朴素贝叶斯分类及python实现
2018-03-14 11:27
1221 查看
1。基础理论
朴素贝叶斯属于分类算法中的一种,是数据挖掘常用的算法之一,简单的理解,有(c1,c2,c3,,,c(n))n个分类,对于某一类c(i),有若干特征属性(a1,a2,a3,,,a(m))m个属性,而现在出现c(j),我们要根据它的属性a判断它比较偏向于哪一类。这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。贝叶斯公式:
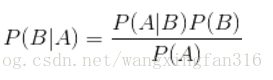
显然对于在实际运用算法中,对于P(A)中A的值可能为向量,即特征属性组成的向量,在算法中我们需要判断P(B|A)最大的值,显然转化为求等式右边的数据,而根据统计理论,对于相互独立的属性,下图可以很清楚的说明。在贝叶斯之前,我们还需要知道以下几个概念:

对于实际的算法,我们进行分类时,B就为我们已知的所以类别,A为某一类别的特征属性,所以算法简单的理解成:已知某个特征属性A,我们要求它属于哪一类B,我们将A这个特征属性属于全部类别的概率都计算出来,最终我们认为A属于概率最大的那个。
朴素贝叶斯算法原理小结
2。举例说明
而对于以下要使用的例子可能会有影响,当然举例的训练数据量比较小,得出的结论并不准确。假设有如下学生选课信息,1表示选了这个课,0表示没选。目前我们得知一个选课特征向量[1,0,1,1,0,0],我们想知道是男生还是女生选了这个课。如果数据量很大,我们可以使用贝叶斯算法,现在我们展示计算过程。
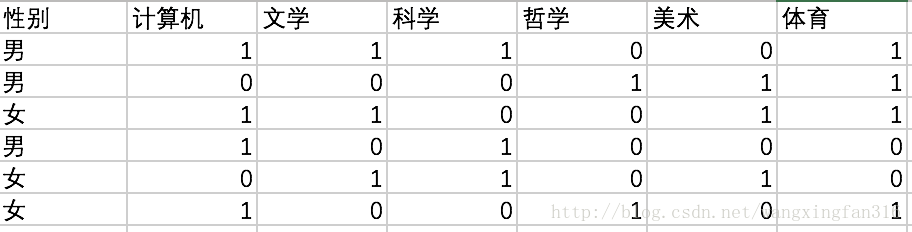
根据贝叶斯公式,我们首先求是男生的概率:
分子上的P(类别)男女数量是一样的都是3,所以概率为1/2
P(在这种选课下是男的) = [[p(男选了计算机)*p(男没选文学)...p(男没选体育)]*p(男)]/[p(男选了计算机)*p(男没选文学)...p(男没选体育)]*p(男)+[p(女选了计算机)*p(女没选文学)...p(女没选体育)]*p(女)] = [[2/3*2/3*2/3*1/3*2/3*1/3]*1/2]/[[2/3*2/3*2/3*1/3*2/3*1/3]*1/2+[2/3*1/3*1/3*1/3*1/3*1/3]*1/2]= 8/9 P(在这种选课下是女的) = [[p(女选了计算机)*p(女没选文学)...p(女没选体育)]*p(女)]/[p(男选了计算机)*p(男没选文学)...p(男没选体育)]*p(男)+[p(女选了计算机)*p(女没选文学)...p(女没选体育)]*p(女)] = [[]*1/2]/[[2/3*2/3*2/3*1/3*2/3*1/3]*1/2+[2/3*1/3*1/3*1/3*1/3*1/3]*1/2]= 1/9
显然在此选课特征向量[1,0,1,1,0,0]下,我们认为此人是男生。
3。代码实现

相关文章推荐
- 《机器学习实战》基于朴素贝叶斯分类算法构建文本分类器的Python实现
- 朴素贝叶斯案例1:进行文档/评论分类(python实现)
- scikit-learn机器学习(六)--朴素贝叶斯分类原理及python实现
- 朴素贝叶斯分类算法的Python实现
- Python实现基于朴素贝叶斯的垃圾邮件分类 标签: python朴素贝叶斯垃圾邮件分类 2016-04-20 15:09 2750人阅读 评论(1) 收藏 举报 分类: 机器学习(19) 听说
- 朴素贝叶斯分类文本 python实现
- 机器学习经典算法详解及Python实现---朴素贝叶斯分类及其在文本分类、垃圾邮件检测中的应用
- 朴素贝叶斯分类的Python实现
- 机器学习经典算法详解及Python实现---朴素贝叶斯分类及其在文本分类、垃圾邮件检测中的应用
- Python实现基于朴素贝叶斯的垃圾邮件分类
- 基于朴素贝叶斯的关于互联网金融新闻分类(python实现)
- 朴素贝叶斯分类算法原理与Python实现与使用方法案例
- 朴素贝叶斯的概率理论及其python代码实现文本分类的实例
- 【朴素贝叶斯】朴素贝叶斯详解 + Python实现垃圾邮件分类
- 机器学习之朴素贝叶斯(NB)分类算法与Python实现
- 朴素贝叶斯分类算法python实现
- 分类算法-----朴素贝叶斯原理和python实现
- 朴素贝叶斯分类算法介绍及python代码实现案例
- 贝叶斯分类方法学习三 python+jieba+mongodb实现朴素贝叶斯新闻文本自动分类
- 机器学习—— 基于朴素贝叶斯分类算法构建文本分类器的Python实现