spark运行模式及集群架构
2018-03-11 11:38
309 查看
1、saprk的运行模式:local/yarn/standalone/k8s
2、spark核心配置文件:saprk-defaults.conf、spark-env.sh
3、saprk的jars目录:在saprk1.x中该目录下只有一个大的包,所有jar包都在这个包里面。在spark2.x该jars目录下就有很多的小的jar包。这儿有一个spark的优化点,以后再说。
4、执行spark的启动命令时,出现问题现有的打印在屏幕上的日志可能太少不便于debug,此时可进入spark的conf目录下,该目录下有一个log4j.properties.template文件,拷贝一份,将其中“log4j.rootCategory=INFO,console”中的"INFO"改成"DEBUG"即可。
####补充一下日志输出级别:
其中 [level] 是日志输出级别,共有5级:

FATAL 0
ERROR 3 为严重错误 主要是程序的错误
WARN 4 为一般警告,比如session丢失
INFO 6 为一般要显示的信息,比如登录登出
DEBUG 7 为程序的调试信息
5、local模式:
配置:编译好spark,将JAVA_HOME加入spark_env.sh文件即可。
启动方式:在${SPARK_HOME}/bin下执行./spark-shell --master local
####n代表该作业所需要消耗的core的数量
可以将SPARK_HOME加入系统环境变量哦
6、yarn模式:
此时的saprk只是作为一个提交作业的客户端。
1)配置:基于local模式下,将hadoop配置文件目录加入saprk的环境变量中。
vi saprk-env.sh
HADOOP_CONF_DIR=/home/hadoop/apps/hadoop/etc/hadoop
2)建议:将hive-site.xml加入spark配置文件目录
这个在同时执行多个作业时可以避免一些问题,具体什么问题大佬们自己测试哦。
3)启动方式:在${SPARK_HOME}/bin下执行"./spark-shell --master yarn --jars mysql驱动包绝对路径"即可
#yarn要先启动哦
可以将SPARK_HOME加入系统环境变量哦,并且建议将SPARK_CONF_DIR配置在系统环境变量中。
7、standalone模式:
主节点Master,从节点Worker。
1) 配置:
vi spark-env.sh 添加
SPARK_MASTER_HOST=192.168.149.141 ##配置Master节点
SPARK_WORKER_CORES=2 ##配置应用程序允许使用的核数(默认是所有的core)
SPARK_WORKER_MEMORY=2g ##配置应用程序允许使用的内存(默认是一个G)
vi slaves 添加
192.168.149.142
192.168.149.143
##slaves配置spark集群的Worker节点,Master节点也可以配置一个Worker节点
可以将SPARK_HOME加入系统环境变量哦
2)启动spark集群:./sbin/start-all.sh
3)网页UI在ip:8080上。
4)提交作业:./bin/spark-shell --master spark://${Master的ip或主机名}:7077
提交一个作业会默认占光所有的core,改作业未完成重新开启一个作业,新作业则没有core
其实对于standalone模式和Mesos模式 ,我们执行作业时可以通过参数控制作业所消耗的core数量,例如,我们可以使用命令“./bin/spark-shell --master spark://${Master的ip或主机名}:7077 --total-excutor-cores 1”来指定该spark-shell作业占用的core数为1。一个core默认占用一个G的内存。
8、spark核心概念
1)Application:用户基于spark的代码,由一个Driver和多个Excutor组成。
2)Application jar:将用户基于spark的代码打包成的jar包
3)Driver program:一个运行Main方法的进程,负责创建SparkContext。
4)Cluster Manager:负责获取集群资源的外部服务(如standalone模式的Master和yarn模式的RM)
5)Deploy mode:运行模式,如standalone模式,yarn模式,local模式,mesos模式
6)Excutor:在工作节点(如standalone模式的Worker和yarn模式的NM)起的进程,可以运行task,也可以将数据保存在内存和磁盘中。每个应用程序都有自己的Excutor.
7)Task:最小的工作单元。
8)Job:一个Job有许许多多的Task,每一个Action操作都会触发一个Job
9)Stage:一个job被拆分成许多的Stage,一个Stage包含多个Task,Stage是提交作业的最小单位,Stage之间彼此依赖。
9、sparkStandalone模式架构
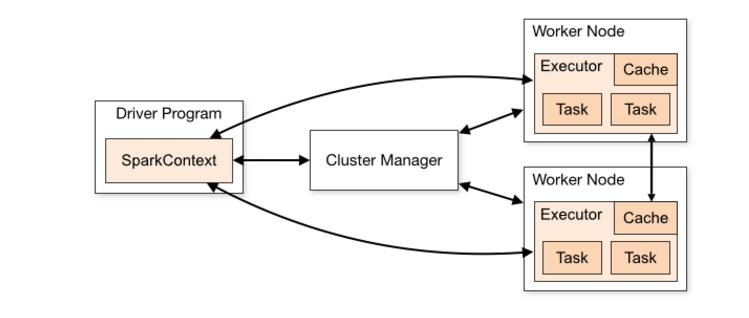
在Spark的standalone模式中,应用程序作为彼此独立的一组进程运行,这组进程受到SparkContext的管理。
集体来说,运行一个集群,首先SparkContext连接到cluster manager(负责在应用程序间分配资源),一旦连接成功,SparkContext就会获取集群的Worker Node的信息,并将作业信息提交给Worker Node执行。
关于这个体系结构,有几个值得注意的地方:
1、每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行Task。这种Application隔离机制是有优势的,无论是从调度角度看(每个Driver调度他自己的任务),还是从运行角度看(来自不同Application的Task运行在不同JVM中),当然这样意味着Spark Application不能跨应用程序共享数据,除非将数据写入外部存储系统(在一些场景中是需要跨应用程序共享数据的,我们可以用Alluxio实现)
2、Spark与底层的资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了。
3、在整个作业生命周期内,driver负责监听和接受来自excutor的请求,请保证它们之间可以相互通信。
4、driver将作业发送到工作节点,所以driver和工作节点最好近一些。
2、spark核心配置文件:saprk-defaults.conf、spark-env.sh
3、saprk的jars目录:在saprk1.x中该目录下只有一个大的包,所有jar包都在这个包里面。在spark2.x该jars目录下就有很多的小的jar包。这儿有一个spark的优化点,以后再说。
4、执行spark的启动命令时,出现问题现有的打印在屏幕上的日志可能太少不便于debug,此时可进入spark的conf目录下,该目录下有一个log4j.properties.template文件,拷贝一份,将其中“log4j.rootCategory=INFO,console”中的"INFO"改成"DEBUG"即可。
####补充一下日志输出级别:
其中 [level] 是日志输出级别,共有5级:
FATAL 0
ERROR 3 为严重错误 主要是程序的错误
WARN 4 为一般警告,比如session丢失
INFO 6 为一般要显示的信息,比如登录登出
DEBUG 7 为程序的调试信息
5、local模式:
配置:编译好spark,将JAVA_HOME加入spark_env.sh文件即可。
启动方式:在${SPARK_HOME}/bin下执行./spark-shell --master local
####n代表该作业所需要消耗的core的数量
可以将SPARK_HOME加入系统环境变量哦
6、yarn模式:
此时的saprk只是作为一个提交作业的客户端。
1)配置:基于local模式下,将hadoop配置文件目录加入saprk的环境变量中。
vi saprk-env.sh
HADOOP_CONF_DIR=/home/hadoop/apps/hadoop/etc/hadoop
2)建议:将hive-site.xml加入spark配置文件目录
这个在同时执行多个作业时可以避免一些问题,具体什么问题大佬们自己测试哦。
3)启动方式:在${SPARK_HOME}/bin下执行"./spark-shell --master yarn --jars mysql驱动包绝对路径"即可
#yarn要先启动哦
可以将SPARK_HOME加入系统环境变量哦,并且建议将SPARK_CONF_DIR配置在系统环境变量中。
7、standalone模式:
主节点Master,从节点Worker。
1) 配置:
vi spark-env.sh 添加
SPARK_MASTER_HOST=192.168.149.141 ##配置Master节点
SPARK_WORKER_CORES=2 ##配置应用程序允许使用的核数(默认是所有的core)
SPARK_WORKER_MEMORY=2g ##配置应用程序允许使用的内存(默认是一个G)
vi slaves 添加
192.168.149.142
192.168.149.143
##slaves配置spark集群的Worker节点,Master节点也可以配置一个Worker节点
可以将SPARK_HOME加入系统环境变量哦
2)启动spark集群:./sbin/start-all.sh
3)网页UI在ip:8080上。
4)提交作业:./bin/spark-shell --master spark://${Master的ip或主机名}:7077
提交一个作业会默认占光所有的core,改作业未完成重新开启一个作业,新作业则没有core
其实对于standalone模式和Mesos模式 ,我们执行作业时可以通过参数控制作业所消耗的core数量,例如,我们可以使用命令“./bin/spark-shell --master spark://${Master的ip或主机名}:7077 --total-excutor-cores 1”来指定该spark-shell作业占用的core数为1。一个core默认占用一个G的内存。
8、spark核心概念
1)Application:用户基于spark的代码,由一个Driver和多个Excutor组成。
2)Application jar:将用户基于spark的代码打包成的jar包
3)Driver program:一个运行Main方法的进程,负责创建SparkContext。
4)Cluster Manager:负责获取集群资源的外部服务(如standalone模式的Master和yarn模式的RM)
5)Deploy mode:运行模式,如standalone模式,yarn模式,local模式,mesos模式
6)Excutor:在工作节点(如standalone模式的Worker和yarn模式的NM)起的进程,可以运行task,也可以将数据保存在内存和磁盘中。每个应用程序都有自己的Excutor.
7)Task:最小的工作单元。
8)Job:一个Job有许许多多的Task,每一个Action操作都会触发一个Job
9)Stage:一个job被拆分成许多的Stage,一个Stage包含多个Task,Stage是提交作业的最小单位,Stage之间彼此依赖。
9、sparkStandalone模式架构
在Spark的standalone模式中,应用程序作为彼此独立的一组进程运行,这组进程受到SparkContext的管理。
集体来说,运行一个集群,首先SparkContext连接到cluster manager(负责在应用程序间分配资源),一旦连接成功,SparkContext就会获取集群的Worker Node的信息,并将作业信息提交给Worker Node执行。
关于这个体系结构,有几个值得注意的地方:
1、每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行Task。这种Application隔离机制是有优势的,无论是从调度角度看(每个Driver调度他自己的任务),还是从运行角度看(来自不同Application的Task运行在不同JVM中),当然这样意味着Spark Application不能跨应用程序共享数据,除非将数据写入外部存储系统(在一些场景中是需要跨应用程序共享数据的,我们可以用Alluxio实现)
2、Spark与底层的资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了。
3、在整个作业生命周期内,driver负责监听和接受来自excutor的请求,请保证它们之间可以相互通信。
4、driver将作业发送到工作节点,所以driver和工作节点最好近一些。

相关文章推荐
- Spark的运行架构分析(二)之运行模式详解
- Spark基本术语表+基本架构+基本提交运行模式
- Spark集群运行模式
- Spark定制班第30课:集群运行模式下的Spark Streaming日志和Web监控台实战演示彻底解密
- Spark教程-构建Spark集群-配置Hadoop单机模式并运行Wordcount(2)
- 第30课:集群运行模式下的Spark Streaming日志和Web监控台实战演示彻底解密
- Spark定制班第31课:集群运行模式下的Spark Streaming调试和难点解决实战经验分享
- Local模式下开发第一个Spark程序并运行于集群环境
- 在spark开发环境中使用Standalone模式调试集群运行
- Maven安装编译Spark,搭建Spark独立集群模式(Hadoop架构之上)
- IDEA【基本配置1】配置SBT 和 scala 并在spark环境中进行wordcount测试(spark集群运行模式)
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-配置Hadoop单机模式并运行Wordcount(2)
- 【原】简述使用spark集群模式运行程序
- Spark教程-构建Spark集群-配置Hadoop单机模式并运行Wordcount(1)
- Spark2.x学习笔记:4、Spark程序架构与运行模式
- Spark的运行架构分析(二)之运行模式详解
- 转:Spark的运行架构分析(二)之运行模式详解
- 蜗龙徒行-Spark学习笔记【五】IDEA中集群运行模式的配置
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-配置Hadoop单机模式并运行Wordcount(1)
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-配置Hadoop伪分布模式并运行Wordcount示例(1)