第一讲 梯度下降
2018-03-05 22:56
253 查看
1. 梯度下降
在学习神经网络与机器学习之前,不得不先了解一种迭代方法,那就是梯度下降法。在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。
在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。这些都会在后面讲解。
2. 梯度下降小述
在学习微积分时,对于一个多元函数,当对其中各个元求偏导数,再把求得的偏导数以向量的形式表示出来,这个向量就是梯度。比如一个具有x和y的函数的两元函数

,假设z代表高度,x,y分别代表两个方向,那么
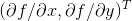
就是的梯度,简称为
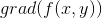
或者
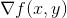
。那么在点
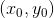
处的梯度就是
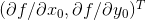
。
在点
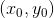
处的梯度
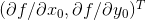
具有什么意义呢?简单的来说,这个梯度就是在点
处变化最快的方向。
3. 梯度下降算法详解
下面就通过图解梯度下降和详细的数学表示两方面来讲解梯度下降。
3.1 图解梯度下降
如下图1.1所示,当我们选定初始点

时,我们通过计算这一点的梯度
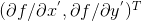
,来找到下降最快的方向,从而得到新的点

,此处的“+”号,并不是代表相加得到,而是代表“更快”的得到最小值。通过迭代,最终找到点
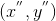
,当前点即是最小值点。
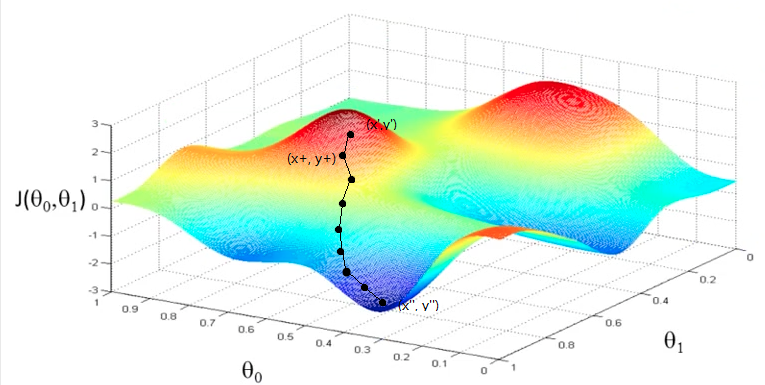
图1.1 梯度下降
3.2 梯度下降的几个概念
在详细的讲解梯度下降算法以前,有必要先了解几个有关的概念。
1. 步长:步长是指每一次迭代过程后,算法下降的长度。用一个比较典型的例子,假设我们在下山,步长就是在我们确定了最陡的方向后,迈出的那一步的距离。
2. 假设函数:假设函数可认为我们在监督学习中,针对输入的m个样本
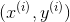
,
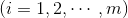
,所要拟合的函数

,可认为是最重要得到的那个函数。
3. 损失函数:损失函数是为了衡量拟合程度的好与坏,所以通常损失函数为
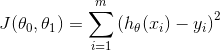
3.3 梯度下降法的代数表示
梯度下降法有代数法和矩阵法两种表示方法,本文着重对代数法进行讲解。矩阵法表示可参考网络中其他资源。
1. 代数法的假设函数和代价函数
代数法表示梯度下降之前,要明确两个函数,分别是假设函数和代价函数。
假设函数实际上是我们最终所想得到的函数(回归)。对于线性回归来说,假设函数表示为

,其中

为模型参数,也是我们最终所要训练得到的参数。
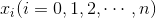
是每个样本的特征序列。如果假设
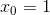
,假设函数可以简化为
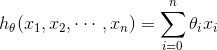
。
对于上述假设函数,我们的损失函数为
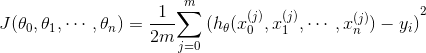
,不难看出,我们是基于最小二乘损失来定义的损失函数,
2. 参数的初始化
所有的参数采用随机初始化。
具体为什么,等到后面讲解多层感知器反向传播的时候,大家就明白了。
3. 梯度下降的算法过程假设我们有样本集
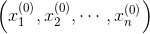
,
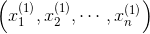
,...,
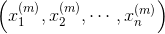
,损失函数为
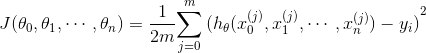
,对于每个参数 的偏导数如下:
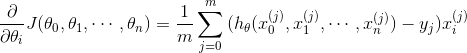
。上式中,所有的
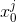
为1.
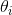
的更新表达式如下:

上式很重要,后面讲解神经网络时,会发现反向传播的根本理论即源于此。
在学习神经网络与机器学习之前,不得不先了解一种迭代方法,那就是梯度下降法。在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。
在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。这些都会在后面讲解。
2. 梯度下降小述
在学习微积分时,对于一个多元函数,当对其中各个元求偏导数,再把求得的偏导数以向量的形式表示出来,这个向量就是梯度。比如一个具有x和y的函数的两元函数
,假设z代表高度,x,y分别代表两个方向,那么
就是的梯度,简称为
或者
。那么在点
处的梯度就是
。
在点
处的梯度
具有什么意义呢?简单的来说,这个梯度就是在点
处变化最快的方向。
3. 梯度下降算法详解
下面就通过图解梯度下降和详细的数学表示两方面来讲解梯度下降。
3.1 图解梯度下降
如下图1.1所示,当我们选定初始点
时,我们通过计算这一点的梯度
,来找到下降最快的方向,从而得到新的点
,此处的“+”号,并不是代表相加得到,而是代表“更快”的得到最小值。通过迭代,最终找到点
,当前点即是最小值点。
图1.1 梯度下降
3.2 梯度下降的几个概念
在详细的讲解梯度下降算法以前,有必要先了解几个有关的概念。
1. 步长:步长是指每一次迭代过程后,算法下降的长度。用一个比较典型的例子,假设我们在下山,步长就是在我们确定了最陡的方向后,迈出的那一步的距离。
2. 假设函数:假设函数可认为我们在监督学习中,针对输入的m个样本
,
,所要拟合的函数
,可认为是最重要得到的那个函数。
3. 损失函数:损失函数是为了衡量拟合程度的好与坏,所以通常损失函数为
3.3 梯度下降法的代数表示
梯度下降法有代数法和矩阵法两种表示方法,本文着重对代数法进行讲解。矩阵法表示可参考网络中其他资源。
1. 代数法的假设函数和代价函数
代数法表示梯度下降之前,要明确两个函数,分别是假设函数和代价函数。
假设函数实际上是我们最终所想得到的函数(回归)。对于线性回归来说,假设函数表示为
,其中
为模型参数,也是我们最终所要训练得到的参数。
是每个样本的特征序列。如果假设
,假设函数可以简化为
。
对于上述假设函数,我们的损失函数为
,不难看出,我们是基于最小二乘损失来定义的损失函数,
2. 参数的初始化
所有的参数采用随机初始化。
具体为什么,等到后面讲解多层感知器反向传播的时候,大家就明白了。
3. 梯度下降的算法过程假设我们有样本集
,
,...,
,损失函数为
,对于每个参数 的偏导数如下:
。上式中,所有的
为1.
的更新表达式如下:
上式很重要,后面讲解神经网络时,会发现反向传播的根本理论即源于此。

相关文章推荐
- 第一讲.Liner_Regression and Gradient_Descent(Rui Xia) 单变量线性回归及梯度下降
- 梯度算法之梯度上升和梯度下降
- 逻辑回归代价函数及其梯度下降公式
- 梯度下降法
- 在梯度下降法中,为什么梯度的负方向是函数下降最快的方向?
- 梯度下降法和牛顿法的简单对比
- 逻辑回归梯度下降法详解
- 数学优化入门:梯度下降法、牛顿法、共轭梯度法
- 机器学习中最小二乘和梯度下降法的个人理解
- Adaptive linear neurons model 线性神经元 运用梯度下降法 进行代价函数的最优化
- l线性回归,梯度下降和正规方程
- 梯度下降法(一)入门
- 梯度下降法实现(step-by-step)
- 感知器与梯度下降
- 机器学习第一篇(stanford大学公开课学习笔记) —机器学习的概念和梯度下降
- 参数学习算法之梯度下降
- 机器学习入门:线性回归及梯度下降
- Machine Learning - Gradient Descent (梯度下降)
- Machine Learning - Gradient Descent (梯度下降)
- 随机梯度下降法和批量梯度下降法