Pandas简易入门(四)
2018-03-08 15:19
239 查看
本节主要介绍一下Pandas的另一个数据结构:DataFrame,本文的内容来源:http://www.cnblogs.com/kylinlin/p/5231328.html 在上一节中已经介绍过了Series对象,Series对象可以理解为由一列索引和一列值,共两列数据组成的结构。而DataFrame就是由一列索引和多列值组成的结构,其中,在DataFrame中的每一列都是一个Series对象。
这是原始的数据:
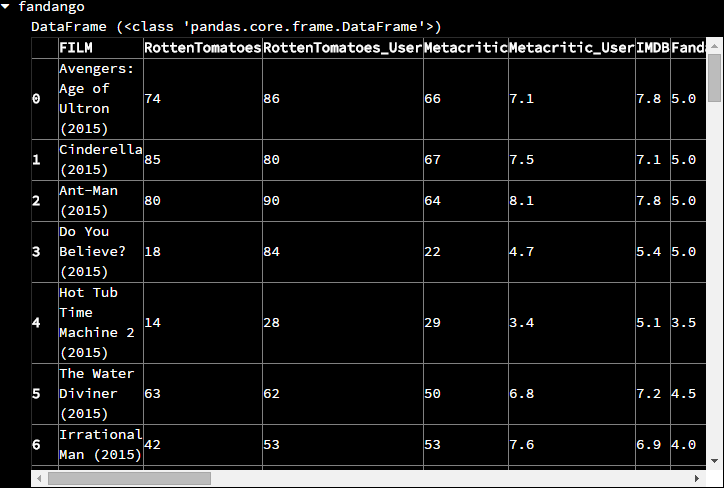
在Series中,每一个索引都对应着一个值,在DataFrame中,每一个索引则对应着一行的数据,可以通过几种方法来选择多数据
总结:要选择连续的多行,就是用列表的切片功能,选择一行就是用loc[]方法或者iloc[]方法(二者的区别可以看我的另一篇博客“Pandas之让人容易混淆的行选择和列选择“)当选择一行的数据时,Pandas会返回一个Series对象,当选择多行数据时,会返回一个DataFrame对象
drop,如果设置为True,就会移出掉该列的数据
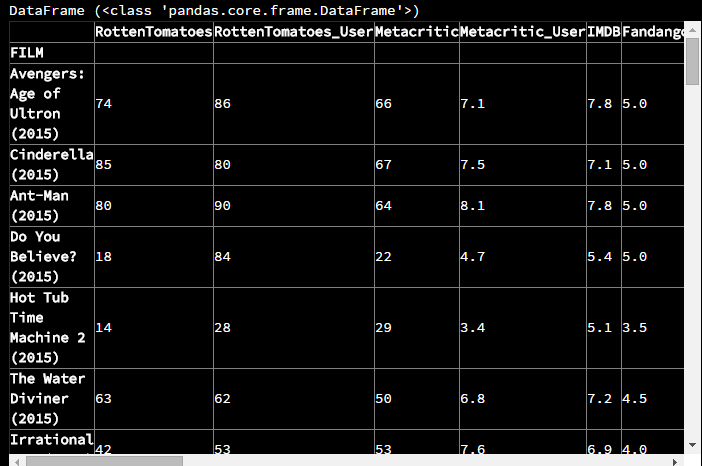
可以看到索引值已经变了,并且该DataFrame中也移除了名为FILM的列(该列变成了索引)使用了自定义的索引后,类似于之前的行选择一样进行选择,只是把整数索引换成了电影名称而已,例如
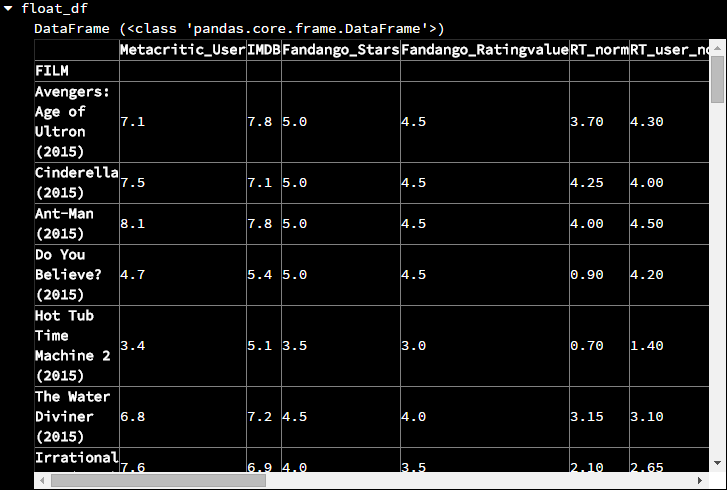
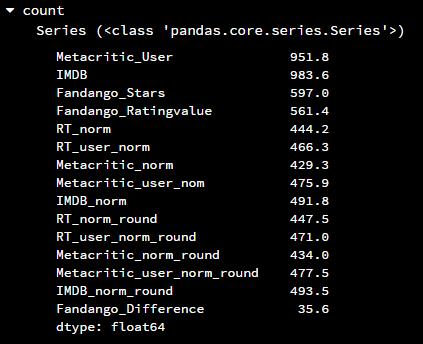
如果该方法没有合并运算结果(譬如将整列(行)的值都分别乘2),那么就会返回一个DataFrame。如下
如果要在行上使用apply()方法,只要指定参数axis = 1即可
行选择
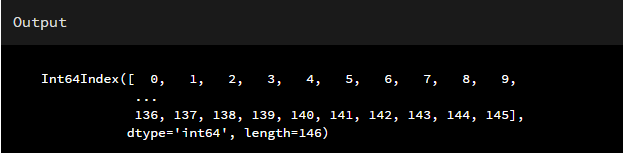
不管何时,你调用了一个方法返回或者打印一个DataFrame时,最左边的一列必然是索引值,可以通过index属性来直接访问DataFrame的索引值,本节所用的数据来源于:https://github.com/fivethirtyeight/data/tree/master/fandangoimport pandas as pd
fandango = pd.read_csv('fandango_score_comparison.csv')
# print(fandango.head(2)) 输出前两行
print(fandango.index) # 打印索引列的值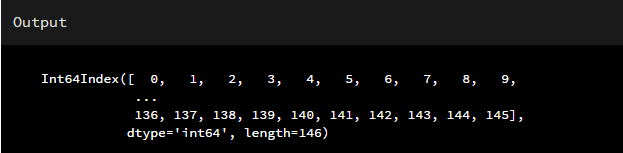
这是原始的数据:

在Series中,每一个索引都对应着一个值,在DataFrame中,每一个索引则对应着一行的数据,可以通过几种方法来选择多数据
# 选择前五行 fandango[0:5] # 选择索引号140及其以后的行 fandango[140:] # 只选择索引号为50的那一行 fandango.loc[50] # 选择索引号为45和90的两行 fanda 16a8a ngo.loc[[45,90]]
总结:要选择连续的多行,就是用列表的切片功能,选择一行就是用loc[]方法或者iloc[]方法(二者的区别可以看我的另一篇博客“Pandas之让人容易混淆的行选择和列选择“)当选择一行的数据时,Pandas会返回一个Series对象,当选择多行数据时,会返回一个DataFrame对象
自定义索引
Pandas可以使用某一列来重新自定义DataFrame的索引,通过set_index()方法来实现,该方法主要有两个参数:inplace,如果设置为True就不会返回一个新的DataFrame,而是直接修改该DataFramedrop,如果设置为True,就会移出掉该列的数据
# 我要把电影名称作为该DataFrame的索引
fandango = pd.read_csv('fandango_score_comparison.csv')
fandango_films = fandango.set_index('FILM', inplace=False, drop=True)
可以看到索引值已经变了,并且该DataFrame中也移除了名为FILM的列(该列变成了索引)使用了自定义的索引后,类似于之前的行选择一样进行选择,只是把整数索引换成了电影名称而已,例如
# 使用切片或者loc[]函数 fandango_films["Avengers: Age of Ultron (2015)":"Hot Tub Time Machine 2 (2015)"] fandango_films.loc["Avengers: Age of Ultron (2015)":"Hot Tub Time Machine 2 (2015)"] # 指定要返回的电影 fandango_films.loc['Kumiko, The Treasure Hunter (2015)'] # 选择要返回的多部电影 movies = ['Kumiko, The Treasure Hunter (2015)', 'Do You Believe? (2015)', 'Ant-Man (2015)'] fandango_films.loc[movies]
Apply方法
apply()方法是运行在Series对象中的,而Pandas中任何单独一列或者单独一行的数据就是一个Series对象,apply()方法中要传递的是一个向量运算方法如果该方法返回一个单独的值(譬如将整列(行)的值相加),那么就会返回一个Series,该Series保存的是全部列的运行结果,如下import numpy as np # 得出每一列的数据类型 types = fandango_films.dtypes # 选择具有浮点数据的那些列 float_columns = types[types.values == 'float64'].index float_df = fandango_films[float_columns]
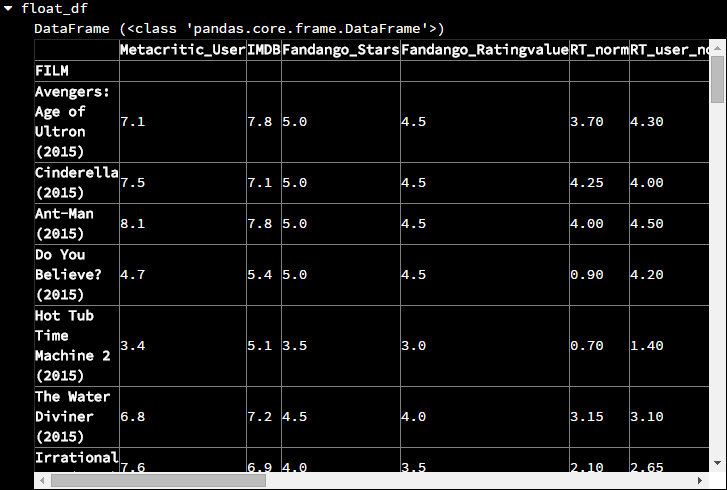
# 对选择的列计算总分,在lambda中的x是一个Series,代表了某一列 count = float_df.apply(lambda x: np.sum(x))

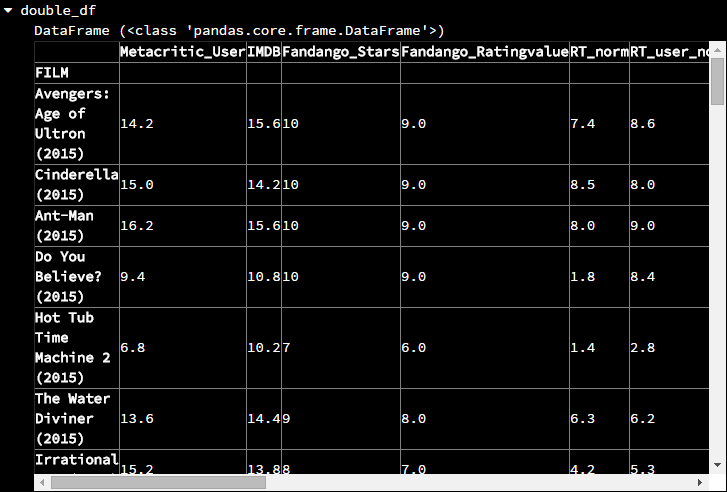
如果该方法没有合并运算结果(譬如将整列(行)的值都分别乘2),那么就会返回一个DataFrame。如下
double_df = float_df.apply(lambda x: x*2)

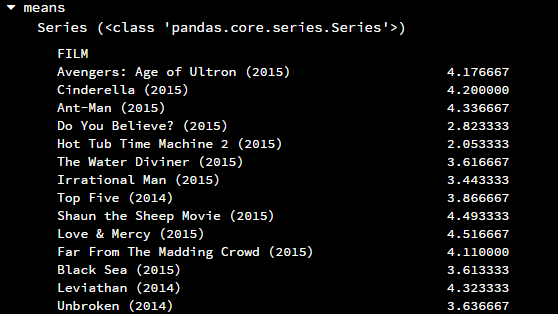
如果要在行上使用apply()方法,只要指定参数axis = 1即可
# 计算每部电影的平均分 means = float_df.apply(lambda x: np.mean(x), axis = 1)


相关文章推荐
- Pandas简易入门(一)
- Pandas简易入门(一)
- Pandas简易入门(二)
- Pandas简易入门(四)
- Pandas简易入门(二)
- Pandas简易入门(三)
- 数据可视化(二)Matplotlib pandas简易入门
- Spring框架自学之路——简易入门
- pandas/sklearn入门指南
- 基于socket和thread写的入门级简易聊天工具
- c++快速简易入门教程_002构造函数
- Lua简易入门
- STORM入门之(Topology简易Demo)
- Pandas入门(上)
- LaTeX-TexmakerX 简易入门指南
- libSVM 简易入门
- 数据可视化(三)- Seaborn简易入门
- DZ插件制作简易入门教程(自学手记)第二篇
- React Router 4 简易入门
- WEB AUDIO API简易入门教程