C语言13之什么是结构体?
2018-03-10 11:34
281 查看
1.什么是结构体?
结构体(struct)是由一系列具有相同类型或不同类型的数据构成的数据集合,也叫结构。在C语言中结构体是一种数据结构。结构体可被声明为变量,指针或者数组等;同时,也是一些元素的集合,这些元素被称为结构体成员,且这些成员可以是不同的类型
1.1结构体的定义、初始化及引用
下面给出六种结构体定义:
1)其中第一种是最基本的结构体定义,其定义了一个结构体student。
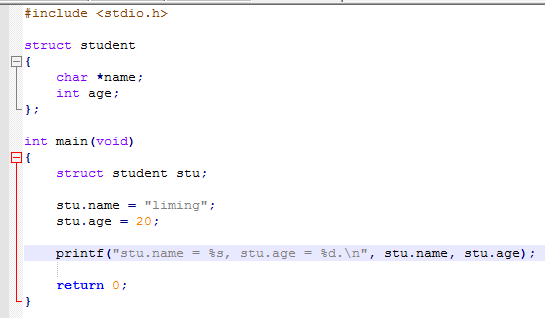

2)第二种则是在定义了一个结构体student的同时定义了一个结构体student的变量stu。


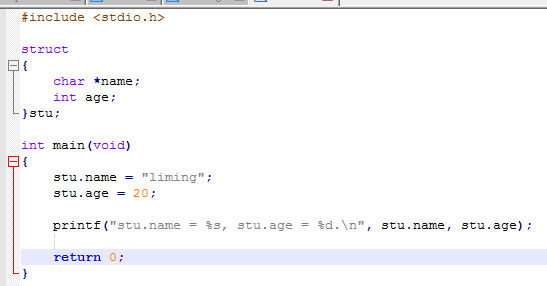
3)第三种结构体定义没有给出该结构体的名称,但是定义了一个该结构体的变量stu,也就是说,若是想要在别处定义该结构体的变量是不行的,只有变量stu这种在定义结构体的同时定义变量才行。

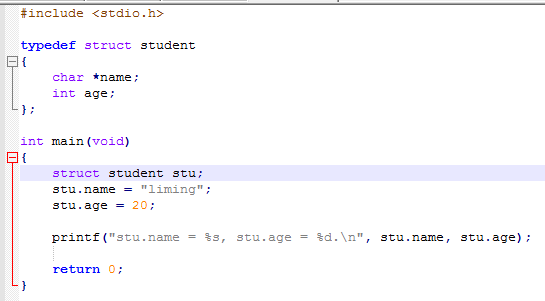
4)第四种结构体定义在第一种结构定义的基础上加了关键字typedef,此时我们将struct D{int d}看成是一个数据类型,但是因为并没有给出别名,直接用D定义变量是不行的。如D test;,不能直接这样定义变量test。但struct D test;可行。

5)第五种结构体定义在第四种结构体定义的基础上加上了别名x,此时像在第四种结构体定义中说得那样,此时的结构体E有别名x,故可以用x定义E的结构体变量。用E不能直接定义,需要在前面加struct,如struct E test;。
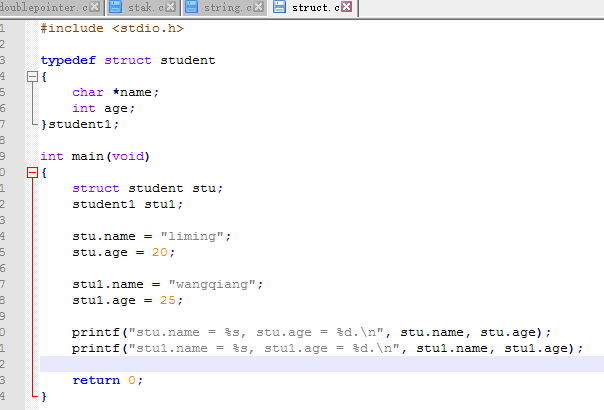

6)第六种结构体定义在第五种的基础上减去了结构体名,但是若是直接使用y来定义该结构体类型的变量也是可以的。如y test;。

1.2结构体的指针
定义结构体指针形式基本上常用的有三种方法:
程序中使用结构体类型指针引用结构体变量的成员,需要通过C提供的函数malloc()来为指针分配安全的地址。函数sizeof()返回值是计算给定数据类型所占内存的字节数。
2.结构体的对齐访问
2.1体对齐访问
1) 结构体通过'.'或者'->'来访问结构体中的元素,其本质实际上都是一样的,使用'.'号和'->'来访问的实质,就是用指针来进行访问,结合这个元素在整个结构体中的偏移量和这个元素的类型来进行访问的。
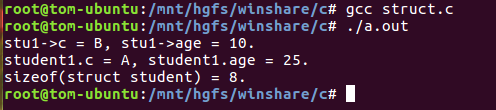
2)但是实际上结构体的元素的偏移量比我们上节讲的还要复杂,因为结构体要考虑元素的对齐访问,所以每个元素实际占的字节数和自己本身的类型所占的字节数不一定完全一样。(譬如char c实际占字节数可能是1,也可以是2,也可能是3,也可以能4••••)
3)一般来说,我们用.的方式来访问结构体元素时,我们是不用考虑结构体的元素对齐的。因为编译器会帮我们处理这个细节。但是因为C语言本身是很底层的语言,而且做嵌入式开发经常需要从内存角度,以指针方式来处理结构体及其中的元素,因此还是需要掌握结构体对齐规则。
2.2结构体为何要对齐访问?
内存对齐的原因:
à某些平台只能在特定的地址处访问特定类型的数据;
à提高存取数据的速度。比如有的平台每次都是从偶地址处读取数据,对于一个int型的变量,若从偶地址单元处存放,则只需一个读取周期即可读取该变量;但是若从奇地址单元处存放,则需要2个读取周期读取该变量。
1)结构体中元素对齐访问主要原因是为了配合硬件,也就是说硬件本身有物理上的限制,如果对齐排布和访问会提高效率,否则会大大降低效率。
2)内存本身是一个物理器件(DDR内存芯片,SoC上的DDR控制器),本身有一定的局限性:如果内存每次访问时按照4字节对齐访问,那么效率是最高的;如果你不对齐访问效率要低很多。
3)还有很多别的因素和原因,导致我们需要对齐访问。譬如Cache的一些缓存特性,还有其他硬件(譬如MMU、LCD显示器)的一些内存依赖特性,所以会要求内存对齐访问。
4)对比对齐访问和不对齐访问:对齐访问牺牲了内存空间,换取了速度性能;而非对齐访问牺牲了访问速度性能,换取了内存空间的完全利用。
2.3结构体对齐的规则和运算
编译器本身可以设置内存对齐的规则,有以下的规则需要记住:
在缺省情况下,C编译器为每一个变量或是数据单元按其自然对界条件分配空间。一般地,可以通过下面的方法来改变缺省的对界条件:


第一个:32位编译器,一般编译器默认对齐方式是4字节对齐。
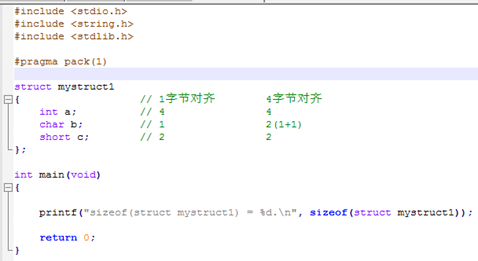



总结下:结构体对齐的分析要点和关键:
1)结构体对齐要考虑:结构体整体本身必须安置在4字节对齐处,结构体对齐后的大小必须4的倍数(编译器设置为4字节对齐时,如果编译器设置为8字节对齐,则这里的4是8)
2)结构体中每个元素本身都必须对其存放,而每个元素本身都有自己的对齐规则。
3)编译器考虑结构体存放时,以满足以上2点要求的最少内存需要的排布来算。
在C99标准中,对于
4000
内存对齐的细节没有作过多的描述,具体的实现交由编译器去处理,所以在不同的编译环境下,内存对齐可能略有不同,但是对齐的最基本原则是一致的,对于结构体的字节对齐主要有下面两点:
1)结构体每个成员相对结构体首地址的偏移量(offset)是对齐参数的整数倍,如有需要会在成员之间填充字节。编译器在为结构体成员开辟空间时,首先检查预开辟空间的地址相对于结构体首地址的偏移量是否为对齐参数的整数倍,若是,则存放该成员;若不是,则填充若干字节,以达到整数倍的要求。
2)结构体变量所占空间的大小是对齐参数大小的整数倍。如有需要会在最后一个成员末尾填充若干字节使得所占空间大小是对齐参数大小的整数倍。
注意:在看这两条原则之前,先了解一下对齐参数这个概念。对于每个变量,它自身有对齐参数,这个自身对齐参数在不同编译环境下不同。下面列举的是两种最常见的编译环境下各种类型变量的自身对齐参数
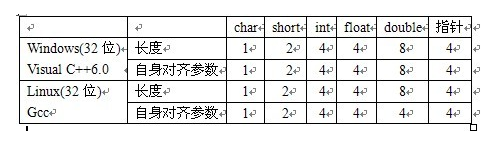
从上面可以发现,在windows(32)/VC6.0下各种类型的变量的自身对齐参数就是该类型变量所占字节数的大小,而在linux(32)/GCC下double类型的变量自身对齐参数是4,是因为linux(32)/GCC下如果该类型变量的长度没有超过CPU的字长,则以该类型变量的长度作为自身对齐参数,如果该类型变量的长度超过CPU字长,则自身对齐参数为CPU字长,而32位系统其CPU字长是4,所以linux(32)/GCC下double类型的变量自身对齐参数是4,如果是在Linux(64)下,则double类型的自身对齐参数是8。
除了变量的自身对齐参数外,还有一个对齐参数,就是每个编译器默认的对齐参数#pragma pack(n),这个值可以通过代码去设定,如果没有设定,则取系统的默认值。在windows(32)/VC6.0下,n的取值可以为1、2、4、8,默认情况下为8。在linux(32)/GCC下,n的取值只能为1、2、4,默认情况下为4。注意像DEV-CPP、MinGW等在windows下n的取值和VC的相同。
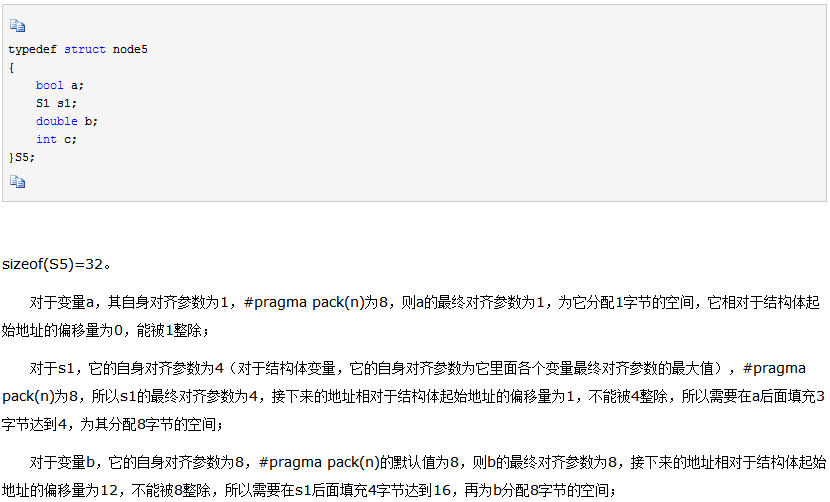
了解了这2个概念之后,可以理解上面2条原则了。对于第一条原则,每个变量相对于结构体的首地址的偏移量必须是对齐参数的整数倍,这句话中的对齐参数是取每个变量自身对齐参数和系统默认对齐参数#pragma pack(n)中较小的一个。举个简单的例子,比如在结构体A中有变量int a,a的自身对齐参数为4(环境为windows/vc),而VC默认的对齐参数为8,取较小者,则对于a,它相对于结构体A的起始地址的偏移量必须是4的倍数。
对于第二条原则,结构体变量所占空间的大小是对齐参数的整数倍。这句话中的对齐参数有点复杂,它是取结构体中所有变量的对齐参数的最大值和系统默认对齐参数#pragma pack(n)比较,较小者作为对齐参数。举个例子假如在结构体A中先后定义了两个变量int a;double b;对于变量a,它的自身对齐参数为4,而#pragma pack(n)值默认为8,则a的对齐参数为4;b的自身对齐参数为8,而#pragma pack(n)的默认值为8,则b的对齐参数为8。由于a的最终对齐参数为4,b的最终对齐参数为8,那么两者较大者是8,然后再拿8和#pragma pack(n)作比较,取较小者作为对齐参数,也就是8,即意味着结构体最终的大小必须能被8整除。





2.4gcc支持但不推荐的对齐指令:#pragma pack() #pragma pack(n) (n=1/2/4/8)
1)#pragma是用来指挥编译器,或者说设置编译器的对齐方式的。编译器的默认对齐方式是4,但是有时候我不希望对齐方式是4,而希望是别的(譬如希望1字节对齐,也可能希望是8,甚至可能希望128字节对齐)。
2)常用的设置编译器编译器对齐命令有2种:第一种是#pragma pack(),这种就是设置编译器1字节对齐(有些人喜欢讲:设置编译器不对齐访问,还有些讲:取消编译器对齐访问);第二种是#pragma pack(4),这个括号中的数字就表示我们希望多少字节对齐。
3)我们需要#prgama pack(n)开头,以#pragma pack()结尾,定义一个区间,这个区间内的对齐参数就是n。
4)#prgma pack的方式在很多C环境下都是支持的,但是gcc虽然也可以不过不建议使用。
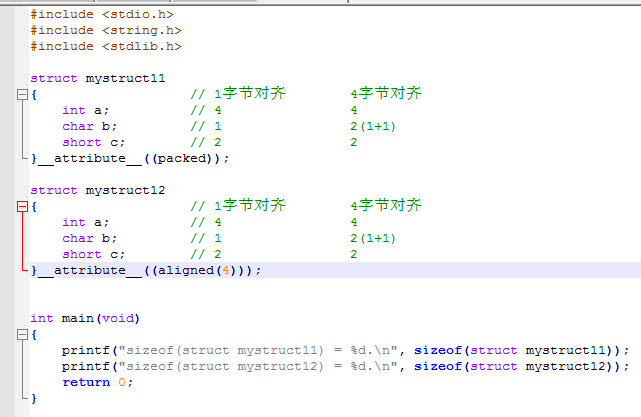
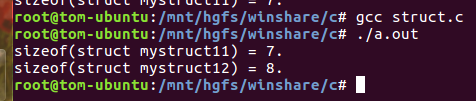
2.5 gcc推荐的 对齐指令__attribute__((packed)) __attribute__((aligned(n)))
1) __attribute__ 是编译器gcc能识别的定义一个"symbol"属性的关键字。如这个symbol是可以是函数,变量,结构成员等,给这个symbol赋值,就用__attribute__。
2)__attribute__((packed))使用时直接放在要进行内存对齐的类型定义的后面,然后它起作用的范围只有加了这个东西的这一个类型。packed的作用就是取消对齐访问。
3)__attribute__((aligned(n)))使用时直接放在要进行内存对齐的类型定义的后面,然后它起作用的范围只有加了这个东西的这一个类型。它的作用是让整个结构体变量整体进行n字节对齐(注意是结构体变量整体n字节对齐,而不是结构体内各元素也要n字节对齐)。
2.6参考阅读blog:
http://www.cnblogs.com/dolphin0520/archive/2011/09/17/2179466.html。
http://blog.csdn.net/sno_guo/article/details/8042332。
3.offsetof宏与container_of宏
3.1由结构体指针进而访问各元素的原理
通过结构体整体变量来访问其中各个元素,本质上是通过指针方式来访问的,形式上是通过.的方式来访问的(这时候其实是编译器帮我们自动计算了偏移量)。
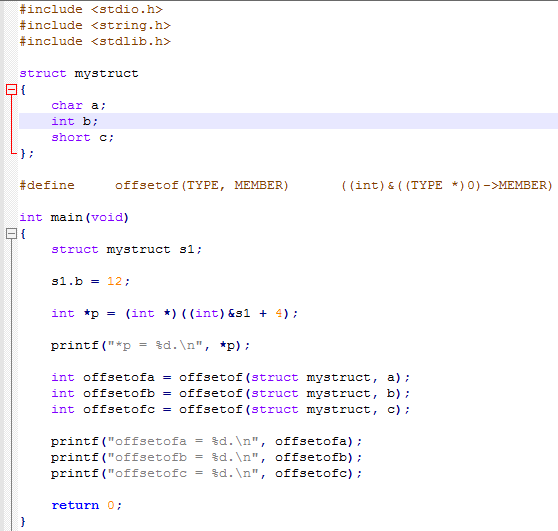
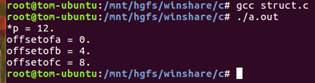
3.2 offsetof宏:
1)offsetof宏的作用是:用宏来计算结构体中某个元素和结构体首地址的偏移量(其实质是通过编译器来帮我们计算)。
2)offsetof宏的原理:我们虚拟一个type类型结构体变量,然后用type.member的方式来访问那个member元素,继而得到member相对于整个变量首地址的偏移量。
3)学习思路:第一步先学会用offsetof宏,第二步再去理解这个宏的实现原理。
(TYPE *)0 这是一个强制类型转换,把0地址强制类型转换成一个指针,这个指针指向一个TYPE类型的结构体变量。 (实际上这个结构体变量可能不存在,但是只要我不去解引用这个指针就不会出错)。
((TYPE *)0)->MEMBER (TYPE *)0是一个TYPE类型结构体变量的指针,通过指针指针来访问这个结构体变量的member元素
&((TYPE *)0)->MEMBER 等效于&(((TYPE *)0)->MEMBER),意义就是得到member元素的地址。但是因为整个结构体变量的首地址是0。它返回的是字节数。
3.3 container_of宏:
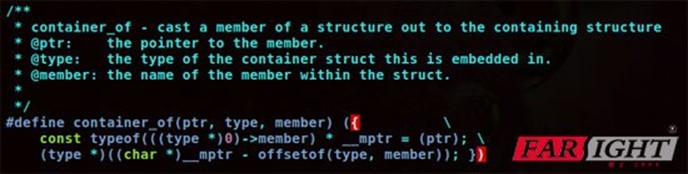
http://emb.hqyj.com/Column/Column433.htm。
1)作用:知道一个结构体中某个元素的地址,反推这个结构体变量的首地址。有了container_of宏,我们可以从一个元素的指针得到整个结构体变量的指针,继而得到结构体中其他元素的指针。
2)typeof关键字的作用是:typepof(a)时由变量a得到a的类型,typeof就是由变量名得到变量数据类型的。
3)这个宏的工作原理:先用typeof得到member元素的类型定义成一个指针,然后用这个指针减去该元素相对于整个结构体变量的偏移量(偏移量用offsetof宏得到的),减去之后得到的就是整个结构体变量的首地址了,再把这个地址强制类型转换为type *即可。
3.4学习指南和要求:
// TYPE是结构体类型,MEMBER是结构体中一个元素的元素名
// 这个宏返回的是member元素相对于整个结构体变量的首地址的偏移量,类型是int
#define offsetof(TYPE, MEMBER) ((int) &((TYPE *)0)->MEMBER)
// ptr是指向结构体元素member的指针,type是结构体类型,member是结构体中一个元素的元素名
// 这个宏返回的就是指向整个结构体变量的指针,类型是(type *)
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member) * __mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })
1)最基本要求是:必须要会这两个宏的使用。就是说能知道这两个宏接收什么参数,返回什么值,会用这两个宏来写代码。看见代码中别人用这两个宏能理解什么意思。
2)升级要求:能理解这两个宏的工作原理,能表述出来。(有些面试笔试题会这么要求)
3)更高级要求:能自己写出这两个宏(不要着急,慢慢来)
container_of()这个宏定义的功能是根据一个已知结构体成员的指针和变量名得出宿主结构体的地址
为方便理解和描述,本文中将已知的结构体成员叫做功能成员,它所在的结构体叫做宿主结构体。
4. offsetof和container of细节
先来分析一下参数:
ptr:指向功能成员的指针,存放功能成员的地址
type:宿主结构体的类型
member:功能成员在结构体中的表示(变量名)
container_of(ptr, type, member)的完整宏展开:
container_of(ptr, type, member) ({
const typeof( ((type*)0)->member ) *__mptr = (ptr) ;
(type*)( (char *)__mptr - offset(type, member) ) ; })
第2行,可能大伙看得有点蒙,先来分解一下这个语句的结构
我们定义一个变量的格式是:修饰符+变量类型+变量名 = 右值;
修饰符 变量类型 变量名 右值
const typeof( ((type*)0)->member ) *__mptr = (ptr) ;
现在看明白了吗,抛开具体细节,"typeof( ((type*)0)->member )"代表的是一种数据类型,那么它是什么样的数据类型呢?
((type*)0):它把0转换为一个type类型(也就是宿主结构体类型),为什么要这样做,且看后文
((type*)0)->member:这个0指针指向结构体中的member成员
typeof是gcc的c语言扩展保留字,用于获取变量的类型
typeof( ((type*)0)->member ) *:得出member的数据类型
所以,第2行的结果就是定义一个指向member的指针,并赋值为ptr
第3行,我们先看后半部分 offset(type, member);
offsetof定义在/include/linux/stddef.h中
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
根据前面的讲解可以知道:&((TYPE *)0)->MEMBER获得MEMBER的地址,此时&stu=0,因为结构体的基地址为0,所以MEMBER自然为其在结构体中的偏移地址。当然也可以把0换成1,这时&stu=1,要想得出功能成员相对于宿主结构体的偏移量还得在后面减去1,所以用0的好处就是使得功能成员的地址是相对于宿主结构体的偏移量。回到第2行,将0改为其他的任意正整数如"1",并不影响最后的结果,因为在第二行中的目的仅仅是获得member的数据类型而已。
(char *)__mptr - offset(type, member):用第2行获得的结构体成员地址减去其在结构体中的偏移值便可得到宿主结构体的地址
可能有些同学觉得疑问,为什么要把__mptr转换为char类型的指针呢,C语言中,一个指向特定数据类型的指针减1,实际上减去的是它所指向数据类型的字节大小sizeof(data),所以这里要把它转换成char类型,不然得不出正确结果
(type*)( (char *)__mptr - offset(type, member) ) 最后把地址转换成宿主结构体的类型type
由此,container_of()实现了根据一个已知结构体成员的指针和变量名得出宿主结构体的地址的功能
结构体(struct)是由一系列具有相同类型或不同类型的数据构成的数据集合,也叫结构。在C语言中结构体是一种数据结构。结构体可被声明为变量,指针或者数组等;同时,也是一些元素的集合,这些元素被称为结构体成员,且这些成员可以是不同的类型
1.1结构体的定义、初始化及引用
下面给出六种结构体定义:
1)其中第一种是最基本的结构体定义,其定义了一个结构体student。
2)第二种则是在定义了一个结构体student的同时定义了一个结构体student的变量stu。
3)第三种结构体定义没有给出该结构体的名称,但是定义了一个该结构体的变量stu,也就是说,若是想要在别处定义该结构体的变量是不行的,只有变量stu这种在定义结构体的同时定义变量才行。
4)第四种结构体定义在第一种结构定义的基础上加了关键字typedef,此时我们将struct D{int d}看成是一个数据类型,但是因为并没有给出别名,直接用D定义变量是不行的。如D test;,不能直接这样定义变量test。但struct D test;可行。
5)第五种结构体定义在第四种结构体定义的基础上加上了别名x,此时像在第四种结构体定义中说得那样,此时的结构体E有别名x,故可以用x定义E的结构体变量。用E不能直接定义,需要在前面加struct,如struct E test;。
6)第六种结构体定义在第五种的基础上减去了结构体名,但是若是直接使用y来定义该结构体类型的变量也是可以的。如y test;。
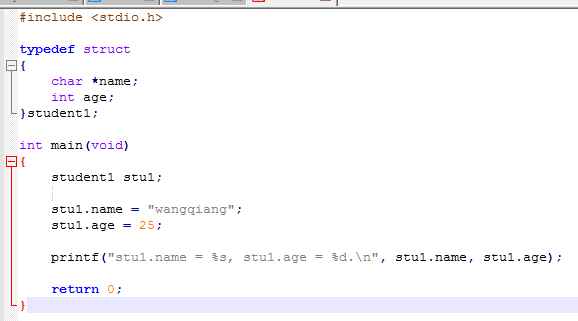
1.2结构体的指针
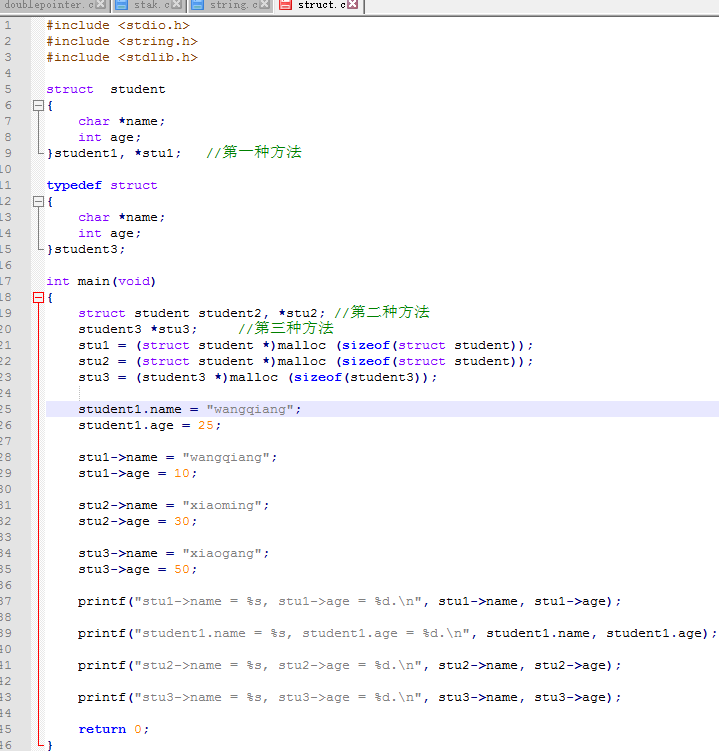
定义结构体指针形式基本上常用的有三种方法:
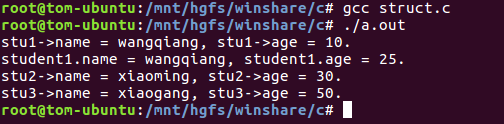
程序中使用结构体类型指针引用结构体变量的成员,需要通过C提供的函数malloc()来为指针分配安全的地址。函数sizeof()返回值是计算给定数据类型所占内存的字节数。
2.结构体的对齐访问
2.1体对齐访问
1) 结构体通过'.'或者'->'来访问结构体中的元素,其本质实际上都是一样的,使用'.'号和'->'来访问的实质,就是用指针来进行访问,结合这个元素在整个结构体中的偏移量和这个元素的类型来进行访问的。
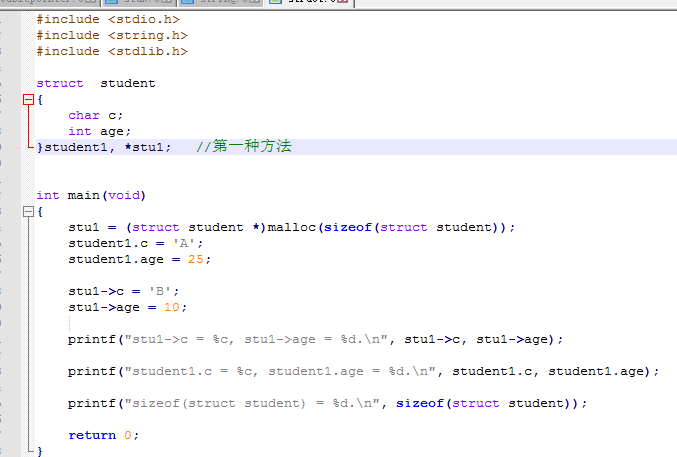
2)但是实际上结构体的元素的偏移量比我们上节讲的还要复杂,因为结构体要考虑元素的对齐访问,所以每个元素实际占的字节数和自己本身的类型所占的字节数不一定完全一样。(譬如char c实际占字节数可能是1,也可以是2,也可能是3,也可以能4••••)
3)一般来说,我们用.的方式来访问结构体元素时,我们是不用考虑结构体的元素对齐的。因为编译器会帮我们处理这个细节。但是因为C语言本身是很底层的语言,而且做嵌入式开发经常需要从内存角度,以指针方式来处理结构体及其中的元素,因此还是需要掌握结构体对齐规则。
2.2结构体为何要对齐访问?
内存对齐的原因:
à某些平台只能在特定的地址处访问特定类型的数据;
à提高存取数据的速度。比如有的平台每次都是从偶地址处读取数据,对于一个int型的变量,若从偶地址单元处存放,则只需一个读取周期即可读取该变量;但是若从奇地址单元处存放,则需要2个读取周期读取该变量。
1)结构体中元素对齐访问主要原因是为了配合硬件,也就是说硬件本身有物理上的限制,如果对齐排布和访问会提高效率,否则会大大降低效率。
2)内存本身是一个物理器件(DDR内存芯片,SoC上的DDR控制器),本身有一定的局限性:如果内存每次访问时按照4字节对齐访问,那么效率是最高的;如果你不对齐访问效率要低很多。
3)还有很多别的因素和原因,导致我们需要对齐访问。譬如Cache的一些缓存特性,还有其他硬件(譬如MMU、LCD显示器)的一些内存依赖特性,所以会要求内存对齐访问。
4)对比对齐访问和不对齐访问:对齐访问牺牲了内存空间,换取了速度性能;而非对齐访问牺牲了访问速度性能,换取了内存空间的完全利用。
2.3结构体对齐的规则和运算
编译器本身可以设置内存对齐的规则,有以下的规则需要记住:
在缺省情况下,C编译器为每一个变量或是数据单元按其自然对界条件分配空间。一般地,可以通过下面的方法来改变缺省的对界条件:
第一个:32位编译器,一般编译器默认对齐方式是4字节对齐。
总结下:结构体对齐的分析要点和关键:
1)结构体对齐要考虑:结构体整体本身必须安置在4字节对齐处,结构体对齐后的大小必须4的倍数(编译器设置为4字节对齐时,如果编译器设置为8字节对齐,则这里的4是8)
2)结构体中每个元素本身都必须对其存放,而每个元素本身都有自己的对齐规则。
3)编译器考虑结构体存放时,以满足以上2点要求的最少内存需要的排布来算。
在C99标准中,对于
4000
内存对齐的细节没有作过多的描述,具体的实现交由编译器去处理,所以在不同的编译环境下,内存对齐可能略有不同,但是对齐的最基本原则是一致的,对于结构体的字节对齐主要有下面两点:
1)结构体每个成员相对结构体首地址的偏移量(offset)是对齐参数的整数倍,如有需要会在成员之间填充字节。编译器在为结构体成员开辟空间时,首先检查预开辟空间的地址相对于结构体首地址的偏移量是否为对齐参数的整数倍,若是,则存放该成员;若不是,则填充若干字节,以达到整数倍的要求。
2)结构体变量所占空间的大小是对齐参数大小的整数倍。如有需要会在最后一个成员末尾填充若干字节使得所占空间大小是对齐参数大小的整数倍。
注意:在看这两条原则之前,先了解一下对齐参数这个概念。对于每个变量,它自身有对齐参数,这个自身对齐参数在不同编译环境下不同。下面列举的是两种最常见的编译环境下各种类型变量的自身对齐参数
从上面可以发现,在windows(32)/VC6.0下各种类型的变量的自身对齐参数就是该类型变量所占字节数的大小,而在linux(32)/GCC下double类型的变量自身对齐参数是4,是因为linux(32)/GCC下如果该类型变量的长度没有超过CPU的字长,则以该类型变量的长度作为自身对齐参数,如果该类型变量的长度超过CPU字长,则自身对齐参数为CPU字长,而32位系统其CPU字长是4,所以linux(32)/GCC下double类型的变量自身对齐参数是4,如果是在Linux(64)下,则double类型的自身对齐参数是8。
除了变量的自身对齐参数外,还有一个对齐参数,就是每个编译器默认的对齐参数#pragma pack(n),这个值可以通过代码去设定,如果没有设定,则取系统的默认值。在windows(32)/VC6.0下,n的取值可以为1、2、4、8,默认情况下为8。在linux(32)/GCC下,n的取值只能为1、2、4,默认情况下为4。注意像DEV-CPP、MinGW等在windows下n的取值和VC的相同。
了解了这2个概念之后,可以理解上面2条原则了。对于第一条原则,每个变量相对于结构体的首地址的偏移量必须是对齐参数的整数倍,这句话中的对齐参数是取每个变量自身对齐参数和系统默认对齐参数#pragma pack(n)中较小的一个。举个简单的例子,比如在结构体A中有变量int a,a的自身对齐参数为4(环境为windows/vc),而VC默认的对齐参数为8,取较小者,则对于a,它相对于结构体A的起始地址的偏移量必须是4的倍数。
对于第二条原则,结构体变量所占空间的大小是对齐参数的整数倍。这句话中的对齐参数有点复杂,它是取结构体中所有变量的对齐参数的最大值和系统默认对齐参数#pragma pack(n)比较,较小者作为对齐参数。举个例子假如在结构体A中先后定义了两个变量int a;double b;对于变量a,它的自身对齐参数为4,而#pragma pack(n)值默认为8,则a的对齐参数为4;b的自身对齐参数为8,而#pragma pack(n)的默认值为8,则b的对齐参数为8。由于a的最终对齐参数为4,b的最终对齐参数为8,那么两者较大者是8,然后再拿8和#pragma pack(n)作比较,取较小者作为对齐参数,也就是8,即意味着结构体最终的大小必须能被8整除。
2.4gcc支持但不推荐的对齐指令:#pragma pack() #pragma pack(n) (n=1/2/4/8)
1)#pragma是用来指挥编译器,或者说设置编译器的对齐方式的。编译器的默认对齐方式是4,但是有时候我不希望对齐方式是4,而希望是别的(譬如希望1字节对齐,也可能希望是8,甚至可能希望128字节对齐)。
2)常用的设置编译器编译器对齐命令有2种:第一种是#pragma pack(),这种就是设置编译器1字节对齐(有些人喜欢讲:设置编译器不对齐访问,还有些讲:取消编译器对齐访问);第二种是#pragma pack(4),这个括号中的数字就表示我们希望多少字节对齐。
3)我们需要#prgama pack(n)开头,以#pragma pack()结尾,定义一个区间,这个区间内的对齐参数就是n。
4)#prgma pack的方式在很多C环境下都是支持的,但是gcc虽然也可以不过不建议使用。
2.5 gcc推荐的 对齐指令__attribute__((packed)) __attribute__((aligned(n)))
1) __attribute__ 是编译器gcc能识别的定义一个"symbol"属性的关键字。如这个symbol是可以是函数,变量,结构成员等,给这个symbol赋值,就用__attribute__。
2)__attribute__((packed))使用时直接放在要进行内存对齐的类型定义的后面,然后它起作用的范围只有加了这个东西的这一个类型。packed的作用就是取消对齐访问。
3)__attribute__((aligned(n)))使用时直接放在要进行内存对齐的类型定义的后面,然后它起作用的范围只有加了这个东西的这一个类型。它的作用是让整个结构体变量整体进行n字节对齐(注意是结构体变量整体n字节对齐,而不是结构体内各元素也要n字节对齐)。
2.6参考阅读blog:
http://www.cnblogs.com/dolphin0520/archive/2011/09/17/2179466.html。
http://blog.csdn.net/sno_guo/article/details/8042332。
3.offsetof宏与container_of宏
3.1由结构体指针进而访问各元素的原理
通过结构体整体变量来访问其中各个元素,本质上是通过指针方式来访问的,形式上是通过.的方式来访问的(这时候其实是编译器帮我们自动计算了偏移量)。
3.2 offsetof宏:
1)offsetof宏的作用是:用宏来计算结构体中某个元素和结构体首地址的偏移量(其实质是通过编译器来帮我们计算)。
2)offsetof宏的原理:我们虚拟一个type类型结构体变量,然后用type.member的方式来访问那个member元素,继而得到member相对于整个变量首地址的偏移量。
3)学习思路:第一步先学会用offsetof宏,第二步再去理解这个宏的实现原理。
(TYPE *)0 这是一个强制类型转换,把0地址强制类型转换成一个指针,这个指针指向一个TYPE类型的结构体变量。 (实际上这个结构体变量可能不存在,但是只要我不去解引用这个指针就不会出错)。
((TYPE *)0)->MEMBER (TYPE *)0是一个TYPE类型结构体变量的指针,通过指针指针来访问这个结构体变量的member元素
&((TYPE *)0)->MEMBER 等效于&(((TYPE *)0)->MEMBER),意义就是得到member元素的地址。但是因为整个结构体变量的首地址是0。它返回的是字节数。
3.3 container_of宏:
http://emb.hqyj.com/Column/Column433.htm。
1)作用:知道一个结构体中某个元素的地址,反推这个结构体变量的首地址。有了container_of宏,我们可以从一个元素的指针得到整个结构体变量的指针,继而得到结构体中其他元素的指针。
2)typeof关键字的作用是:typepof(a)时由变量a得到a的类型,typeof就是由变量名得到变量数据类型的。
3)这个宏的工作原理:先用typeof得到member元素的类型定义成一个指针,然后用这个指针减去该元素相对于整个结构体变量的偏移量(偏移量用offsetof宏得到的),减去之后得到的就是整个结构体变量的首地址了,再把这个地址强制类型转换为type *即可。
3.4学习指南和要求:
// TYPE是结构体类型,MEMBER是结构体中一个元素的元素名
// 这个宏返回的是member元素相对于整个结构体变量的首地址的偏移量,类型是int
#define offsetof(TYPE, MEMBER) ((int) &((TYPE *)0)->MEMBER)
// ptr是指向结构体元素member的指针,type是结构体类型,member是结构体中一个元素的元素名
// 这个宏返回的就是指向整个结构体变量的指针,类型是(type *)
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member) * __mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })
1)最基本要求是:必须要会这两个宏的使用。就是说能知道这两个宏接收什么参数,返回什么值,会用这两个宏来写代码。看见代码中别人用这两个宏能理解什么意思。
2)升级要求:能理解这两个宏的工作原理,能表述出来。(有些面试笔试题会这么要求)
3)更高级要求:能自己写出这两个宏(不要着急,慢慢来)
container_of()这个宏定义的功能是根据一个已知结构体成员的指针和变量名得出宿主结构体的地址
为方便理解和描述,本文中将已知的结构体成员叫做功能成员,它所在的结构体叫做宿主结构体。
4. offsetof和container of细节
先来分析一下参数:
ptr:指向功能成员的指针,存放功能成员的地址
type:宿主结构体的类型
member:功能成员在结构体中的表示(变量名)
container_of(ptr, type, member)的完整宏展开:
container_of(ptr, type, member) ({
const typeof( ((type*)0)->member ) *__mptr = (ptr) ;
(type*)( (char *)__mptr - offset(type, member) ) ; })
第2行,可能大伙看得有点蒙,先来分解一下这个语句的结构
我们定义一个变量的格式是:修饰符+变量类型+变量名 = 右值;
修饰符 变量类型 变量名 右值
const typeof( ((type*)0)->member ) *__mptr = (ptr) ;
现在看明白了吗,抛开具体细节,"typeof( ((type*)0)->member )"代表的是一种数据类型,那么它是什么样的数据类型呢?
((type*)0):它把0转换为一个type类型(也就是宿主结构体类型),为什么要这样做,且看后文
((type*)0)->member:这个0指针指向结构体中的member成员
typeof是gcc的c语言扩展保留字,用于获取变量的类型
typeof( ((type*)0)->member ) *:得出member的数据类型
所以,第2行的结果就是定义一个指向member的指针,并赋值为ptr
第3行,我们先看后半部分 offset(type, member);
offsetof定义在/include/linux/stddef.h中
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
根据前面的讲解可以知道:&((TYPE *)0)->MEMBER获得MEMBER的地址,此时&stu=0,因为结构体的基地址为0,所以MEMBER自然为其在结构体中的偏移地址。当然也可以把0换成1,这时&stu=1,要想得出功能成员相对于宿主结构体的偏移量还得在后面减去1,所以用0的好处就是使得功能成员的地址是相对于宿主结构体的偏移量。回到第2行,将0改为其他的任意正整数如"1",并不影响最后的结果,因为在第二行中的目的仅仅是获得member的数据类型而已。
(char *)__mptr - offset(type, member):用第2行获得的结构体成员地址减去其在结构体中的偏移值便可得到宿主结构体的地址
可能有些同学觉得疑问,为什么要把__mptr转换为char类型的指针呢,C语言中,一个指向特定数据类型的指针减1,实际上减去的是它所指向数据类型的字节大小sizeof(data),所以这里要把它转换成char类型,不然得不出正确结果
(type*)( (char *)__mptr - offset(type, member) ) 最后把地址转换成宿主结构体的类型type
由此,container_of()实现了根据一个已知结构体成员的指针和变量名得出宿主结构体的地址的功能

相关文章推荐
- 第09天C语言(13):结构体-类型定义方式
- 黑马程序员--C语言自学笔记---13结构体、预编译、宏、条件编译
- c语言中定义结构体指针并指向一片内存空间和直接定义一个结构体变量的区别 Node *p=(Node *)malloc(sizeof(Node)); 和 Node p 两个有什么区别??? Node是一
- C语言typedef定义结构体数组,下面这段代码是什么意思?
- C语言及程序设计进阶例程-13 结构体数组及其应用
- 【C语言连载六】--------变量、修饰词、结构体、枚举、typedef
- C语言声明数组变量时,在什么情况下,可不指定数组大小
- 《C语言及程序设计》实践参考——点结构体
- c语言中的0UL或1UL是什么意思
- C语言中结构体变量私有化详解
- C语言第十次博客作业--结构体
- c语言博客作业-结构体
- c语言中的#ifndef、#def、#endif等宏是什么意思 .
- C语言头文件组织与包含原则(函数指针和结构体的前项声明)
- [转]C语言开发函数库时利用不透明指针对外隐藏结构体细节
- C语言中什么叫做左值?右值?
- C语言指针赋值0会产生什么结果?
- 浅谈C语言中结构体的初始化
- 普法知识(13):什么是法人?
- c语言中语句srand(time(NULL))什么意思。