深度学习系列之SSD(Single Shot MultiBox Detector) 个人总结
2018-03-22 20:58
591 查看
1. Introduction
SSD模型在保证精度的前提下,速度还特别快,可以做到real time。其中原因在于ssd消除了object proposal这个环节。Faster R-CNN是先利用RPN产生object proposal,然后对proposal进行分类和回归,所以速度没有ssd快。ssd进行检测的方法是利用卷积后的多个不同尺度的feature map,每个feature map使用固定尺度(不同feature map使用的尺度不同)但不同aspect ratio的anchor。利用这些anchor来进行分类和回归,且这里的分类并不是faster r-cnn的二分类,而是最终的分类。因此,ssd更快。
*另有一个备注:文章中的default box可以理解为faster r-cnn中的anchor
2. SSD
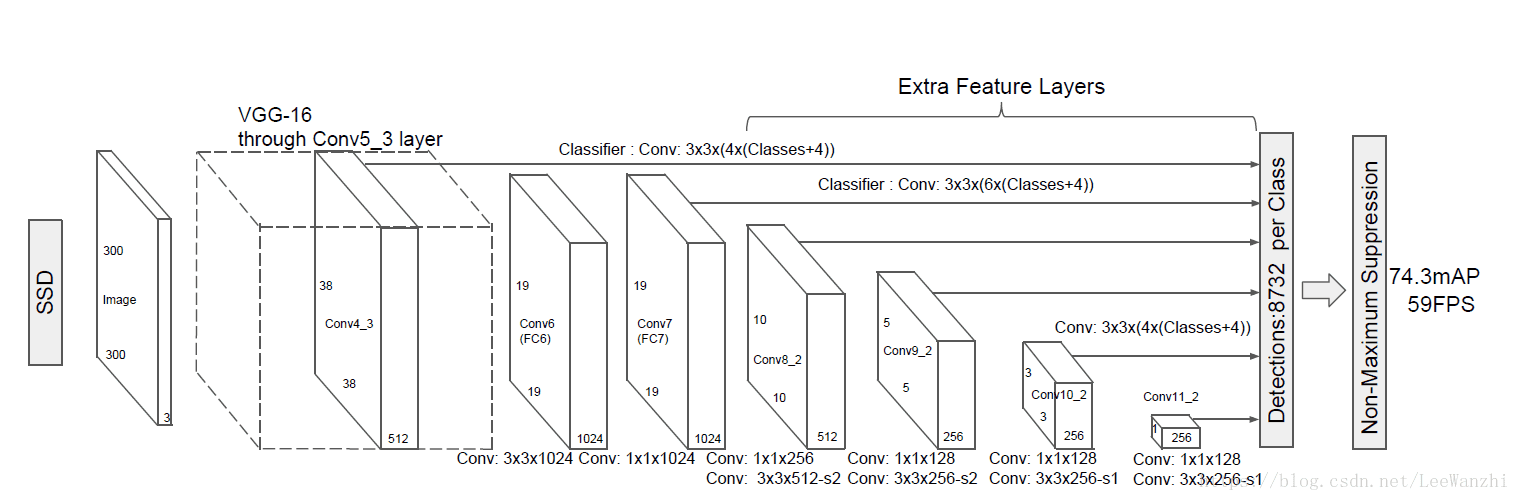
2.1 model
(1) 利用多尺度feature map进行检测,这里的多尺度不是人为缩放的,而是取自不同卷积层的feature map。如图,后面的每个feature map都直接连上了分类器。
(2) 在feature map的每个位置,有k个anchor。每个anchor产生C类分数+4个位置偏移量。这些值是有3x3的不同的小卷积核产生的。一个卷积和产生一个值。所以每个位置需要(C+4)*k个卷积核。
(3) 对于一张m x n的feature map,需要(C+4)k个卷积核,产生(C+4)*k*m*n个输出。但是一张feature map的参数量为(3*3*channel)*k(C+4)。 所有的feature map的参数量加起来,那么需要训练的参数量是很大的。这就是为什么ssd在训练的时候真的很慢而且很吃显存。那为什么检测时速度很快,堪称real-time呢?因为参数都已经训练好了呀,直接用就可以了。
这种方法可以有效覆盖image上不同尺度的物体,如图:
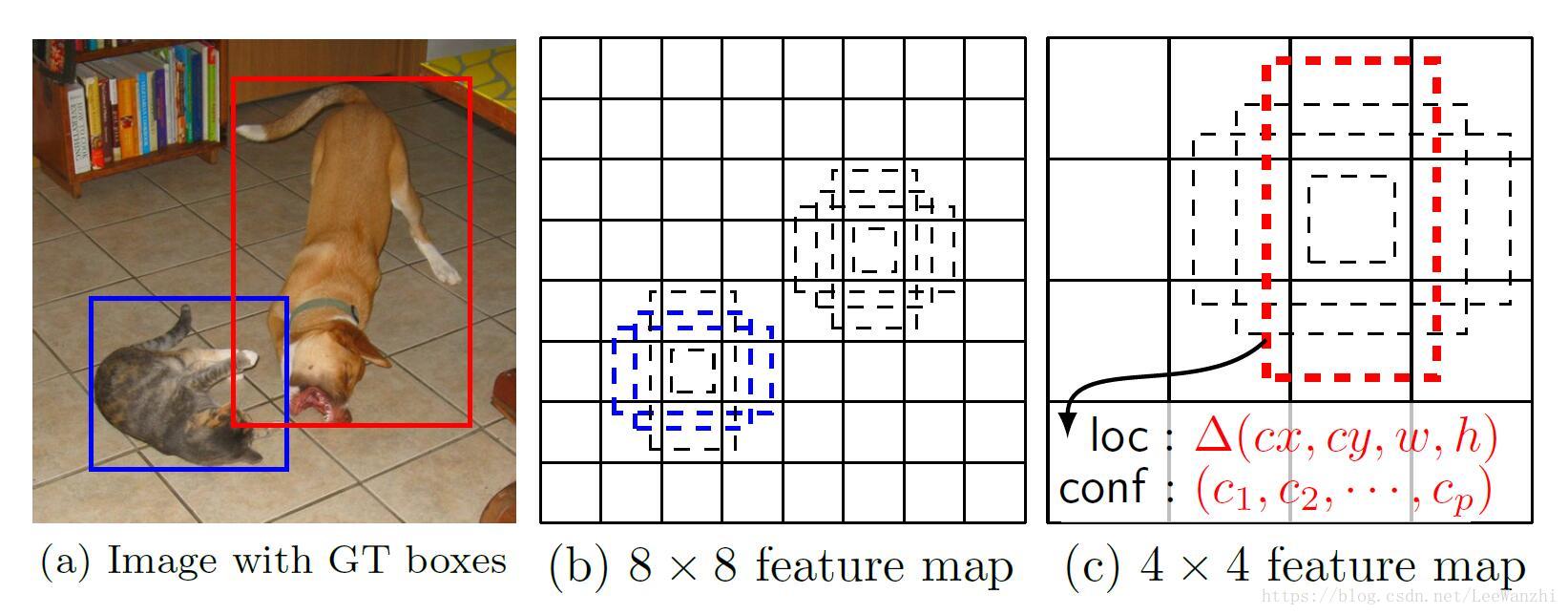
2.2 Training
匹配策略:匹配与GT的IoU大于0.5的anchor。
loss function:= 置信损失(softmax loss) + 位置损失(smooth L1)
具体公式就不写了。
另外,我们前面提到,feature map上的每个位置都会产生k个anchor。本文采用的是6个。
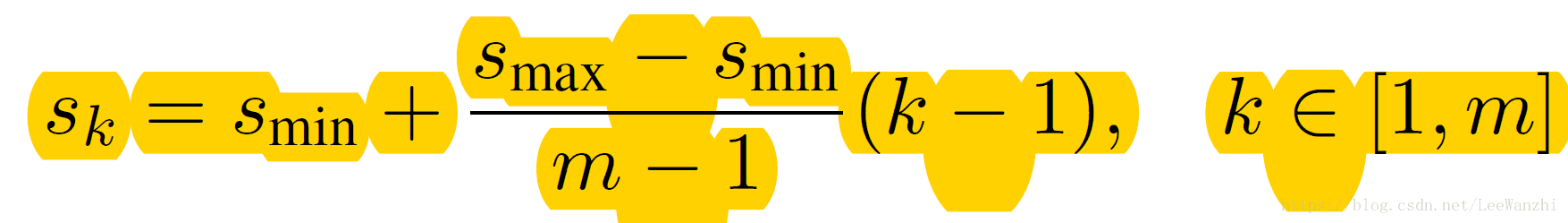
m表示feature map的数量。k是feature map的索引。Smin是最小的scale,Smax是最大的scale。 Sk表示当前feature map采用的scale。
尺度解决了,还有aspect ratio,ar={1,2,3,1/2,1/3}。
anchor的宽Wk = Sk * sqrt(ar),
anchor的高Hk = Sk / sqrt(ar).
对
a2c5
于ar=1时,另外增加一个尺度Sk(extra) = sqrt(Sk * S(k+1))
如此一来,每个位置,产生6个anchor。
hard negtive mining:将false postive存起来(也就是得分高的负样本存起来),用作训练时用的负样本。因为false postive的loss值很大,这样才能使权重得到较好的更新。如果负样本中全是易区分的负样本,则网络学不到有用的东西,权重也无法得到较好的更新。
3. 评价
ssd很6,但对于小物体的检测比较渣。因为ssd对图像进行了缩放(300x300;512x512),小物体本身就小,一缩放更小,再一卷积池化,信息几乎快丢失了。
而faster R-CNN虽然也对图像进行了resize,但只是将最短边缩放到了600,信息比ssd丰富。所以faster r-cnn对小物体检测比ssd好。
文中提到的改进:
(1)将300x300改成512x512,并且证明确实得到了改善。
(2)random crop,对图像进行随机切割。
(3)对anchor使用更小的尺度和其他不同的宽高比。我觉得可以把尺度降低。

相关文章推荐
- RCNN系列学习笔记(6):SSD: Single Shot MultiBox Detector
- 【论文笔记】物体检测系列 SSD: Single Shot MultiBox Detector
- SSD: Single Shot MultiBox Detector 编译方法总结
- 目标检测之SSD(single shot multibox detector)的pytorch代码阅读总结
- Ubuntu14.04安装CPU版SSD(Single Shot MultiBox Detector)/Caffe版本(二)
- SSD+caffe︱Single Shot MultiBox Detector 目标检测(一)
- SSD论文阅读(Wei Liu——【ECCV2016】SSD Single Shot MultiBox Detector)
- SSD: Single Shot MultiBox Detector in TensorFlow(翻译)
- CAFFE实验学习笔记(3)——SSD(Single Shot MultiBox Detector)
- SSD: Single Shot MultiBox Detector
- SSD:Single Shot MultiBox Detector
- ubuntu14.04安装CPU版SSD(Single Shot MultiBox Detector)/Caffe版本
- Ubuntu14.04安装CPU版SSD(Single Shot MultiBox Detector)/Caffe版本(三)
- SSD: Single Shot MultiBox Detector 之再阅读
- 目标检测 - 基于 SSD: Single Shot MultiBox Detector 的人体上下半身检测
- 转载SSD论文阅读:SSD: Single Shot MultiBox Detector
- SSD(single shot multibox detector)算法及Caffe代码详解
- SSD(single shot multibox detector)算法及Caffe代码详解
- 论文阅读:SSD: Single Shot MultiBox Detector
- SSD: Single Shot MultiBox Detector的安装配置和运行