NLP中Sequence-to-Sequence model代码详解
2018-03-19 17:19
363 查看
在NLP领域,sequence to sequence模型有很多应用,比如机器翻译、自动应答机器人等。在看懂了相关的论文后,我开始研读TensorFlow提供的源代码,刚开始看时感觉非常晦涩,现在基本都弄懂了,我在这里主要介绍Sequence-to-Sequence Models用到的理论,然后对源代码进行详解。
sequence-to-sequence模型
在NLP中最为常见的模型是language model,它的研究对象是单一序列,而本文中的sequence to sequence模型同时研究两个序列。经典的sequence-to-sequence模型由两个RNN网络构成,一个被称为“encoder”,另一个则称为“decoder”,前者负责把variable-length序列编码成fixed-length向量表示,后者负责把fixed_length向量表示解码成variable-length输出,它的基本网络结构如下,
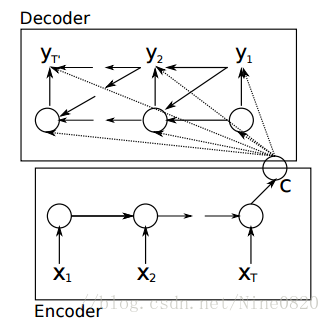
其中每一个小圆圈代表一个cell,比如GRUcell、LSTMcell、multi-layer-GRUcell、multi-layer-GRUcell等。这里比较直观的解释就是,encoder的最终隐状态c包含了输入序列的所有信息,因此可以使用c进行解码输出。尽管“encoder”或者“decoder”内部存在权值共享,但encoder和decoder之间一般具有不同的一套参数。在训练sequence-to-sequence模型时,类似于有监督学习模型,最大化目标函数。
Github源代码解析
整个工程主要使用了四个源文件,seq2seq.py文件是一个用于创建sequence-to-sequence模型的库,data_utils.py中包含了对原始数据进行预处理的一些操作,seq2seq_model.py用于定义machine translation模型,translate.py用于训练和测试所定义的翻译模型。因为源代码较长,下面仅针对每个.py文件,对理解起来可能有困难的代码块进行解析。
seq2seq.py文件
这个文件中比较重要的两个库函数basic_rnn_seq2seq和embedding_attention_seq2seq已经在上一部分作了介绍,这里主要介绍其它的几个功能函数。
(1)sequence_loss_by_example(logits, targets, weights)
这个函数用于计算所有examples的加权交叉熵损失,logits参数是一个2D Tensor构成的列表对象,每一个2D Tensor的尺寸为[batch_size x num_decoder_symbols],函数的返回值是一个1D float类型的Tensor,尺寸为batch_size,其中的每一个元素代表当前输入序列example的交叉熵。另外,还有一个与之类似的函数sequence_loss,它对sequence_loss_by_example函数返回的结果进行了一个tf.reduce_sum运算,因此返回的是一个标称型float Tensor。
(2)model_with_buckets(encoder_inputs, decoder_inputs, targets, weights, buckets, seq2seq)
这个函数创建了一个支持bucketing策略的sequence-to-sequence模型,它仍然属于Graph的定义阶段。具体来说,这段程序定义了length(buckets)个graph,每个graph的输入为总模型的输入“占位符”的一部分,但这些graphs共享模型参数,函数的返回值outputs和losses均为列表对象,尺寸为[length(buckets)],其中每一个元素为当前graph的bucket_outputs和bucket_loss。
data_utils.py文件
(1)create_vocabulary(vocabulary_path, data_path, max_vocabulary_size)
这个函数用于根据输入文件创建词库,在这里data_path参数表示输入源文件的路径,vocabulary_path表示输出文件的路径,vocabulary_path文件中每一行代表一个单词,且按照其在data_path中的出现频数从大到小排列,比如第1行为r”_EOS”,第2行为r”_UNK”,第3行为r’I’,第4行为r”have”,第5行为r’dream’,……
(2)def data_to_token_ids(data_path, target_path, vocabulary_path)
这个函数用于把字符串为元素的数据文件转换为以int索引为元素的文件,在这里data_path表示输入源数据文件的路径,target_path表示输出索引数据文件的路径,vocabulary_path表示词库文件的路径。整个函数把数据文件中的每一行转换为在词库文件中的索引值,两单词的索引值之间用空格隔开,比如返回值文件的第一行为’1 123 235’,第二行为‘3 1 234 554 879 355’,……
seq2seq_model.py文件
机器学习模型的定义过程,一般包括输入变量定义、输入信息的forward propagation和误差信息的backward propagation三个部分,这三个部分在这个程序文件中都得到了很好的体现,下面我们结合代码分别进行介绍。
(1)输入变量的定义
与前面的几个样例不同,这里输入数据采用的是最常见的“占位符”格式,以self.encoder_inputs为例,这个列表对象中的每一个元素表示一个占位符,其名字分别为encoder0, encoder1,…,encoder39,encoder{i}的几何意义是编码器在时刻i的输入。这里需要注意的是,在训练阶段执行sess.run()函数时会再次用到这些变量名字。另外,跟language model类似,targets变量是decoder inputs平移一个单位的结果,读者可以结合当前模型的损失函数进行理解。
(2)输入信息的forward propagation
从代码中可以看到,输入信息的forward popagation分成了两种情况,这是因为整个sequence to sequence模型在训练阶段和测试阶段信息的流向是不一样的,这一点可以从seq2seqf函数的do_decode参数值体现出来,而do_decoder取值对应的就是tf.nn.seq2seq.embedding_attention_seq2seq函数中的feed_previous参数,forward_only为True也即feed_previous参数为True时进行模型测试,为False时进行模型训练。这里还应用到了一个很重要的函数tf.nn.seq2seq.model_with_buckets,我么在seq2seq文件中对其进行讲解。
(3)误差信息的backward propagation
这一段代码主要用于计算损失函数关于参数的梯度。因为只有训练阶段才需要计算梯度和参数更新,所以这里有个if判断语句。并且,由于当前定义除了length(buckets)个graph,故返回值self.updates是一个列表对象,尺寸为length(buckets),列表中第i个元素表示graph{i}的梯度更新操作。
模型已经定义完成了,这里便开始进行模型训练了。上面的两个for循环用于为之前定义的输入占位符赋予具体的数值,这些具体的数值源自于get_batch函数的返回值。当session.run函数开始执行时,当前session会对第bucket_id个graph进行参数更新操作。
sequence-to-sequence模型
在NLP中最为常见的模型是language model,它的研究对象是单一序列,而本文中的sequence to sequence模型同时研究两个序列。经典的sequence-to-sequence模型由两个RNN网络构成,一个被称为“encoder”,另一个则称为“decoder”,前者负责把variable-length序列编码成fixed-length向量表示,后者负责把fixed_length向量表示解码成variable-length输出,它的基本网络结构如下,
其中每一个小圆圈代表一个cell,比如GRUcell、LSTMcell、multi-layer-GRUcell、multi-layer-GRUcell等。这里比较直观的解释就是,encoder的最终隐状态c包含了输入序列的所有信息,因此可以使用c进行解码输出。尽管“encoder”或者“decoder”内部存在权值共享,但encoder和decoder之间一般具有不同的一套参数。在训练sequence-to-sequence模型时,类似于有监督学习模型,最大化目标函数。
Github源代码解析
整个工程主要使用了四个源文件,seq2seq.py文件是一个用于创建sequence-to-sequence模型的库,data_utils.py中包含了对原始数据进行预处理的一些操作,seq2seq_model.py用于定义machine translation模型,translate.py用于训练和测试所定义的翻译模型。因为源代码较长,下面仅针对每个.py文件,对理解起来可能有困难的代码块进行解析。
seq2seq.py文件
这个文件中比较重要的两个库函数basic_rnn_seq2seq和embedding_attention_seq2seq已经在上一部分作了介绍,这里主要介绍其它的几个功能函数。
(1)sequence_loss_by_example(logits, targets, weights)
这个函数用于计算所有examples的加权交叉熵损失,logits参数是一个2D Tensor构成的列表对象,每一个2D Tensor的尺寸为[batch_size x num_decoder_symbols],函数的返回值是一个1D float类型的Tensor,尺寸为batch_size,其中的每一个元素代表当前输入序列example的交叉熵。另外,还有一个与之类似的函数sequence_loss,它对sequence_loss_by_example函数返回的结果进行了一个tf.reduce_sum运算,因此返回的是一个标称型float Tensor。
(2)model_with_buckets(encoder_inputs, decoder_inputs, targets, weights, buckets, seq2seq)
for j, bucket in enumerate(buckets): with variable_scope.variable_scope(variable_scope.get_variable_scope(), reuse=True if j > 0 else None): # 函数seq2seq有两个返回值,因为tf.nn.seq2seq.embedding_attention_seq2seq函数有两个返回值 bucket_outputs, _ = seq2seq(encoder_inputs[:bucket[0]], decoder_inputs[:bucket[1]]) outputs.append(bucket_outputs) if per_example_loss: losses.append(sequence_loss_by_example( outputs[-1], targets[:bucket[1]], weights[:bucket[1]], softmax_loss_function=softmax_loss_function)) else: losses.append(sequence_loss( outputs[-1], targets[:bucket[1]], weights[:bucket[1]], softmax_loss_function=softmax_loss_function))
这个函数创建了一个支持bucketing策略的sequence-to-sequence模型,它仍然属于Graph的定义阶段。具体来说,这段程序定义了length(buckets)个graph,每个graph的输入为总模型的输入“占位符”的一部分,但这些graphs共享模型参数,函数的返回值outputs和losses均为列表对象,尺寸为[length(buckets)],其中每一个元素为当前graph的bucket_outputs和bucket_loss。
data_utils.py文件
(1)create_vocabulary(vocabulary_path, data_path, max_vocabulary_size)
这个函数用于根据输入文件创建词库,在这里data_path参数表示输入源文件的路径,vocabulary_path表示输出文件的路径,vocabulary_path文件中每一行代表一个单词,且按照其在data_path中的出现频数从大到小排列,比如第1行为r”_EOS”,第2行为r”_UNK”,第3行为r’I’,第4行为r”have”,第5行为r’dream’,……
(2)def data_to_token_ids(data_path, target_path, vocabulary_path)
这个函数用于把字符串为元素的数据文件转换为以int索引为元素的文件,在这里data_path表示输入源数据文件的路径,target_path表示输出索引数据文件的路径,vocabulary_path表示词库文件的路径。整个函数把数据文件中的每一行转换为在词库文件中的索引值,两单词的索引值之间用空格隔开,比如返回值文件的第一行为’1 123 235’,第二行为‘3 1 234 554 879 355’,……
seq2seq_model.py文件
机器学习模型的定义过程,一般包括输入变量定义、输入信息的forward propagation和误差信息的backward propagation三个部分,这三个部分在这个程序文件中都得到了很好的体现,下面我们结合代码分别进行介绍。
(1)输入变量的定义
# Feeds for inputs.
self.encoder_inputs = []
self.decoder_inputs = []
self.target_weights = []
for i in xrange(buckets[-1][0]): # Last bucket is the biggest one.
self.encoder_inputs.append(tf.placeholder(tf.int32, shape=[None],
name="encoder{0}".format(i)))
for i in xrange(buckets[-1][1] + 1):
self.decoder_inputs.append(tf.placeholder(tf.int32, shape=[None],
name="decoder{0}".format(i)))
self.target_weights.append(tf.placeholder(dtype, shape=[None],
name="weight{0}".format(i)))
# Our targets are decoder inputs shifted by one.
targets = [self.decoder_inputs[i + 1]
for i in xrange(len(self.decoder_inputs) - 1)]与前面的几个样例不同,这里输入数据采用的是最常见的“占位符”格式,以self.encoder_inputs为例,这个列表对象中的每一个元素表示一个占位符,其名字分别为encoder0, encoder1,…,encoder39,encoder{i}的几何意义是编码器在时刻i的输入。这里需要注意的是,在训练阶段执行sess.run()函数时会再次用到这些变量名字。另外,跟language model类似,targets变量是decoder inputs平移一个单位的结果,读者可以结合当前模型的损失函数进行理解。
(2)输入信息的forward propagation
# Training outputs and losses. if forward_only: # 返回每一个bucket子图模型对应的output和loss self.outputs, self.losses = tf.nn.seq2seq.model_with_buckets( self.encoder_inputs, self.decoder_inputs, targets, b941 self.target_weights, buckets, lambda x, y: seq2seq_f(x, y, True), softmax_loss_function=softmax_loss_function) # If we use output projection, we need to project outputs for decoding. if output_projection is not None: for b in xrange(len(buckets)): self.outputs[b] = [ tf.matmul(output, output_projection[0]) + output_projection[1] for output in self.outputs[b] ] else: self.outputs, self.losses = tf.nn.seq2seq.model_with_buckets( self.encoder_inputs, self.decoder_inputs, targets, self.target_weights, buckets, lambda x, y: seq2seq_f(x, y, False), softmax_loss_function=softmax_loss_function)
从代码中可以看到,输入信息的forward popagation分成了两种情况,这是因为整个sequence to sequence模型在训练阶段和测试阶段信息的流向是不一样的,这一点可以从seq2seqf函数的do_decode参数值体现出来,而do_decoder取值对应的就是tf.nn.seq2seq.embedding_attention_seq2seq函数中的feed_previous参数,forward_only为True也即feed_previous参数为True时进行模型测试,为False时进行模型训练。这里还应用到了一个很重要的函数tf.nn.seq2seq.model_with_buckets,我么在seq2seq文件中对其进行讲解。
(3)误差信息的backward propagation
# 返回所有bucket子graph的梯度和SGD更新操作,这些子graph共享输入占位符变量encoder_inputs,区别在于, # 对于每一个bucket子图,其输入为该子图对应的长度。 params = tf.trainable_variables() if not forward_only: self.gradient_norms = [] self.updates = [] opt = tf.train.GradientDescentOptimizer(self.learning_rate) for b in xrange(len(buckets)): gradients = tf.gradients(self.losses[b], params) clipped_gradients, norm = tf.clip_by_global_norm(gradients, max_gradient_norm) self.gradient_norms.append(norm) self.updates.append(opt.apply_gradients( zip(clipped_gradients, params), global_step=self.global_step))
这一段代码主要用于计算损失函数关于参数的梯度。因为只有训练阶段才需要计算梯度和参数更新,所以这里有个if判断语句。并且,由于当前定义除了length(buckets)个graph,故返回值self.updates是一个列表对象,尺寸为length(buckets),列表中第i个元素表示graph{i}的梯度更新操作。
# Input feed: encoder inputs, decoder inputs, target_weights, as provided.
input_feed = {}
for l in xrange(encoder_size):
input_feed[self.encoder_inputs[l].name] = encoder_inputs[l]
for l in xrange(decoder_size):
input_feed[self.decoder_inputs[l].name] = decoder_inputs[l]
input_feed[self.target_weights[l].name] = target_weights[l]
......
if not forward_only:
output_feed = [self.updates[bucket_id], # Update Op that does SGD.
self.gradient_norms[bucket_id], # Gradient norm.
self.losses[bucket_id]] # Loss for this batch.
else:
output_feed = [self.losses[bucket_id]] # Loss for this batch.
for l in xrange(decoder_size): # Output logits.
output_feed.append(self.outputs[bucket_id][l])
outputs = session.run(output_feed, input_feed)模型已经定义完成了,这里便开始进行模型训练了。上面的两个for循环用于为之前定义的输入占位符赋予具体的数值,这些具体的数值源自于get_batch函数的返回值。当session.run函数开始执行时,当前session会对第bucket_id个graph进行参数更新操作。

相关文章推荐
- Python - 序列(sequence) 详解 及 代码
- Python - 序列(sequence) 详解 及 代码
- 关于c#代码Convert.ToChar(null);出现异常,而object obj = null; Convert.ToChar(obj);//返回'\0'空字符问题详解
- Linux任务切换代码(switch_to)详解(转)
- Linux任务切换代码(switch_to)详解
- 主机下COBOL程序的编译? 下面是DB2访问程序的JCL编译代码,不太理解,求详解。
- 基于简单seq to seq 的聊天机器人+代码实现 (tensorfow 1.1版本)
- C语言 文件的打开与关闭详解及示例代码
- HTTP响应代码中文详解
- asp.net/c#代码实现excel to mssql数据导入
- PullToRefresh代码案例
- hdoj2050代码及详解
- Java:集合框架二(LinkerList)详解和代码示例
- 对django中render()与render_to_response()的区别详解
- Informix 动态服务器错误代码中文详解(二)
- openstack swift各类 HTTP 返回状态代码详解
- android Json解析详解(详细代码)
- 后台验证码实现,附代码详解
- php调用C代码的方法详解和zend_parse_parameters函数详解
- 代码管理Git-常用命令详解