基于3D卷积神经网络的行为识别:3D Convolutional Neural Networks for Human Action Recognition
2018-03-05 21:09
489 查看
Original url: http://www.cnblogs.com/Ponys/p/3450177.html

简介:这是一片发表在TPAMI上的文章,可以看见作者有余凯(是百度的那个余凯吗?)本文提出了一种3D神经网络:通过在神经网络的输入中增加时间这个维度(连续帧),赋予神经网络行为识别的功能。相应提出了一种3D卷积,对三幅连续帧用一个3D卷积核进行卷积(可以理解为用三个二维卷积核卷积三张图)。 3D神经网络结构图:
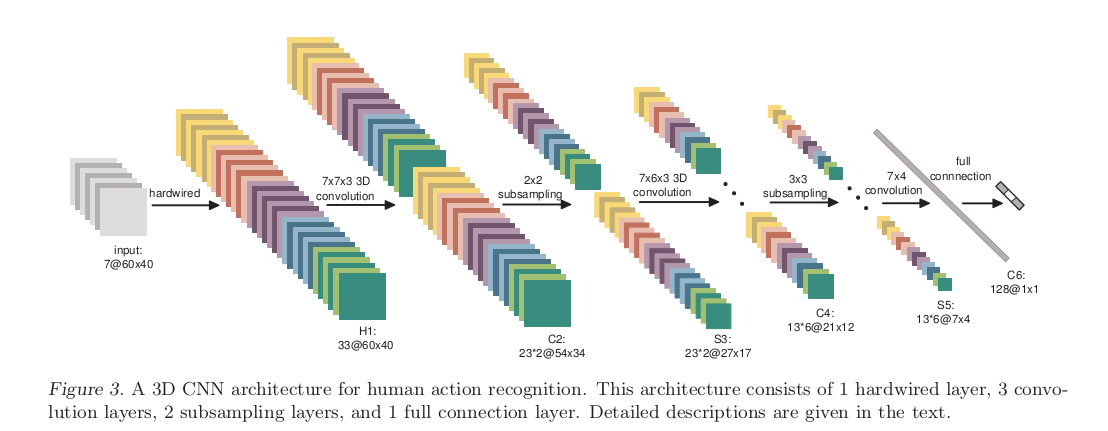
input—>H1 神经网络的输入为7张大小为60*40的连续帧,7张帧通过事先设定硬核(hardwired kernels)获得5种不同特征:灰度、x方向梯度、y方向梯度、x方向光流、y方向光流,5个channels一共33个maps。对于这个做法,原文这么解释“相比于随机初始化,通过先验知识对图像的特征提取使得反向传播训练有更好的表现”。对此我的理解是,梯度表征了图像的边沿的分布,而光流则表征物体运动的趋势,3DCNN通过提取这两种信息来进行行为识别。H1—>C2 用两个7*7*3的3D卷积核对5个channels分别进行卷积,获得两个系列,每个系列5个channels共23个maps。然后为卷积结果加上偏置套一个tanh函数进行输出。(典型神经网。)

卷积后map大小为54*34.C2—>S3 2x2池化,下采样S3—>C4 为了提取更多的图像特征,用三个7*6*3的3D卷积核分别对各个系列各个channels进行卷积,获得6个系列,每个系列依旧5个channels的大量maps。然后加偏置套tanh。C4—>S53X3池化,下采样。S5—>C6 进行了两次3D卷积之后,时间上的维数已经被压缩得无法再次进行3D卷积(两个光流channels只有两个maps)。此时对各个maps用7*42D卷积核进行卷积,加偏置套tanh(烦死了!),获得C6层。C6层维度已经相当小,flatten为一列有128个节点的神经网络层。C6—>output 经典神经网络模型两层之间全链接,output的节点数目随标签而定。 相关概念——3D卷积:老师说:“看图说话”,上图:
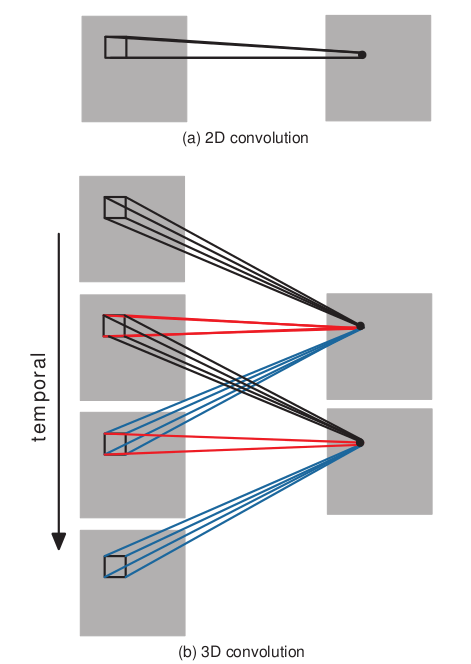
3D卷积可以理解为为想领的3幅图用3个不同卷积核进行卷积,并把卷积结果相加。可以这么说,通过这种3幅图之间的卷积,网络提取了时间之间某种的相关性。

训练: 同CNN,本网络使用典型的随机初始化——反向传播算法进行训练。反向传播的算法在NN中的实现以前已经说过,请翻博文。不知到CNN中会不会有改进,具体方法以后贴一CNN论文出来。 效果: 使用3DCNN对3个标签的veido(CellToEar, ObjectPut, Pointing)进行行为识别,效果与其他三种行为识别方法进行对比。发现在前两中标签下效果怒好与其他方法,Pointing则略逊。
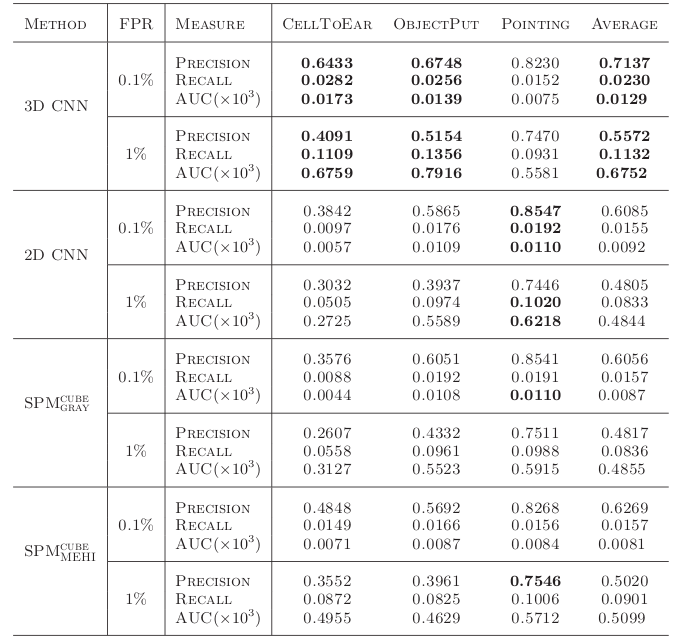
MORE:在与其他方法进行对比的时候作者积极歪歪了各种特征我不知道他在说什么。另外,作者以后可能回访出DBN版本的行为识别,或非监督版本的3DCNN。 我学完UFLDL之后就整天想3帧放在一起学习能不能行为识别啊有木有!但是多帧大图片使用普通NN的话参数过多不实用,CNN则用局部链接+池化很好的解决了参数过多这个问题。本文作者对CNN在时间维度上进行扩充,实现了一个行为识别的功能,实乃快人一步。实际效果还得见同行评议(不知到老师的实验室搞不搞)。 从这篇论文看出,目前的DL研究方法仍然十分Tricky,网络的搭建和参数的选择很大程度上依赖直觉与实验,这个就比较考研研究人员的天赋 与……………………资源了。不知到什么时候才能有系统的NN设计方法出来。(还是已经有了我不知道?)
简介:这是一片发表在TPAMI上的文章,可以看见作者有余凯(是百度的那个余凯吗?)本文提出了一种3D神经网络:通过在神经网络的输入中增加时间这个维度(连续帧),赋予神经网络行为识别的功能。相应提出了一种3D卷积,对三幅连续帧用一个3D卷积核进行卷积(可以理解为用三个二维卷积核卷积三张图)。 3D神经网络结构图:
input—>H1 神经网络的输入为7张大小为60*40的连续帧,7张帧通过事先设定硬核(hardwired kernels)获得5种不同特征:灰度、x方向梯度、y方向梯度、x方向光流、y方向光流,5个channels一共33个maps。对于这个做法,原文这么解释“相比于随机初始化,通过先验知识对图像的特征提取使得反向传播训练有更好的表现”。对此我的理解是,梯度表征了图像的边沿的分布,而光流则表征物体运动的趋势,3DCNN通过提取这两种信息来进行行为识别。H1—>C2 用两个7*7*3的3D卷积核对5个channels分别进行卷积,获得两个系列,每个系列5个channels共23个maps。然后为卷积结果加上偏置套一个tanh函数进行输出。(典型神经网。)
卷积后map大小为54*34.C2—>S3 2x2池化,下采样S3—>C4 为了提取更多的图像特征,用三个7*6*3的3D卷积核分别对各个系列各个channels进行卷积,获得6个系列,每个系列依旧5个channels的大量maps。然后加偏置套tanh。C4—>S53X3池化,下采样。S5—>C6 进行了两次3D卷积之后,时间上的维数已经被压缩得无法再次进行3D卷积(两个光流channels只有两个maps)。此时对各个maps用7*42D卷积核进行卷积,加偏置套tanh(烦死了!),获得C6层。C6层维度已经相当小,flatten为一列有128个节点的神经网络层。C6—>output 经典神经网络模型两层之间全链接,output的节点数目随标签而定。 相关概念——3D卷积:老师说:“看图说话”,上图:
3D卷积可以理解为为想领的3幅图用3个不同卷积核进行卷积,并把卷积结果相加。可以这么说,通过这种3幅图之间的卷积,网络提取了时间之间某种的相关性。
训练: 同CNN,本网络使用典型的随机初始化——反向传播算法进行训练。反向传播的算法在NN中的实现以前已经说过,请翻博文。不知到CNN中会不会有改进,具体方法以后贴一CNN论文出来。 效果: 使用3DCNN对3个标签的veido(CellToEar, ObjectPut, Pointing)进行行为识别,效果与其他三种行为识别方法进行对比。发现在前两中标签下效果怒好与其他方法,Pointing则略逊。
MORE:在与其他方法进行对比的时候作者积极歪歪了各种特征我不知道他在说什么。另外,作者以后可能回访出DBN版本的行为识别,或非监督版本的3DCNN。 我学完UFLDL之后就整天想3帧放在一起学习能不能行为识别啊有木有!但是多帧大图片使用普通NN的话参数过多不实用,CNN则用局部链接+池化很好的解决了参数过多这个问题。本文作者对CNN在时间维度上进行扩充,实现了一个行为识别的功能,实乃快人一步。实际效果还得见同行评议(不知到老师的实验室搞不搞)。 从这篇论文看出,目前的DL研究方法仍然十分Tricky,网络的搭建和参数的选择很大程度上依赖直觉与实验,这个就比较考研研究人员的天赋 与……………………资源了。不知到什么时候才能有系统的NN设计方法出来。(还是已经有了我不知道?)

相关文章推荐
- 基于3D卷积神经网络的行为识别:3D Convolutional Neural Networks for Human Action Recognition
- 基于3D卷积神经网络的行为识别:3D Convolutional Neural Networks for Human Action Recognition
- 【论文学习】3D Convolutional Neural Networks for Human Action Recognition
- 3D Convolutional Neural Networks for Human Action Recognition
- 《3D Convolutional Neural Networks for Human Action Recognition》论文阅读笔记
- 深度学习文章阅读2--3D Convolutional Neural Networks for Human Action Recognition
- 3D Convolutional Neural Networks for Human Action Recognition
- 【论文笔记】Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
- Convolutional Neural Networks for Visual Recognition
- End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for Human
- READING NOTE: Two-Stream Convolutional Networks for Action Recognition in Videos
- Two-Stream Convolutional Networks for Action Recognition in Videos
- Convolutional Neural Networks for Visual Recognition 7
- [深度学习论文笔记][Video Classification] Two-Stream Convolutional Networks for Action Recognition in Videos
- Convolutional Neural Networks for Visual Recognition
- Two-Stream Convolutional Networks for Action Recognition in Video
- CS231n: Convolutional Neural Networks for Visual Recognition
- 斯坦福CS231n课程: 视觉识别中的卷积神经网络 Convolutional Neural Networks for Visual Recognition
- Convolutional Neural Networks for Visual Recognition 8
- Convolutional Neural Networks for Visual Recognition