升级完善第一个爬虫GCZW3,使能够批量爬取多篇文章热评
2018-03-13 15:47
225 查看
前天写了观察者网的爬虫,只能根据某个网页链接爬取,不能一次性大量爬取多篇文章的热门评论。
于是,今天想把它升级一下,让它可以从首页获取首页展示的所有文章的链接,并分别进行爬取。
于是写了mainPage2links() 函数,向它传入首页链接,可以得到首页展示文章的链接。
然后就可以批量爬取了。
当然这其中,也遇到了问题。首页解析后,在h4标签下的子标签a中可以找到文章的网址后半段,因此思路是先取出a标签中的href网址后半段,然后通过字符串的合并,得到完整的文章链接。
现在h4标签下的子标签a中是这样的:<h4 class="module-title"><a href="/industry-science/2018_03_13_449958.shtml" target="_blank">马斯克:准备送人上火星 但会丧命</a></h4>
首先想要得到/industry-science/2018_03_13_449958.shtml,在这里遇到了第1个难点,就是先要得到h4标签,然后通过bs4中父子标签的关系,得到a标签,所以网址后半段就可以通过下面的语句得到。links = soup.find_all('h4')
print(type(links))
finalArticleLinksList =[]
for k in links:
#print(k['href'])
allarticleLinks = k.a['href']
print(allarticleLinks)#后代标签然后,把通过字符串合并得到文章的最终网址链接。finalArticleLinks = ('http://www.guancha.cn' + allarticleLinks)再然后,遇到了第2个难点,上面语句得到的allarticleLinks是string类型,本来以为是list类型,结果操作时总是出错。后来查阅了如何构造列表的方法,成功创建了列表,在for循环中,对变量finalArticleLinks进行append的方式构造了列表finalArticleLinksList。

这样就可以通过遍历finalArticleLinksList中的每个网址,批量进行文章的人们评论爬虫了。
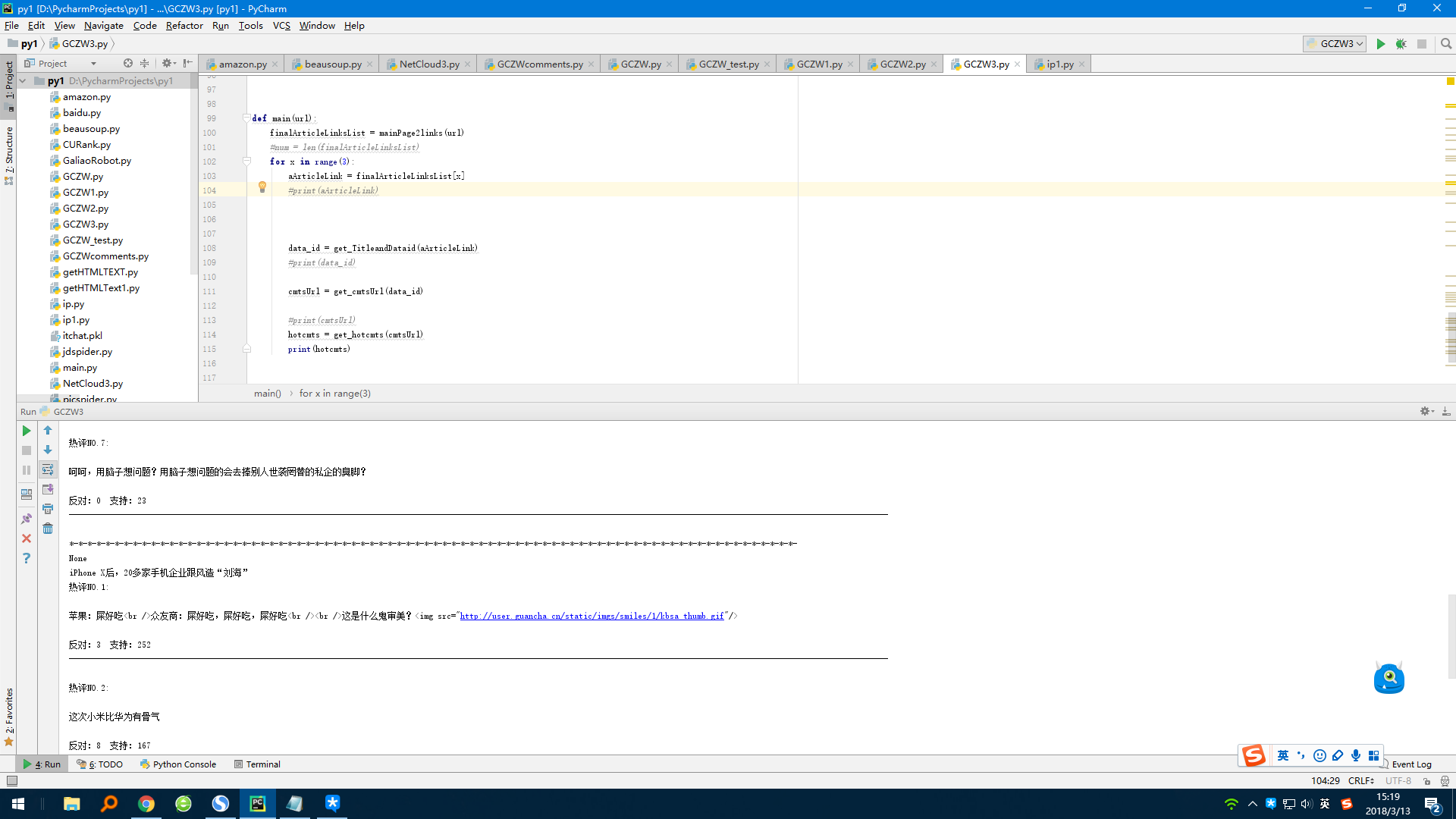
于是,今天想把它升级一下,让它可以从首页获取首页展示的所有文章的链接,并分别进行爬取。
于是写了mainPage2links() 函数,向它传入首页链接,可以得到首页展示文章的链接。
然后就可以批量爬取了。
当然这其中,也遇到了问题。首页解析后,在h4标签下的子标签a中可以找到文章的网址后半段,因此思路是先取出a标签中的href网址后半段,然后通过字符串的合并,得到完整的文章链接。
现在h4标签下的子标签a中是这样的:<h4 class="module-title"><a href="/industry-science/2018_03_13_449958.shtml" target="_blank">马斯克:准备送人上火星 但会丧命</a></h4>
首先想要得到/industry-science/2018_03_13_449958.shtml,在这里遇到了第1个难点,就是先要得到h4标签,然后通过bs4中父子标签的关系,得到a标签,所以网址后半段就可以通过下面的语句得到。links = soup.find_all('h4')
print(type(links))
finalArticleLinksList =[]
for k in links:
#print(k['href'])
allarticleLinks = k.a['href']
print(allarticleLinks)#后代标签然后,把通过字符串合并得到文章的最终网址链接。finalArticleLinks = ('http://www.guancha.cn' + allarticleLinks)再然后,遇到了第2个难点,上面语句得到的allarticleLinks是string类型,本来以为是list类型,结果操作时总是出错。后来查阅了如何构造列表的方法,成功创建了列表,在for循环中,对变量finalArticleLinks进行append的方式构造了列表finalArticleLinksList。
这样就可以通过遍历finalArticleLinksList中的每个网址,批量进行文章的人们评论爬虫了。

相关文章推荐
- dedecms V5.6 批量提取第一个图片作为缩略图(支持文章和图集模型
- 【Linux】一种Linux网络设备出厂批量软件初始化、安装、升级的方案
- 易宝典文章——怎样配置TMG能够使外部用户成功访问Outlook Anywhere?
- Linq 看文章到第一个小项目
- 很喜欢看某方面的文章,如何将不同站点,不同博主同一类别的文章归类整合到一起,再批量导出成各种格式---豆约翰博客备份专家新增按分类收藏博文功能
- Web文件批量上传控件升级日志-Xproer.HttpUploader
- WordPress 如何批量修改文章信息的SQL语句
- dedecms自定义字段添加与调用以及指定多篇文章调用
- 阿里云服务器自动化批量升级临时带宽
- 我们是这样写升级日志的,处处能够体现人文情怀
- 为了杜绝软件平台浪费现象,开沃软件打破GIS行业常规,基于其产品“HiMap移动GIS引擎”,推出了“第一个永久免费升级的移动GIS引擎!”的创新承诺。http://himap.us/
- 病毒侵袭持续中(我的第三道AC自动机---模板再次完善升级)
- 使用继续完善前人写的文章:使用ICTCLAS JAVA版(ictclas4j)进行中文分词
- Windows10升级安装错误代码0xC1900101-全集(win10普及,觉得这篇文章还挺好)
- 我的第一个比较完善的系统
- 豆约翰博客备份专家新增微信公众号文章批量下载功能
- 付亮:完善3G还有三步棋 网络监管待升级
- 批量抓取csdn博客列表文章,简化后转为pdf保存
- 如何给wordpress首页自动显示文章内容的第一个图片
- SharePoint 2010 升级到2013时 保证用户能够连接但不能修改正升级的数据