kmp算法(C语言)
2018-03-05 20:11
302 查看
查了好多资料,终于知道kmp算法的意思了。
定义 Knuth-Morris-Pratt 字符串查找算法,简称为 “KMP算法”,常用于在一个文本串S内查找一个模式串P 的出现位置,这个算法由Donald Knuth、Vaughan Pratt、James H. Morris三人于1977年联合发表,故取这3人的姓氏命名此算法。
一般算法
下面是两个字符串char str[80] = "bacbababadababacambabacaddababacasdsd";
char subStr[80] = "ababaca";
求subStr在str的第几个为值,
假设str有n个字符,subStr有m个字符,(n >= m),如果最用效率最低的方法是,根据str的每一个字符到后面的m个字符长度之间的字符与subStr字符进行挨个比较,如果其中有不一样的就会进行,将str的那个第一个比较的字符往后移一位,进行下次比较,循环主串,直到结束。
KMP算法一般算法,是主串的每个字符进行匹配,如果存在一种,减少主串的匹配次数,效率就会极大的提高。
这就要根据子串的结构特性进行减少匹配次数。
具体的思想是下图。
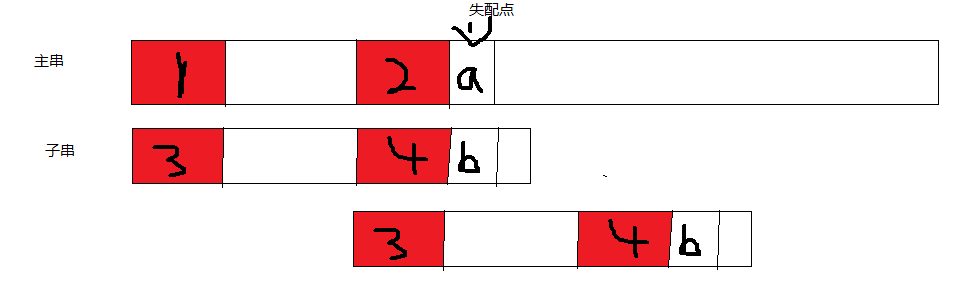
长的是主串,短的部分是子串,
当匹配的时候,失配点处之前的字符都相同,如果他们存在一种前端的最长字符串与末端的最长字符串相同,
如图
1区字符串 == 2区的字符串 3区字符串 == 4区字符串,1区 == 3区, 2区 == 4区,于是可以推出,2区 == 3区,
于是2区与3区就不用比较,
子串会移动一段距离 (移动的距离 = 前面相同字符串的个数 - 最长前后端的同的字符个数)
比如子串“ababaca”,0001230,前两位默认为0,第3位前面“ab”有0个,“aba”有1个,“abab”有两个,“ababa”有3个,“ababac”有0个int* getNext(char *subStr){
int *next = (int *)calloc(sizeof(int), strlen(subStr));
int i;
int j;
int k;
int strLen = strlen(subStr);
for(i = 2;i < strLen; i++){
j = 1;
k = 0;
while(j < i){
if(subStr[k] == subStr[j]){
k++;
j++;
}else{
j++;
if(subStr[k] != subStr[j]){
k = 0;
}
}
}
next[i] = k;
}
return next;
}
匹配
时间复杂度
O(m+n)
定义 Knuth-Morris-Pratt 字符串查找算法,简称为 “KMP算法”,常用于在一个文本串S内查找一个模式串P 的出现位置,这个算法由Donald Knuth、Vaughan Pratt、James H. Morris三人于1977年联合发表,故取这3人的姓氏命名此算法。
一般算法
下面是两个字符串char str[80] = "bacbababadababacambabacaddababacasdsd";
char subStr[80] = "ababaca";
求subStr在str的第几个为值,
假设str有n个字符,subStr有m个字符,(n >= m),如果最用效率最低的方法是,根据str的每一个字符到后面的m个字符长度之间的字符与subStr字符进行挨个比较,如果其中有不一样的就会进行,将str的那个第一个比较的字符往后移一位,进行下次比较,循环主串,直到结束。
KMP算法一般算法,是主串的每个字符进行匹配,如果存在一种,减少主串的匹配次数,效率就会极大的提高。
这就要根据子串的结构特性进行减少匹配次数。
具体的思想是下图。
长的是主串,短的部分是子串,
当匹配的时候,失配点处之前的字符都相同,如果他们存在一种前端的最长字符串与末端的最长字符串相同,
如图
1区字符串 == 2区的字符串 3区字符串 == 4区字符串,1区 == 3区, 2区 == 4区,于是可以推出,2区 == 3区,
于是2区与3区就不用比较,
子串会移动一段距离 (移动的距离 = 前面相同字符串的个数 - 最长前后端的同的字符个数)
next数组
是为了求子串上的每一个字符前面前端的最长字符串=末端的最长字符串的个数,说的有些模糊,比如子串“ababaca”,0001230,前两位默认为0,第3位前面“ab”有0个,“aba”有1个,“abab”有两个,“ababa”有3个,“ababac”有0个int* getNext(char *subStr){
int *next = (int *)calloc(sizeof(int), strlen(subStr));
int i;
int j;
int k;
int strLen = strlen(subStr);
for(i = 2;i < strLen; i++){
j = 1;
k = 0;
while(j < i){
if(subStr[k] == subStr[j]){
k++;
j++;
}else{
j++;
if(subStr[k] != subStr[j]){
k = 0;
}
}
}
next[i] = k;
}
return next;
}
匹配
int KMP(char *str, char *subStr){
int subStrLen = strlen(subStr);
int strLen = strlen(str);
int *next = getNext(subStr);
int i = 0;
int j = 0;
while(str[i]){
while(subStr[j] != 0 && str[i+j] == subStr[j]){
j++;
}
if(subStr[j] == 0){
return i;
}
if(j == 0){
i++;
}else{
i = i + j - next[j];
}
j = next[j];
}
return -1;
}时间复杂度
O(m+n)

相关文章推荐
- [C语言]KMP算法
- KMP算法--c语言实现
- KMP算法与朴素模式匹配算法(C语言)
- KMP算法(C语言)
- C语言KMP算法的实现
- KMP算法--C语言
- KMP算法--c语言源代码
- KMP算法的C语言实现
- KMP算法的C语言实现
- C语言-字符串匹配-KMP算法及next数组求解和运用实例
- KMP算法(Knuth-Morris-Pratt Algorithm)的C语言实现加注释
- C语言快速模式匹配(KMP算法)
- kmp算法字符串匹配C语言实现
- KMP算法C语言的实现
- C语言数据结构KMP算法实现模式串主串匹配(数据结构第三次试验)
- kmp算法详解 c语言
- KMP算法的C语言实现
- c语言中使用BF-KMP算法实例
- C语言实现字符串匹配KMP算法
- KMP算法的C语言实现