机器学习【三】集成算法
2018-03-16 08:55
267 查看
Ensemble learning:
目的:让单个弱分类器分类效果不行,一起组合成强分类器
bagging 并行抽样训练 训练多个分类器,求出预测值,如果是分类任务可以求众数,如果是回归任务可以求平均值(随机森林是其 典型代表)
boosting 串行训练,从弱学习器开始加强,通过加权进行训练。
stacking 聚合多个分类或回归模型
bagging模型:
典型代表:随机森林 随机:取样随机,特征随机 森林:多个决策树
优势:可以处理高维度的数据,并且不用做特征选择
训练完之后,可以给出哪些特征很重要
boosting模型:
典型代表:adaboost,Xgboost
adaboost:
将前面的全部数据先训练一个分类器,算出错误率,调节权重,给错分的赋予更大权重,给分类正确赋予小权重,根据新数据,继续训练新的分类器,最后作出综合评价。
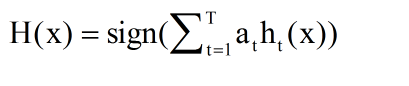
其中,at为每个弱分类器的权重,ht为弱分类器。
随机森林代码(基于sklearn库):# -*- coding: utf-8 -*-
#load the library with iris dataset
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
import numpy as np
iris=load_iris()
df=pd.DataFrame(iris.data,columns=iris.feature_names)
#view top five data
#print(df.head())
df['specials']=pd.Categorical.from_codes(iris.target,iris.target_names)######create feature name
help(pd.Categorical.from_codes)
#data will be sperated train and test
df['is_train'] = np.random.uniform(0,1,len(df)) <= 0.75
train,test=df[df['is_train']==True],df[df['is_train']==False]
print('Number of observation in the training data: ',len(train))
print('Number of observation in the test data: ',len(test))
features = df.columns[:4]
#transferred number
y=pd.factorize(train['specials'])[0]
#Create a random forest Classfier
clf=RandomForestClassifier(n_estimators=20,criterion='gini',max_features='auto',min_samples_split=2)
clfba=BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators=20)
clfde=DecisionTreeClassifier(min_samples_split=2)
clf.fit(train[features],y)
clfba.fit(train[features],y)
clfde.fit(train[features],y)
#print(clf.predict(test[features]))
#print(clfba.predict(test[features]))
#print(clfde.predict(test[features]))
#view top five data
preds=iris.target_names[clf.predict(test[features])]
predsba=iris.target_names[clfba.predict(test[features])]
predsde=iris.target_names[clfde.predict(test[features])]
#print(preds[0:5])
#create a confusion matrix
print(pd.crosstab(test['specials'],preds,rownames=['Actual Species'],colnames=['Predicted Species']))
print(pd.crosstab(test['specials'],predsba,rownames=['Actual Species'],colnames=['Predicted Species']))
print(pd.crosstab(test['specials'],predsde,rownames=['Actual Species'],colnames=['Predicted Species']))
#estimate feature importance
print(list(zip(train[features],clf.feature_importances_)))其中:
(1)df['specials']=pd.Categorical.from_codes(iris.target,iris.target_names)是将燕尾花中为
当然这个代码未考虑交叉验证。
adaboost算法:




代码:import numpy as np
import matplotlib
import matplotlib.pyplot as plt
def base_model(data,Dt):
m = data.shape[0]
pred = []
pos = None
mark = None
min_err = np.inf
for j in range(m):
pred_temp = [];
sub_mark = None
lsum = np.sum(data[:j,1])
rsum = np.sum(data[j:,1])
if lsum<rsum:
sub_mark = -1
pred_temp.extend([-1]*(j))
pred_temp.extend([1]*(m-j))
else:
sub_mark = 1
pred_temp.extend([1]*(j))
pred_temp.extend([-1]*(m-j))
err = np.sum(1*(data[:,1] != pred_temp)*Dt) ###
if err < min_err:
min_err = err
pos = (data[:,0][j-1] + data[:,0][j]) / 2
mark = sub_mark
pred = pred_temp[:]
model = [pos,mark,min_err]
return model,pred
def adaboost(data):
models = []
m = data.shape[0]
D = np.zeros(m) +1.0/m
T = 3
y = data[:, 1]
for t in range(T):
Dt = D[:]
model,y_ = base_model(data,Dt)
print(model)
errt = model[-1]
alpha = 0.5 + np.log((1-errt)/errt)
Zt = np.sum([Dt[i] * np.exp(-alpha * y[i] * y_[i]) for i in range(m)])
D = np.array([Dt[i] * np.exp(-alpha * y[i] * y_[i]) for i in range(m)]) / Zt
models.append([model , alpha])
return models
def adaboost_prediction(models, X):
pred_ = []
for x in X:
result = 0
for base in models:
alpha_ = base[1]
if x[0] > base[0][0]:
result -= base[0][1] * alpha_
else:
result += base[0][1] * alpha_
pred_.append(np.sign(result))
return pred_
if __name__ == '__main__':
data = np.array([[0,1],[1,1],[2,1],[3,-1],[4,-1],[5,-1],[6,1],[7,1],[8,1],[9,-1]],dtype = np.float32)
plt.scatter(data[:,0],data[:,1],c=data[:,1],cmap=plt.cm.Paired)
plt.xlabel('x')
plt.ylabel('y')
plt.show()
models = adaboost(data)
X=data
Y=data[:,1]
Y_=adaboost_prediction(models, X)
acc=np.sum(1*(Y==Y_)) / float(len(X))
print(acc)
结果:

代码分析:
本代码就是首先定义了 基础模型
然后用adaboost进行样本权值修正 提升基础模型
最后预测 作出了综合评价 综合评价是在训练当中把每个基础模型的系数算出来和预测结果相乘求和之后用sign函数做了评价
对于本代码分类的错误率计算我总感觉有点问题 不知道它这样的意义何在 不过adaboost的思想是知道了,后面会在sklearn中实现下adaboost
参考: adaboost:http://www.xtecher.com/Xfeature/view?aid=8109
随机森林:全球人工智能课堂上老师讲的代码
目的:让单个弱分类器分类效果不行,一起组合成强分类器
bagging 并行抽样训练 训练多个分类器,求出预测值,如果是分类任务可以求众数,如果是回归任务可以求平均值(随机森林是其 典型代表)
boosting 串行训练,从弱学习器开始加强,通过加权进行训练。
stacking 聚合多个分类或回归模型
bagging模型:
典型代表:随机森林 随机:取样随机,特征随机 森林:多个决策树
优势:可以处理高维度的数据,并且不用做特征选择
训练完之后,可以给出哪些特征很重要
boosting模型:
典型代表:adaboost,Xgboost
adaboost:
将前面的全部数据先训练一个分类器,算出错误率,调节权重,给错分的赋予更大权重,给分类正确赋予小权重,根据新数据,继续训练新的分类器,最后作出综合评价。
其中,at为每个弱分类器的权重,ht为弱分类器。
随机森林代码(基于sklearn库):# -*- coding: utf-8 -*-
#load the library with iris dataset
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
import numpy as np
iris=load_iris()
df=pd.DataFrame(iris.data,columns=iris.feature_names)
#view top five data
#print(df.head())
df['specials']=pd.Categorical.from_codes(iris.target,iris.target_names)######create feature name
help(pd.Categorical.from_codes)
#data will be sperated train and test
df['is_train'] = np.random.uniform(0,1,len(df)) <= 0.75
train,test=df[df['is_train']==True],df[df['is_train']==False]
print('Number of observation in the training data: ',len(train))
print('Number of observation in the test data: ',len(test))
features = df.columns[:4]
#transferred number
y=pd.factorize(train['specials'])[0]
#Create a random forest Classfier
clf=RandomForestClassifier(n_estimators=20,criterion='gini',max_features='auto',min_samples_split=2)
clfba=BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators=20)
clfde=DecisionTreeClassifier(min_samples_split=2)
clf.fit(train[features],y)
clfba.fit(train[features],y)
clfde.fit(train[features],y)
#print(clf.predict(test[features]))
#print(clfba.predict(test[features]))
#print(clfde.predict(test[features]))
#view top five data
preds=iris.target_names[clf.predict(test[features])]
predsba=iris.target_names[clfba.predict(test[features])]
predsde=iris.target_names[clfde.predict(test[features])]
#print(preds[0:5])
#create a confusion matrix
print(pd.crosstab(test['specials'],preds,rownames=['Actual Species'],colnames=['Predicted Species']))
print(pd.crosstab(test['specials'],predsba,rownames=['Actual Species'],colnames=['Predicted Species']))
print(pd.crosstab(test['specials'],predsde,rownames=['Actual Species'],colnames=['Predicted Species']))
#estimate feature importance
print(list(zip(train[features],clf.feature_importances_)))其中:
(1)df['specials']=pd.Categorical.from_codes(iris.target,iris.target_names)是将燕尾花中为
iris.target=[0 0 0...1... 4000 2...]数字的转化为对应的字符串名(2)y=pd.factorize(train['specials'])[0]是将训练集中的字符串转换为数字,重复的用相同的数字表示。
当然这个代码未考虑交叉验证。
adaboost算法:
代码:import numpy as np
import matplotlib
import matplotlib.pyplot as plt
def base_model(data,Dt):
m = data.shape[0]
pred = []
pos = None
mark = None
min_err = np.inf
for j in range(m):
pred_temp = [];
sub_mark = None
lsum = np.sum(data[:j,1])
rsum = np.sum(data[j:,1])
if lsum<rsum:
sub_mark = -1
pred_temp.extend([-1]*(j))
pred_temp.extend([1]*(m-j))
else:
sub_mark = 1
pred_temp.extend([1]*(j))
pred_temp.extend([-1]*(m-j))
err = np.sum(1*(data[:,1] != pred_temp)*Dt) ###
if err < min_err:
min_err = err
pos = (data[:,0][j-1] + data[:,0][j]) / 2
mark = sub_mark
pred = pred_temp[:]
model = [pos,mark,min_err]
return model,pred
def adaboost(data):
models = []
m = data.shape[0]
D = np.zeros(m) +1.0/m
T = 3
y = data[:, 1]
for t in range(T):
Dt = D[:]
model,y_ = base_model(data,Dt)
print(model)
errt = model[-1]
alpha = 0.5 + np.log((1-errt)/errt)
Zt = np.sum([Dt[i] * np.exp(-alpha * y[i] * y_[i]) for i in range(m)])
D = np.array([Dt[i] * np.exp(-alpha * y[i] * y_[i]) for i in range(m)]) / Zt
models.append([model , alpha])
return models
def adaboost_prediction(models, X):
pred_ = []
for x in X:
result = 0
for base in models:
alpha_ = base[1]
if x[0] > base[0][0]:
result -= base[0][1] * alpha_
else:
result += base[0][1] * alpha_
pred_.append(np.sign(result))
return pred_
if __name__ == '__main__':
data = np.array([[0,1],[1,1],[2,1],[3,-1],[4,-1],[5,-1],[6,1],[7,1],[8,1],[9,-1]],dtype = np.float32)
plt.scatter(data[:,0],data[:,1],c=data[:,1],cmap=plt.cm.Paired)
plt.xlabel('x')
plt.ylabel('y')
plt.show()
models = adaboost(data)
X=data
Y=data[:,1]
Y_=adaboost_prediction(models, X)
acc=np.sum(1*(Y==Y_)) / float(len(X))
print(acc)
结果:
代码分析:
本代码就是首先定义了 基础模型
然后用adaboost进行样本权值修正 提升基础模型
最后预测 作出了综合评价 综合评价是在训练当中把每个基础模型的系数算出来和预测结果相乘求和之后用sign函数做了评价
对于本代码分类的错误率计算我总感觉有点问题 不知道它这样的意义何在 不过adaboost的思想是知道了,后面会在sklearn中实现下adaboost
参考: adaboost:http://www.xtecher.com/Xfeature/view?aid=8109
随机森林:全球人工智能课堂上老师讲的代码

相关文章推荐
- 机器学习集成算法--- 朴素贝叶斯,k-近邻算法,决策树,支持向量机(SVM),Logistic回归
- 机器学习:集成算法(Ensemble Method)
- 机器学习集成算法:XGBoost思想
- 深度 | 机器学习集成算法:XGBoost思想
- 机器学习笔记(8)——集成学习之Bootstrap aggregating(Bagging)装袋算法
- 机器学习集成算法:XGBoost思想
- 机器学习_集成算法
- 机器学习-集成算法
- Python机器学习:通过scikit-learn实现集成算法
- 干货 | 机器学习集成算法:XGBoost模型构造
- 机器学习之-集成算法【人工智能工程师--AI转型必修课】
- 机器学习(5)-决策树与集成算法
- 机器学习(六):集成算法(1)Bagging
- 机器学习原理 || 集成算法: Adaboost
- 机器学习教程 之 集成学习算法: 深入刨析AdaBoost
- 机器学习:集成算法(随机森林,Adaboost)
- 机器学习-决策树与集成算法
- 机器学习 —— 决策树及其集成算法(Bagging、随机森林、Boosting)
- Python数据分析与机器学习-Xgboost集成算法
- 机器学习 —— 决策树及其集成算法(Bagging、随机森林、Boosting)