数据分析学习之路——(九)给留言数据贴情感标签,其实很简单
2018-03-15 00:00
435 查看
摘要: 对某酒店客人留言的数据进行情感分类预测
最近一直忙着找工作的事,难得抽出一点时间更新博客。前段时间仔细研究了一篇文章——运用机器学习来预测情感分类,也就是数据分析中最基本的分类模型的应用,感觉很有意思。于是自己在这篇文章基础上,完善了一下思路和代码,既有可视化的数据体验,也得到了不错的预测结果(主要靠调参数)。本文借鉴了微信公众号R语言中文社区一篇文本情感分类的文章。
说到文本分析-情感分类,我工作中做的客服应用系统也有相关的业务需求,即根据座席与客户聊天的数据来判断客户的友好程度,也可以根据客户的对话聊天来给客户贴上标签,并预测新客户标签分类。由于我在实际工作中能够接触到部分客户的生产数据,因此做过相关方面的尝试,但由于数据的保密性,本文还是以公开的某酒店留言数据为例,分析的思路都一样。
网上有很多对TF-IDF(词频-逆文档频率)的分析介绍,我就不多说了。TF,指某个词在全部词中的比例,是从词本身维度度量的;IDF,指所有句子中除以包含某个词的句子数量,再取对数得到的,是从句子维度来度量的,将这两个维度值相乘便得到我们构建特征向量的权重值。
至此,我完成了特征以及权重的构建,接下来就是用train_data训练模型并进行预测了。
这是分词后所有词的集合,关键就是要得到它,后文会很有用:


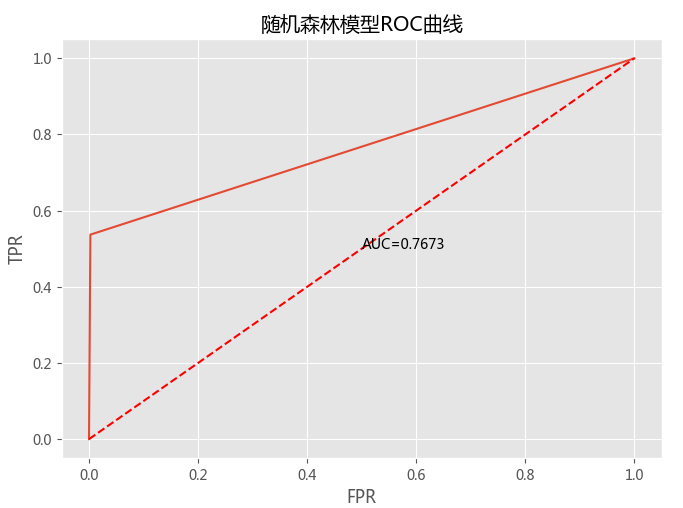
ROC曲线(网上很多介绍,此处不多讲)就是一种综合评价模型的方法,横坐标FPR表示假正类率,纵坐标TPR表示真正类率,实曲线下面的面积,表示模型预测为正类的概率,取值在(0,1)之间,一般来讲>0.5,值越大表示模型的预测效果越好。那么对随机森林模型进行评价,取值为0.7673,综合上面的准确率,说明此模型的分类效果还不错。
最近一直忙着找工作的事,难得抽出一点时间更新博客。前段时间仔细研究了一篇文章——运用机器学习来预测情感分类,也就是数据分析中最基本的分类模型的应用,感觉很有意思。于是自己在这篇文章基础上,完善了一下思路和代码,既有可视化的数据体验,也得到了不错的预测结果(主要靠调参数)。本文借鉴了微信公众号R语言中文社区一篇文本情感分类的文章。
说到文本分析-情感分类,我工作中做的客服应用系统也有相关的业务需求,即根据座席与客户聊天的数据来判断客户的友好程度,也可以根据客户的对话聊天来给客户贴上标签,并预测新客户标签分类。由于我在实际工作中能够接触到部分客户的生产数据,因此做过相关方面的尝试,但由于数据的保密性,本文还是以公开的某酒店留言数据为例,分析的思路都一样。
分析思路
所有留言数据放在一个excel文件里,分两个sheet页,第一页数据为train_data,第二页为test_data,所以在建立模型时需要把两个sheet页数据拼在一起选特征,而建立模型只需要train_data。但是在选特征之前还有一件重要的事要做。sheet页中的数据是一个长句,没办法进行分析,因此要进行分词并选择重要的词作为特征。那么前期最重要的数据处理就来了,一个是分词,一个是选特征向量。分词
分词的方法有很多,Python中有个jieba包,处理这个这个问题非常便捷。jieba分词有三种模式——全模式(jieba.cut(text, cut_all=True))、精确模式(默认)(jieba.cut(text, cut_all=False))、搜索引擎模式(jieba.cut_for_search(text)),可以选择合适的参数及方法,本项目我选择的默认的精确模式。在处理分词时,要根据不同的业务需求设置自定词(比如我所在的基金行业有基金净值这么个固定词,如果没有设自定词,就很容易被分成基金和净值两个词);另外还需要设置常见的、没有意义的通用词,这些词对选取特征和模型建立没有意义,反而还增加了程序的执行时间,称为停止词。特征向量
特征选择,也就是在分词完成后,我们需要判定哪些词出现的频率最高,并且对留言的影响效果有多大,影响效果的意义指:某个或某几个词能够指明这个留言长句更倾向于哪一类。比如:某个留言中含有"服务态度很差",那么"态度很差"这个特征会将这个留言归于负面评价的分类当中概率更大。那么怎么去定义,计算特征向量呢?本训练使用TF-IDF权重构造文档词条矩阵。网上有很多对TF-IDF(词频-逆文档频率)的分析介绍,我就不多说了。TF,指某个词在全部词中的比例,是从词本身维度度量的;IDF,指所有句子中除以包含某个词的句子数量,再取对数得到的,是从句子维度来度量的,将这两个维度值相乘便得到我们构建特征向量的权重值。
至此,我完成了特征以及权重的构建,接下来就是用train_data训练模型并进行预测了。
实现过程
数据获取
首先是数据获取,分别读取训练数据和测试数据,因为构建模型时要选特征词,因此需要将两部分数据合并。evaluation =pd.read_excel('C:/Users/Nekyo/DA/HelloBI/Hotel Evaluation.xlsx',sheetname=0) # 训练数据
evaluation1 =pd.read_excel('C:/Users/Nekyo/DA/HelloBI/Hotel Evaluation.xlsx',sheetname=1) # 测试数据
evaluation_new =pd.concat([evaluation,evaluation1]) # 将两部分数据合并,后面选特征分词
接下来就是设置自定词和停止词,以及分词。因为分词过程中产生了一些诸如"333"、"n"等无效的字符,因此通过正则,我只把中文词保留下来了。'''读取自定词,根据不同业务场景,可以定义新词添加到文件'''
with open('C:/Users/Nekyo/DA/HelloBI/all_words.txt') as words:
my_words=[i.strip() for i in words.readlines()]
for word in my_words:
jieba.add_word(word)
'''读取停止词'''
with open('C:/Users/Nekyo/DA/HelloBI/mystopwords.txt') as words:
stop_words=[i.strip() for i in words.readlines()]
'''处理数据集中的留言数据,输出只包括中文词的列表集合'''
def get_sentence(evaluation):
swords=[]
for eva in evaluation['Content']:
words=cut_word(eva)
pattern = re.compile(u"[\u4e00-\u9fa5]+")
result = re.findall(pattern, words) # 分词后,只保留中文词
swords.append(' '.join(result))
return swords
'''分词函数'''
def cut_word(sentence):
words=[i for i in jieba.cut(sentence) if i not in stop_words]
result=' '.join(words) # result是去除停止词的集合
return result这是分词后所有词的集合,关键就是要得到它,后文会很有用:
s_words=get_sentence(evaluation_new)
可视化分析
接下来对我们得到的词做一下可视化展示,云图能够非常直观地展示所有的词出现的频次,通过这些词我们能够大概地判断留言总体呈现什么趋势。'''可视化云图'''
def set_wordcloud(s_words):
all_words = []
for word in s_words:
all_words.extend(str(word).split(' '))
words_count={}
words_count=words_count.fromkeys(all_words)
for word in list(words_count.keys()):
words_count[word.decode('utf-8')]=all_words.count(word) # 云图需要字典格式: {'xx':100,'yy':200,'zz':300}
del[words_count['']] # 字典中存在空元素,删去
wordcloud=WordCloud(font_path='C:/Users/Nekyo/tools/SOFTWARE/Anaconda2/Library/lib/fonts/songti.ttf',
width=1000,height=600,background_color='white')
wordcloud.fit_words(words_count)
plt.imshow(wordcloud)
plt.axis('off')
plt.show()特征权重
如图所展示的那样,正面评价的词占了绝大多数,说明该酒店给顾客留下了非常好的印象,相对来讲,更多顾客给了表较高的评价。那么再接下来就是建立模型,测试预测效果了。'''设置TF-IDF权重''' def setModel(s_words): tfidf = TfidfVectorizer(max_features=100) # 选择频数前100的特征 dtm = tfidf.fit_transform(s_words).toarray() columns = tfidf.get_feature_names() X_data = pd.DataFrame(dtm, columns=columns) # 将矩阵转换为数据框 return X_data X=setModel(s_words) y = evaluation.Emotion # 情感标签变量 X_train,X_test,y_train,y_test = train_test_split\ (X[:3890],y,train_size = 0.8, random_state=1) # X[:3890]为前面提到的train_data
分析模型
最后就是用训练数据X[:3890]建立模型,对测试数据X[3890:]进行分类预测,也就是调用Python功能强大的sklearn包。我分别用了朴素贝叶斯、随机森林、SVM三种模型,最后会发现随机森林的预测效果确实比较不错,能够达到80%。SVM这个模型在本项目中效果很差,过拟合太严重了。因此我们需要根据不同的实际业务环境,多尝试各种模型的预测效果以及稳定情况,选择合适的模型。print '################################# 朴素贝叶斯模型 ##############################' from sklearn.naive_bayes GaussianNB nb = GaussianNB() fit = nb.fit(X_train,y_train) pred = fit.predict(X_test) accuracy = metrics.accuracy_score(y_test,pred) print '训练集上的准确率为%-8.6f%%' % (accuracy*100) pred1 = fit.predict(X[3890:]) print '预测分类结果:\n', pred1 accuracy1 = metrics.accuracy_score(evaluation1.Emotion,pred1) print '测试集上的准确率为%-8.6f%%' % (accuracy1*100) print '################################## 随机森林 ################################' from sklearn.ensemble import RandomForestClassifier rf=RandomForestClassifier(n_estimators=150,n_jobs=-1, # 调参是个体力活 oob_score=True,max_depth=150,min_samples_split=2,min_samples_leaf=1) rfit=rf.fit(X_train,y_train) rpred=rfit.predict(X_test) raccuracy = metrics.accuracy_score(y_test,rpred) print '训练集上的准确率为%-8.6f%%' % (raccuracy*100) rpred1=rfit.predict(X[3890:]) print '预测分类结果:\n', rpred1 raccuracy1 = metrics.accuracy_score(evaluation1.Emotion,rpred1) print '测试集上的准确率为%-8.6f%%' % (raccuracy1*100) print '##################################### SVM #################################' from sklearn.svm import SVC,LinearSVC #svc=LinearSVC() # 可选择不同的SVM模型 svc = SVC(kernel='sigmoid') #svc = SVC(kernel='poly', degree=3) sfit=svc.fit(X_train,y_train) spred=sfit.predict(X_test) saccuracy = metrics.accuracy_score(y_test,spred) print '训练集上的准确率为%-8.6f%%' % (saccuracy*100) spred1=sfit.predict(X[3890:]) print '预测分类结果:\n', spred1 saccuracy1 = metrics.accuracy_score(evaluation1.Emotion,spred1) print '测试集上的准确率为%-8.6f%%' % (saccuracy1*100)
模型评价
最后,我使用ROC Curve对模型进行评价。为什么需要这一步呢?因为通过模型我们预测的值是一个准确率,但是单靠一个准确率,还不能肯定地说这是个好模型。举一个极端的例子,将一份数据集分为两类,其中A类数量为990,B类数量为10,然后一个模型预测的结果全部为A类,准确率达到99%,这能说明这个模型非常好吗,答案显然是否定的。那么这时除开准确率(Accuracy)外,还需要精确率(Precision)、召回率(Recall)、F1-Score等标准来综合评价模型。ROC曲线(网上很多介绍,此处不多讲)就是一种综合评价模型的方法,横坐标FPR表示假正类率,纵坐标TPR表示真正类率,实曲线下面的面积,表示模型预测为正类的概率,取值在(0,1)之间,一般来讲>0.5,值越大表示模型的预测效果越好。那么对随机森林模型进行评价,取值为0.7673,综合上面的准确率,说明此模型的分类效果还不错。
结语
本文实际上就是一个文本分析+机器学习+分类预测的简单案例, 至此就讲解完了。但是,还有很多需要思考的地方,也就是实现过程实际还可以优化的地方。比如:1、选特征的方式需要优化,如果有新的留言,分词后会产生新词,而原来的模型并没有这个词;2、预测的方法过于简单,还应该加上交叉验证这一步骤,使模型的bias和variance处于平衡状态,模型更加稳健。
相关文章推荐
- 大数据分析学习之路——Hive
- R语言︱词典型情感分析文本操作技巧汇总(打标签、词典与数据匹配等)
- 数据分析学习之路——(四)爬虫初探—链家网城市新开楼盘房价
- 大数据分析学习之路—安装数据分析常用库
- 数据分析学习之路——(一)初衷
- 数据分析学习之路——(三)从泰坦尼克号撞击冰山后开始说起
- 数据分析学习之路——(八)分类算法介绍
- R语言︱词典型情感分析文本操作技巧汇总(打标签、词典与数据匹配等)
- 数据分析学习之路——(二)链家网部分城市新开楼盘分析
- 数据分析学习之路——(七)用数据分析教你如何买基金(2)
- 数据分析学习之路——(六)用数据分析教你如何买基金(1)
- vlc学习计划(6)--网络数据流接收处理过程分析
- 微软企业库5.0 学习之路——第七步、Cryptographer加密模块简单分析、自定义加密接口及使用—下篇
- CYQ.Data 轻量数据层之路 应用示例三 Aop切入留言系统--操作日志(二十七)
- vlc学习计划(7)--从接收到数据流到播放视频的过程分析
- ExtJs学习之路--从Grid中得到数据
- 如何抓取网页数据、分析并且去除Html标签(C#)
- Linux 学习数据专题【管理、编程、源码分析】——Linux相关图书选购指南
- C#抓取网页数据、分析并且去除HTML标签 【转】
- ORACLE学习之路--如何将EXCEL中的数据导入ORACLE