编译原理第二章总结
2018-03-24 10:40
267 查看
第二章 高级语言及语法描述
2.1程序语言的定义
程序语言主要由语法和语义两个方面定义。
2.1.1 语法三个基本概念:1,字母表:一个有限的字符集,包括大小写英文字母、数字 、特殊字符; 任何语言:一定字符集(字母表)上的字符串(有限序列)
2,单词符号:是语言中具有独立意义的最基本结构
一般包括:常数,标识符,基本字、算符和界符3,语法单位:由单词符号构成的更大的结构
一般包括: 表达式、 语句、分程序(语句块)、函数(有返回值)、程序;
语法=词法规则+语法规则
词法规则规定了字母表中哪样的字符串是一个单词符号。
语法规则规定了如何从单词符号形成语法单位。
2.1.2 语义
定义语言的单词符号和语法单位的意义。
语义描述方法:属性文法和基于属性文法的语法制导翻译方法。
2.2 高级语言的一般特性
2.2.1 高级语言的分类1,按程序设计范型分类:强制式语言(过程式语言。c)、应用式语言(函数式语言。lisp)、基于规则的语言(prolog,yacc)、面向对象的语言(java);2,按编译时是否需要类型检查分类:静态类型语言(c,c++,java)、动态类型语言(Python, Ruby,PHP)
3,按类型检查强弱分类:弱类型语言(C,C++,VB)、强类型语言(JAVA, C#)
2.2.2 程序结构支持过程的嵌套定义(Pascal)、不支持过程的嵌套定义(c/c++/java)
程序结构的不同,决定了符号表构造方法的不同
2.2.3 数据类型与操作基本数据类型(int,char,float,double)
构造数据类型(指针,静态数组,动态数组)
自定义数据类型(栈,队列,字符串,结构体)
每种数据类型都隐含了数据对象可以具有的值
和作用于这种类型数据对象的操作
名字和标识符:标识符:以字母开头后跟字母数字组成字符串,例 PI、nm1
名字:当给标识符一定意义时,该标识符成为名字,例 PI :π(圆周率)
(1)同一标识符在过程中的不同地点(不同的分程序)可用来表示不同的名字
(2)在程序运行时,同一个名字在不同时间也可能代表不同的存储单元(递归的情况)
(3)同一个存储单元也可能有好几个不同的名字(c语言中的共用体)(4)名字的性质可以隐约定
例:FORTRAN语言中未经说明语句显式说明的名字,凡以I,J,…,N为首的均认为是整型,否则就认为是实型。
(5)名字的性质可以动态确定
例:APL语言,同一标识符在一行里可能是整型,在另一行里就是实型
(6)名字的性质是“静态”确定的:名字的性质是通过说明语句或隐约规则定义的
名字的性质是“动态”确定的:名字的性质只有在程序运行时才能知道静态:编译时可以确定的, 动态:运行时才能确定的
2.2.4 语句与控制结构
1,表达式:表达式的形式(前缀,中缀,后缀)
表达式中的运算符(算数,关系,逻辑;优先级,结合性)
运算符的代数性质(交换律,结合律等等)2,语句说明性语句执行性语句:赋值语句、控制语句、输入/输出语句
2.3 程序语言的语法描述基本概念:字母表:由若干元素组成的有限非空集合,用表示,它的每个元素称为一个符号。
符号串: 由中的符号所构成的有穷序列。
空字:不包含符号的序列称为空字,记为。
用*表示上的所有符号串的全体,空字也包括在其中。字符串集合的和(等价于集合的并运算):
设A、B是两个符号串的集合,则将集合A、B的和记为A+B或A B,定义为:A B={w|wA或wB}
符号串集合的连接:*的子集U和V中的(连接)积定义为: UV={αβ∣α∈U &β∈ V }
即集合UV中的符号串是由U和V的符号串连接而成的。注意,一般UVVU,但(UV)W=U(VW).V的闭包:
令: V* = V0V1V2…,称 V*是V的闭包。
V的正则包(正闭包,正则闭包):
记V+ = VV*, 称 V+是V的正则包,即V+ =V1V2V3…。
2.3.1 上下文无关文法(它定义的语法单位是与上下文环境无关的,不能描述自然语言)
一个上下文无关文法G是一个四元式(VT,VN,S,P):
VT是一个非空有限集,它的每个元素称为终结符号(组成语言的基本符号);
VN是一个非空有限集,它的每个元素称为非终结符号(代表语法范畴),VN∩VT=空集;
S是一个非终结符号,称为开始符号;
P是一个产生式集合(有限),每个产生式的形式是P->a,其中,P属于VN,a属于终结符和非终结符并集的闭包。开始符号S至少必须在某个产生式的左部出现一次。
采用推导的方法:利用产生式,对非终结符进行替换、展开直接推导:仅当A->γ是一个产生式,有αAβ => αγ β,该推导称为直接推导(直接导出)
如果S最终能推出a,则称a是一个句型。仅含终结符号的句型是一个句子。文法G所产生的句子的全体是一个语言。
最左推导:任何一步a=>b都是对a中的最左非终结符进行替换的。(同理最右推导)
例:G[E]: E→E+T|T T→T*F|F F→(E)|a
E=>E+T =>T+T =>F+T =>a+T =>a+T*F =>a+F*F =>a+a*F =>a+a*a(最左推导)
E=>E+T =>E+T*F =>E+T*a =>E+F*a =>E+a*a =>T+a*a =>F+a*a =>a+a*a (最右推导)最右推导被称为规范推导。
限制:不含有P->P,且P不存在用不终结的回路。
2.3.2 语法分析数与二义性
语法树的根结由开始符号所标记。随着推导的展开,当某个非终结符被它的某个候选式所替换时,这个非终结符的相应结就会产生下一代新结。如对于文法 E→E+E|E*E|(E)|i, 关于(i*i+i)的推导形成语法树如图:
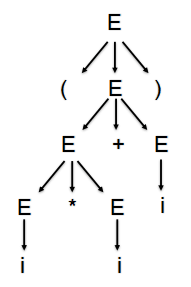
如果一个文法中存在某个句子对应两棵不同的语法树,则称这个文法是二义的。
如E→E+E|E*E|(E)|i, 关于(i*i+i)的推导E=>(E) =>(E*E) =>(i*E) =>(i*E+E)=>(i*i+E) =>(i*i+i)
E=>(E)=>(E+E) =>(E*E+E) => (i*E+E)=>(i*i+E) =>(i*i+i)
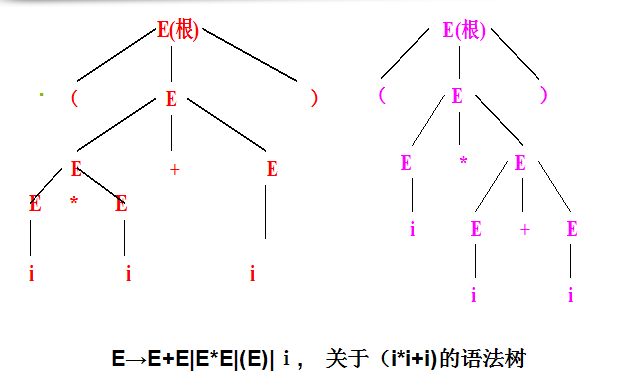
消除二义性:规定优先级(加新运算符)。
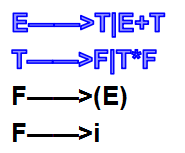
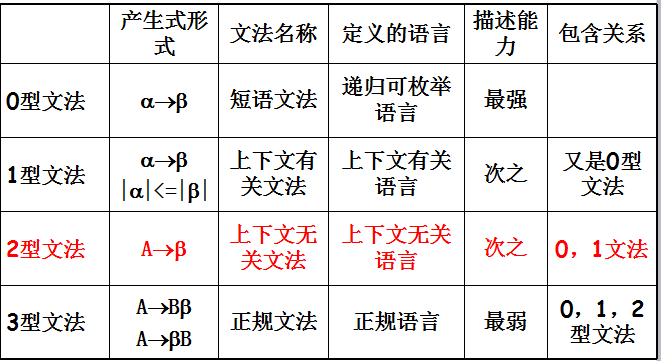
2.3.3 形式语言鸟瞰
6,1,是{0,1,2,3,4,5,6,7,8,9}的闭包。
2,最左推导:
N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127N=>ND=>DD=>3D=>34N=>ND=>NDD=>DDD=>5DD=>56D=>568依次替换最左边的
最右推导:
N=>ND=>N7=>ND7=>N27=>ND27=>N127=>D127=>0127N=>ND=>N4=>D4=>34N=>ND=>N8=>ND8=>N68=>D68=>568依次替换最右边的
7,G(E):E->SA|SB
S->+|-|空字.
A->1|3|5|7|9
B->CFG
C->A|2|4|6|8
F->DF|D|空字
D->0|C
G->0|A


通过这一章的学习,深刻体会到编译原理“路漫漫其修远兮”,抽象难懂,但是通过不断的举例研究和老师讲解,还是可以懂。在学习中还有很多对计算机分析语言神奇的赞叹,希望在越来越难懂的后继章节,上下求索。
2.1程序语言的定义
程序语言主要由语法和语义两个方面定义。
2.1.1 语法三个基本概念:1,字母表:一个有限的字符集,包括大小写英文字母、数字 、特殊字符; 任何语言:一定字符集(字母表)上的字符串(有限序列)
2,单词符号:是语言中具有独立意义的最基本结构
一般包括:常数,标识符,基本字、算符和界符3,语法单位:由单词符号构成的更大的结构
一般包括: 表达式、 语句、分程序(语句块)、函数(有返回值)、程序;
语法=词法规则+语法规则
词法规则规定了字母表中哪样的字符串是一个单词符号。
语法规则规定了如何从单词符号形成语法单位。
2.1.2 语义
定义语言的单词符号和语法单位的意义。
语义描述方法:属性文法和基于属性文法的语法制导翻译方法。
2.2 高级语言的一般特性
2.2.1 高级语言的分类1,按程序设计范型分类:强制式语言(过程式语言。c)、应用式语言(函数式语言。lisp)、基于规则的语言(prolog,yacc)、面向对象的语言(java);2,按编译时是否需要类型检查分类:静态类型语言(c,c++,java)、动态类型语言(Python, Ruby,PHP)
3,按类型检查强弱分类:弱类型语言(C,C++,VB)、强类型语言(JAVA, C#)
2.2.2 程序结构支持过程的嵌套定义(Pascal)、不支持过程的嵌套定义(c/c++/java)
程序结构的不同,决定了符号表构造方法的不同
2.2.3 数据类型与操作基本数据类型(int,char,float,double)
构造数据类型(指针,静态数组,动态数组)
自定义数据类型(栈,队列,字符串,结构体)
每种数据类型都隐含了数据对象可以具有的值
和作用于这种类型数据对象的操作
名字和标识符:标识符:以字母开头后跟字母数字组成字符串,例 PI、nm1
名字:当给标识符一定意义时,该标识符成为名字,例 PI :π(圆周率)
(1)同一标识符在过程中的不同地点(不同的分程序)可用来表示不同的名字
(2)在程序运行时,同一个名字在不同时间也可能代表不同的存储单元(递归的情况)
(3)同一个存储单元也可能有好几个不同的名字(c语言中的共用体)(4)名字的性质可以隐约定
例:FORTRAN语言中未经说明语句显式说明的名字,凡以I,J,…,N为首的均认为是整型,否则就认为是实型。
(5)名字的性质可以动态确定
例:APL语言,同一标识符在一行里可能是整型,在另一行里就是实型
(6)名字的性质是“静态”确定的:名字的性质是通过说明语句或隐约规则定义的
名字的性质是“动态”确定的:名字的性质只有在程序运行时才能知道静态:编译时可以确定的, 动态:运行时才能确定的
2.2.4 语句与控制结构
1,表达式:表达式的形式(前缀,中缀,后缀)
表达式中的运算符(算数,关系,逻辑;优先级,结合性)
运算符的代数性质(交换律,结合律等等)2,语句说明性语句执行性语句:赋值语句、控制语句、输入/输出语句
2.3 程序语言的语法描述基本概念:字母表:由若干元素组成的有限非空集合,用表示,它的每个元素称为一个符号。
符号串: 由中的符号所构成的有穷序列。
空字:不包含符号的序列称为空字,记为。
用*表示上的所有符号串的全体,空字也包括在其中。字符串集合的和(等价于集合的并运算):
设A、B是两个符号串的集合,则将集合A、B的和记为A+B或A B,定义为:A B={w|wA或wB}
符号串集合的连接:*的子集U和V中的(连接)积定义为: UV={αβ∣α∈U &β∈ V }
即集合UV中的符号串是由U和V的符号串连接而成的。注意,一般UVVU,但(UV)W=U(VW).V的闭包:
令: V* = V0V1V2…,称 V*是V的闭包。
V的正则包(正闭包,正则闭包):
记V+ = VV*, 称 V+是V的正则包,即V+ =V1V2V3…。
2.3.1 上下文无关文法(它定义的语法单位是与上下文环境无关的,不能描述自然语言)
一个上下文无关文法G是一个四元式(VT,VN,S,P):
VT是一个非空有限集,它的每个元素称为终结符号(组成语言的基本符号);
VN是一个非空有限集,它的每个元素称为非终结符号(代表语法范畴),VN∩VT=空集;
S是一个非终结符号,称为开始符号;
P是一个产生式集合(有限),每个产生式的形式是P->a,其中,P属于VN,a属于终结符和非终结符并集的闭包。开始符号S至少必须在某个产生式的左部出现一次。
采用推导的方法:利用产生式,对非终结符进行替换、展开直接推导:仅当A->γ是一个产生式,有αAβ => αγ β,该推导称为直接推导(直接导出)
如果S最终能推出a,则称a是一个句型。仅含终结符号的句型是一个句子。文法G所产生的句子的全体是一个语言。
最左推导:任何一步a=>b都是对a中的最左非终结符进行替换的。(同理最右推导)
例:G[E]: E→E+T|T T→T*F|F F→(E)|a
E=>E+T =>T+T =>F+T =>a+T =>a+T*F =>a+F*F =>a+a*F =>a+a*a(最左推导)
E=>E+T =>E+T*F =>E+T*a =>E+F*a =>E+a*a =>T+a*a =>F+a*a =>a+a*a (最右推导)最右推导被称为规范推导。
限制:不含有P->P,且P不存在用不终结的回路。
2.3.2 语法分析数与二义性
语法树的根结由开始符号所标记。随着推导的展开,当某个非终结符被它的某个候选式所替换时,这个非终结符的相应结就会产生下一代新结。如对于文法 E→E+E|E*E|(E)|i, 关于(i*i+i)的推导形成语法树如图:
如果一个文法中存在某个句子对应两棵不同的语法树,则称这个文法是二义的。
如E→E+E|E*E|(E)|i, 关于(i*i+i)的推导E=>(E) =>(E*E) =>(i*E) =>(i*E+E)=>(i*i+E) =>(i*i+i)
E=>(E)=>(E+E) =>(E*E+E) => (i*E+E)=>(i*i+E) =>(i*i+i)
消除二义性:规定优先级(加新运算符)。
2.3.3 形式语言鸟瞰
6,1,是{0,1,2,3,4,5,6,7,8,9}的闭包。
2,最左推导:
N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127N=>ND=>DD=>3D=>34N=>ND=>NDD=>DDD=>5DD=>56D=>568依次替换最左边的
最右推导:
N=>ND=>N7=>ND7=>N27=>ND27=>N127=>D127=>0127N=>ND=>N4=>D4=>34N=>ND=>N8=>ND8=>N68=>D68=>568依次替换最右边的
7,G(E):E->SA|SB
S->+|-|空字.
A->1|3|5|7|9
B->CFG
C->A|2|4|6|8
F->DF|D|空字
D->0|C
G->0|A
通过这一章的学习,深刻体会到编译原理“路漫漫其修远兮”,抽象难懂,但是通过不断的举例研究和老师讲解,还是可以懂。在学习中还有很多对计算机分析语言神奇的赞叹,希望在越来越难懂的后继章节,上下求索。

相关文章推荐
- 编译原理——第二章高级语言及其语法描述总结
- 编译原理第二章高级语言及其语法描述内容总结
- 编译原理—第二章学习总结
- 编译原理第二章总结
- 编译原理第二章总结
- 编译原理第二章学习总结
- 编译原理第二章高级语言机器语法描述总结
- 编译原理-第二章-高级语言及其语法描述总结
- 程序设计语言——编译原理 第二章总结
- 编译原理第二章高级语言及其语法描述内容总结
- 编译原理期末复习考点总结(一) 通俗易懂的方式解释概念(纯手打)
- 第二章 Javac编译原理
- 【编译原理】第二章 一个简单的语法制导翻译器
- 编译原理(龙书第二版):语法分析相关习题及总结
- 软了个考——其实一开始总结编译原理我是拒绝的
- 编译原理第二次作业 编译器任务总结
- 【编译原理】概述总结(一)
- 编译原理第三章总结
- 编译原理第三章词法分析内容总结
- 编译原理(自动机)软考考点总结