logstash input output filter 插件总结
2018-03-05 16:06
971 查看
Logstash学习记录
官方文档logstash2.3 document:https://www.elastic.co/guide/en/logstash/current/index.html一:什么是Logstash
1. logstash 是什么?
Logstash 是有管道输送能力的开源数据收集引擎。它可以动态地从分散的数据源收集数据,并且标准化数据输送到你选择的目的地。它是一款日志而不仅限于日志的搜集处理框架,将分散多样的数据搜集自定义处理并输出到指定位置。2.工作原理
Logstash使用管道方式进行日志的搜集处理和输出。有点类似*NIX系统的管道命令 xxx | ccc | ddd,xxx执行完了会执行ccc,然后执行ddd。在logstash中,包括了三个阶段: 输入input --> 处理filter(不是必须的) --> 输出output[插入]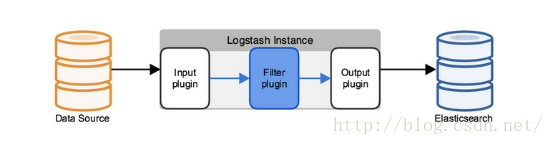
每个阶段都由很多的插件配合工作,比如file、elasticsearch、redis等等。每个阶段也可以指定多种方式,比如输出既可以输出到elasticsearch中,也可以指定到stdout在控制台打印。由于这种插件式的组织方式,使得logstash变得易于扩展和定制。
3.运行logstash
Logstash运行仅仅依赖java运行环境(jre)若logstash的安装目录在${logstashHome},进入安装目录可在控制台输入命令:bin/logstash -e 'input { stdin { } } output { stdout {} }'我们现在可以在命令行下输入一些字符,然后我们将看到logstash的输出内容:hello world2013-11-21T01:22:14.405+0000 0.0.0.0 hello world使用-e参数在命令行中指定配置是很一种方式,不过如果需要配置更多设置则需要很长的内容。这种情况,我们首先创建一个配置文件,并且指定logstash使用这个配置文件。标准配置为文件含有input{} filter{}和output{}三部分,如配置一个配置文件sampl.confinput { file { path => "/path/to/logstash-tutorial.log" start_position => beginning ignore_older => 0 }} filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}"} }} output{ elasticsearch {hosts=>localhost:9020} Stdout{Codec=>”rubydebug” }} /path/to/是配置文件在你的文件系统的具体位置logstash-tutorial.log为Apache日志内容如下:83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/images/kibana-search.pngHTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; IntelMac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36" 在命令行输入:bin/logstash -f first-pipeline.conf --configtest查证配置文件有无错误然后运行logstash调用配置文件bin/logstash -f first-pipeline.conf 在命令行有输出JSON格式:{"clientip" : "83.149.9.216","ident" : ,"auth" : ,"timestamp" : "04/Jan/2015:05:13:42 +0000","verb" : "GET","request" :"/presentations/logstash-monitorama-2013/images/kibana-search.png","httpversion" : "HTTP/1.1","response" : "200","bytes" : "203023","referrer" :"http://semicomplete.com/presentations/logstash-monitorama-2013/","agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"} 命令行参数Logstash 提供了一个 shell 脚本叫 logstash 方便快速运行。它支持一下参数: -e意即执行。我们在 "Hello World" 的时候已经用过这个参数了。事实上你可以不写任何具体配置,直接运行bin/logstash -e '' 达到相同效果。这个参数的默认值是下面这样:input { stdin { }}output { stdout { }}--config 或 -f意即文件。真实运用中,我们会写很长的配置,甚至可能超过 shell 所能支持的 1024 个字符长度。所以我们必把配置固化到文件里,然后通过 bin/logstash -f agent.conf 这样的形式来运行。此外,logstash 还提供一个方便我们规划和书写配置的小功能。你可以直接用 bin/logstash -f /etc/logstash.d/ 来运行。logstash 会自动读取 /etc/logstash.d/ 目录下所有的文本文件,然后在自己内存里拼接成一个完整的大配置文件,再去执行。--configtest 或 -t意即测试。用来测试 Logstash 读取到的配置文件语法是否能正常解析。Logstash 配置语法是用 grammar.treetop定义的。尤其是使用了上一条提到的读取目录方式的读者,尤其要提前测试。--log 或 -l意即日志。Logstash 默认输出日志到标准错误。生产环境下你可以通过 bin/logstash -l logs/logstash.log 命令来统一存储日志。 --filterworkers 或 -w意即工作线程。Logstash 会运行多个线程。你可以用 bin/logstash -w 5 这样的方式强制 Logstash 为过滤插件运行5 个线程。注意:Logstash目前还不支持输入插件的多线程。而输出插件的多线程需要在配置内部设置,这个命令行参数只是用来设置过滤插件的!提示:Logstash 目前不支持对过滤器线程的监测管理。如果 filterworker 挂掉,Logstash 会处于一个无 filter 的僵死状态。这种情况在使用 filter/ruby 自己写代码时非常需要注意,很容易碰上 NoMethodError: undefined method '*' for nil:NilClass 错误。需要妥善处理,提前判断。 --pluginpath 或 -P可以写自己的插件,然后用 bin/logstash --pluginpath /path/to/own/plugins 加载它们。--verbose输出一定的调试日志。小贴士:如果你使用的 Logstash 版本低于 1.3.0,你只能用 bin/logstash -v 来代替。 --debug输出更多的调试日志。小贴士:如果你使用的 Logstash 版本低于 1.3.0,你只能用 bin/logstash -vv 来代替CTRL-D 退出运行中的logstashshell二:配置logstash
创建配置文件,在配置文件的各个部分(input,filter,output)制定并配置你要使用的插件1. 数据类型
Logstash 支持少量的数据值类型: booldebug => true stringhost => "hostname" numberport => 514 arraymatch => ["datetime", "UNIX", "ISO8601"] hashoptions => { key1 => "value1", key2 => "value2"}ü2事件依赖配置
1. Filed references ,sprintf format, conditionals 作用在filter和output阶段Filed reference 是filed嵌套,如下面事件{ "agent": "Mozilla/5.0 (compatible; MSIE 9.0)", "ip": "192.168.24.44", "request": "/index.html" "response": { "status": 200, "bytes": 52353 }, "ua": { "os": "Windows 7" } }你可以定义[ua][os]来引用os字段Sprintf format (1) 根据appache日志状态码计数output { statsd { increment => "apache.%{[response][status]}" } } (2)output { file { path => "/var/log/%{type}.%{+yyyy.MM.dd.HH}" } }Conditional 在某种特定条件下过滤,输出event(if ,else if,else 可以嵌套)comparison operators比较操作: equality: ==, !=, <, >, <=, >= regexp: =~, !~ (checks a pattern on the right against a string value on the left) inclusion: in, not inboolean operators布尔操作: and, or, nand, xor一元操作: !
仅让grok成功的字段索引到elasticsearch中 output { if "_grokparsefailure" not in [tags] { elasticsearch { ... } } } 2. @matedata字段 在output阶段不作为event的一部分输出,可以很好的作为条件判断,或是利用字段引用(filed reference)和sprintf format 来扩展或是创建字段

如果要显示输出@matedata可设置stdout { codec => rubydebug { metadata => true } } Similarly, you can use conditionals to direct events to particular outputs. For example, you could:l alert nagios of any apache events with status 5xxl record any 4xx status to Elasticsearchl record all status code hits via statsdTo tell nagios about any http event that has a 5xx status code, you first need to check the value of the typefield. If it’s apache, then you can check to see if the status field contains a 5xx error. If it is, send it to nagios. If it isn’t a 5xx error, check to see if the status field contains a 4xx error. If so, send it to Elasticsearch. Finally, send all apache status codes to statsd no matter what the status field contains:output { if [type] == "apache" { if [status] =~ /^5\d\d/ { nagios { ... } } else if [status] =~ /^4\d\d/ { elasticsearch { ... } } statsd { increment => "apache.%{status}" } }}
4.input plugins
l Input-file-pluginPath=>”/var/log/*” 作为输入的文件的完全路径Excude =>”*.gz” 不用匹配的文件,非=完全路径ignore_older => 86400 (s)时间间隔最后被修改的被忽略max_open_files => numberadd_field=> {} hash值, eg:add_field => {“addfield”=>”content”}close =>”plain”delimiter=> “\n” 默认值,定界符discover_interval => 15(s) 每隔多久在文件路径模式下发现新的文件 (interval 时间间隔)sincedb_path 默认$HOME/.sincedb ,将被写入硬盘的sincedb_database文件的路径,默认是匹配$HOME/.sincedb*的路径sincedb_write_interval =>15(s)多久将被监控日志文件的当前位置写一个since database 一次start_position => “end” 还可”beginning” 从哪开始读取文件,仅当文件是新建的或是从前没见过的,否则失效 start_interval => 设置多久看一次文件是否修改,有新的日志行,tags =>”arrary ” 添加时间tag 可任意多的type => “string ”为input 控制的所有事件添加一个type 的字段, 在filter操作会用到该字段 l Input-stdin-plugin是 logstash 里最简单和基础的插件
l Input-jdbc-pluginschedule:设置监听间隔。可以设置每隔多久监听一次什么的。具体参考官方文statement_filepath: 执行的sql 文件路径+名称数据库的表的一条记录为一个事件下面配置文件监控的是远程数据库,注意的是,MySQL数据库配置是要设为允许远程访问

5.Filter plugins
l Filter-grok-plugin 解析任意文本并且结构化他们。grok目前是logstash中最好的解析非结构化日志并且结构化他们的工具。这个工具非常适合syslog、apache log、mysql log之类的人们可读日志的解析其配置参数如下: add_field => ... # hash (optional), default: {} add_tag => ... # array (optional), default: [] break_on_match => ... # boolean (optional), default: true设为true时grok的第一个成功匹配将结束fliter操作,若想完成所有的匹配应该设为false drop_if_match => ... # boolean (optional), default: false keep_empty_captures => ... # boolean (optional), default: false match => ... # hash (optional), default: {} named_captures_only => ... # boolean (optional), default: true存储时间有命名的捕获 overwrite => ... # array (optional), default: []允许字段重写,字段已经存在用grok匹配的信息重写该字段 grok{ match=>{"message"=>"%{SYSLOGBASE"}%{DATA:message}} Overwrite=>[“message”] #重写message字段 } patterns_dir => ... # array (optional), default: [] remove_field => ... # array (optional), default: [] remove_tag => ... # array (optional), default: [] tag_on_failure => ... # array (optional), default: ["_grokparsefailure"]表示没有成功匹配 l Filter-date-plugin从字段中解析日期,并将这个日期date或timestamp作为事件的@timestamp这个字段在整理事件和回填旧数据是特别有用add-field =>{} remove-field =>[]add-tag =>[]remove-tag =>[]local=>””match=>[“fieldname”,”format” “format”]Format 有多种匹配格式的可能:MMM dd YYYY HH:mm:ss MMM d YYYY HH:mm:ss dd/MMM/yyyy:HH:mm:ss Z ISO8601 (如:2011-04-19T03:44:01.1032)Periodic_flush=>falseTag_on_failure=>[“_datepardefailure”]没有成功匹配是添加字段,此处为默认值Target=>“@timestamp”将匹配的timestamp字段放在指定的字段 默认是@timestamp l Filter-syslog-pluginSyslog对于Logstash是一个很长用的配置,并且它有很好的表现(协议格式符合RFC3164)。Syslog实际上是UNIX的一个网络日志 标准,由客户端发送日志数据到本地文件或者日志服务器。在这个例子中,你根本不用建立syslog实例;我们通过命令行就可以实现一个syslog服务, 通过这个例子你将会看到发生什么。首先,让我们创建一个简单的配置文件来实现logstash+syslog,文件名是 logstash-syslog.confinput { tcp { port => 5000 type => syslog } udp { port => 5000 type => syslog }} filter { if [type] == "syslog" { grok { match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:)?: %{GREEDYDATA:syslog_message}" } add_field => [ "received_at", "%{@timestamp}" ] add_field => [ "received_from", "%{host}" ] } syslog_pri { } date { match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } }} output { elasticsearch { host => localhost } stdout { codec => rubydebug }}
执行logstash:bin/logstash -f logstash-syslog.conf
通常,需要一个客户端链接到Logstash服务器上的5000端口然后发送日志数据。在这个简单的演示中我们简单的使用telnet链接到 logstash服务器发送日志数据(与之前例子中我们在命令行标准输入状态下发送日志数据类似)。首先我们打开一个新的shell窗口,然后输入下面的 命令:telnet localhost 5000你可以复制粘贴下面的样例信息(当然也可以使用其他字符,不过这样可能会被grok filter不能正确的解析):Dec 23 12:11:43 louis postfix/smtpd[31499]: connect from unknown[95.75.93.154]Dec 23 14:42:56 louis named[16000]: client 199.48.164.7#64817: query (cache) 'amsterdamboothuren.com/MX/IN' deniedDec 23 14:30:01 louis CRON[619]: (www-data) CMD (php /usr/share/cacti/site/poller.php >/dev/null 2>/var/log/cacti/poller-error.log)Dec 22 18:28:06 louis rsyslogd: [origin software="rsyslogd" swVersion="4.2.0" x-pid="2253" x-info="http://www.rsyslog.com"] rsyslogd was HUPed, type 'lightweight'.
之后你可以在你之前运行Logstash的窗口中看到输出结果,信息被处理和解析!{ "message" => "Dec 23 14:30:01 louis CRON[619]: (www-data) CMD (php /usr/share/cacti/site/poller.php >/dev/null 2>/var/log/cacti/poller-error.log)", "@timestamp" => "2013-12-23T22:30:01.000Z", "@version" => "1", "type" => "syslog", "host" => "0:0:0:0:0:0:0:1:52617", "syslog_timestamp" => "Dec 23 14:30:01", "syslog_hostname" => "louis", "syslog_program" => "CRON", "syslog_pid" => "619", "syslog_message" => "(www-data) CMD (php /usr/share/cacti/site/poller.php >/dev/null 2>/var/log/cacti/poller-error.log)", "received_at" => "2013-12-23 22:49:22 UTC", "received_from" => "0:0:0:0:0:0:0:1:52617", "syslog_severity_code" => 5, "syslog_facility_code" => 1, "syslog_facility" => "user-level", "syslog_severity" => "notice"} l Filter-mutate-plugin替换重命名移除事件中的字段add_field(hash) ,add_tag(array) ,remove_field(array),remove_tag(array)convert=>{} 改变字段类型,若为array所有将转换eg:convert=> { “field_name” =>”integer”}gsub => { “fieldname”,”/”,”_” } 将fielname字段值中所有”/”替换成 “_” “fieldname2”,”[\\?#-]”,”.” } 将fielname2字段值中所有”\?#-”替换成 “_”Join => {} 将数组用分隔符连接合并起来 “fieldname” =>”,” strip=>[] 去除字段首尾的空白格Lowercase=> [“fieldname”] 将字符串转换后才能小写 uppercase =>[]merge => { } 合并两个字段,array+string 或string+stringremove => [] 移除一个或多个字段, 新版本可能不可用remove_field => {} 如果过滤器成功,从事件移除任意字段,可%{fieldname}remove_tag =>[]rename 重命名一个或多个字段,hash rename=> {“HOSTIP”=>”client_ip”}replace => { } 给字段赋新值, update=> { } 用一个新值更新字段split=> { “fieldname”=>””},通过一个分隔字符将字段分离成一个array,仅string注: mutate在有json插件的情况下要放在json之后,可修改json转换后结构data中的字段 l Filter-geoip-plugin查询IP地址,从中得到物理地址信息并添加到日志中,(该插件配置必须在grok配置后面)指定包含要查询的IP的字段的名称(name)Geoip{ Source=>”clientip” ->包含ip或者主机名,如果是array 只第一个可用}可直接分析一个ip的经纬度,归属地址信息target=>”geoip”将解析得到的字段信息存放到指定字段中database=>”pathofGeoipdatabase” logstash使用的geoip数据库,默认的是GeoLiteCity数据库
l Filter-KV-plugin帮助自动解析message,包含有foo=bar形式的自动解析为foo:bar字段适合像postfix,iptables和其他趋向key=value语法的日志add-field =>{} remove-field =>[]add-tag =>[]remove-tag =>[]source=>“message”tagret=>””periodic-flush=flase/trueallow_duplicate_values=>“true”允许重复key/value对儿 eg:当有两个“from”=me “from”=m设为false 只允许唯一一个default-keys=>{}向事件中添加健值对哈希表,以防source中不包含这些应有的字段exclude-keys=>[]去除事件中不必要的健值对,填keyfield-split=>“”字符串中的一个字符,用以划分出可解析的key-value eg:pin=123&d=123&e=foo则field-split=>“&”include-keys=>[]保留事件中需要的键值,去除剩余的include-brackets=>“true”值不包含括号(有去除)prefix=>“”在所有key前加一个字符串trim=>“”trimkey=>“”去除key=value中的字符 如
<>value -split=>“=”上述操作仅对原event中field有效对default-keys添加的字段无效。

l Filter-multiline -plugin不是线程安全的 不可解决多流信息mulyiline{ type=> pattern=>“”匹配模式 negate=>“false”true=>不匹配的进行what what=>“previous/next”} “^\s”空格开头“\\$”反斜线符source=>“message”allow-dulplicate=>true 允许重复值在event中pattern-dir=>array logstash自带的匹配模式 NUMBER\d+ l Fliter-ruby-plugin执行ruby代码init=>“”在logstash启动时执行的任何代码code=>“”为每个事件执行的代码要有一个指代事件 本身的event变量可用add-field =>{} remove-field =>[]add-tag =>[]remove-tag =>[]periodic-flush=>“false”

l Filter-json-plugin是一个转换过滤插件,对一个包含json字格式数据的字段,可扩展成一个数据结构add-field =>{} remove-field =>[]add-tag =>[]remove-tag =>[]source=>“message” 指定要转换的字段(是Json格式) 默认是message字段tagret=>”” 指定转换后数据的字段

6.output plugins
输出插件统一具有一个参数是 workers。Logstash 为输出做了多线程的准备。l Output-file-plugin与input-file不同 这里可用sprintf format格式自定义输出到文件路径 path=>’’/path/to/configure file/’ message_format=>”%{message}” 默认参 是按json形式输出整个event的数据,设为%{message}是保存按照日志的原始格式保存(前提是filter未修改删除message字段)Worker=>1 output 的worker数目gzip=>false 如果设为true,乱码输出create_if_delete=>true 输出file如果不存在被删除 就自动新建一个Codec=>”json_lines”编码格式 可设为rubydebugl Output-stdout-plugin标准输出插件,直接将处理的数据输出到命令行,是最基础和简单的输出插件Codec=>”json_lines”编码格式 可设为rubydebug 单就 outputs/stdout 插件来说,其最重要和常见的用途就是调试。所以在不太有效的时候,加上命令行参数 -vv 运行,查看更多详细调试信息。
l Output-elasticsearch-plugin将数据输出到elasticsearch存放,方便搜索分析处理hosts=>[host:port] 这部分会专门发一篇博客,最近正在学习
编码插件(Codec)
Codec 是 logstash 从 1.3.0 版开始新引入的概念(Codec 来自 Coder/decoder 两个单词的首字母缩写)。在此之前,logstash 只支持纯文本形式输入,然后以过滤器处理它。但现在,我们可以在输入 期处理不同类型的数据,这全是因为有了 codec 设置。所以,这里需要纠正之前的一个概念。Logstash 不只是一个input | filter | output 的数据流,而是一个 input | decode | filter | encode | output 的数据流!codec 就是用来 decode、encode 事件的。codec 的引入,使得 logstash 可以更好更方便的与其他有自定义数据格式的运维产品共存,比如 graphite、fluent、netflow、collectd,以及使用 msgpack、json、edn 等通用数据格式的其他产品等
相关文章推荐
- Logstash input output filter插件总结
- Logstash学习记录--logstash input output filter 插件总结
- Expected one of #, input, filter, output at line 2, column 1 (byte 2): Logstash
- logstash 中input插件读取的数据没有日期,现在想在filter插件的csv插件中插入以时间字段
- logstash启动报配置文件错误Expected one of #, input, filter, output at line 1, column 1 (byte 1) after
- 基于Metronic的Bootstrap开发框架经验总结(5)--Bootstrap文件上传插件File Input的使用
- bootstrap-fileinput 插件项目总结参考
- Logstash的logstash-input-jdbc插件mysql数据同步ElasticSearch及词库
- logstash-input-log4j 插件使用简介
- logstash安装与logstash-input-jdbc插件使用
- java中的Io(input与output)操作总结(一)
- logstash-input-exec插件使用
- 写程序很难之logstash之file input插件实现分析
- [logstash-input-file]插件使用详解
- 使用CBaseFilter, CBaseInputPin和CBaseOutputPin写一个简单的Filter
- Logstash学习20_[logstash-input-file]插件使用详解
- logstash5.x 常用输入插件 input-plugins
- Logstash之Logstash inputs(file和redis插件)、Logstash outputs(elasticsearch 和redis插件)和Filter plugins
- logstash-5.5.3离线安装logstash-input-jdbc插件
- [logstash-input-redis]插件使用详解