C语言拾遗——链表
2018-03-04 21:38
197 查看
C语言拾遗——链表
本篇主要讲述链表的创建,增、删、改、查、反逆、排序等操作。链表是一种常见的重要的数据结构;它是动态地进行存储分配的一种结构.每一个节点包含两部分,数据和指向下一个节点地址的指针,各节点之间的地址不连续是链表不同于数组的最大特性。
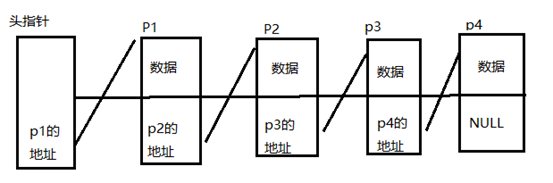
简单链表:
s
truct Student
{ int num;
float score;
struct Student *next;
}a,b,c; //建立一个简单链表,它由3个学生数据的结点组成所谓建立动态链表是指在程序执行过程中从无到有地建立起一个链表,即一个一个地开辟结点和输入各结点数据,并建立起前后相链的关系。链表的建立一般是指先建立一个空链表,而后一个个地将元素插在队尾。
一、C语言实现创建链表代码
#include<stdio.h>
#include<stdlib.h>
struct student
{
int num;
float score;
struct student *pNext;
};
typedef struct student ST; //简写结构体声明
//添加链表元素,先建立一个空链表,而后一个个地将元素插在队尾。
void add(ST **phead, int inum, float iscore)
{
if (*phead == NULL) //判断链表是否为空
{
ST *newnode = (ST *)malloc(sizeof(ST)); //分配内存
if (newnode==NULL)
{
printf("内存分配失败");
return;
}
newnode->num = inum; //节点初始化
newnode->score = iscore;
newnode->pNext = NULL;
*phead=newnode; //让头指针指向这个节点
}
else //链表不为空,尾部插入的方式
{
ST *p = *phead; //指向头节点
while (p->pNext != NULL) //循环到最后一个节点的地址
{
p = p->pNext; //不断循环向前
}
ST *newnode = (ST *)malloc(sizeof(ST)); //分配内存
if (newnode == NULL)
{
printf("内存分配失败");
return;
}
newnode->num = inum; //节点初始化
newnode->score = iscore;
newnode->pNext = NULL;
p->pNext = newnode; //链接上
}
}
//显示链表元素
void showall(ST *head)
{
ST *pb = head;
while (pb != NULL)
{
printf("\n%d,%f", pb->num, pb->score);
printf(" %p,%p ", pb, pb->pNext); //打印两个节点的地址
pb = pb->pNext; //指针不断向前循环
}
}
void main()
{
struct student *head = NULL; //头节点指针
add(&head, 1, 70);
add(&head, 2, 80);
add(&head, 3, 90);
add(&head, 4, 100);
showall(head);
//也可以通过下面这种方式来访问
printf("\n%d,%f", head->num, head->score);
printf("\n%d,%f", head->pNext->num, head->pNext->score);
printf("\n%d,%f", head->pNext->pNext->num, head->pNext->pNext->score);
system("pause");
}二、查找链表元素
类似数组操作,传入链表头指针,进行比对,没有找到就不停的向前移动,直到队尾。
ST * search(ST *head, int num) //根据编号查找结点
{
while (head != NULL)
{
if (num == head->num)
{
return head;
}
head = head->pNext; // 指针不断向前循环
}
return NU
4000
LL; //返回为空
}
void main()
{
struct student *head = NULL; //头节点指针
add(&head, 1, 70);
add(&head, 2, 80);
add(&head, 3, 90);
add(&head, 4, 100);
showall(head);
ST *psearch = search(head, 5);
if (psearch == NULL)
{
printf("\n没有找到");
}
else
printf("\n%d,%f", psearch->num, psearch->score); //打印链表指针指向的地址
psearch = search(head, 3);
if (psearch == NULL)
{
printf("\n没有找到");
}
else
printf("\n找到%d,%f", psearch->num, psearch->score); //打印链表指针指向的地址
system("pause");
}三、改变链表元素的值
这个操作建立在查找的基础上,就像数组中修改一个数组元素一样,链表的修改也很简单,找到元素,重新赋值就好了。
void change(ST *head, int oldnum, int newnum) //查找oldnum,修改newnum
{
ST *psearch = search(head, oldnum);
if (psearch == NULL)
{
printf("没有找到");
}
else
{
psearch->num = newnum;
printf("修改成功");
}
}
void main()
{
struct student *head = NULL; //头节点指针
add(&head, 1, 70);
add(&head, 2, 80);
add(&head, 3, 90);
add(&head, 4, 100);
showall(head);
printf("\n改变后\n");
change(head, 3, 33);
showall(head);
system("pause");
}四、插入链表节点
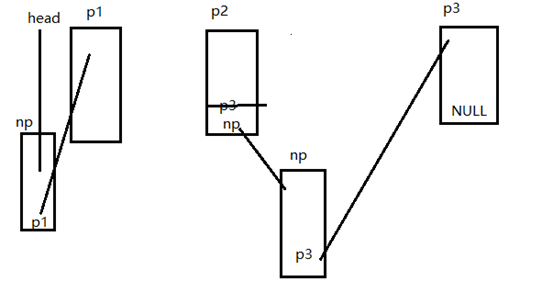
分为两种,在节点之前插入和在节点后面插入两种方式,在节点前面插入,如果在第一个元素p1前插入,那就让np的指向为p1,再让头指针指向要插入的节点np的地址就可以了。如果在中间插入,那就先让np的指向等于px的指向,再让px的指向为np就可以了,如图所示
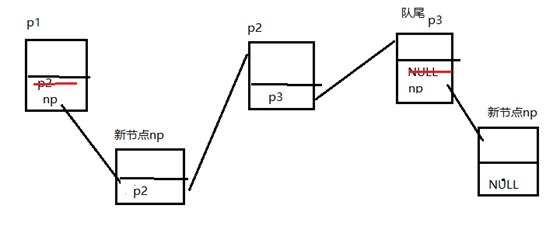
同理在节点后面插入,如果这个节点是最后一个,就把新节点的指向改为NULL,再把最后一个的指向改为新节点的地址,如果在中间插入,就让新节点np的指向要插入节点px的指向,再让px的指向为np就可以了,如图所示
代码如下
ST *Headinset(ST *head, int num, int inum, float iscore) //根据节点,在节点前插入
{
ST*p1, *p2;
p1 = p2 = NULL;
p1 = head;
while (p1 != NULL)
{
if (p1->num == num) //判定相等
{
break;
}
else
{
p2 = p1;
p1 = p1->pNext; //循环到下一个节点
}
}
if (head == p1) //头节点
{
ST* newnode = (ST *)malloc(sizeof(ST)); //分配内存
newnode->num = inum;
newnode->score = iscore;
newnode->pNext = p1; //指向第一个节点
head = newnode; //newnode成为第一个节点
}
else
{
ST* newnode = (ST *)malloc(sizeof(ST)); //分配内存
newnode->num = inum;
newnode->score = iscore;
newnode->pNext = p1; //新节点指向p1
p2->pNext = newnode; //指向新节点
}
return head;
}
ST *Backinset(ST *head, int num, int inum, float iscore) //根据节点,在节点后插入
{
ST*p1, *p2;
p1 = p2 = NULL; //对节点置空
p1 = head;
while (p1 != NULL) //一直循环到最后一个节点
{
if (p1->num == num) //判定相等
{
break;
}
else
{
p2 = p1;
p1 = p1->pNext; //循环到下一个节点
}
}
if (p1->pNext == NULL) //最后一个节点
{
ST* newnode = (ST *)malloc(sizeof(ST)); //分配内存
newnode->num = inum;
newnode->score = iscore;
newnode->pNext = NULL; //指针与此时为空,最后一个节点的指向为NULL
p1->pNext = newnode; //指向新开辟的节点
}
else
{
p2 = p1->pNext; //记录下一个节点的位置
ST* newnode = (ST *)malloc(sizeof(ST)); //分配内存
newnode->num = inum;
newnode->score = iscore;
newnode->pNext = p2; //链接下一个节点
p1->pNext = newnode; //p1指向新节点
}
return head; //没有改变head,卵用不大
}
void main()
{
struct student *head = NULL; //头节点指针
add(&head, 1, 70);
add(&head, 2, 80);
add(&head, 3, 90);
add(&head, 4, 100);
showall(head);
printf("\n从前插入\n");
head = Headinset(head, 2, 5, 76); //在2前面插入5
showall(head);
printf("\n从后插入\n");
head = Backinset(head, 3, 5, 76); //在3后面插入5
showall(head);
system("pause");
}五、删除链表节点
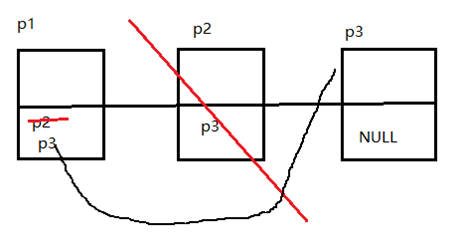
链表节点的删除也比数组简单,找到指定节点p后,让前一个节点p-1的指向改为p的指向,也就是p+1的地址,然后free(p)就完成节点p的删除了。如图
代码如下
ST* delete(ST * head,int num)
{
ST *p1, *p2;
p1 = p2 = NULL;
p1 = head; //从头结点开始循环
while (p1 != NULL)
{
if (p1->num == num) //判断是否相等
{
break; //相等跳出循环
}
else
{
p2 = p1; //记录当前结点
p1 = p1->pNext;
}
}
if (p1 == head)
{
head = p1->pNext; //跳过头节点
free(p1); //释放第一个节点
}
else
{
p2->pNext = p1->pNext; //跳过了p1;
free(p1); //释放节点
}
return head; //返回头节点的值
}
void main()
{
struct student *head = NULL; //头节点指针
add(&head, 1, 70);
add(&head, 2, 80);
add(&head, 3, 90);
add(&head, 4, 100);
showall(head);
printf("\n删除后\n");
delete(head, 3);
showall(head);
system("pause");
}总结:
链表的增加,删除,不需要移动,直接操作。
查询与修改,无法像数组定位位置,需要用循环的方式来定位
下面再说说链表的逆转与排序
链表的逆置,是指“头变尾,尾变头”,将原来的“ABCD……”变成“……DCBA”,先从单链表模型来看 如图所示,链表的逆置实际就是改变结构体中的指针,指向上一个地址即可。
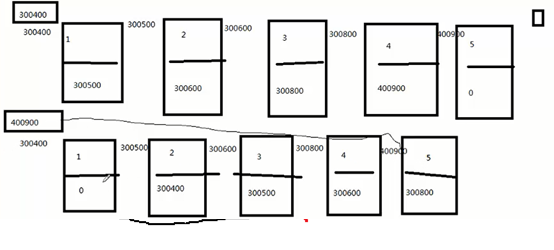
其主要代码如下:
ST *rev(ST *head)
{
ST *p1, *p2, *p3;
p1 = p2 = p3 = NULL;
if (head == NULL || head->pNext == NULL) //如果空链表或者只有一个节点
{
return head; //返回头节点
}
p1 = head;
p2 = head->pNext;
while (p2 != NULL) //从第二个到最后一个节点进行循环
{
p3 = p2->pNext; //布局三个节点
p2->pNext = p1; //指向前面一个节点\
p1 = p2; //指针向前移动,从第二个到最后一个节点全部指向前面的节点
p2 = p3;
}
head->pNext = NULL; //代表链表的结束,设置第一个节点指向为空
head = p1; //当p2=NULL时,p1指向最后一个节点
return head; //副本机制,改变的head,并不会生效,需要返回值赋值
}
void main()
{
struct student *head = NULL; //头节点指针
add(&head, 1, 70);
add(&head, 2, 80);
add(&head, 3, 90);
add(&head, 4, 100);
showall(head);
printf("\n逆转后\n");
head=rev(head); //逆转链表
showall(head);
system("pause");
}链表的排序
由于链表不能随便访问的特性,决定了链表的排序适合冒泡排序法,不适合选择排序等。
我们按照输入的要求实现不同的排序,当输入>时,按照从大到小排序;当输入<时实现从小到大排序。
用冒泡排序链表和进行数组排序的思路一样,两层for循环,外层每循环一次就一个极值沉底,共循环n-1次,内层循环进行相邻节点大小的比较及交换。代码如下
void sort(ST *head, char ch) //ch='>'时,从大到小排序,ch='<'时从小到大排序
{
if (ch == '>') //从大到小排序
{
for (ST *p1 = head;p1 != NULL;p1 = p1->pNext) //外层的循环,只能遍历所有的情况,数组可以规避一些无意义的,链表就要全部刷一遍
{
for (ST *p2 = head;p2 != NULL;p2 = p2->pNext)
{
if (p1->num > p2->num)
{
ST tmp;
tmp.num = p1->num;
p1->num = p2->num;
p2->num = tmp.num;
tmp.score = p1->score;
p1->score = p2->score;
p2->score = tmp.score;
}
}
}
}
else if(ch == '<') //从小到大排序
{
for (ST *p1 = head;p1 != NULL;p1 = p1->pNext)
{
for (ST *p2 = head;p2 != NULL;p2 = p2->pNext)
{
if (p1->num < p2->num)
{
ST tmp;
tmp.num = p1->num;
p1->num = p2->num;
p2->num = tmp.num;
tmp.score = p1->score;
p1->score = p2->score;
p2->score = tmp.score;
}
}
}
}
}
void main()
{
struct student *head = NULL; //头节点指针
add(&head, 1, 70);
add(&head, 2, 80);
add(&head, 3, 90);
add(&head, 4, 100);
showall(head);
printf("\n从大到小排序后\n");
sort(head, '>');
showall(head);
printf("\n小到大排序后\n");
sort(head, '<');
showall(head);
system("pause");
}

相关文章推荐
- 关于C语言链表的学习
- C语言小结之链表
- C语言创建和操作单链表数据结构的实例教程
- C语言的通用链表
- c语言链表,请高手指点
- C语言单向链表的建立
- 「算法精解_C语言描述」 链表_双向链表的实现与分析
- C语言链表与malloc函数
- C语言实现双向循环链表[下]
- 史上最简单的C语言链表实现,没有之一
- c语言-简单学生信息管理(内存链表练习)
- C语言学习之用链表实现通讯录
- C语言循环链表
- 黑马程序员———C语言———【数据结构:单链表】
- C语言 链表 数据结构实验之链表五:单链表的拆分
- 自杀环---约瑟夫环(单链表经典面试题)------>C语言实现
- 链表的c语言实现(四)
- C语言单链表实现19个功能完全详解