从Mysql源代码角度分析一句简单sql的查询过程
2018-03-26 00:40
513 查看
1. 前言
使用mysql这么多年,以前一直只懂写sql,却不其中运行原理,直至最近抽时间看了一下mysql源代码, 对其事务运行原理及sql解析优化有一些更深入的理解. 本篇是讲述sql解析的开篇之作,希望透过最最简单的sql来让大家了解sql的查询解析过程, 如果本文力图把一个简单sql的执行过程所涉及的方法及其相关值的变化详细讲清楚,如果有问题欢迎留言.
2. 准备
2.1 参考
linux下使用eclipse debug mysql5.62.2 创建表
create table wlt_tab1( id int primary key );
2.3 执行查询
select * from wlt_tab1 where 1=0 and id=0
3. 执行查询
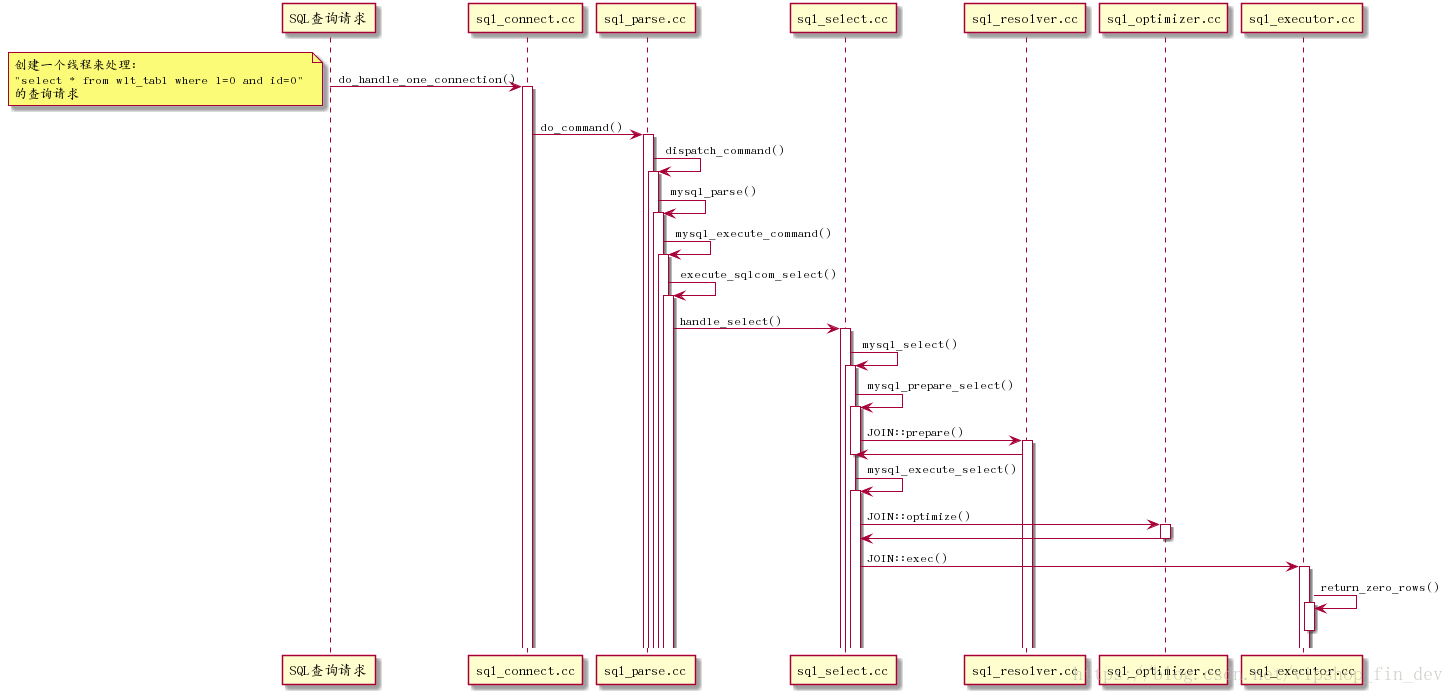
如果看不清楚,可在PC端点击查看到大图,
下面会针对上面时序图的每个方法详细解说!
3.1 do_handle_one_connection()
如果线程池中没有可用的缓存线程,则会通过本方法创建线程来处理用户请求.
3.2 do_command()
读取客户端传递的命令并分发
3.3 dispatch_command()
根据用户请求信息的第一个字段表示这个请求类型,以下摘取本方法代表性的简化 代码来说明本方法在查询过程中处理了哪些功能switch(command){
case COM_INIT_DB: ...;
case COM_CHANGE_USER: ...;
case COM_STMT_PREPARE: ...;
//如果是查询请求
case COM_QUERY:
//从网络数据包中读取Query并存入thd->query
alloc_query(thd,packet,packet_length);
//解析
mysql_parse(thd,thd->query(),thd->query_length(),&parser_state);
...
}3.4 mysql_parse()
/*
从lex_start方法源代码上看,本方法主要是将thd->lex对象内容重新清理
置为初始化状态.
注: thd是当前线程上下文信息类,后续与用户处理相关函数都会传入这个类,
估计是c++没有像java的ThreadLocal那么方便的类,所以老是要这么麻烦地传
来传去的
lex: 语法分析对象
本方法的实现在:sql_lex.cc
*/
lex_start(thd);
/*
查看query cache中是否有命中,如果有,则返回结果
如果没有,则作如下动作
*/
if(query_cache_send_result_to_client(thd,rawbuf,length)<=0){
//解析sql
bool err = parse_sql(thd,parser_state,NULL);
//执行
mysql_execute_command(thd);
}parse_sql() sql解析过程
mysql解析过程如下: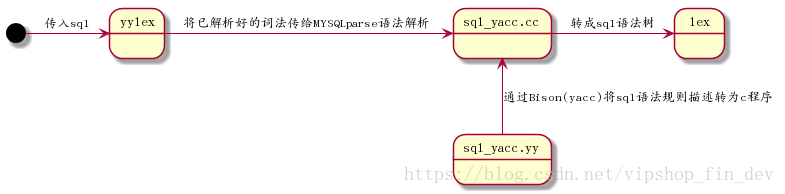
mysql是使用了开始的bison(即yacc的开源版)作为sql语法解析器
如上图所示,在lex词法解析阶段,会解析出select,from,where这几个token
接下来sql_yacc.cc的MYSQLparse会根据上面的token解析出语法树,yacc是使用巴科斯范式(BNF)表达语法规则,大家可以百度学习一下,下面节选几个与我们相关的表达式:
select_from:
FROM join_table_list where_clause group_clause having_clause
opt_order_clause opt_limit_clause procedure_analyse_clause
{
Select->context.table_list=
Select->context.first_name_resolution_table=
Select->table_list.first;
}
| FROM DUAL_SYM where_clause opt_limit_clause
/* oracle compatibility: oracle always requires FROM clause,
and DUAL is system table without fields.
Is "SELECT 1 FROM DUAL" any better than "SELECT 1" ?
Hmmm :) */
;
where_clause:
/* empty */ { Select->where= 0; }
| WHERE
{
Select->parsing_place= IN_WHERE;
}
expr
{
SELECT_LEX *select= Select;
select->where= $3;
select->parsing_place= NO_MATTER;
if ($3)
$3->top_level_item();
}
;parse_sql()方法执行完后,我们可以在gdb中查看语法树lex:
##查看select_lex->where (gdb) call print_where(lex->select_lex->where,"",QT_WITHOUT_INTRODUCERS) WHERE:() 0x7fff98005e10 ((1 = 0) and (`id` = 0)) (gdb) p lex->select_lex->table_list->first $9 = (TABLE_LIST *) 0x7fff98005260 ##查看sql使用的database (gdb) p $9->db $10 = 0x7fff980057c0 "wlt" (gdb) p $9->table_name $11 = 0x7fff98005218 "wlt_tab1"
3.5 mysql_execute_command()
//获取解析后的sql语法树
Lex *lex = thd->lex;
//根据解析后的sql语法树的类型,决定如何作下一步处理
switch(lex->sql_command){
case SQLCOM_SHOW_STATUS:...;
case SQLCOM_INSERT: ...;
case SQLCOM_SELECT:
...
res = execute_sqlcom_select(thd,all_tables);
}3.6 execute_sqlcom_select()
3.7 handle_select()
3.8 mysql_select()
sql真正执行入口,这里会分别执行:
JOIN::prepare() ; //预处理
JOIN::optimize();//查询优化
JOIN::exec();//执行
3.9 JOIN::prepare()
执行sql查询优化计划前的准备工作其中 setup_wild()方法会把查询语句中的”*”扩展为表上的所有列
3.9.1 setup_wild()
可以看本方法的主要代码:while (wild_num && (item= it++))
{
if (item->type() == Item::FIELD_ITEM &&
//如果field值为*
((Item_field*) item)->field_name[0] == '*' &&
!((Item_field*) item)->field)
{
if (subsel &&
subsel->substype() == Item_subselect::EXISTS_SUBS)
{
...
}else if (insert_fields(thd, ((Item_field*) item)->context,
((Item_field*) item)->db_name,
((Item_field*) item)->table_name, &it,
any_privileges))
{
...
}
}3.9.2 insert_fields()
//字段迭代器
Field_iterator_table_ref field_iterator;
field_iterator.set(tables);
for (; !field_iterator.end_of_fields(); field_iterator.next())
{
Item *item;
item= field_iterator.create_item(thd);
if (!found)
{
found= TRUE;
it->replace(item);
}
else
it->after(item); /* 将当前sql语句的表的字段一一加到fields_list中 */
}3.10 JOIN::optimize()
JOIN::optimize()函数主要功能是对sql各种优化,包括条件下推,关联索引列,计算最优查询优化执行计划…与本请求sql优化相关的是optimize_cond()方法
处理本sql时,optimize_cond()方法最终会将select_lex->cond_value置为Item::COND_FALSE,针对这个结果,后续处理如下:
if (select_lex->cond_value == Item::COND_FALSE ||
select_lex->having_value == Item::COND_FALSE ||
(!unit->select_limit_cnt && !(select_options & OPTION_FOUND_ROWS)))
{ /* Impossible cond */
zero_result_cause= select_lex->having_value == Item::COND_FALSE ?
"Impossible HAVING" : "Impossible WHERE";
tables= 0;
primary_tables= 0;
best_rowcount= 0;
goto setup_subq_exit;
}3.10.1 optimize_cond()
这个方法主要代码可以简化如下://等式合并 build_equal_items(thd,conds,NULL,true,join_list,cond_equal); //常量求值 propagate_cond_constants(thd, (I_List<COND_CMP> *) 0, conds, conds); //条件去除 remove_eq_conds(thd, conds, cond_value) ;
在刚进这个方法时,我们可以打印 conds对象的值
(gdb) p call print_where(conds,"",QT_WITHOUT_INTRODUCERS) WHERE:() 0x7fff98005e10 ((1 = 0) and (`wlt`.`wlt_tab1`.`id` = 0))
remove_eq_conds()方法会优化掉条件中 1=0
3.10.1.1 remove_eq_conds()
本方法会调用: internal_remove_eq_conds(thd, cond, cond_value); // Scan all the condition3.10.1.2 internal_remove_eq_conds()
while ((item=li++))
{
/×这里会取当前条件组的第一个条件递归调用本方法
在递归的方法中会判断到item->const_item()为true,
并对1=0进行求值:
*tmp_cond_value= eval_const_cond(cond) ? Item::COND_TRUE : Item::COND_FALSE;
×/
Item *new_item=internal_remove_eq_conds(thd, item, &tmp_cond_value);
switch (tmp_cond_value) {
case Item::COND_OK: // Not TRUE or FALSE
if (and_level || *cond_value == Item::COND_FALSE)
*cond_value=tmp_cond_value;
break;
//当前1=0的条件会进入 Item::COND_FALSE
case Item::COND_FALSE:
if (and_level)
{
*cond_value=tmp_cond_value;
return (Item*) 0; // Always false
}
break;
}这里在gdb中如果输入:
(gdb) call print_where(conds,"",QT_WITHOUT_INTRODUCERS) WHERE:() (nil)
3.11 JOIN::exec()
//
if (zero_result_cause)
{
//返回0结果行
return_zero_rows(this, *columns_list);
DBUG_VOID_RETURN;
}作者: 吴炼钿

相关文章推荐
- mysql sql查询过程分析之explain关键字
- Mybatis底层原理学习(二):从源码角度分析一次查询操作过程
- Navicat for MySQL 执行sql文件过程分析(导入数据)
- SQL查询前10条记录(SqlServer/mysql/oracle)语法分析
- mysql高级----查询截取分析(二):批量插入数据脚本、用show profile分析sql、全局查询日志
- PostgreSQL服务过程中的那些事二:Pg服务进程处理简单查询四:分析重写成querytree
- MySQL索引优化分析,SQL优化,慢查询分析
- MySQL——查询sql总结:简单查询、连接查询、子查询
- mysql提供了explain query_sql进行查询分析
- MySQL第五天---存储过程、查询区分大小写、事务(MySQL及Java实现的简单模板)
- 查询和分析存储过程性能的T-SQL
- MySQL高级开发--慢查询日志分析(二)--分析慢SQL(show profile)
- MySQL中如何查看“慢查询”,如何分析执行SQL的效率?
- 推荐SQLPrompt3 -简单破解无限期的使用这款很不错的SQL查询分析工具
- 简单搞一下 Oracle 存储过程动态SQL之获取查询总数!
- MySQL (五) 下 sql 练习(查询分析)
- MySQL中如何查看“慢查询”,如何分析执行SQL的效率?
- 分析mysql的QueryCache在相同语义SQL是否可以使用查询缓存
- MySQL利用profile分析慢sql详解(group left join效率高于子查询)
- 【MySql性能优化二】利用explain进行查询和分析sql语句