hadoop运行简单例子--单词统计
2018-03-15 22:06
330 查看
前提是已经搭建好了Hadoop平台:如下


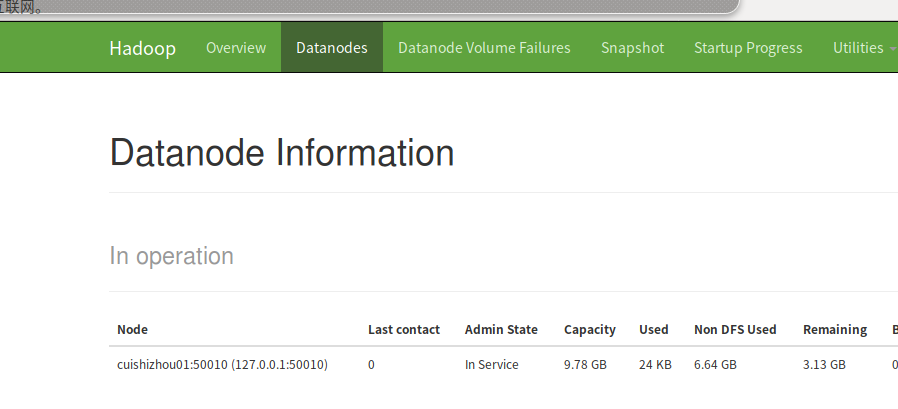
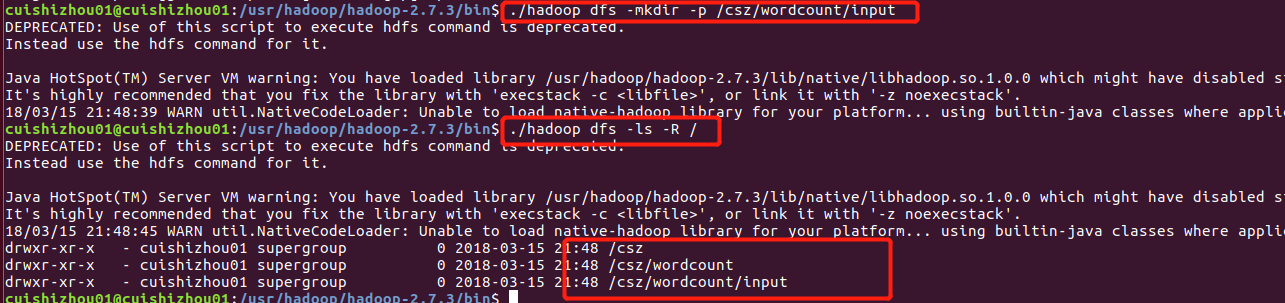
第一步:创建HDFS目录:
文件输入目录: hadoop fs -mkdir -p /csz/wordcount/input
第二步:新建数据文件:
myword
I thought a thought. But the thought I thought wasn't the thought I thought I thought. If the thought I thought I thought had been the thought I thought, I wouldn't have thought so much.

将文件遇到hdfs文件中:
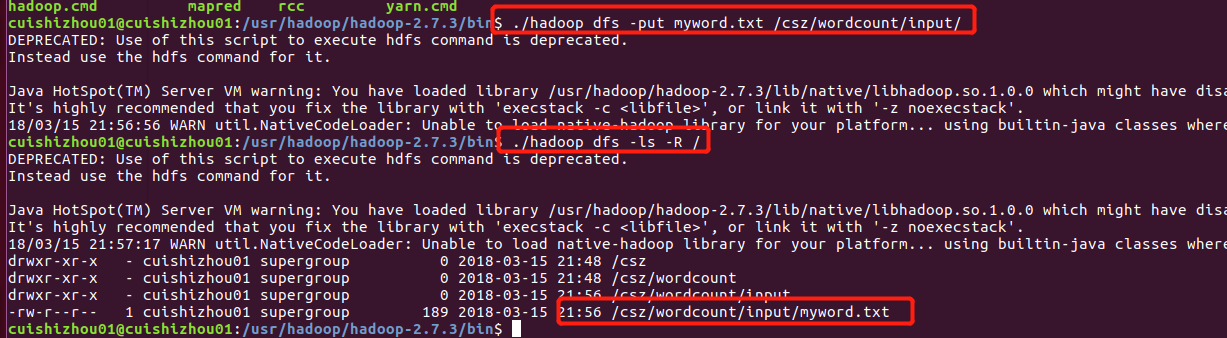
运行wordcount程序:
./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /csz/wordcount/input /csz/wordcount/output
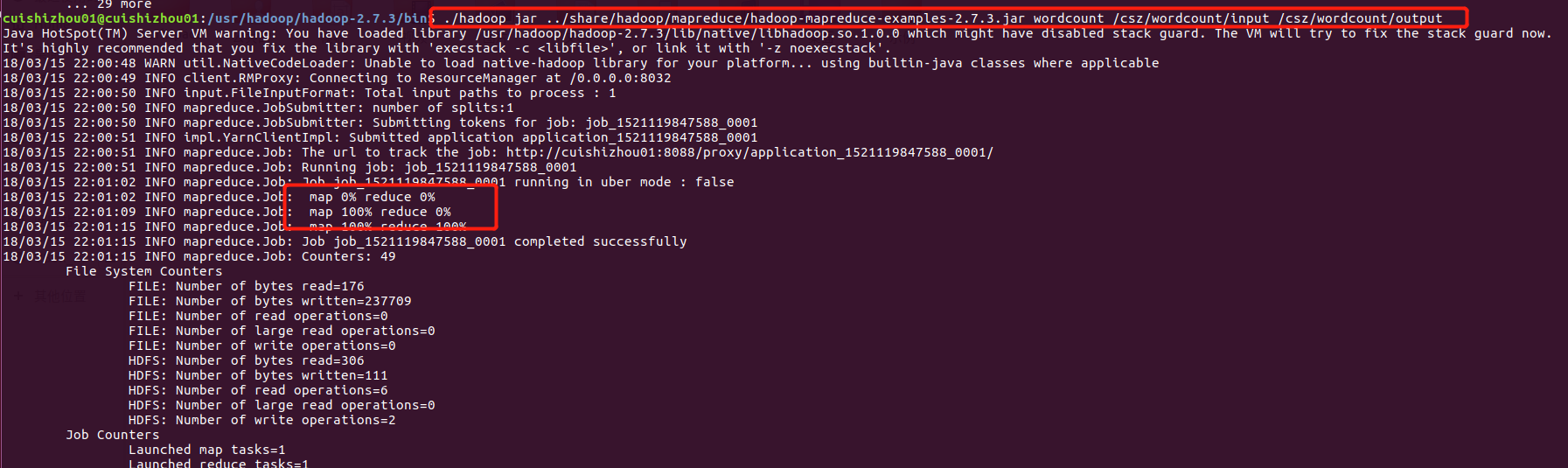
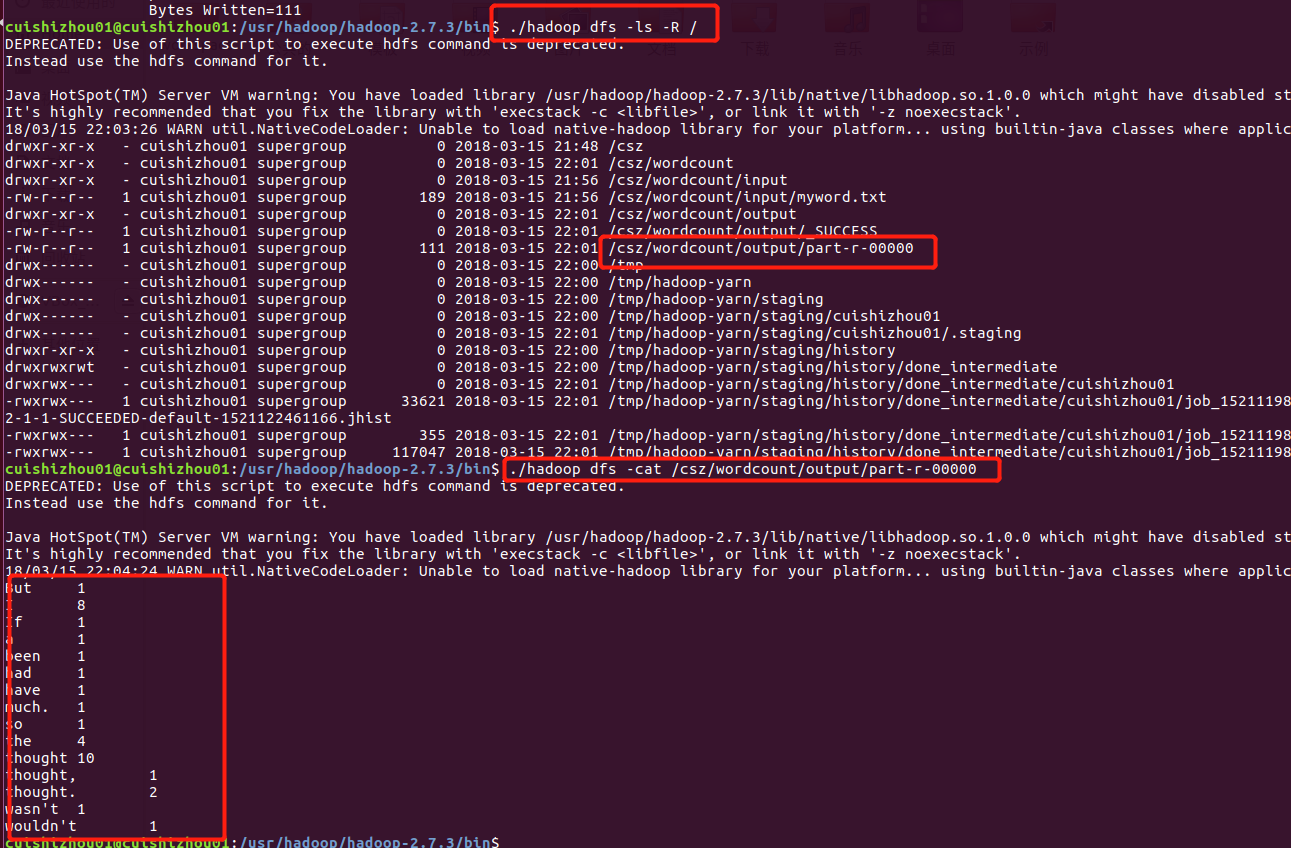
查看统计结果:
第一步:创建HDFS目录:
文件输入目录: hadoop fs -mkdir -p /csz/wordcount/input
第二步:新建数据文件:
myword
I thought a thought. But the thought I thought wasn't the thought I thought I thought. If the thought I thought I thought had been the thought I thought, I wouldn't have thought so much.
将文件遇到hdfs文件中:
运行wordcount程序:
./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /csz/wordcount/input /csz/wordcount/output
查看统计结果:

相关文章推荐
- hadoop基础----hadoop实战(三)-----hadoop运行MapReduce---对单词进行统计--经典的自带例子wordcount
- hadoop基础----hadoop实战(三)-----hadoop运行MapReduce---对单词进行统计--经典的自带例子wordcount
- 第六篇:Eclipse上运行第一个Hadoop实例 - WordCount(单词统计程序)
- Hadoop运行单词统计
- hadoop老API(基于统计单词数的例子)
- 在Linux系统设置共享文件夹、Hadoop单机/伪分布部署,运行Hadoop Wordcount单词统计实例
- 一个简单的例子理解C++ map, 运用map统计单词出现的次数
- 运行Hadoop自带的wordcount单词统计程序
- hadoop简单应用-统计文本文件单词个数
- 通过hadoop自带的demo运行单词统计
- CentOS 6 安装Hadoop 2.6 (四)运行简单例子
- Hadoop 运行 yarn jar 单词统计问题解决
- 一个简单的例子理解C++ map, 运用map统计单词出现的次数
- Hadoop 统计单词字数的例子
- 通过hadoop自带的demo运行单词统计
- 云计算学习笔记006---运行hadoop的例子程序:统计字符--wordcount例子程序
- Hadoop的简单单词统计案例
- 自定义实现InputFormat、OutputFormat、输出到多个文件目录中去、hadoop1.x api写单词计数的例子、运行时接收命令行参数,代码例子
- Netty笔记一(可以运行看到结果的简单例子)
- Hadoop2.4.1 简单的用户手机流量统计的MapReduce程序(三)