梯度下降算法以及与线性回归模型的结合阐述
2018-03-04 17:44
239 查看
梯度下降算法在机器学习领域是非常重要的一个解决问题的方法,目的就是基于历史数据,拟合出一个理想的模型。一、梯度下降算法阐述1.1 梯度下降阐述梯度下降算法是对损失函数(cost function)进行求导,最后目标是获得使损失函数的导数最小或者相对最小的参数值。

具体分析,损失函数 J(θ0,θ1),图形化表示损失函数如图:
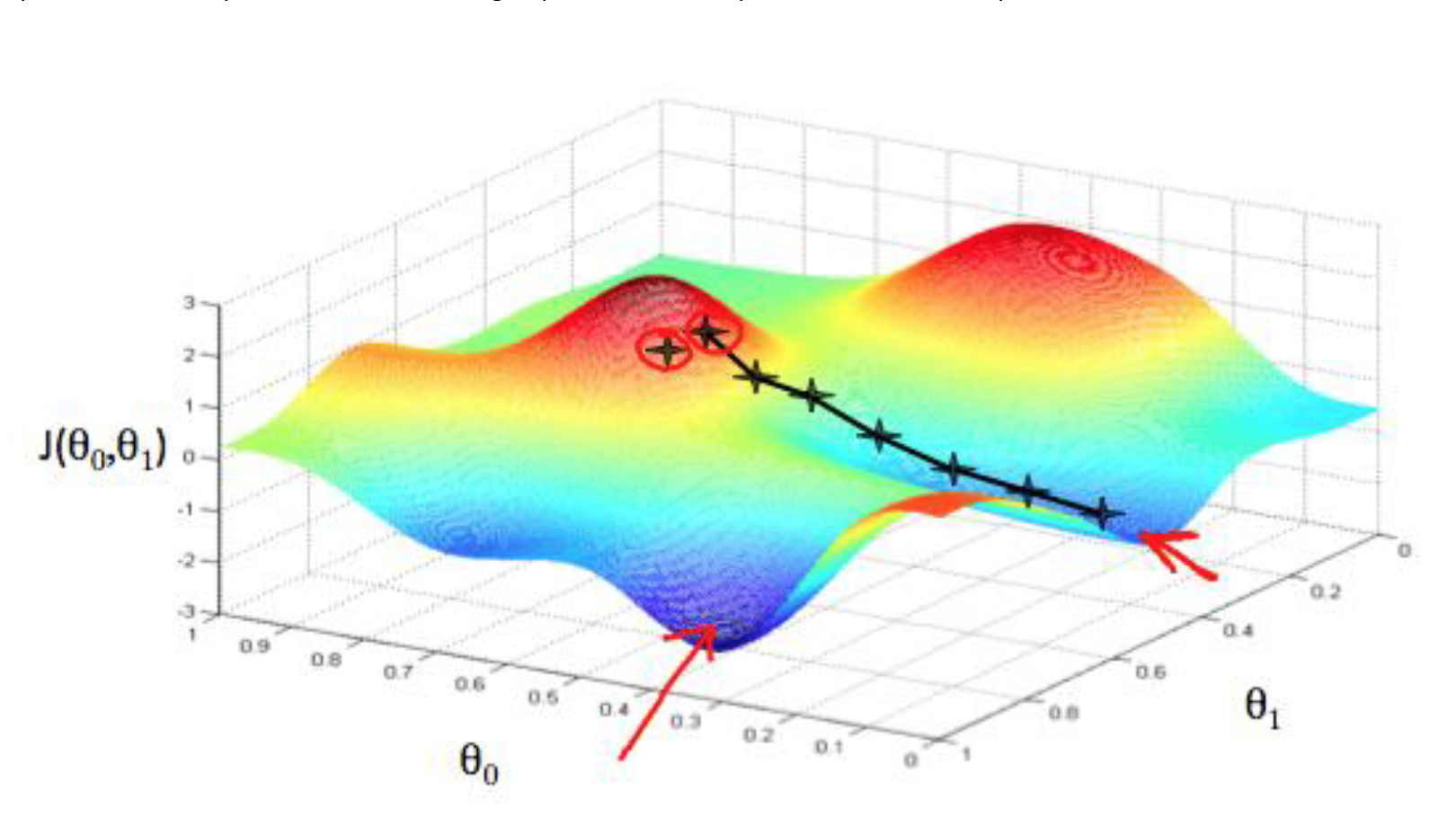
梯度下降算法的目的就是将(θ0,θ1)对应的 J(θ0,θ1)从较高的地方,逐步改变到低谷的 J(θ0,θ1)值,也就是让 J(θ0,θ1)尽可能的小,可以理解成从山上下山,逐渐下到较低或最低的山底。梯度下降算法如下:

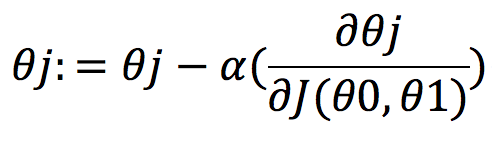
(其中alpha>0, j=0,1)
举个例子:
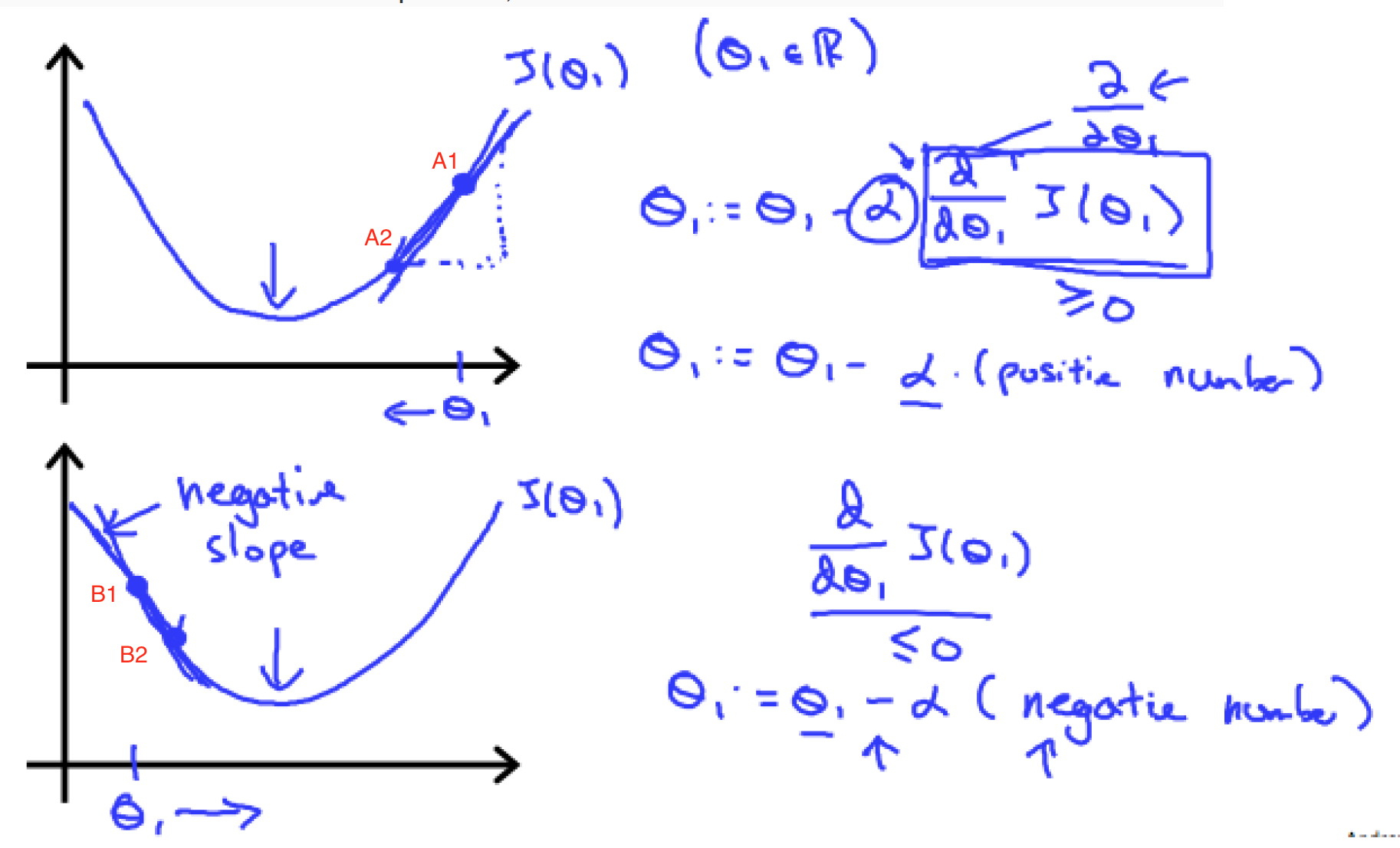
例如损失函数如图所示,alpha>0,如果初始值在A1点,A1点的斜率是正数,那么θ1会往左移动,往更加接近最低点的位置移动。如果初始值处于B1点,斜率为负数,那么θ1会往右移动,也是往更加接近最低点的位置移动。
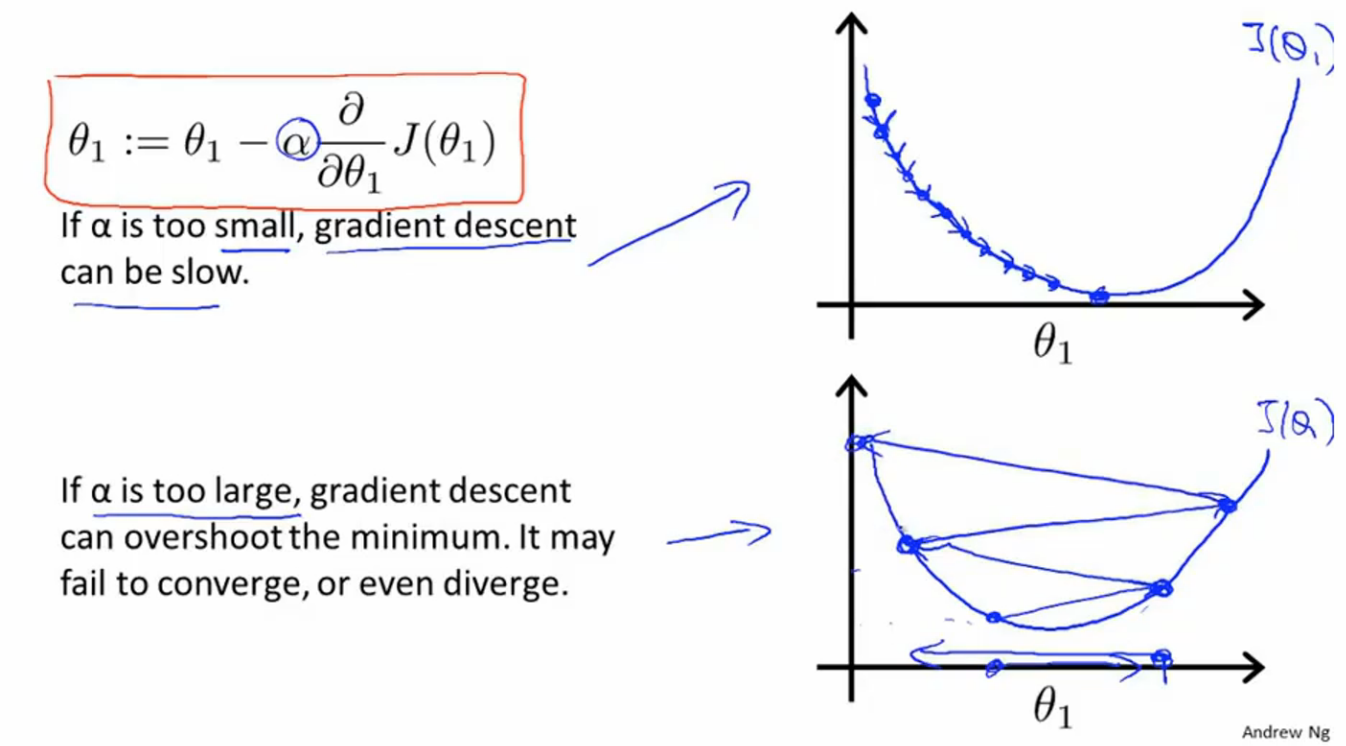
1.2 alpha的作用alpha表示学习速率,直观的表现是影响梯度下降过程中的步长。alpha越大,学习速率越大,收敛越快,alpha越小,学习速率越小,收敛越慢。另外,alpha的值如果过于小,会是学习速率过于慢,影响效率,另外,很容易得出局部最优解的结果。alpha的值过大也会引发另一个问题,导致梯度下降的过程中错过最优解,而导致发散不收敛。
1.3 alpha大小的影响
1.4 收敛速率即使不调节alpha的值,随着梯度下降过程中越来越接近最优点或局部最优点,由于斜率在接近最优点的过程中是逐渐降低的,收敛速率也是逐步降低的。例如,A1的斜率大于A2的斜率,B1的斜率大于B2的斜率。
1.5 局部最优解当cost function如下图所示的时候,很容易求出的θ值是局部最优解。局部最优解的表现是导师为0,达到局部最优解的位置之后,无论怎么进行梯度下降,由于其导数为0,都不会改变θ值。

1.6 θ参数同时更新有一点需要说明,所有θ的更新需要同步进行,不能单独进行,下面对θ的更新进行了比较,一定要谨记。

二、线性回归模型的梯度下降2.1 总体阐述左侧是梯度下降算法,右侧是线性回归模型以及相应的cost function

2.2 梯度下降的算法求解以下就是梯度下降算法的求解过程,一般对微积分和求导有所了解的话,还是比较简单的。

2.3 线性函数的cost function(凸函数)线性回归的cost function是凸函数,所谓的凸函数简单点理解就是一个弓形函数,在梯度下降的时候,只会求出最优解。
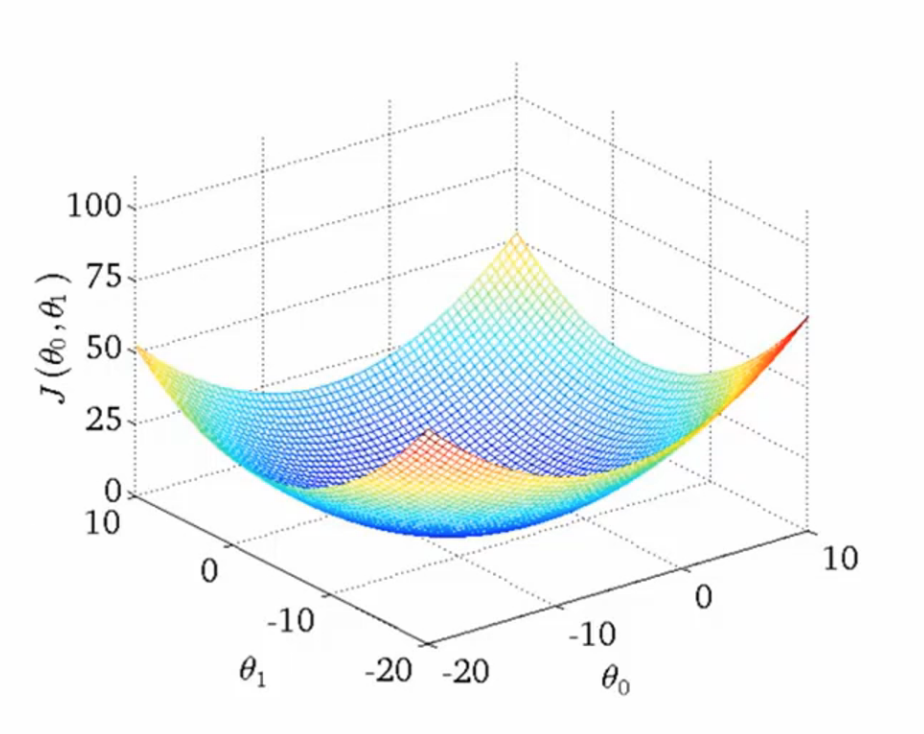
2.4 线性回归模型的梯度下降过程
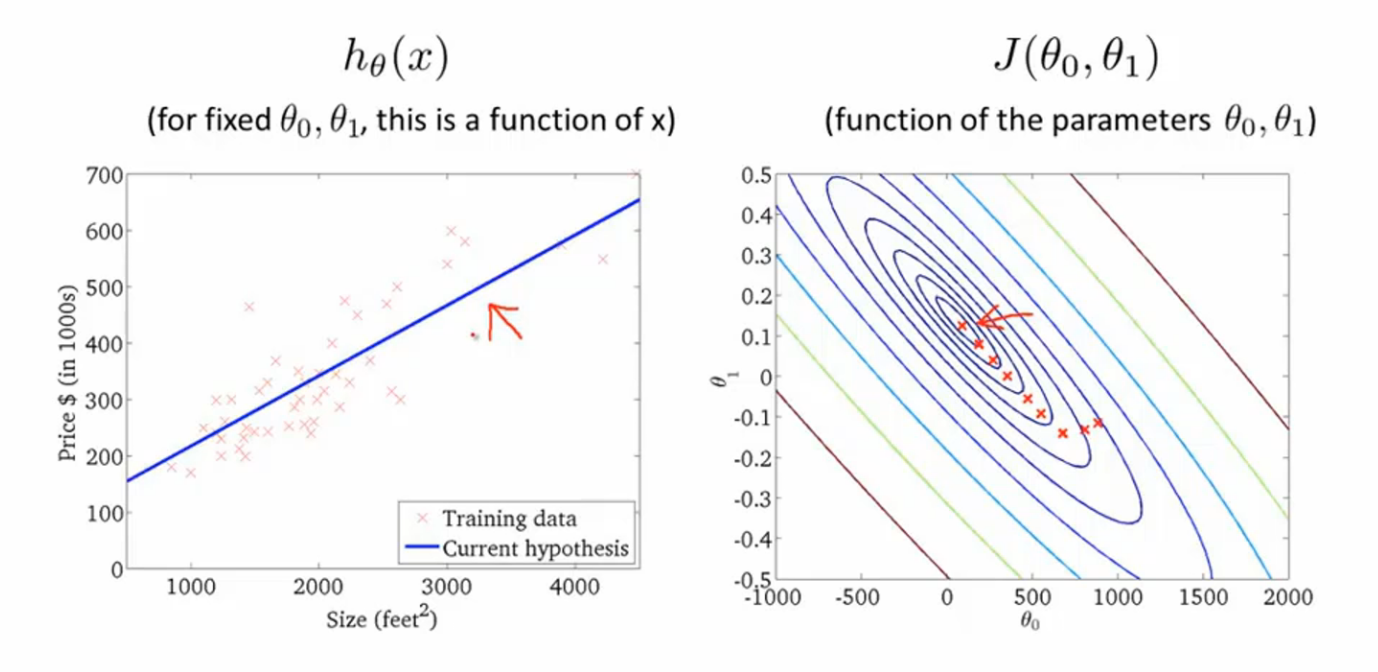
三、总结以上就是针对梯度下降算法,以及结合线性回归模型的梯度下降的算法解释。
欢迎大家关注:数据之下 微信公众号,系统性的分享机器学习、深度学习等方面的知识,不做碎片化学习的牺牲者,要做利用好碎片化时间的受益者。

具体分析,损失函数 J(θ0,θ1),图形化表示损失函数如图:
梯度下降算法的目的就是将(θ0,θ1)对应的 J(θ0,θ1)从较高的地方,逐步改变到低谷的 J(θ0,θ1)值,也就是让 J(θ0,θ1)尽可能的小,可以理解成从山上下山,逐渐下到较低或最低的山底。梯度下降算法如下:
(其中alpha>0, j=0,1)
举个例子:
例如损失函数如图所示,alpha>0,如果初始值在A1点,A1点的斜率是正数,那么θ1会往左移动,往更加接近最低点的位置移动。如果初始值处于B1点,斜率为负数,那么θ1会往右移动,也是往更加接近最低点的位置移动。
1.2 alpha的作用alpha表示学习速率,直观的表现是影响梯度下降过程中的步长。alpha越大,学习速率越大,收敛越快,alpha越小,学习速率越小,收敛越慢。另外,alpha的值如果过于小,会是学习速率过于慢,影响效率,另外,很容易得出局部最优解的结果。alpha的值过大也会引发另一个问题,导致梯度下降的过程中错过最优解,而导致发散不收敛。
1.3 alpha大小的影响
1.4 收敛速率即使不调节alpha的值,随着梯度下降过程中越来越接近最优点或局部最优点,由于斜率在接近最优点的过程中是逐渐降低的,收敛速率也是逐步降低的。例如,A1的斜率大于A2的斜率,B1的斜率大于B2的斜率。
1.5 局部最优解当cost function如下图所示的时候,很容易求出的θ值是局部最优解。局部最优解的表现是导师为0,达到局部最优解的位置之后,无论怎么进行梯度下降,由于其导数为0,都不会改变θ值。
1.6 θ参数同时更新有一点需要说明,所有θ的更新需要同步进行,不能单独进行,下面对θ的更新进行了比较,一定要谨记。
二、线性回归模型的梯度下降2.1 总体阐述左侧是梯度下降算法,右侧是线性回归模型以及相应的cost function
2.2 梯度下降的算法求解以下就是梯度下降算法的求解过程,一般对微积分和求导有所了解的话,还是比较简单的。
2.3 线性函数的cost function(凸函数)线性回归的cost function是凸函数,所谓的凸函数简单点理解就是一个弓形函数,在梯度下降的时候,只会求出最优解。
2.4 线性回归模型的梯度下降过程
三、总结以上就是针对梯度下降算法,以及结合线性回归模型的梯度下降的算法解释。
欢迎大家关注:数据之下 微信公众号,系统性的分享机器学习、深度学习等方面的知识,不做碎片化学习的牺牲者,要做利用好碎片化时间的受益者。

相关文章推荐
- httpd2.4结合mysql5.5以及php5.5纯手工打造高效搭建LAMP运营平台基础篇
- 根据产品原型结合主流程抽取类,属性以及关系
- 使用MVP框架,retrofit结合Rxjava以及fresco加载图片,用recycleview实现
- HTML5 Web Speech API 结合Ext实现浏览器语音识别以及输入
- 使用原生JavaScriptAjax以及jQuery的Ajax结合SpringMVC发送和获取json数据
- 阐述二维码的原理以及使用google api和PHP QR Code来生成二维码
- 版本管理器subversion的简单配置以及和apache的结合使用
- Python:通过执行100万次打印来比较C和python的性能,以及用C和python结合来解决性能问题的方法 .
- 【Android游戏开发二十一】Android os设备谎言分辨率的解决方案!以及简单阐述游戏引擎如何使用!
- svn安装以及与myeclipse结合完整版
- cocos2dx 3.0结合cocostudio创建界面UI以及特效
- 基于多尺度卷积神经网络框架结合语义标签和surface normals以及深度预测
- 详解线程、了解进程与线程的区别以及线程分离与结合属性
- Lucene.net(4.8.0) 学习问题记录五: JIEba分词和Lucene的结合,以及对分词器的思考
- API生命周期第三阶段:API实施模式,以及结合swagger和项目现状的最佳模式
- 根据排队论阐述路由器和高速公路的拥堵以及拥堵缓解问题
- CxImage与OpenGL结合,用于读入多种格式的纹理以及用来把屏幕保存为各种格式的图像文件。
- 结合实例详解clone()函数,Cloneable接口以及深拷贝与浅拷贝的问题
- C++类型转换----dynamic_cast(以及结合typeid的应用)
- sqlserver 的查询最近7天的数据 group by 与with的结合 以及系统表的妙用