机器学习-凸优化理论-课堂笔记
2018-03-09 19:58
656 查看
转载地址: http://blog.csdn.net/JoyceWYJ/article/details/51580139
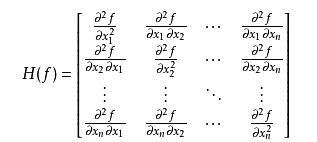
从Hessian矩阵可以看出,Hessian矩阵是个对称矩阵,因此可以定义矩阵的正负,也就是求对应的二次型的正负。求解二次型的特征值,如果特征值全正,就是正定矩阵;如果有正有负,就是不定矩阵。
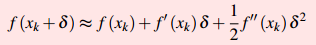
2)输入为矢量的泰勒级数展开如下,如果二次型>0,为正定矩阵,对应的xk是局部极小点;不定矩阵就是鞍点。二阶用矩阵表示,更高阶的用Tensor表示,处理高维矩阵,这里不作引申。
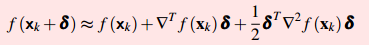
下面举例说明如何判断极值点。例如有函数 f(x) = (x12+ x22 -1)2 + (x22-1)2 1)计算一阶偏导和二阶偏导得到

2)另一阶偏导 ∇f=0 得到稳定点[0,0],[1,0],[-1,0],[0,1],[0,-1]
。
3)继续判断每一个稳定点对应的二阶偏导,如果某点得到的矩阵的特征值都小于0,函数在这个点就是严格
局部最大;如果特征值有正有负,就是不定矩阵,可以作为鞍点的候选点。
4)如果‖αkdk‖< ε,则停止迭代,输出解xk+1;否则继续迭代。
下面看一下如何选择dk。 1)深度下降法中dk选作负梯度-∇f(x),该算法通常速度比较慢。 2)牛顿法做近似时考虑了一阶导数和二阶导数,优势是下降的更快,如果选好了步长,可能一步到位。

,严格凸函数充要条件
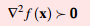
。结合上文海森矩阵的性质,可以知道,海森矩阵是正定矩阵一定是凸函数。 可以证明,凸函数局部最优解就是全局最优解。这也是研究凸函数的意义所在。 凸函数和凸集的关系:一元函数f的α水平集为 Sα = {x|x≤α},则有“f是凸函可推导出Sα对于每个α是凸集。
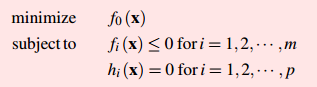
这是一个求函数最小化的问题,同时满足一些约束条件。其中f0(x)是凸函数,并且可行域是凸集,那么这个问题就是一个凸优化问题。
前言
这节课主要介绍凸优化的入门知识,程博士推荐阅读Boyd的《凸优化》,最经典的凸优化的书,这本书有600多页,细致讲解了凸优化相关的理论知识,可以作为一门学科来学习。因为硕士阶段学过《工程优化》,在这次学习过程中能容易的get到思想。 一般的优化问题包括 有约束和无约束两种,在这里我们将要弄清楚两件事情:为什么要优化?为什么要凸优化? 首先,为什么要优化?大致组织了以下两点: 1)方程式组本身没有解,但是在工程应用中会有求近似解的需求,怎么办呢?可以转化为求f(x)的最小值,即最小二乘问题。通过求导、求梯度来解。 2)如果方程式组变量特别多,且都是高阶的,可以想象是相当难解的。仍然可以转为最优化问题。1. 优化问题基础知识
1.1 无约束优化问题
首先来看无约束优化问题。无约束优化问题中会需要极值点分析,如局部最小(大)点、全局最小(大)点以及拐点(例如x3在x=0时)。高等数学有讲过,简单的函数求极值点可以求梯度,复杂一点的可以求二阶偏导,得到Hessian矩阵。从Hessian矩阵可以看出,Hessian矩阵是个对称矩阵,因此可以定义矩阵的正负,也就是求对应的二次型的正负。求解二次型的特征值,如果特征值全正,就是正定矩阵;如果有正有负,就是不定矩阵。
1.2 泰勒级数展开
泰勒展开特别有用,可以很方便的把一个函数展开成幂级数,即从函数的线性近似来估计函数。 1)输入为标量的泰勒级数展开:如果是极值点,一阶导数一定为0;如果一阶导数f’(xk)为0,可以是极大点、极小点或者拐点。然后再求二阶导数,f’’(xk)>0,xk为严格局部最小点,反之局部最大点,f’’(xk)=0则可能是一个鞍点。2)输入为矢量的泰勒级数展开如下,如果二次型>0,为正定矩阵,对应的xk是局部极小点;不定矩阵就是鞍点。二阶用矩阵表示,更高阶的用Tensor表示,处理高维矩阵,这里不作引申。
下面举例说明如何判断极值点。例如有函数 f(x) = (x12+ x22 -1)2 + (x22-1)2 1)计算一阶偏导和二阶偏导得到
2)另一阶偏导 ∇f=0 得到稳定点[0,0],[1,0],[-1,0],[0,1],[0,-1]
。
3)继续判断每一个稳定点对应的二阶偏导,如果某点得到的矩阵的特征值都小于0,函数在这个点就是严格
局部最大;如果特征值有正有负,就是不定矩阵,可以作为鞍点的候选点。
1.3 无约束优化迭代法
无约束优化问题直接分析法的局限性: 1)函数可能不可导; 2)函数求出了导数,但是对于复杂函数,不一定能求出来f’(x)=0的x; 3)求出的解可能是一个集合。 由于直接分析存在上述局限性,一般复杂的问题都不是通过求导解决的,需要“迭代法”。 迭代法的基本运算步骤如下: 1)选择一个初始点,设置收敛系数ε,计数k=0; 2)决定一个搜索方向dk,使函数下降;(核心) 3)决定步长αk使得f(xk+αdk)对于α≥0最小化,构建xk+1=xk+αkdk;4)如果‖αkdk‖< ε,则停止迭代,输出解xk+1;否则继续迭代。
下面看一下如何选择dk。 1)深度下降法中dk选作负梯度-∇f(x),该算法通常速度比较慢。 2)牛顿法做近似时考虑了一阶导数和二阶导数,优势是下降的更快,如果选好了步长,可能一步到位。
1.4 约束性优化问题
约束性优化问题是指除了给出方程外,方程的解还需要满足f(x)定义域约束等若干条约束条件,这种问题在实际生产中更有意义,在《工程优化》中学习过这类问题的解决方法。 衡量一般约束性优化问题极值点的一阶必要条件叫做KKT条件。KKT条件 (https://www.zhihu.com/question/23311674)说明了 1)最优点x∗必须满足所有等式及不等式限制条件, 也就是说最优点必须是一个可行解; 2)在最优点x∗,∇f必须是∇gi和∇hj的线性組合,μi和λj都叫作拉格朗日乘子。 那么什么条件下,KKT条件可以成为充要条件,什么条件下局部最小解可以成为全局最小解呢?这就是研究凸集和凸函数的意义啦。2. 凸集和凸函数
凸集的概念比较容易理解,满足集合上任意两点的连线上的点都在集合内,就是凸集。凸函数是定义在某个向量空间的凸子集C上的实值函数。 若要判断一个函数是否是凸函数,比较易用的有个二阶充要条件: 凸函数的二阶充要条件:如果函数f二阶可导,则凸函数充要条件,严格凸函数充要条件
。结合上文海森矩阵的性质,可以知道,海森矩阵是正定矩阵一定是凸函数。 可以证明,凸函数局部最优解就是全局最优解。这也是研究凸函数的意义所在。 凸函数和凸集的关系:一元函数f的α水平集为 Sα = {x|x≤α},则有“f是凸函可推导出Sα对于每个α是凸集。
3. 凸优化问题
3.1 凸优化问题的标准形式
如果一个问题是这样的形式:这是一个求函数最小化的问题,同时满足一些约束条件。其中f0(x)是凸函数,并且可行域是凸集,那么这个问题就是一个凸优化问题。
3.2 如何解凸优化问题
简单的可以用KKT法解决,复杂的可以用牛顿法、内点法等。 那么想一下,实际问题中凸优化适用范围大吗?对于非凸问题,有没有什么研究意义呢?办法就是“取近似“,把非凸优化问题近似为凸优化问题,再来求解。另外,有的问题在n维上看是非凸的,在n+1维上看可能就是凸问题。
相关文章推荐
- 机器学习课堂笔记(十五)
- 机器学习课堂笔记(五)
- Machine Learning 机器学习课堂笔记5(梯度下降)
- 机器学习课程_课堂笔记1:
- 机器学习课堂笔记(十六)
- 机器学习课堂笔记(十二)
- 机器学习课堂笔记(四)
- 机器学习笔记_数学基础_7-凸优化理论
- 【学习笔记】斯坦福大学公开课(机器学习) 之学习理论.a
- 机器学习笔记(十二)计算学习理论
- 机器学习笔记—学习理论
- 机器学习课堂笔记(十)
- 机器学习入门学习笔记:(2.4)线性判别分析理论推导
- 机器学习课堂笔记(十七)
- 公开课机器学习笔记(17)学习理论二 VC维、ERM总结、模型选择、特征选择
- 林轩田-机器学习基石 课堂笔记(一)A takes D and H to get g
- 斯坦福大学公开课 :Andrew Ng 机器学习课堂笔记之第一节(机器学习的动机与应用)
- 林轩田-机器学习基石 课堂笔记(八) Noise and Error
- 听课笔记(第七讲): VC维理论 (台大机器学习)
- JAVA课堂笔记一 理论学习总结篇