Zookeeper官方文档学习笔记
2018-03-23 10:50
375 查看
Zookeeper是一个为分布式应用服务的分布式协作服务:
应用程序可以使用它的服务来同步,维护配置,分组和命名设计目标:
简洁:分布式程序可以通过namespace协作,zookeeper的数据是存在内存中的,所以可以实现高吞吐和低冗余重复:zookeeper在一组主机(ensemble)上被复制
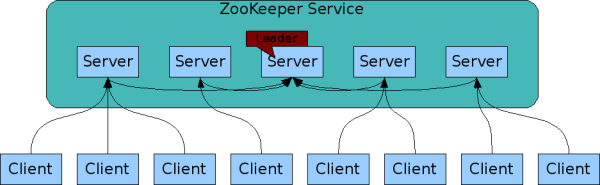
这些server彼此知道,Clients连在Server上,并维持一个TCP连接:发送请求、接受回应、查看事件、发送心跳。如果一个server掉线,它的Clients会连接到别的Servers
有序:每个zookeeper stamp更新一个代表所有交易顺序的数字
快速:zookeeper在读取:写入速率 = 10:1时最快
树状结构:
每个节点是一个znode,由路径标识Znode维护了数据变更的版本号,ACL变化,时间戳
Znode里的数据自动读写,读时会获取到所有的数据,写时会替换所有的数据
临时节点随session创建和销毁
update和watch:
客户端可以watch znodes,当znode改变时watch会被触发和移除APIs:
create:在树中创建一个节点delete:删除一个节点
exists:测试一个节点在某地是否存在
get data:从一个node获取数据
set data:给node写数据
get children:获取一个节点的子节点
sync:等待数据propagate
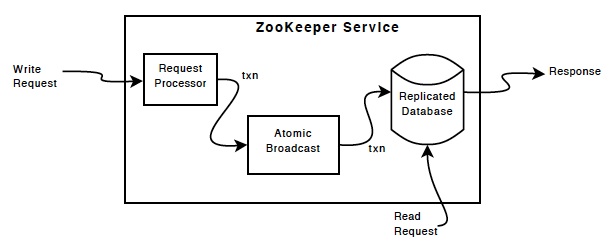
Replicated Database是一个在内存中并包括整棵树的数据库,更新会写入disk,写入也会在存入内存数据库之前序列化到disk
性能调优:
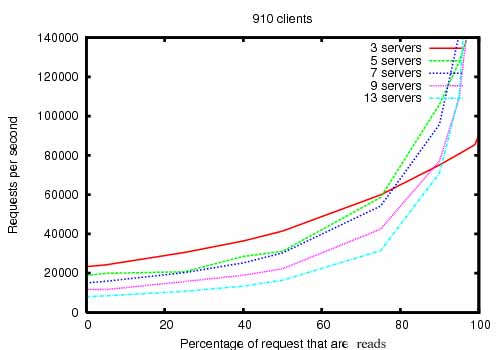
多读少写!

相关文章推荐
- db4o_8.0对象数据库官方文档翻译_学习笔记四
- ES权威指南[官方文档学习笔记]-11 search with query dsl
- ES权威指南[官方文档学习笔记]-38 Partial updates to documents
- ES权威指南[官方文档学习笔记]-22 Cluster health
- ES权威指南[官方文档学习笔记]-49 Searching - the basic tools
- ES权威指南[官方文档学习笔记]-56 Inverted index
- Log4j2官方文档翻译、学习笔记之二——Appender的分类及常用类型示例
- PostgreSQL官方文档学习笔记
- ES权威指南[官方文档学习笔记]-10 search lite
- ES权威指南[官方文档学习笔记]-37 optimistic concurrency control
- ES权威指南[官方文档学习笔记]-21 - an empty cluster
- ES权威指南[官方文档学习笔记]-48 Multi-document patterns
- Log4j2官方文档翻译、学习笔记之三——Layouts的分类及常用类型示例
- kafka官方文档学习笔记1--基本概念了解
- Solidity官方文档学习笔记(2)
- xtrabackup官方文档学习笔记【全备部分】
- libevent官方文档学习笔记
- tensorflow学习笔记十七:tensorflow官方文档学习 Vector Representations of Words
- ES权威指南[官方文档学习笔记]-9 retrieving a document
- ES权威指南[官方文档学习笔记]-36 dealing with conflicts