tf.matmul(pool2_flat_h, full_connected_w) + full_connected_b)
# dropout
keep_p = tf.placeholder("float")
full_connected_drop = tf.nn.dropout(full_connected_h, keep_p)
# output layer
full_connected2_w = weight_v([1024, 10])
full_connected2_b = bias_v([10])
y_conv=tf.nn.softmax(tf.matmul(full_connected_drop, full_connected2_w) + full_connected2_b)
# Training and evaluation model
#Cross entropy
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
# Gradient descent method
train_step = tf.train.AdamOptimizer(1e-3).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
# Accuracy calculation
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
session.run(tf.initialize_all_variables())
sumnumber = 0
for i in range(1000):
batch = mnist.train.next_batch(25)
if i%1 == 0:
train_accuracy = accuracy.eval(feed_dict={x:batch[0], y_: batch[1], keep_p: 1.0})
print "No. %d, train_accuracy: %g"%(i, train_accuracy)
sumnumber += train_accuracy
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_p: 0.5})
result_accuracy = sumnumber/1000
print "result_accuracy: %g"%result_accuracy最终的结果如下(准确率为99.07%):
我的代码和PPT里面介绍的Simple CNN的模型结构是一样的:
但是PPT得到的结果为98.85%(我的结果要好一些),当使用Deep CNN的时候得到的结果为99.38%。很明显复杂的模型会得到更好的结果。但是这也并不代表CNN越深越好,有可能发生overfitting?
在这张PPT在最后还介绍了AlexNet、ResNet等网络结构。
4 课件《TF-UST-DAY3.pptx》
这张PPT介绍了RNN,RNN与CNN或者其它NN最主要的区别是RNN可以处理时序数据
RNN的经典结构示意图如下:

RNN按时间展开后的结构:
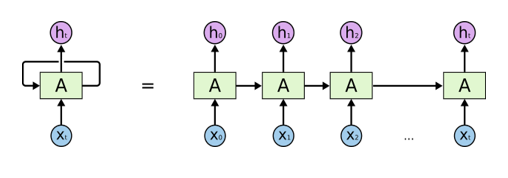
可以看做是同一神经网络结构在时间序列上被复制多次的结果。
RNN的应用:语音识别、机器翻译等等时序分析问题上。
下面这张图可以帮助你很好地理解RNN的工作流程:
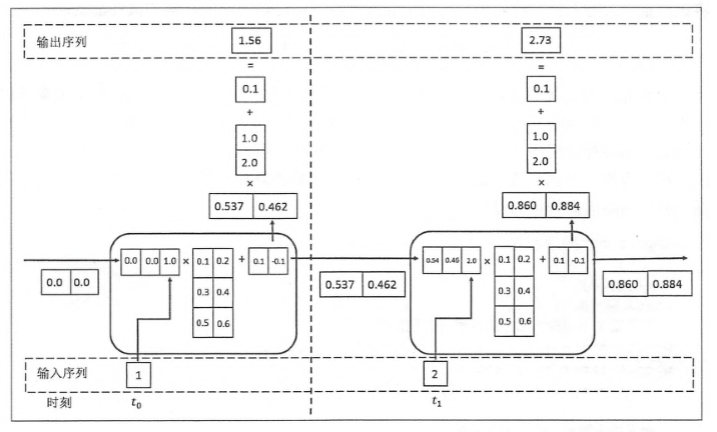
可以看到,每一个神经元的输入包含两个部分(1 “历史数据–当前时间点之前学习到的经验” 2 “实时数据”–当前时间点输入的数据),这也就不难理解为什么RNN可以应用在处理时序方面的问题而CNN等其它NN不具备这样的功能。
下面是PPT为我们总结的RNN的应用场景:

总之RNN是很强大的,但是训练它却并不容易。
在看完这三张PPT后,最大的收获是认识到Data driven learning和Rule based programming的不同,也意识到深度学习的重要性。
5 书本《Tensorflow 实战Google深度学习框架》
这本书建议仔细阅读第3、4、5、6、7、8章。
第一章对深度学习做了全方位的介绍,其中举例DeepMind团队的AlphaGo围棋人机大战以及接下来研究的星际争霸2人机大战都是基于TensorFlow实现的。TensorFlow已经被成功应用到语音搜索、广告、电商、图片等众多Google产品中,学术界和工业界也纷纷关注TensorFlow。
第二章介绍了如何安装TensorFlow环境以及在安装好的环境中运行简单的TensorFlow样例程序。由于博主已经成功安装过TensorFlow,并且运行过自己的代码,所以这一章就简单浏览了一下。
第三章将详细介绍TensoFlow的计算模型、数据模型、运行模型和神经网络的主要计算流程以及通过TensorFlow如何实现这些运算,建议详细阅读。
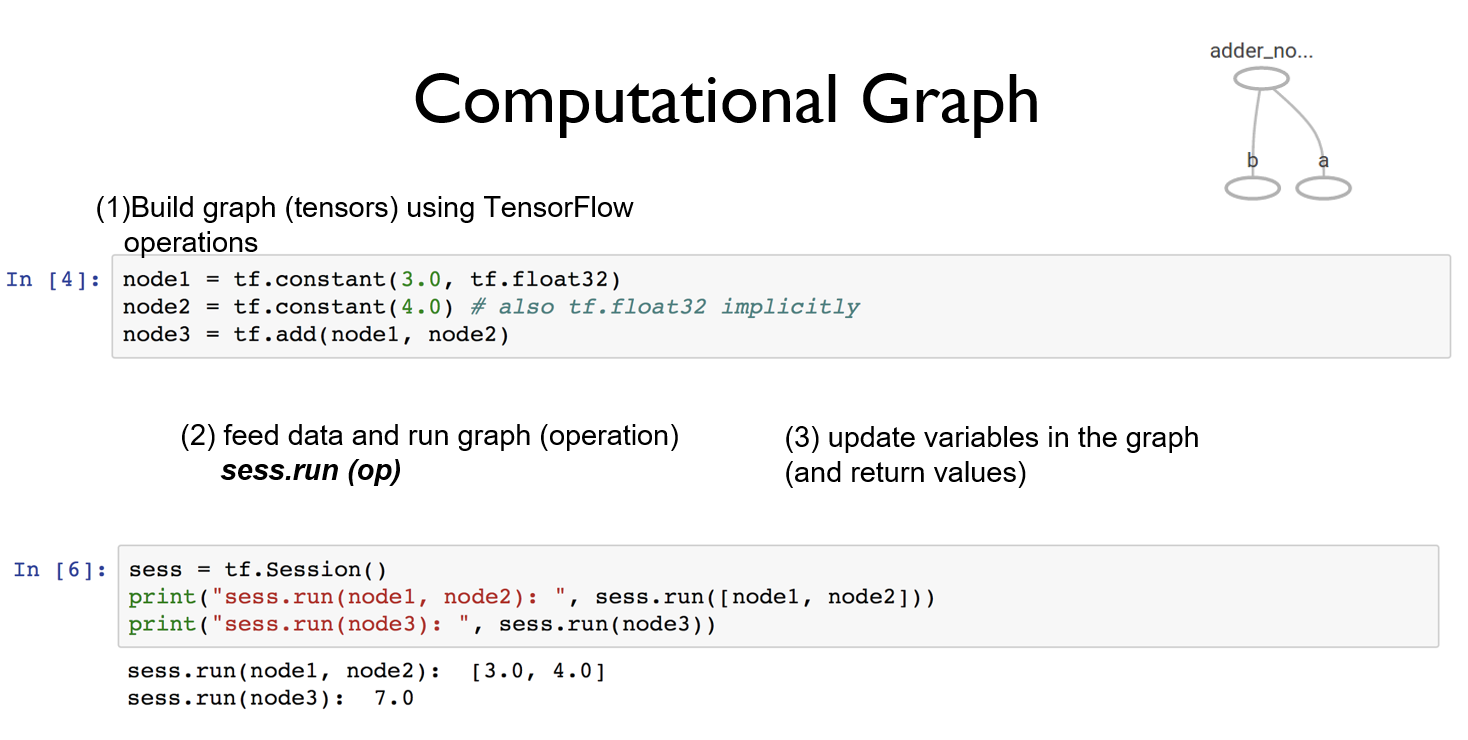
计算模型。计算图是TensorFlow中最基本的一个概念,TensorFlow中的所有计算都会被转化为计算图上的节点,下面截图将会给出很好的解释:
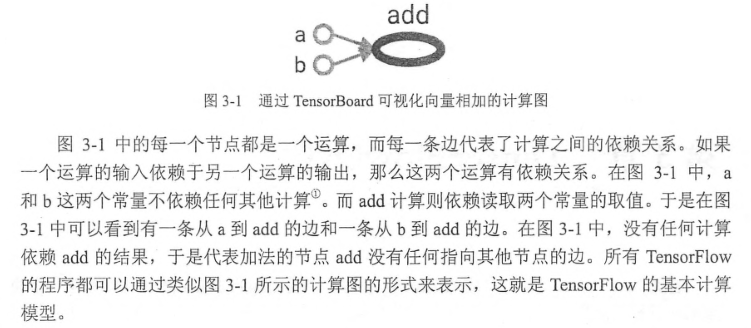
TensorFlow中的计算图不仅仅可以用来隔离张量和计算,它还提供了管理张量和计算的机制。
数据模型。张量是TensorFlow管理数据的形式,在TensorFlow中所有的数据都通过张量的形式来表示。我们可以将张量简单理解为多维数组,计算图中的每一个节点代表一个计算,计算的结果就保存在张量中,在张量中没有保存数字,它保存的是如何得到这些数字的计算过程。

P43页详细解释了上面代码的含义。
运行模型。TensorFlow使用session来执行定义好的运算。session拥有并管理TensorFlow程序运行时的所有资源。利用session.close()或者Python上下文管理机制关闭会话回收资源。
TensorFlow实现神经网络。向前传播算法:通过矩阵乘法表达,建议详细阅读P50到P53页。在TensorFlow中使用简单的两行矩阵乘法就能够实现一个简单的向前传播算法:

监督学习:在已知答案的标注数据集上,模型给出的预测结果要尽可能接近真实的答案,通过调整神经网络中的参数对训练数据进行拟合,可以使得模型对未知样本提供预测的能力。
反向传播算法:
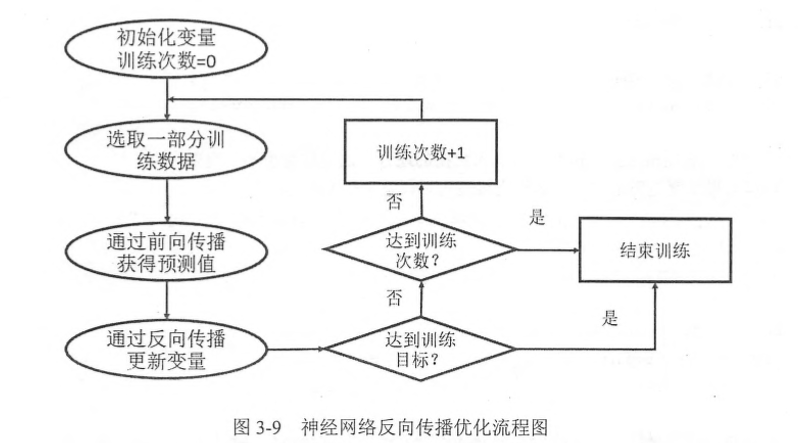
通过反向传播算法不断更新神经网络的权重参数,最终使得神经网络预测的结果和真实答案更加接近。用博主的话来说就是:我们首先知道x数据集和它对应的真实结果y数据集,我们将x数据集丢进神经网络里面最终得到y’数据集,此时我们定义一个损失函数(cost function),来计算y’数据集和真实y数据集之间的差距,然后通过优化器(TensorFlow提供7种优化器,博主最熟悉的要数梯度下降优化器)使得y’与y之间的差距尽可能小,这样不断更新神经网络的参数,最终使得差距最小,神经网络模型训练成功。
第四章将详细介绍了深层神经网络。指出了线性模型的局限性,使用激活函数(ReLU函数、sigmoid函数、tanh函数)来去线性化,此外还介绍了损失函数。在4.3介绍了神经网络优化算法:反向传播算法和梯度下降算法,梯度下降算法主要用于优化单个参数的取值,而反向传播算法给出了一个高效的方法在所有参数上使用梯度下降算法。在最后介绍了三个神经网络优化过程中遇到的问题和相应的解决方案:设置学习率:通过指数衰减的方式、过拟合问题:通过正则化、如何使模型在位置数据上更加健壮:使用滑动平均模型。
第五章介绍了MNIST数字识别问题。由于博主已经成功使用CNN让MNIST识别准确率达到99%以上,所以这一章节也只是简单阅读了一下,建议读者可以详细按照步骤最终实现自己的MNIST数字识别。
第六章通过介绍图像识别问题详细介绍了卷积神经网络,通过这种特殊的神经网络可以使得图像识别问题的准确率提高到一个新的层次。前面的PPT以及介绍过CNN,这一节将会有很多比较细节的东西。本章介绍的LeNet-5模型可以将MNIST数据集上的正确率进一步提升到99.4%,比博主的99.07%高了很多,建议研究这个模型。
第七章主要介绍TensorFlow使用多线程处理数据的框架,详细介绍了TensorFlow中主要图像处理函数(图像解码、图像大小调整、图像彩色调整等等)。
第八章详细介绍了RNN,前面的课件也介绍过RNN,如果想要更加深入地了解,可以仔细阅读。
第九章介绍了TensorBoard可视化,也就是说可以看见自己训练模型过程中各种参数的变化过程,通过这种可视化调节参数,使得我们更加容易得到最优模型。
第十章介绍了TensorFlow的计算加速,总之一句话:强烈建立安装TensorFlow的GPU版本,它会比CPU版本快很多倍。博主之前有计算过一张图片,刚开始使用CPU版本计算,大致花了三个小时才计算出一张图片,而当博主改用GPU版本之后只需要短短一两分钟!有关GPU版本的安装过程详见前面章节。
5 书本《神经网络与深度学习》
大致浏览了一下这本书的内容,发现和博主读的上一本书大同小异,由于时间关系博主只将它作为备用参考书,在以后遇到问题可以按照知识点去查阅。
关于实验室服务器的使用:
建议使用VNC软件来连接服务器。此外还可以设置屏幕的分辨率:

相关文章推荐
- Udacity深度学习(google)笔记(2)——深度神经网络, tensorflow
- DeepLearning.ai学习笔记(一)神经网络和深度学习--Week4深层神经网络
- tensorflow学习笔记--深度学习中的epochs,batch_size,iterations详解
- Udacity 深度学习_学习笔记(1)TensorFlow练习环境安装
- 深度学习笔记 (二) 在TensorFlow上训练一个多层卷积神经网络
- [翻译]斯坦福CS 20SI:基于Tensorflow的深度学习研究课程笔记,Lecture note 2: TensorFlow Ops
- TensorFlow 深度学习笔记
- 深度学习笔记——深度学习框架TensorFlow之DNN深度神经网络的实现(十四)
- 吴恩达深度学习笔记 course4 week2 深度卷积网络 实例探究
- TensorFlow深度学习笔记 Tensorboard入门
- 深度学习笔记——深度学习框架TensorFlow(十)[Creating Estimators in tf.contrib.learn]
- 深度学习笔记 (二) 在TensorFlow上训练一个多层卷积神经网络
- TensorFlow 深度学习笔记 从线性分类器到深度神经网络
- 【深度学习笔记】(二)Hello, Tensorflow!
- TensorFlow深度学习笔记 Logistic Classification
- TensorFlow 深度学习笔记 TensorFlow实现与优化深度神经网络
- 深度学习笔记——深度学习框架TensorFlow(十一)
- 深度学习笔记——深度学习框架TensorFlow之MLP(十四)
- 斯坦福CS20SI:基于Tensorflow的深度学习研究课程笔记,Lecture note2:TensorFlow Ops
- TensorFlow-实战Google深度学习框架 笔记(上)