node架构与模块机制
2018-03-11 00:06
316 查看
回到node
node特性基于chrome V8特性基于事件驱动
非阻塞io
node的web开发优势高并发服务
高性能io node内部有一个进程池
前后端代码统一
node内部架构

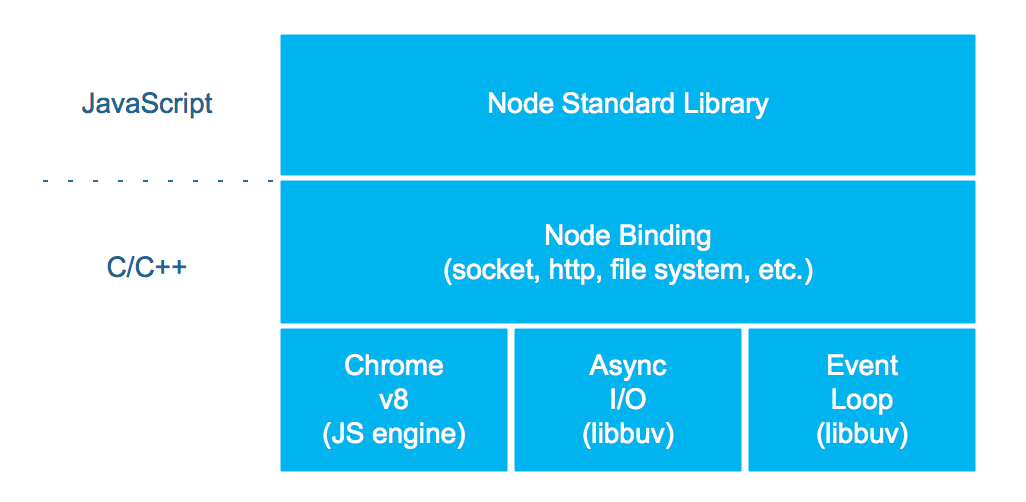
通过绑定调用C++,js可以调用c++程序。js是单线程的,如何去调用底层呢 node有一个插件比如libuv用来读取文件。node底层c++有一个线程池,这个跟js无关。还有事件循环,有一个循环机制维护一个消息队列
node模块机制
以模块(文件)来划分功能、组织代码和代码复用用包规范来管理应用和可复用组件
用npm工具和网站进行开源社区代码共享
Node模块模型
核心模块(C++写的,可以直接拿来用的)C/C++内建模块,最底层的模块。提供API给Javascript核心模块或其他Javascript文件模块调用(process.binding())Javascript核心模块,存放在node安装目录的lib下,为C/C++内建模块提供封装和桥接
文件模块C++扩展模块,为了运行效率和特殊目的按照Node规范编译,扩展名为node,用process.dlopen()加载执行(动态连结库)
Javascript文件模块,由第三方或用户自行编写的模块
常用的Node核心模块
console:控制台输入输出fs:与文件系统交互(在不同操作系统下是不一样的,node底层有个机制封装,可以使我们用的一样,实现跨平台)
fttp:提供HTTP服务器功能
net:有很多C++的库 提供TCP/IP网络功能
os:提供了一些操作系统相关的实用方法,比如取cpu、内存的信息
path:一般和os合起来用 提供了一些操作系统相关的实用方法
url:解析URL
querystring:解析URL的查询字符串
crypto:提供加密和解密功能,基本上是对OpenSSL的包装
模块对象
模块对象(module)实际上也是一个文件,表示当前模块文件,是一个js对象。模块对象不是全局的,而是每个模块唯一的模块对象的属性module.id,模块的标识符,通常是完全解析后的文件名
module.loaded 模块是否已经加载完成,或正在加载中 js运行时要先运行模块中的代码,加载完成后再执行其他的
filename 模块完全解析后的文件名
parent 调用该模块的模块
children 被该模块引用的模块对象
exports 模块的导出对象,默认为空对象
模块的导出
module.exports,模块的导出对象,默认为空对象 例子 exptestexports变量是module.exports的快捷方式,module.exports.f=…可以被更简洁地写成 exports.f=…exports变量直接赋值(exports=…)会使之不再是module.exports的快捷方式,导致不能被导出
为避免出错,模块的导出都用module.exports,不用exports
模块引用
使用require方法来指定加载模块,方法的参数是模块的标识符模块标识符包括核心模块,如http, fs, path等(核心模块不需要写路径,默认路径)
文件模块,可以省略文件扩展名以.或..开始的相对路径
绝对路径
安装包模块,如express, colors在全局(npm list -global)或当前应用的node_modules中寻找目录
在package.json文件中,寻找main属性所指明的模块入口文件
没有package.json文件,以index.js为模块入口文件
require.resolve()可用来解析模块标识符的绝对路径。
模块缓存
模块在第一次require后会被缓存,多次require不会导致模块的代码被执行多次Node模块的缓存不同于浏览器的js缓存,浏览器只缓存文件,Node模块缓存的是编译和执行之后的对象
require.cache对象代表Node模块缓存区,缓存的模块以属性的方式加入该对象,可以用require.cache[‘模块标识符’]来访问具体的缓存模块,也可以delete该缓存
node包规范
Node采用包来对一组具有相互依赖关系的模块进行统一管理,封装为独立的复用组件或单个应用Node的包通常为一个目录,包括如下内容package.json,包的描述文件
bin目录,用于存放可执行文件和其他二进制文件
lib目录,用于存放待加载的js文件
doc目录,用于存放包使用说明的文档
test目录,用于存放单元测试用例代码文件
node_modules目录,本地安装的其他第三方包(全局安装的第三方包用npm list -g查询)
package.json
package.json文件是一个JSON对象package.json的主要属性name:包名,npm install依赖此名称
version:版本号,版本号为a,b,c的形式,其中a是大版本号,b是小版本号,c是补丁号
description:项目描述,npm search会用到
keywords:关键字,npm search会用到
main:包输出主入口模块的ID,当包被require时,返回的就是这个模块的导出
author,contributors:author是一个人,contributors是一组人
dependents:当前包所依赖的其他包和包的版本
scripts:指定了运行脚本命令的npm命令行缩写
基于包规范开发应用流程
创建目录进入目录
初始化(npm init生成package.json文件)
配置依赖项(修改package.json的dependencies)
安装依赖包(npm install)
配置运行脚本命令(scripts的start子项,配置start是为统一包运行入口方式)
编写代码
运行代码(npm start)
非阻塞IO和事件驱动
非阻塞IO
操作系统内核进行I/O操作时有两种方式阻塞,应用要读取磁盘某文件时,要等待系统内核完成硬盘寻道、读取数据、复刻数据到内存等操作后,调用才结束非阻塞,应用的I/O调用可以立即返回,但返回的是调用的状态,需要轮询的方式确定系统内核是否完成所有操作
Windows的IOCP及*nix的libev有不同的实现
Node的非阻塞I/O底层是基于libuv的线程池(但也把IOCP包括在内(为了跨平台))
非阻塞I/O不再局限于文件I/O,还包括网络资源等的I/O
libuvlibuv是为Node设计开发的跨平台抽象层,用于抽象Windows的IOCP及*nix的libev,目前已独立开源
特性异步文件I/O
异步TCP, UDP套接字
异步DNS解析
线程池调度
。。。
非阻塞IO的调用过程和流程非阻塞I/O的调用过程
非阻塞I/O的流程
事件驱动
事件驱动:只有当事件发生时候才会调用回调函数的函数执行方式JavaScript异步的本质是事件驱动,其关键要素包括:消息队列(message queue),不占用JavaScript主线程运算时间的任务完成后或外部触发一个事件都会在消息队列里增加一条消息(事件)
回调函数(callback),每个消息有对应的处理函数
无限循环(even loop),不停地从消息队列(即观察者的队列)中检索消息,只要消息队列不空并且主线程空闲,就把消息对应的回调函数加载到EC Stack上执行主线程空闲:EC Stack上没有函数EC执行,Global EC的全局代码也执行完毕
每个请求不创建线程,用事件驱动调回调函数的方式 大大提高效率
node一般配的服务器是nginx主要用于反向代理和负载均衡
事件驱动的高性能服务器
传统web服务器(Apache, Tomcat, IIS等)基本上都是为每个请求启动一个线程来处理,直到该请求结束,大并发请求到来时,内存会耗光,导致服务器缓慢基于事件驱动处理请求,无须为每一请求创建额外的服务线程(通过线程池的方式节省开销),节省了线程创建、管理、销毁的开销,能极大地提高并发请求的性能。
Nginx web服务器是基于事件驱动的,在反向代理和负载均衡上有着大量的应用
Node可以独立作为事件驱动的高性能Web服务器,也可以和各种Web服务器配合使用。
Node event模块(重要)
Node event模块是一个基于发布/订阅模式的实现,比javascript客户端的事件模型简单,主要包括:事件源:可以发出事件的对象事件:通过事件源以唯一的字符串(事件名)来进行识别
事件订阅:为某个事件设置回调函数(可以有多个)
事件发布:事件源触发某个事件(可以触发任意次)
var events = require('events');
var eventEmitter = events.EventEmitter;
var count = 0;
var em = new eventEmitter(); //事件源
em.on('timed',function(data){ //事件订阅
console.log('timed '+data);
})
em.on('timed', function(data){ //事件订阅
console.log('事件数据:'+data);
})
setInterval(function(){
em.emit('timed',count++); //事件发布
},1000);输出结果:timed 0 事件数据:0 timed 1 事件数据:1 timed 2 事件数据:2 timed 3 事件数据:3
EventEmitter事件源对象基本都继承于EventEmitter
Node核心模块有近半数继承于EventEmitter
自定义对象的事件驱动可以通过继承于EventEmitter来实现
var events = require('events');
var util = require('util');
function MyEventSource() { //自定义事件源的构造函数
events.EventEmitter.call(this); //调用父类的构造函数
}
util.inherits(MyEventSource,events.EventEmitter); // 继承
MyEventSource.prototype.doit = function (data) {
this.emit('myevent',data); //事件发布
}
// 可以通过下面的代码来使用上面的事件源
var obj = new MyEventSource();
obj.on("myevent",function(data){ //事件订阅
console.log('Received data: "'+ data + '"');
})
obj.doit('foobar');
// Received data: "foobar"使用ES6的语法糖:var events = require('events');
class MyEmitter extends events.EventEmitter {};
const myEmitter = new MyEmitter();
myEmitter.on('event',() => {
console.log("触发了一个事件!");
});
myEmitter.emit('event');
// 触发了一个事件!EventEmitter.prototype方法事件默认最大的订阅数(监听器数)为10个,可以设置getMaxListeners(),返回当前最大订阅数
setMaxListeners(n),修改当前最大订阅数
为某事件增加订阅addListener(eventName, listener),一个事件可以多个订阅
on(eventName, listener),一个事件可以多个订阅
once(eventName, listener),一个事件只能一个订阅
emit(eventName[, …args]),按监听器的注册顺序,同步地调用每个注册名为eventName事件的监听器,并传入提供的参数。如果事件有监听器,则返回true,否则返回false
eventNames(),返回触发器上已注册监听器的事件的数组
listenerCount(eventName),返回正在监听名为eventName的事件的监听器的数量
listeners(eventName),返回名为eventName的事件的监听器数组的副本
removeAllListeners([eventNames]),移除全部或指定eventName的监听器
removeListener(eventName,listener),从名为eventName的事件的监听器数组中移除指定的listener
Node Buffer和Stream
BufferBuffer主要用来处理网络流、文件流等二进制数据,是Node网络编程的基石。Buffer类似数组,其元素都是字节(0-255的16进制表示),即其元素都是固定大小的
Buffer是Node全局对象的函数,无须用require加载
Buffer是典型的JS与C++结合的模块,性能相关部分用C++实现,再用JS封装。(要用c++眼光来看他 只不过提供了一些方法让js去调)
Buffer对象的内存分配是由Node的C++实现内存申请的,在V8堆外分配物理内存(是操作系统分配的空间),Buffer对象的大小在被创建时确定,且无法调整。(只能删掉重新分配)
Buffer函数Buffer函数是Buffer对象的构造函数,可以接受Buffer大小或数组或字符串来构造Buffer对象,但这些构造方式基本都被新版本的Node废弃了,取而代之的是Buffer函数的一些方法
Buffer函数的属性poolSize Buffer示例池大小的字节数(slab动态内存管理机制,小于实例池大小的Buffer对象共享实例池,大于实例池大小的Buffer对象按需分配)
Buffer函数的方法构建Buffer对象Buffer.alloc(size[,fill[,encoding]]),新建一个大小为size字节的Buffer对象,会清理该Buffer对象内存size ,Buffer对象的字节数
fill | | 用来预填充新建的Buffer的值。默认为0
encoding 如果fill是字符串,则该值是它的字符编码。默认:’utf8’
allocUnsafe(size),新建一个大小为size字节的Buffer对象,不会清理该Buffer对象内存,速度较快
from(array),复制数组新建Buffer对象
from(buffer),复制一个Buffer对象来新建Buffer对象
from(string[,encoding]),复制字符串来新建Buffer对象,encoding参数指定字符编码,默认为’utf8’
compare(),Buffer对象的比较,用于排序
const buf1 = Buffer.from('1234');
const buf2 = Buffer.from('0123');
const arr = [buf1, buf2];
console.log(arr.sort(Buffer.compare));
// 输出:[<Buffer 30 31 32 33>, <Buffer 31 32 33 34>] 16进制表示
// (结果相当于:[buf2, buf1])concat(),多个Buffer对象的合并(先把多个Buffer对象写在数组里)
isBuffer(),判断参数是否为Buffer对象
isEncoding(encoding) 判断当前的node是否支持某一编码(这样才知道内存里的值是什么),如果encoding是一个支持的字符编码则返回true,否则返回false
Buffer.protoType方法Buffer对象类似数组,可以用下标访问元素,也支持一些数组的属性和方法
Buffer.prototype属性length,分配的内存字节数,也是Buffer对象支持的最多元素成员数量
Buffer.prototype方法indexOf(),返回参数Buffer在Buffer对象第一次出现的位置(从0开始计数)
const buf = Buffer.from('this is a buffer');
console.log(buf.indexOf('is')) // 2
console.log(buf.indexOf(Buffer.from('a buffer'))); // 8
console.log(buf.indexOf(97)) //8lastIndexOf() 返回参数Buffer在Buffer对象最后出现的位置
includes方法,返回参数Buffer在Buffer对象是否存在
const buf = Buffer.from('this is a buffer');
console.log(buf.includes('is')) // true
console.log(buf.includes(Buffer.from('a buffer'))); // true
console.log(buf.includes(97)) // trueslice方法,用于提取Buffer的一部分,返回一个新Buffer(内存共享),原Buffer不变,第一个参数为起始位置(从0开始),第二个参数为终止位置(不包括在内)
const buf1 = Buffer.allocUnsafe(26);
for (let i = 0; i < 26; i++){
buf1[i] = i + 97;
}
const buf2 = buf1.slice(0,3);
console.log(buf2.toString('ascii',0,buf2.length)); //abc
buf1[0] = 33; // 注意buf1, buf2同时改变
console.log(buf2.toString('ascii',0,buf2.length)); //!bcequals方法,比较两个Buffer对象是否具有完全相同的字节内容
fill(value[,offset[,end]][,encoding]),填充一个Buffervalue | | 用来填充buf的值
offset 开始填充buf的位置 默认为0
end 结束填充Buf的位置(不包含),默认 buf.length
encoding 如果value是一个字符串,则这是它的字符编码,默认 utf8
copy(target[,targetStart[,sourceStart[,sourceEnd]]]),拷贝一个Buffer内容到另一个Buffertarget 要拷贝进的Buffer
targetStart target中开始拷贝的偏移量,默认0
sourceStart buf中开始拷贝的偏移量,默认0
sourceEnd buf中结束拷贝的偏移量,默认buf.length
Buffer对象还有一系列对内部元素的读(read开头)写(write开头)方法,这些方法名后缀包括字节类型(Double, Float, Int8, UInt8, Int16, UInt16, Int32, UInt32)和字节顺序(BE大端,LE小端)默认按小端字节序(x86的读写顺序,部分嵌入式是大端字节序)
Stream(流)Node I/O相关函数的调用方式有两种:同步阻塞,程序要等调用完成才能执行后续代码
异步不阻塞,后续代码不用等调用完成,程序通过调用回调和事件循环再回头处理数据
Node I/O遇到大文件或网络不稳定时,等待数据全部载入内存需要较长时间或导致出错,而采用“数据流”的方式,可以在数据还没有接受完成时,就开始处理,每读入一部分数据就处理一部分。
Stream是对数据进行读写操作功能的抽象,在应用程序中表示一组有序的、有起点有终点的字节数据的传输。
Node Stream通过事件驱动机制(所有的流都是EventEmitter的实例)实现数据的分段传输、及时处理
Stream类型 Readable 可读的流(例如fs.createReadStream())
Writable 可写的流(例如fs.createWriteStream())
Duplex 可读写的流(例如net.Socket)
Transform 在读写过程中可以修改和变换数据的Duplex流(例如zlib.createDeflate())
Stream管道机制通过pipe方法,实现不同数据流的对接,简化数据操作
通过unpipe方法,解除不同数据流的对接
var zlib = require('zlib');
var fs = require('fs');
var gzip = zlib.createGzip();
var inp = fs.createReadStream('pipe.js');
var out = fs.createWriteStream('pipe.js.gz');
inp.pipe(gzip).pipe(out); // 文件流到gzip再留到另一个文件执行结果,文件夹中多了一个pipe.js.gz,解压之后是pipe.jsStream Readable 只读流可读流是对数据源头的抽象,其功能是代表上游,提供数据给下游。例如:HTTP responses (Node为客户端时)
HTTP requests (Node为服务器端时)
fs read streams
可读流的两种模式flowing,可读流自动从系统底层读取数据,通过事件将数据提供给应用
paused,必须显式调用stream.read()方法来从流中读取数据片段
可读流有三种状态初始时flowing = null,不存在数据消费者,不会产生数据
调用pipe或resume()方法后,flowing = true,进入flowing模式,数据不新生成,可读流频繁触发事件
调用pause()方法后,flowing = false,进入paused模式,数据还在生成,但堆积到流的内部缓存,可读流不会触发事件
Stream Readable事件readable事件,在数据流能够向外提供数据时触发,回调函数function() {}
data事件,在流将数据传递给消费者时触发,回调函数function(chunk){},chunk是传递过来的数据片段
end事件,在流中再没有数据可供消费者触发,回调函数function (){}。
close事件,在数据源关闭时触发。close事件触发后,该流将不会再触发任何事件,回调函数function(){}
error事件,在读取数据发生错误时被触发,回调函数function(error){}, error是错误信息封装
Stream Readable对象方法read方法,从系统缓存读取数据并返回参数数量的数据(默认返回系统缓存之中的所有数据)。如果读不到数据,则返回null。在flowing模式中该方法是自动调用的,paused模式下可手动调用
_read (由C++写)底层数据源将数据放入可读数据流(自动调用)即从磁盘读数据到内存
push 在_read方法内部调用这个方法来触发data事件以传递_read从底层读入的数据
pause 使可读流进入paused模式,停止释放data事件和自动调用read方法
isPaused方法,检查可读流是否进入paused模式
resume方法,使可读流从paused模式转为flowing模式,继续释放data事件和自动调用read方法
setEncoding方法,使得可读流返回指定编码的字符串
Stream Readable底层
var Readable = require('stream').Readable;
var rs = Readable();
var c = 97;
// 重新定义_read 实现了一个底层的虚拟的_read函数 re.push(null)表示已经读完
rs._read = function() {
rs.push(String.fromCharCode(c++));
if(c > 'z'.charCodeAt(0)) rs.push(null);
};
rs.pipe(process.stdout); // 自动调用_read方法
// 打印结果:abcdefghijklmnopqrstuvwxyz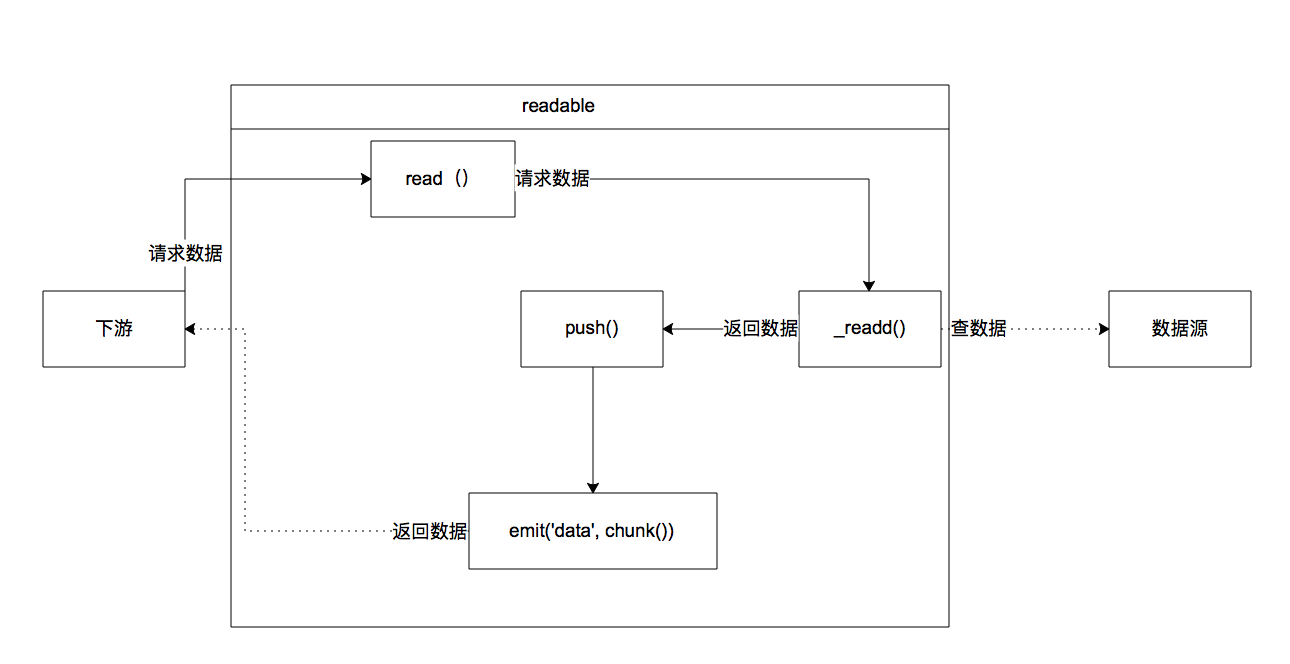
Stream Writable可写流是对数据目的地的抽象,其功能是代表下游,消耗上游提供的数据。例如:HTTP responses (Node为服务器端时)
HTTP requests (Node为客户端时)
fs write streams
Stream Writable事件 drain事件,可写流调用write方法返回false表示因缓冲区满而停止写入,当缓冲区数据全部传给底层系统(到底层文件或者网络),可以继续写入时,会触发drain事件,表示缓冲区空了,回调函数function(){ }
finish事件,可写流调用了end方法,且缓冲区数据都已经传给底层系统之后,表示写操作完成,回调函数function() { }
pipe事件,可读流调用pipe方法,目标流向可写流时,可写流触发pipe事件,回调函数function(src){ },src是source stream
unpipe事件,可读流调用unpipe方法,在目标流中移除可写流,可写流将触发unpipe事件,回调函数function(src){ },src是source stream
close事件,在数据源关闭时触发。close事件触发后,该流将不会再触发任何事件,回调函数function(){}
error事件,在写入数据出错或者使用管道出错时被触发,回调函数function(error){}, error是错误信息封装
Stream Writable对象方法write 用于向可写流写入数据(从node的对象写到磁盘中去)。它接受两个参数,一个是写入的内容,可以是字符串,也可以是一个stream对象(比如可读数据流)或buffer对象(表示二进制数据);另一个是写入完成后的回调函数(可选)。write方法返回一个布尔值,表示本次数据是否处理完成,返回true表示可以写入新数据了,返回false表示缓冲区满了。
_write (实际将数据写到磁盘)底层执行实际的写入操作(自动调用)
setDefaultEncoding方法,将写入的数据编码成新的格式,它返回一个布尔值,表示编码是否成功,如果返回false表示编码失败
cork方法 强制让等待写入的数据放入缓冲区。当调用unfork方法或end方法时,缓冲区(内存中)的数据才会吐出。主要用于处理大批量的小块数据的直接写入问题
end 用于关闭可写流,可以通过参数写入最后的数据和给finish事件传递回调函数,在调用end方法之后,再调用write方法将会导致错误。
Stream Duplex 双向流双向流同时具有可读流河可写流的方法属性,例如:TCP sockets
zlib streams
crypto streams
Stream Transform 转换流再双向流的基础上,将可读流释放的数据自动转换成另一种数据,然后再发给可写流,例如zlib streams
crypto streams
转换流对象相比双向流对象多一个底层的_transform方法,在流的过程中自动调用以实现流的转换
var Transform = require('stream').Transform;
var ts = Transform();
// 模拟实现转换流 一般这种方法都是用c++写的,这里用js模拟
ts._transform = function (obj, encoding, next) {
next(null, obj.toString().toUpperCase());
};
ts.pipe(process.stdout);
ts.write('a');
ts.write('b');
ts.end('c');
// 输出:ABC

相关文章推荐
- Nodejs 模块查找机制还不错(从当前目录开始逐级向上查找node_modules)
- 2. node.js 模块管理机制
- Node总结 模块机制
- 【深入浅出Node.js系列三】深入Node.js的模块机制
- Node.js的模块机制
- 深入浅出Node.js(三):深入Node.js的模块机制
- node.js(3) 模块加载机制
- Node.js中的模块机制学习笔记
- Node.js的模块载入方式与机制
- node.js require 实现机制初窥;pomelo代码分析5----------- pomel-loader模块
- 模块机制 之commonJs、node模块 、AMD、CMD
- 深入浅出Node.js(三):深入Node.js的模块机制
- Node.js笔记之模块机制
- 深入浅出Node.js(三):深入Node.js的模块机制
- Node.js的模块机制
- 深入浅出Node.js(三):深入Node.js的模块机制
- Node.js---02、node.js 模块加载机制
- Node.js的模块载入方式与机制
- Node.js 模块加载机制
- Node中的模块机制