【目标检测】R-CNN系列之Faster-RCNN
2018-03-25 15:56
866 查看
基础特征提取网络:VGG、PVANet、ResNet、IncRes V2、ResNeXt
1. 如何设计区域生成网络;
2. 如何训练区域生成网络;
3. 如何让区域生成网络和Fast RCNN网络共享特征提取网络。

这张图只需要记住一点:RPN网络,这是本文的核心贡献,RPN通过深度网络代替了以往Selective Search方法实现Proposal 功能,相较于之前方法有很大提升。

这张图非常简洁,如果先前不了解RPN的同学可能不是很懂,从几个关键点说明一下:1)RPN 连接在 Conv5 之后 参考网络结构图,先理解 Conv5,Conv5是前面经过4次conv和pooling。 对于原图800*600的输入,Feature尺寸 变为[800/16,600/16] = [50,37.5],即卷积池化的特征提取过程中不断的缩小了图像原来的尺寸。 Conv5的输出维度为 256,Feature维度 为 256,可以理解为通道数,特征数。2)Anchor 生成与排序 特征图采用滑窗方式遍历,每个特征像素点 对应K个 Anchor(即不同的Scale和Size),上述input对应的Anchor Count为 50*38*k(9) = 17100。(三种不同的Scale和size,所以K取9) 对应如此多的 Anchor,需要通过置信度剔除大多数Candidate,通常保留100-300个就足够了。(Candidate减少这一步也是Faster-RCNN速度变快的一个原因)
训练过程中通过IOU进行正负样本的选择,测试过程中置信度较低的被丢弃。(IOU不懂的话,可以简单理解为重叠率)
3)RPN 输出
如上图所示,输出分为两部分,2K Scores + 4K Reg,基于 256d 的 intermediate 层,通过两个网络,同时进行 分类 + 回归,Scores提供了作为前景、背景目标的概率(2位),Reg提供了4个坐标值(x,y,w,h),标识Box位置。
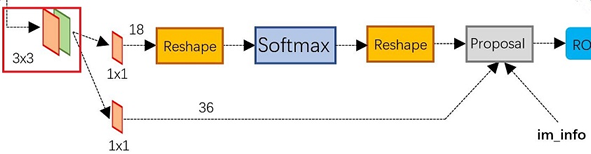
参考如下Caffe结构图,先通过3*3 的卷积核进行处理,然后1*1的卷积核进行降维,在 k=9 的情况下,每个像素对应生成 2*k = 18个 Scores 参数 和 4*k = 36个 Reg参数。
整体上 1*1 卷积生成的特征是 分类W*H*18 & 回归W*H*36,其中 ReShape 是方便 Softmax 用的,可以忽略掉。
Proposal层 根据 Softmax 输出(丢弃背景),结合对应 Anchor和Stride进行映射,将Box映射到原图,作为下一步 ROI Pooling 的输入。
注意:3*3卷积核的中心点对应原图(re-scale,源代码设置re-scale为600*1000)上的位置(点),将该点作为anchor的中心点,在原图中框出多尺度、多种长宽比的anchors。所以,anchor不在conv特征图上,而在原图上。对于一个大小为H*W的特征层,它上面每一个像素点对应9个anchor,这里有一个重要的参数feat_stride = 16, 它表示特征层上移动一个点,对应原图移动16个像素点(看一看网络中的stride就明白16的来历了)。把这9个anchor的坐标进行平移操作,获得在原图上的坐标。之后根据ground truth label和这些anchor之间的关系生成rpn_lables,具体的方法论文中有提到,根据overlap来计算,生成的rpn_labels中,positive的位置被置为1,negative的位置被置为0,其他的为-1。box_target通过_compute_targets()函数生成,这个函数实际上是寻找每一个anchor最匹配的ground truth box, 然后进行论文中提到的box坐标的转化。

在整个faster RCNN算法中,有三种尺度。

区域生成网络(RPN)和fast RCNN都需要一个原始特征提取网络(上图灰色方框)。这个网络使用ImageNet的分类库得到初始参数W0,但要如何精调参数,使其同时满足两方的需求呢?本文讲解了三种方法。
b. 从W0W0开始,用候选区域训练Fast RCNN,参数记为W1W1
c. 从W1W1开始,训练RPN…
具体操作时,仅执行两次迭代,并在训练时冻结了部分层。论文中的实验使用此方法。
如Ross Girshick在ICCV 15年的讲座Training R-CNNs of various velocities中所述,采用此方法没有什么根本原因,主要是因为”实现问题,以及截稿日期“。
近似联合训练直接在上图结构上训练。在backward计算梯度时,把提取的ROI区域当做固定值看待;在backward更新参数时,来自RPN和来自Fast RCNN的增量合并输入原始特征提取层。
此方法和前方法效果类似,但能将训练时间减少20%-25%。公布的python代码中包含此方法。
联合训练直接在上图结构上训练。但在backward计算梯度时,要考虑ROI区域的变化的影响。推导超出本文范畴,请参看15年NIP论文。
基于区域的目标检测CNN如何利用这些建议框。对于检测网络,我们采用Fast R-CNN,现在描述一种算法,学习由RPN和Fast R-CNN之间共享的卷积层。 RPN和Fast R-CNN都是独立训练的,要用不同方式修改它们的卷积层。因此需要开发一种允许两个网络间共享卷积层的技术,而不是分别学习两个网络。注意到这不是仅仅定义一个包含了RPN和Fast R-CNN的单独网络,然后用反向传播联合优化它那么简单。原因是Fast R-CNN训练依赖于固定的目标建议框,而且并不清楚当同时改变建议机制时,学习Fast R-CNN会不会收敛。 RPN在提取得到proposals后,作者选择使用Fast-R-CNN实现最终目标的检测和识别。RPN和Fast-R-CNN共用了13个VGG的卷积层,显然将这两个网络完全孤立训练不是明智的选择,作者采用交替训练(Alternating training)阶段卷积层特征共享: 第一步,我们依上述训练RPN,该网络用ImageNet预训练的模型初始化,并端到端微调用于区域建议任务; 第二步,我们利用第一步的RPN生成的建议框,由Fast R-CNN训练一个单独的检测网络,这个检测网络同样是由ImageNet预训练的模型初始化的,这时候两个网络还没有共享卷积层; 第三步,我们用检测网络初始化RPN训练,但我们固定共享的卷积层,并且只微调RPN独有的层,现在两个网络共享卷积层了; 第四步,保持共享的卷积层固定,微调Fast R-CNN的fc层。这样,两个网络共享相同的卷积层,构成一个统一的网络。注意:第一次迭代时,用ImageNet得到的模型初始化RPN和Fast-R-CNN中卷积层的参数;从第二次迭代开始,训练RPN时,用Fast-R-CNN的共享卷积层参数初始化RPN中的共享卷积层参数,然后只Fine-tune不共享的卷积层和其他层的相应参数。训练Fast-RCNN时,保持其与RPN共享的卷积层参数不变,只Fine-tune不共享的层对应的参数。这样就可以实现两个网络卷积层特征共享训练。关于论文其他内容建议直接看原文。
RCNN:
1. 在图像中确定约1000-2000个候选框 (使用选择性搜索)
2. 每个候选框内图像块缩放至相同大小,并输入到CNN内进行特征提取
3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4. 对于属于某一特征的候选框,用回归器进一步调整其位置Fast RCNN:
1. 在图像中确定约1000-2000个候选框 (使用选择性搜索)
2. 对整张图片输进CNN,得到feature map
3. 找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层
4. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
5. 对于属于某一特征的候选框,用回归器进一步调整其位置Faster RCNN:
1. 对整张图片输进CNN,得到feature map
2. 卷积特征输入到RPN,得到候选框的特征信息
3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4. 对于属于某一特征的候选框,用回归器进一步调整其位置总的来说,从R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN一路走来,基于深度学习目标检测的流程变得越来越精简,精度越来越高,速度也越来越快。可以说基于region proposal的R-CNN系列目标检测方法是当前目标检测技术领域最主要的一个分支。
1、Faster R-CNN的思想:
Faster R-CNN可以简单地看做“区域生成网络RPNs + Fast R-CNN”的系统,用区域生成网络代替FastR-CNN中的Selective Search方法。Faster R-CNN这篇论文着重解决了这个系统中的三个问题:1. 如何设计区域生成网络;
2. 如何训练区域生成网络;
3. 如何让区域生成网络和Fast RCNN网络共享特征提取网络。
2、Faster-RCNN的网络结构:
Faster-R-CNN算法由两大模块组成:1.PRN候选框提取模块;2.Fast R-CNN检测模块。其中,前端是基于卷积的基础特征提取网络,可以自由选择,没记错的话当时作者用过VGG和ZF,而RPN是全卷积神经网络,用于提取候选框;Fast R-CNN基于RPN提取的proposal检测并识别proposal中的目标。这张图只需要记住一点:RPN网络,这是本文的核心贡献,RPN通过深度网络代替了以往Selective Search方法实现Proposal 功能,相较于之前方法有很大提升。
3、RPN网络的解析:
这张图非常简洁,如果先前不了解RPN的同学可能不是很懂,从几个关键点说明一下:1)RPN 连接在 Conv5 之后 参考网络结构图,先理解 Conv5,Conv5是前面经过4次conv和pooling。 对于原图800*600的输入,Feature尺寸 变为[800/16,600/16] = [50,37.5],即卷积池化的特征提取过程中不断的缩小了图像原来的尺寸。 Conv5的输出维度为 256,Feature维度 为 256,可以理解为通道数,特征数。2)Anchor 生成与排序 特征图采用滑窗方式遍历,每个特征像素点 对应K个 Anchor(即不同的Scale和Size),上述input对应的Anchor Count为 50*38*k(9) = 17100。(三种不同的Scale和size,所以K取9) 对应如此多的 Anchor,需要通过置信度剔除大多数Candidate,通常保留100-300个就足够了。(Candidate减少这一步也是Faster-RCNN速度变快的一个原因)
训练过程中通过IOU进行正负样本的选择,测试过程中置信度较低的被丢弃。(IOU不懂的话,可以简单理解为重叠率)
3)RPN 输出
如上图所示,输出分为两部分,2K Scores + 4K Reg,基于 256d 的 intermediate 层,通过两个网络,同时进行 分类 + 回归,Scores提供了作为前景、背景目标的概率(2位),Reg提供了4个坐标值(x,y,w,h),标识Box位置。
参考如下Caffe结构图,先通过3*3 的卷积核进行处理,然后1*1的卷积核进行降维,在 k=9 的情况下,每个像素对应生成 2*k = 18个 Scores 参数 和 4*k = 36个 Reg参数。
整体上 1*1 卷积生成的特征是 分类W*H*18 & 回归W*H*36,其中 ReShape 是方便 Softmax 用的,可以忽略掉。
Proposal层 根据 Softmax 输出(丢弃背景),结合对应 Anchor和Stride进行映射,将Box映射到原图,作为下一步 ROI Pooling 的输入。
注意:3*3卷积核的中心点对应原图(re-scale,源代码设置re-scale为600*1000)上的位置(点),将该点作为anchor的中心点,在原图中框出多尺度、多种长宽比的anchors。所以,anchor不在conv特征图上,而在原图上。对于一个大小为H*W的特征层,它上面每一个像素点对应9个anchor,这里有一个重要的参数feat_stride = 16, 它表示特征层上移动一个点,对应原图移动16个像素点(看一看网络中的stride就明白16的来历了)。把这9个anchor的坐标进行平移操作,获得在原图上的坐标。之后根据ground truth label和这些anchor之间的关系生成rpn_lables,具体的方法论文中有提到,根据overlap来计算,生成的rpn_labels中,positive的位置被置为1,negative的位置被置为0,其他的为-1。box_target通过_compute_targets()函数生成,这个函数实际上是寻找每一个anchor最匹配的ground truth box, 然后进行论文中提到的box坐标的转化。
在整个faster RCNN算法中,有三种尺度。
原图尺度:原始输入的大小。不受任何限制,不影响性能。
归一化尺度:输入特征提取网络的大小,在测试时设置,源码中opts.test_scale=600。anchor在这个尺度上设定。这个参数和anchor的相对大小决定了想要检测的目标范围。
网络输入尺度:输入特征检测网络的大小,在训练时设置,源码中为224*224。
RPN与Fast R-CNN特征共享:
Faster-R-CNN算法油两大模块组成,PRN候选框提取模块;Fast R-CNN检测模块,前面已经讲完RPN网络。区域生成网络(RPN)和fast RCNN都需要一个原始特征提取网络(上图灰色方框)。这个网络使用ImageNet的分类库得到初始参数W0,但要如何精调参数,使其同时满足两方的需求呢?本文讲解了三种方法。
轮流训练
a. 从W0W0开始,训练RPN。用RPN提取训练集上的候选区域b. 从W0W0开始,用候选区域训练Fast RCNN,参数记为W1W1
c. 从W1W1开始,训练RPN…
具体操作时,仅执行两次迭代,并在训练时冻结了部分层。论文中的实验使用此方法。
如Ross Girshick在ICCV 15年的讲座Training R-CNNs of various velocities中所述,采用此方法没有什么根本原因,主要是因为”实现问题,以及截稿日期“。
近似联合训练直接在上图结构上训练。在backward计算梯度时,把提取的ROI区域当做固定值看待;在backward更新参数时,来自RPN和来自Fast RCNN的增量合并输入原始特征提取层。
此方法和前方法效果类似,但能将训练时间减少20%-25%。公布的python代码中包含此方法。
联合训练直接在上图结构上训练。但在backward计算梯度时,要考虑ROI区域的变化的影响。推导超出本文范畴,请参看15年NIP论文。
基于区域的目标检测CNN如何利用这些建议框。对于检测网络,我们采用Fast R-CNN,现在描述一种算法,学习由RPN和Fast R-CNN之间共享的卷积层。 RPN和Fast R-CNN都是独立训练的,要用不同方式修改它们的卷积层。因此需要开发一种允许两个网络间共享卷积层的技术,而不是分别学习两个网络。注意到这不是仅仅定义一个包含了RPN和Fast R-CNN的单独网络,然后用反向传播联合优化它那么简单。原因是Fast R-CNN训练依赖于固定的目标建议框,而且并不清楚当同时改变建议机制时,学习Fast R-CNN会不会收敛。 RPN在提取得到proposals后,作者选择使用Fast-R-CNN实现最终目标的检测和识别。RPN和Fast-R-CNN共用了13个VGG的卷积层,显然将这两个网络完全孤立训练不是明智的选择,作者采用交替训练(Alternating training)阶段卷积层特征共享: 第一步,我们依上述训练RPN,该网络用ImageNet预训练的模型初始化,并端到端微调用于区域建议任务; 第二步,我们利用第一步的RPN生成的建议框,由Fast R-CNN训练一个单独的检测网络,这个检测网络同样是由ImageNet预训练的模型初始化的,这时候两个网络还没有共享卷积层; 第三步,我们用检测网络初始化RPN训练,但我们固定共享的卷积层,并且只微调RPN独有的层,现在两个网络共享卷积层了; 第四步,保持共享的卷积层固定,微调Fast R-CNN的fc层。这样,两个网络共享相同的卷积层,构成一个统一的网络。注意:第一次迭代时,用ImageNet得到的模型初始化RPN和Fast-R-CNN中卷积层的参数;从第二次迭代开始,训练RPN时,用Fast-R-CNN的共享卷积层参数初始化RPN中的共享卷积层参数,然后只Fine-tune不共享的卷积层和其他层的相应参数。训练Fast-RCNN时,保持其与RPN共享的卷积层参数不变,只Fine-tune不共享的层对应的参数。这样就可以实现两个网络卷积层特征共享训练。关于论文其他内容建议直接看原文。
RCNN系列总结:
至此RCNN系列目标检测算法讲完,最后总结一下各算法的步骤:RCNN:
1. 在图像中确定约1000-2000个候选框 (使用选择性搜索)
2. 每个候选框内图像块缩放至相同大小,并输入到CNN内进行特征提取
3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4. 对于属于某一特征的候选框,用回归器进一步调整其位置Fast RCNN:
1. 在图像中确定约1000-2000个候选框 (使用选择性搜索)
2. 对整张图片输进CNN,得到feature map
3. 找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层
4. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
5. 对于属于某一特征的候选框,用回归器进一步调整其位置Faster RCNN:
1. 对整张图片输进CNN,得到feature map
2. 卷积特征输入到RPN,得到候选框的特征信息
3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4. 对于属于某一特征的候选框,用回归器进一步调整其位置总的来说,从R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN一路走来,基于深度学习目标检测的流程变得越来越精简,精度越来越高,速度也越来越快。可以说基于region proposal的R-CNN系列目标检测方法是当前目标检测技术领域最主要的一个分支。

相关文章推荐
- 深度学习笔记之目标检测算法系列(包括RCNN、Fast RCNN、Faster RCNN和SSD)
- 目标检测 RCNN, SPPNet, Fast RCNN, Faster RCNN 总结
- 目标检测方法系列:R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD
- 目标检测:RCNN、FAST-RCNN、FASTER-RCNN对比
- 目标检测——从RCNN到Faster RCNN 串烧
- Caffe学习系列——6使用Faster-RCNN进行目标检测
- 目标检测方法系列——R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD
- 【相关知识】目标检测之||R-CNN||SPP-NET ||Fast-RCNN ||Faster-RCNN||YOLO ||SSD
- 目标检测网络发展历程从R-CNN到Faster-RCNN
- 目标检测方法系列:R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD
- 目标检测方法系列——R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD
- CNN目标检测与分割(一):Faster RCNN详解
- 大话目标检测经典模型(RCNN、Fast RCNN、Faster RCNN)
- 目标检测——从RCNN到Faster RCNN 串烧
- 1:基于深度学习的目标检测技术:RCNN、Fast R-CNN、Faster R-CNN
- 目标检测:RCNN,FAST-RCNN,FASTER-RCNN区别
- 大话目标检测经典模型(RCNN、Fast RCNN、Faster RCNN)
- 目标检测之RCNN,SPP-NET,Fast-RCNN,Faster-RCNN
- TensorFlow 目标检测方法系列——R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD
- CNN目标检测(一):Faster RCNN详解