ML 入门:归一化、标准化和正则化
2018-03-20 19:08
155 查看
原贴:https://zhuanlan.zhihu.com/p/29957294?utm_medium=social&utm_source=weibo在学习 Machine Learning 的过程中遇到了三个有点模糊的概念——归一化、标准化和正则化,经过收集资料和咨询培神之后,最终理解了这三者的区别,特此小记。
举个例子,我们判断一个人的身体状况是否健康,那么我们会采集人体的很多指标,比如说:身高、体重、红细胞数量、白细胞数量等。一个人身高 180cm,体重 70kg,白细胞计数

,etc.衡量两个人的状况时,白细胞计数就会起到主导作用从而遮盖住其他的特征,归一化后就不会有这样的问题。
其中

是样本数据的均值(mean),

是样本数据的标准差(std)。
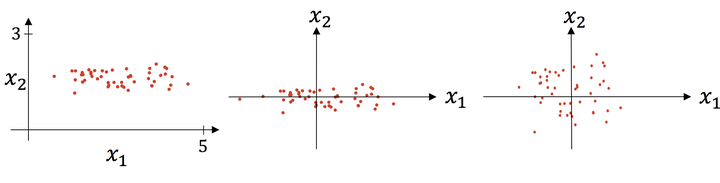
上图则是一个散点序列的标准化过程:原图->减去均值->除以标准差。显而易见,变成了一个均值为 0 ,方差为 1 的分布,下图通过 Cost 函数让我们更好的理解标准化的作用。
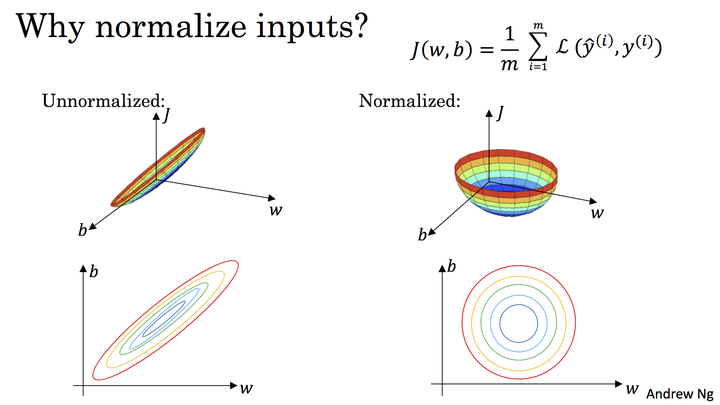
机器学习的目标无非就是不断优化损失函数,使其值最小。在上图中,

就是我们要优化的目标函数我们不难看出,标准化后可以更加容易地得出最优参数

和

以及计算出
的最小值,从而达到加速收敛的效果。

注:上图来源于 Andrew Ng 的课程讲义
提高模型的泛化能力(Be advantageous to the generalization of network)
允许更高的学习速率从而加速收敛(Batch Normalization enables higher learning rates)
其原理是利用正则化减少内部相关变量分布的偏移(Reducing Internal Covariate Shift),从而提高了算法的鲁棒性。

Batch Normalization 由两部分组成,第一部分是缩放与平移(scale and shift),第二部分是训练缩放尺度和平移的参数(train a BN Network),算法步骤如下:

接下来训练 BN 层参数

和

,限于篇幅的原因按下不表,有兴趣的读者可以拜读这篇论文。
正则化一般具有如下形式:

其中,第 1 项是经验风险,第 2 项是正则项,

为调整两者之间关系的系数。第 1 项的经验风险较小的模型可能较复杂(有多个非零参数),这时第 2 项的模型复杂度会较大。常见的有正则项有 L1 正则 和 L2 正则 ,其中 L2 正则 的控制过拟合的效果比 L1 正则 的好。正则化的作用是选择经验风险与模型复杂度同时较小的模型。

常见的有正则项有 L1 正则 和 L2 正则 以及 Dropout ,其中 L2 正则 的控制过拟合的效果比 L1 正则 的好。
为什么叫 L1 正则,有 L1、L2 正则 那么有没有 L3、L4 之类的呢?首先我们补一补课,

正则的 L 是指
范数,其定义为:

范数:

(非零元素的个数)

范数:

(每个元素绝对值之和)

范数:

(欧氏距离)
范数:

在机器学习中,若使用了

作为正则项,我们则说该机器学习任务引入了
正则项。
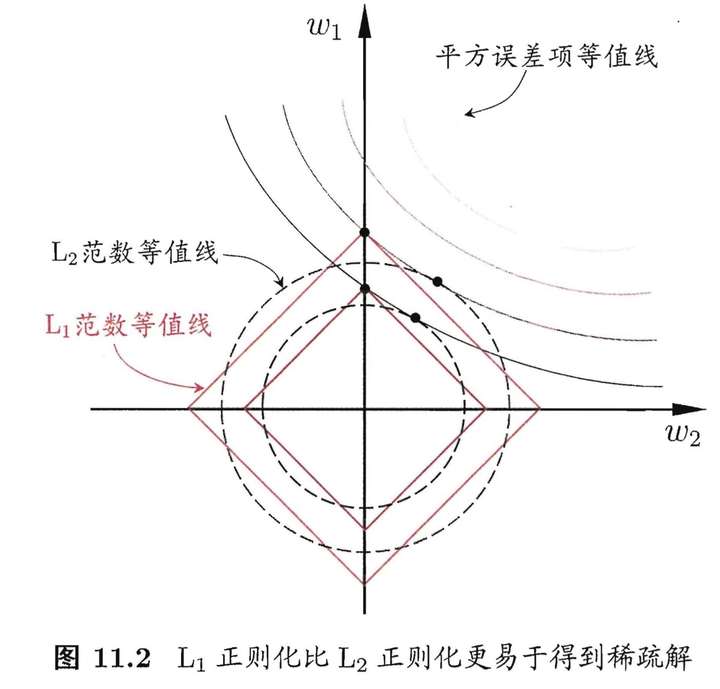
上图来自周志华老师的《机器学习》插图
凸函数,不是处处可微分
得到的是稀疏解(最优解常出现在顶点上,且顶点上的 w 只有很少的元素是非零的)

凸函数,处处可微分
易于优化
0x01 归一化 Normalization
归一化一般是将数据映射到指定的范围,用于去除不同维度数据的量纲以及量纲单位。常见的映射范围有 [0, 1] 和 [-1, 1] ,最常见的归一化方法就是 Min-Max 归一化:Min-Max 归一化
举个例子,我们判断一个人的身体状况是否健康,那么我们会采集人体的很多指标,比如说:身高、体重、红细胞数量、白细胞数量等。一个人身高 180cm,体重 70kg,白细胞计数
,etc.衡量两个人的状况时,白细胞计数就会起到主导作用从而遮盖住其他的特征,归一化后就不会有这样的问题。
0x02 标准化 Normalization
在这里我们需要强调一下英文翻译的问题,在 Udacity 字幕组中对此进行了探讨:归一化和标准化的英文翻译是一致的,但是根据其用途(或公式)的不同去理解(或翻译)下面我们将探讨最常见的标准化方法: Z-Score 标准化。Z-Score 标准化
其中
是样本数据的均值(mean),
是样本数据的标准差(std)。
上图则是一个散点序列的标准化过程:原图->减去均值->除以标准差。显而易见,变成了一个均值为 0 ,方差为 1 的分布,下图通过 Cost 函数让我们更好的理解标准化的作用。
机器学习的目标无非就是不断优化损失函数,使其值最小。在上图中,
就是我们要优化的目标函数我们不难看出,标准化后可以更加容易地得出最优参数
和
以及计算出
的最小值,从而达到加速收敛的效果。
注:上图来源于 Andrew Ng 的课程讲义
Batch Normalization
在机器学习中,最常用标准化的地方莫过于神经网络的 BN 层(Batch Normalization),因此我们简单的谈谈 BN 层的原理和作用,想要更深入的了解可以查看论文。我们知道数据预处理做标准化可以加速收敛,同理,在神经网络使用标准化也可以加速收敛,而且还有如下好处:具有正则化的效果(Batch Normalization reglarizes the model)提高模型的泛化能力(Be advantageous to the generalization of network)
允许更高的学习速率从而加速收敛(Batch Normalization enables higher learning rates)
其原理是利用正则化减少内部相关变量分布的偏移(Reducing Internal Covariate Shift),从而提高了算法的鲁棒性。
Batch Normalization 由两部分组成,第一部分是缩放与平移(scale and shift),第二部分是训练缩放尺度和平移的参数(train a BN Network),算法步骤如下:
接下来训练 BN 层参数
和
,限于篇幅的原因按下不表,有兴趣的读者可以拜读这篇论文。
0x03 正则化 Regularization
正则化主要用于避免过拟合的产生和减少网络误差。正则化一般具有如下形式:
其中,第 1 项是经验风险,第 2 项是正则项,
为调整两者之间关系的系数。第 1 项的经验风险较小的模型可能较复杂(有多个非零参数),这时第 2 项的模型复杂度会较大。常见的有正则项有 L1 正则 和 L2 正则 ,其中 L2 正则 的控制过拟合的效果比 L1 正则 的好。正则化的作用是选择经验风险与模型复杂度同时较小的模型。
常见的有正则项有 L1 正则 和 L2 正则 以及 Dropout ,其中 L2 正则 的控制过拟合的效果比 L1 正则 的好。
范数
为什么叫 L1 正则,有 L1、L2 正则 那么有没有 L3、L4 之类的呢?首先我们补一补课, 正则的 L 是指
范数,其定义为:
范数:
(非零元素的个数)
范数:
(每个元素绝对值之和)
范数:
(欧氏距离)
范数:
在机器学习中,若使用了
作为正则项,我们则说该机器学习任务引入了
正则项。
上图来自周志华老师的《机器学习》插图
L1 正则 Lasso regularizer
凸函数,不是处处可微分
得到的是稀疏解(最优解常出现在顶点上,且顶点上的 w 只有很少的元素是非零的)
L2 正则 Ridge Regularizer / Weight Decay
凸函数,处处可微分
易于优化
Dropout
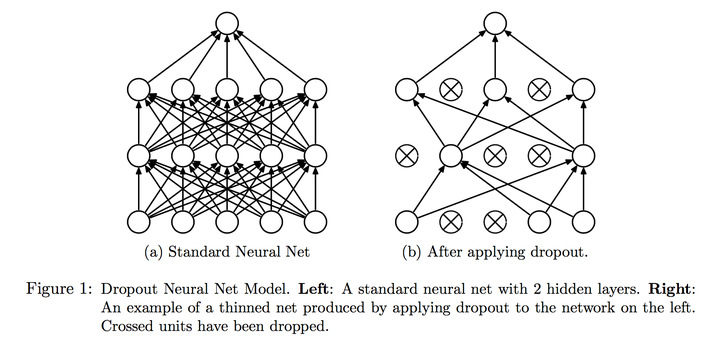
Dropout 主要用于神经网络,其原理是使神经网络中的某些神经元随机失活,让模型不过度依赖某一神经元,达到增强模型鲁棒性以及控制过拟合的效果。除此之外,Dropout 还有多模型投票等功能,若有兴趣可以拜读这篇论文。

相关文章推荐
- 特征的转换_03-标准化,归一化,正则化
- 归一化 标准化 正则化
- 使用sklearn进行数据预处理 —— 标准化/归一化/正则化
- 使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- [Scikit-Learn] - 数据预处理 - 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- [Scikit-Learn] - 数据预处理 - 归一化/标准化/正则化
- 正则化,归一化和标准化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 数据预处理 - 归一化/标准化/正则化
- [置顶] python归一化、标准化、正则化
- 【机器学习】【数据预处理】数据的规范化,归一化,标准化,正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化