大数据笔记14:Zebra项目分析与实施
2018-03-02 22:35
621 查看
第14天——Zebra项目分析与实施
第一部分 Zebra项目概述一、Zebra项目介绍二、日志数据结构分析三、数据以| 分割后,每个数据项的含义四、Zebra项目整体架构(一)技术架构(二)工程架构五、Zebra业务说明六、Zebra项目设计思想
第二部分 Zebra项目实施过程一、创建Maven项目ZebraProject二、zebra_jobtracker模块V1.0三、zebra_engine1_01模块V1.0四、zebra_jobtracker模块V1.1五、zebra_engine1_02模块V1.0六、zebra_engine1_01模块V1.1七、zebra_engine1_02模块V1.1八、二级引擎zebra_engine2模块
第一部分 Zebra项目概述一、Zebra项目介绍
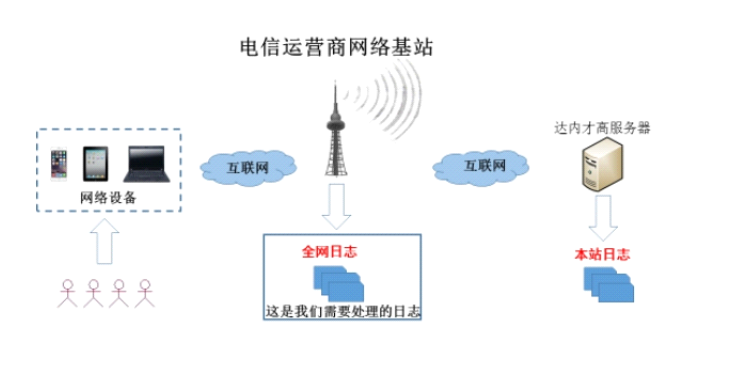
如图所示,电信运营商的用户通过连接到互联网中的各种网络设备访问一个网站时,其访问信息会通过基站在网络中传递,基站可以收集所有用户的访问日志数据。
Zebra项目是对电信运营商收集的用户上网数据进行分析的一个应用程序。通过分析得到的结果可以展现不同小区的上网详情。
二、日志数据结构分析日志里的某一条数据(以下为一整行数据,以| 为分割符):533||11|93287887015245963|6||||1|100.82.254.88|100.82.98.100|2152|2152|13849|147855076||||103|1409649427963|1409649428488|1|15|999||0|10.83.124.18||60914|0|137.175.9.211||80|734|329|4|2|0|0|0|0|221|29|0|0|20|221|12600|1260|1|0|1|3|6|200|221|221|255|559955.com|/tu/31322.JPG|559955.com|Mozilla/5.0 (Linux; Android 4.3; zh-cn; SAMSUNG-SM-G7108V_TD Release/02.15.2014 Browser/AppleWebKit537.36 Build/JSS15J) AppleWebkit/537.36 (KHTML, like Gecko) Version/1.5 Mobile Safari/537.36||http://www.701111.com/||0|0|0|0|||3|0|525|0|0|1:734/329
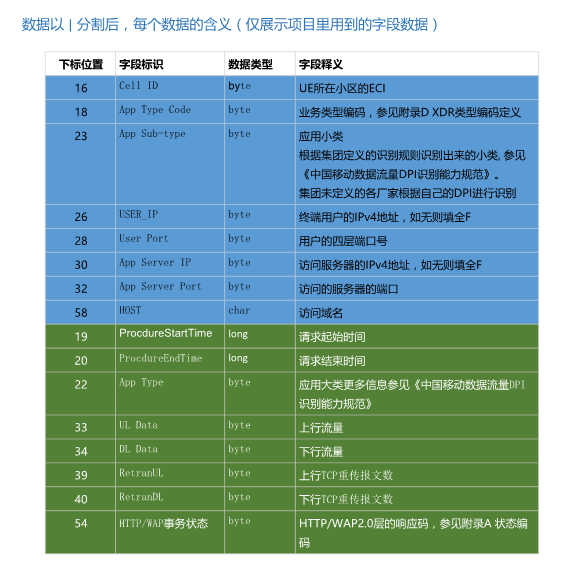
三、数据以| 分割后,每个数据项的含义(仅展示项目里用到的字段数据)
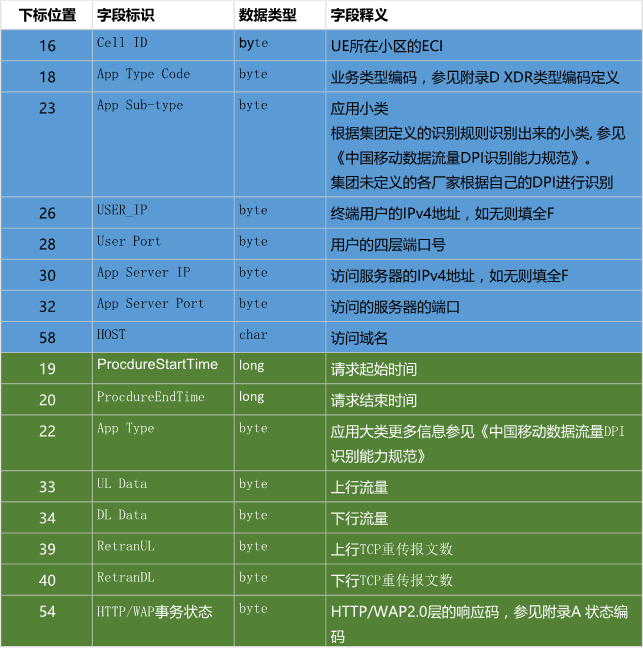
这是需要处理的每行数据中的字段,通过对这些数据的处理,可以得到不同小区的上网详情数据。具体来说,就是把一段时间内的同一个小区内访问同一网站、同一个ip的访问累计起来,就可以得到某小区内对某网站的访问详情。
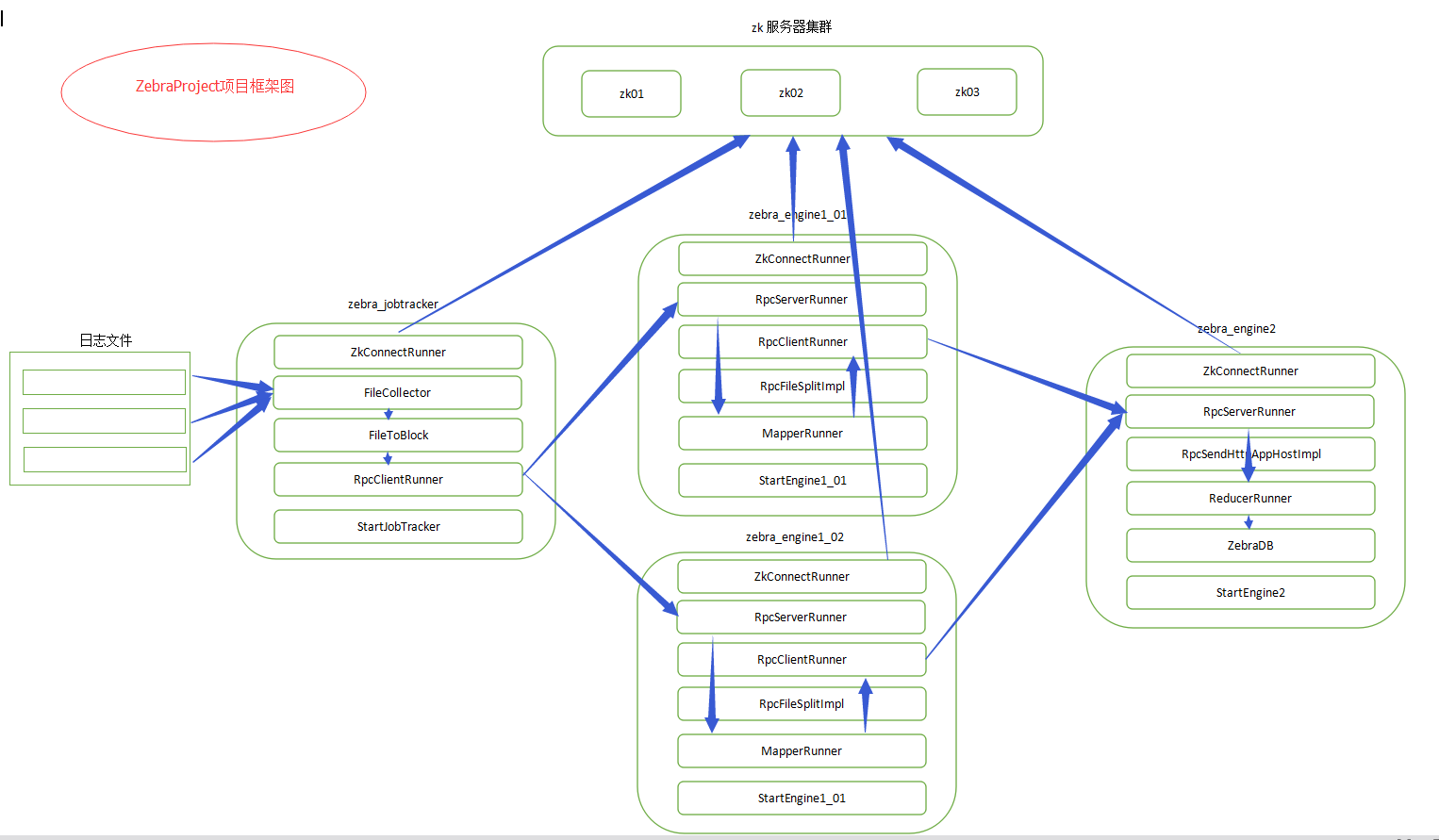
四、Zebra项目整体架构(一)技术架构1、maven利用Maven工程来管理项目。主要是利用Maven来管理jar包,以及利用maven生成avro的rpc方法及序列化对象。2、avro利用avro实现对象的序列化以及节点间的rpc通信。3、zookeeper利用zookeeper达到分布式环境的协调服务。
(二)工程架构
1、ZebraProject工程① 管理整个项目的pom.xml文件② 定义全局变量参数③ 定义avro相关的avsc文件及avdl文件
2、zebra_jobtracker模块① 定时扫描是否有待处理文件② 根据用户定义的参数,对文件进行逻辑切块。③ 根据文件切块数量生成对应的任务数量。(一个文件块相当于一个任务)④ 将任务分发给一级引擎节点(TaskTracker )去处理。并通过zookeeper监控TaskTracker的状态来决定任务分配
3、zebra_engine1模块① 接收jobtracker发来的任务,根据任务进行对文件的处理② 将文件数据进行清洗和整理。(根据zebra要求的业务逻辑进行数据整理)③ 将处理完的数据发给二级引擎,二级引擎做最后的合并④ 通过zookeeper,注册自身节点信息状态,便于集群其他机器监控继而做相关的业务逻辑处理
4、zebra_engine2模块① 接收(一个或多个)一级引擎发来的数据。② 对数据进行归并处理③ 将最后处理的数据结果落地(写文件或写数据库)
五、Zebra业务说明1、数据项含义
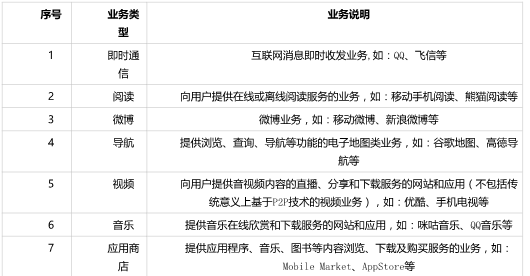
2、应用大类说明

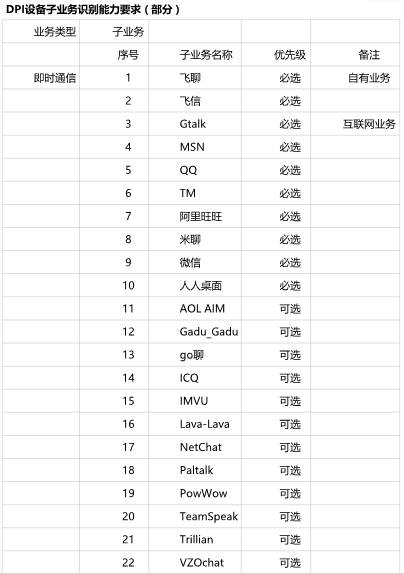
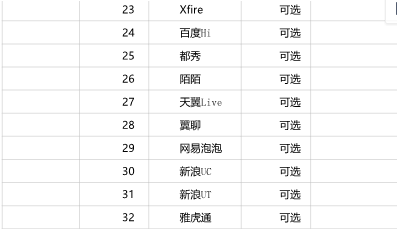
3、应用小类说明
4、业务字段处理逻辑
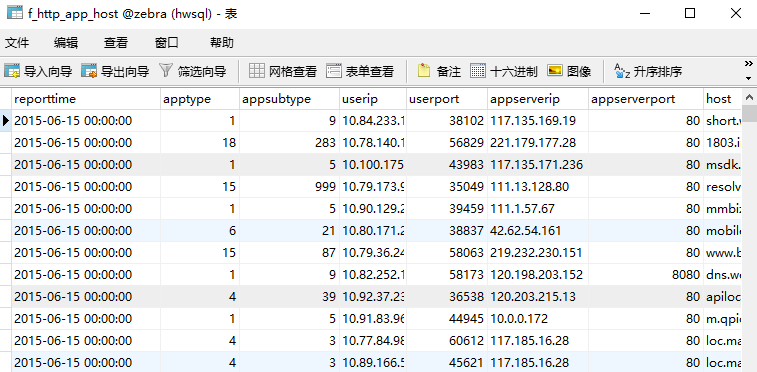
总表f_http_app_host:
建表语句:
后期可能会根据统计出来的数据进行业务拆分,形成几个不同的维度进行查询:(1)应用欢迎度;(2)各网站表现;(3)小区Http上网能力;(4)小区上网喜好。
(1)应用欢迎度表说明
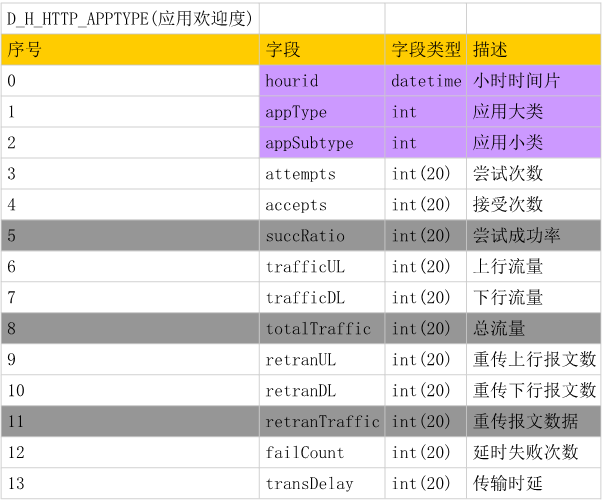
建表语句:

建表语句:

建表语句:

建表语句:
日志文件103_20150615143630_00_00_000.csv:10.3MB
该日志文件总共有20802条记录。
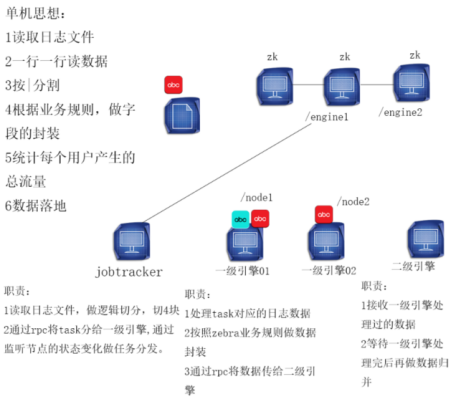
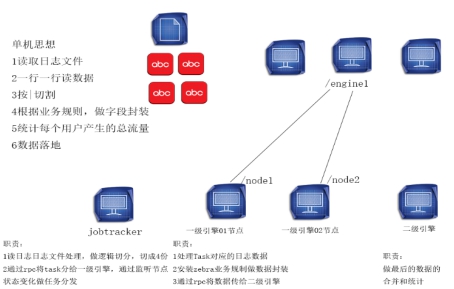
2、四个进程职责jobtracker——>一级引擎01、一级引擎02——>二级引擎
说明:在RPC中,传数据的一端是客户端、接收数据的一端是服务器端。
(1)jobtracker的职责读取日志文件,做逻辑切分,切4块(每块3M)
通过rpc将task分给一级引擎,通过监听节点的状态变化做任务分发
(2)一级引擎01、02的职责处理task对应的日志数据
按照zebra业务规则做数据封装(Map)
通过rpc将数据传给二级引擎
(2)二级引擎的职责:接收一级引擎处理过的数据
等待一级引擎处理完后再做数据归并
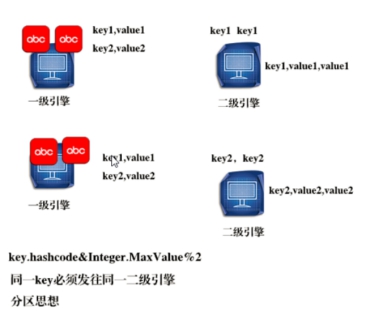
3、重要的分区思想

第二部分 Zebra项目实施过程
一、创建Maven项目ZebraProject
1、添加四个子模块(1)添加zebra_jobtracker子模块



(2)添加zebra_engine1_01子模块

(3)添加zebra_engine1_02子模块
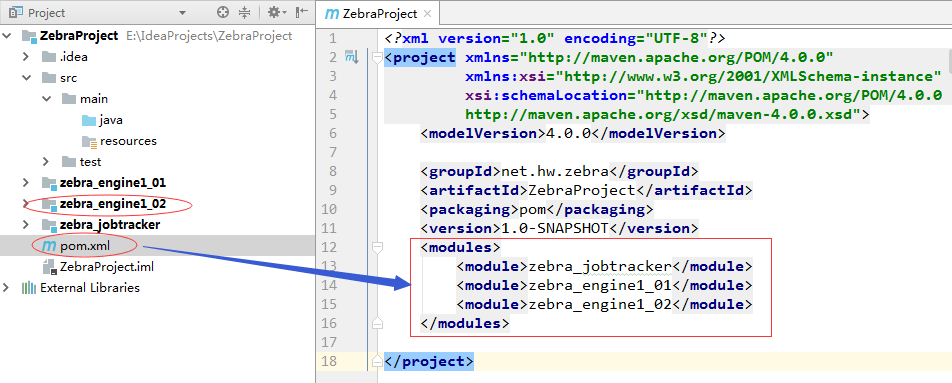
(4)添加zebra_engine2子模块
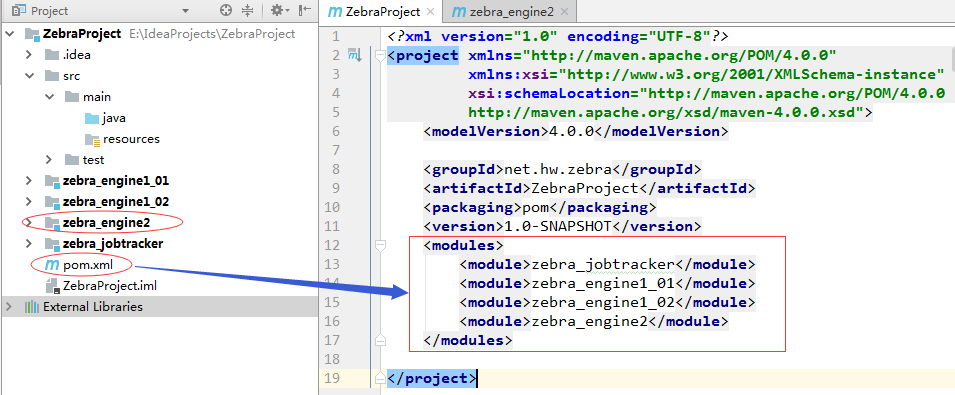
2、修改ZebraProject的pom.xml文件,添加依赖和插件
(1)FileSplit.avsc(文件切片模式文件) { "namespace": "rpc.domain", "type": "record", "name": "FileSplit", "fields": [ {"name": "path", "type": ["string", "null"]}, {"name": "start", "type": ["long", "null"]}, {"name": "length", "type": ["long", "null"]} ]}
字段说明:path: 待处理文件的位置start: 处理的文件切片(逻辑切片)的起始位置length: 处理的文件切片的长度(字节为单位)
(2)HttpAppHost.avsc(Zebra业务对象模式文件){ "namespace": "rpc.domain", "type": "record", "name": "HttpAppHost", "fields": [ {"name": "reportTime", "type": ["string", "null"]}, {"name": "cellid", "type": ["string", "null"]}, {"name": "appType", "type": ["int", "null"]}, {"name": "appSubtype", "type": ["int", "null"]}, {"name": "userIP", "type": ["string", "null"]}, {"name": "userPort", "type": ["int", "null"]}, {"name": "appServerIP", "type": ["string", "null"]}, {"name": "appServerPort", "type": ["int", "null"]}, {"name": "host", "type": ["string", "null"]}, {"name": "attempts", "type": ["int", "null"]}, {"name": "accepts", "type": ["int", "null"]}, {"name": "trafficUL", "type": ["long", "null"]}, {"name": "trafficDL", "type": ["long", "null"]}, {"name": "retranUL", "type": ["long", "null"]}, {"name": "retranDL", "type": ["long", "null"]}, {"name": "transDelay", "type": ["long", "null"]} ]}
(3)RpcFileSplit.avdl(发送文件切片的协议文件)
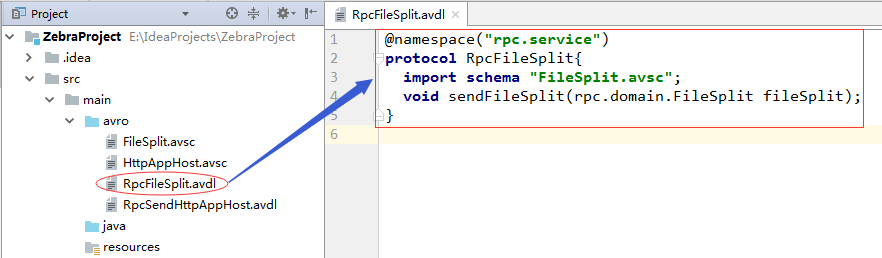
@namespace("rpc.service")
protocol RpcFileSplit{
import schema "FileSplit.avsc";
void sendFileSplit(rpc.domain.FileSplit fileSplit);
}(4)RpcSendHttpAppHost.avdl(发送Zebra业务对象的协议文件)
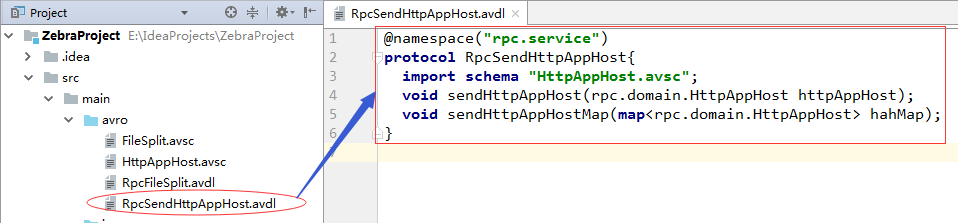
@namespace("rpc.service")
protocol RpcSendHttpAppHost{
import schema "HttpAppHost.avsc";
void sendHttpAppHost(rpc.domain.HttpAppHost httpAppHost);
void sendHttpAppHostMap(map<rpc.domain.HttpAppHost> hahMap);
}4、利用avro插件基于模式文件和协议文件生成相应的类和接口右击pom.xml,单击Maven—>Generate Sources and Update Folders:

生成了序列化类FileSplit和HttpAppHost,RPC服务接口RpcFileSplit和RpcSendHttpAppHost。

5、配置全局的属性文件env.properties
# 日志文件所在目录
zebra.dir=D:\\program\\zebra\\data
# 30秒扫描一次
zebra.scanninginterval=30000
# 文件切片大小为3MB
zebra.blocksize=3000000
# zk服务器的ip:port
zebra.zk.serverip=192.168.225.51:2181,192.168.225.52:2181,192.168.225.53:2181
# 会话超时时长
zebra.zk.sessiontimeout=30000
# jobtracker节点路径
zebra.zk.jobtrackerpath=/jobtracker
# 一级引擎节点路径
zebra.zk.engine1path=/engine1
# 二级引擎节点路径
zebra.zk.engine2path=/engine2查看zk服务器集群的ip地址:



6、创建GlobalEnv类定义全局变量,读取env.properties属性文件
package net.hw.common;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import rpc.domain.FileSplit;
import java.io.File;
import java.io.InputStream;
import java.util.Properties;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.LinkedBlockingDeque;
/**
* Created by howard on 2017/11/3
*
* 定义全局变量,读取属性文件
*/
public class GlobalEnv {
/**
* 日志文件目录
*/
private static String dir;
/**
* 扫描时间间隔
*/
private static long scanningInterval;
/**
* 文件切片大小
*/
private static long blockSize;
/**
* zk服务器ip地址
*/
private static String zkServerIp;
/**
* 连接zk服务的会话超时
*/
private static int sessionTimeout;
/**
* jobtracker节点路径
*/
private static String jobTrackerPath;
/**
* 一级引擎节点路径
*/
private static String engine1Path;
/**
* 二级引擎节点路径
*/
private static String engine2Path;
/**
* 文件链式阻塞队列(收集日志文件先保存到该队列供后续处理)
*/
private static BlockingQueue<File> fileQueue = new LinkedBlockingDeque<File>();
/**
* 文件切片链式阻塞队列(将每个文件切成若干片保存到该队列供后续处理)
*/
private static BlockingQueue<FileSplit> fileSplitQueue = new LinkedBlockingDeque<FileSplit>();
/**
* 静态代码块,只执行一次
*/
static {
try {
initParam();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 加载属性文件,获取参数值
*/
public static void initParam() throws Exception {
// 定义属性对象
Properties properties = new Properties();
// 获取资源作为输入流
InputStream in = GlobalEnv.class.getResourceAsStream("/env.properties");
// 将输入流数据加载到属性对象
properties.load(in);
// 关闭输入流
in.close();
// 从属性对象中读取属性
if (properties.containsKey("zebra.dir")) {
dir = properties.getProperty("zebra.dir");
}
if (properties.containsKey("zebra.scanninginterval")) {
scanningInterval = Long.parseLong(properties.getProperty("zebra.scanninginterval"));
}
if (properties.containsKey("zebra.blocksize")) {
blockSize = Long.parseLong(properties.getProperty("zebra.blocksize"));
}
if (properties.containsKey("zebra.zk.serverip")) {
zkServerIp = properties.getProperty("zebra.zk.serverip");
}
if (properties.containsKey("zebra.zk.sessiontimeout")) {
sessionTimeout = Integer.parseInt(properties.getProperty("zebra.zk.sessiontimeout"));
}
if (properties.containsKey("zebra.zk.jobtrackerpath")) {
jobTrackerPath = properties.getProperty("zebra.zk.jobtrackerpath");
}
if (properties.containsKey("zebra.zk.engine1path")) {
engine1Path = properties.getProperty("zebra.zk.engine1path");
}
if (properties.containsKey("zebra.zk.engine2path")) {
engine2Path = properties.getProperty("zebra.zk.engine2path");
}
}
/**
* 连接zk服务器获取ZooKeeper对象
*/
public static ZooKeeper connectZkServer() throws Exception {
final CountDownLatch cdl = new CountDownLatch(1);
ZooKeeper zk = new ZooKeeper(zkServerIp, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
if (event.getState() == Event.KeeperState.SyncConnected) {
System.out.println("连接zk服务器成功!");
cdl.countDown();
}
}
});
cdl.await();
return zk;
}
public static String getDir() {
return dir;
}
public static void setDir(String dir) {
GlobalEnv.dir = dir;
}
public static long getScanningInterval() {
return scanningInterval;
}
public static void setScanningInterval(long scanningInterval) {
GlobalEnv.scanningInterval = scanningInterval;
}
public static long getBlockSize() {
return blockSize;
}
public static void setBlockSize(long blockSize) {
GlobalEnv.blockSize = blockSize;
}
public static String getZkServerIp() {
return zkServerIp;
}
public static void setZkServerIp(String zkServerIp) {
GlobalEnv.zkServerIp = zkServerIp;
}
public static int getSessionTimeout() {
return sessionTimeout;
}
public static void setSessionTimeout(int sessionTimeout) {
GlobalEnv.sessionTimeout = sessionTimeout;
}
public static String getJobTrackerPath() {
return jobTrackerPath;
}
public static void setJobTrackerPath(String jobTrackerPath) {
GlobalEnv.jobTrackerPath = jobTrackerPath;
}
public static String getEngine1Path() {
return engine1Path;
}
public static void setEngine1Path(String engine1Path) {
GlobalEnv.engine1Path = engine1Path;
}
public static String getEngine2Path() {
return engine2Path;
}
public static void setEngine2Path(String engine2Path) {
GlobalEnv.engine2Path = engine2Path;
}
public static BlockingQueue<File> getFileQueue() {
return fileQueue;
}
public static BlockingQueue<FileSplit> getFileSplitQueue() {
return fileSplitQueue;
}
}二、zebra_jobtracker模块V1.0作用:作为资源调度者。获取日志文件放入文件队列,从文件队列里取出文件,进行文件切分,然后文件切片放入文件切片队列。

1、修改pom.xml文件,添加对ZebraProject的依赖
package net.hw.file;
import net.hw.common.GlobalEnv;
import java.io.File;
/**
* Created by howard on 2017/11/3
*/
public class FileCollector implements Runnable {
@Override
public void run() {
// 获取日志文件目录
File dir = new File(GlobalEnv.getDir());
// 获取日志文件目录下所有文件
File[] files = dir.listFiles();
// 遍历所有文件
for (File file : files) {
// 处理后缀名为ctr的标识文件,表明对应的日志文件尚未处理
if (file.getName().endsWith(".ctr")) {
// 获取对应的日志文件名
String logFileName = file.getName().split(".ctr")[0] + ".csv";
// 创建日志文件对象
File logFile = new File(dir, logFileName);
// 将日志文件添加到文件队列中,等待后续处理
GlobalEnv.getFileQueue().add(logFile);
// 删除标识文件,表明对应的日志文件已经处理
file.delete();
}
}
// 每隔指定时间收集一次日志
try {
Thread.sleep(GlobalEnv.getScanningInterval());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}3、编写FileToBlock类作用:该线程类从文件队列(全局的fileQueue对象)里拿日志文件,然后对它进行逻辑切分(假切,不会生成切块文件)[10.3MB: 0~3MB; 3MB~6MB; 6MB~9M; 9M~10.3M],切分后将相关数据封装到FileSplit对象里,然后将FileSplit对象添加到文件切片队列(全局的fileSplitQueue对象)里,等待后续处理。
package net.hw.file;
import net.hw.common.GlobalEnv;
import rpc.domain.FileSplit;
import java.io.File;
/**
* Created by howard on 2017/11/3
*/
public class FileToBlock implements Runnable{
@Override
public void run() {
while (true) {
try {
// 从文件队列中获取日志文件,用take()方法,没有日志文件就会产生阻塞
File file = GlobalEnv.getFileQueue().take();
// 获取文件长度
long length = file.length();
// 计算切片数量
long num = length % GlobalEnv.getBlockSize() == 0 ? length / GlobalEnv.getBlockSize() : length / GlobalEnv.getBlockSize() + 1;
// 遍历全部切片,封装成FileSplit对象,添加到文件切片队列
for (int i = 0; i < num; i++) {
// 创建文件切片对象
FileSplit split = new FileSplit();
// 设置文件切片路径
split.setPath(file.getPath());
// 设置文件切片起点
split.setStart(i * GlobalEnv.getBlockSize());
// 设置文件切片长度
if (i == num - 1) {
split.setLength(length - split.getStart());
} else {
split.setLength(GlobalEnv.getBlockSize());
}
// 将切片添加到文件切片队列里
GlobalEnv.getFileSplitQueue().add(split);
// 输出切片信息
System.out.println(split);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}4、编写StartJobTrakcer类——利用线程池启动线程
package net.hw.common;
import net.hw.file.FileCollector;
import net.hw.file.FileToBlock;
import net.hw.rpc.RpcClientRunner;
import net.hw.zk.ZkConnectRunner;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* Created by howard 2017/11/3
*/
public class StartJobTracker {
public static void main(String[] args) {
// 提示用户jobtracker启动
System.out.println("jobtracker已经启动……");
// 创建缓存线程池(大池子,小队列)
ExecutorService es = Executors.newCachedThreadPool();
// 启动文件收集线程
es.submit(new FileCollector());
// 启动文件切片线程
es.submit(new FileToBlock());
// 启动连接zk服务器的线程==>启动RPC客户端发送文件切片的线程
es.submit(new ZkConnectRunner());
}
}运行程序,结果如下:

并且该日志文件所对应的标识文件(*.ctr)被删除了,表明此日志文件已被处理。通过标识文件可以避免日志文件被重复处理。
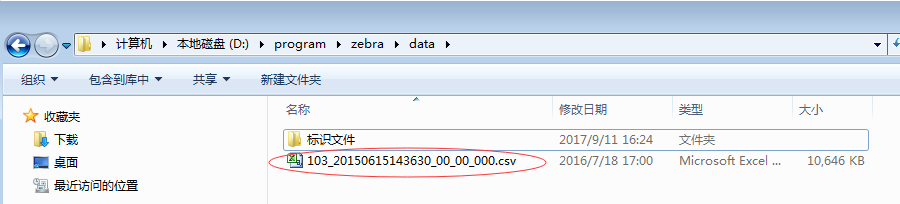
查看日志文件属性:
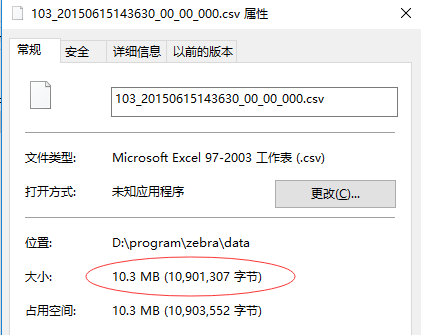
10.3MB的日志文件,按3MB来切,得到四个文件切片:{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 0, "length": 3000000}{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 3000000, "length": 3000000}{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 6000000, "length": 3000000}{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 9000000, "length": 1901307}三、zebra_engine1_01模块V1.0作用:接收jobtracker发来的任务,根据任务进行对文件的处理;将文件数据进行清洗和整理;将处理完的数据发给二级引擎;通过zookeeper,注册自身节点信息状态,便于集群其他机器监控继而做相关的业务逻辑处理。
1、修改pom.xml文件,添加对父工程ZebraProject的依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent>
<artifactId>ZebraProject</artifactId>
<groupId>net.hw.zebra</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>zebra_engine1_01</artifactId>
<dependencies>
<dependency>
<groupId>net.hw.zebra</groupId>
<artifactId>ZebraProject</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
</project>2、编写ownenv.properties文件
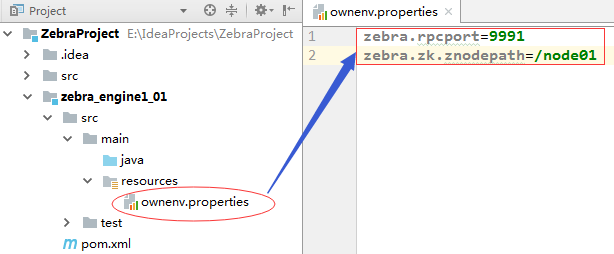
3、编写ownenv类,定义变量并且读取ownenv.properties属性文件
package net.hw.common;
import rpc.domain.FileSplit;
import rpc.domain.HttpAppHost;
import java.io.InputStream;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class OwnEnv {
/**
* rpc通信端口
*/
private static int rpcPort;
/**
* 一级引擎在zk服务器上的节点路径
*/
private static String znodePath;
/**
* 文件切片链式阻塞队列
*/
private static BlockingQueue<FileSplit> splitQueue = new LinkedBlockingQueue<FileSplit>();
/**
* zebra业务对象链式阻塞队列
*/
private static BlockingQueue<Map<CharSequence, HttpAppHost>> mapQueue = new LinkedBlockingQueue<>();
/**
* 静态代码块,只执行一次
*/
static {
try {
initParam();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 加载属性文件,获取参数值
*/
public static void initParam() throws Exception{
// 定义属性对象
Properties properties = new Properties();
// 获取资源作为输入流
InputStream in = GlobalEnv.class.getResourceAsStream("/ownenv.properties");
// 将输入流数据加载到属性对象
properties.load(in);
// 关闭输入流
in.close();
// 从属性对象中读取属性
if (properties.containsKey("zebra.rpcport")) {
rpcPort = Integer.parseInt(properties.getProperty("zebra.rpcport"));
}
if (properties.containsKey("zebra.zk.znodepath")) {
znodePath = properties.getProperty("zebra.zk.znodepath");
}
}
public static int getRpcPort() {
return rpcPort;
}
public static void setRpcPort(int rpcPort) {
OwnEnv.rpcPort = rpcPort;
}
public static String getZnodePath() {
return znodePath;
}
public static void setZnodePath(String znodePath) {
OwnEnv.znodePath = znodePath;
}
public static BlockingQueue<FileSplit> getSplitQueue() {
return splitQueue;
}
public static BlockingQueue<Map<CharSequence, HttpAppHost>> getMapQueue() {
return mapQueue;
}
}如何将切块后的任务使用rpc传递给一级引擎?
对于jobtracker与一级引擎而言,一级引擎是rpc服务器端,jobtracker是rpc的客户端。在jobtracker模块中需要知道一级引擎的ip和端口号,这些信息又在一级引擎中,那么在jobtracker中如何获取这些信息呢?
解决方案:让一级引擎创建节点/node01,并将一级引擎服务器的ip和端口保存到节点数据中。
4、编写ZkConnectRunner,负责一级引擎节点创建
作用:为一级引擎在zk服务器上创建节点,保存一级引擎的ip和port。
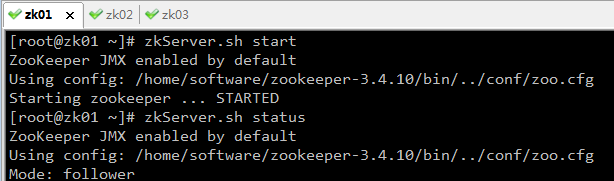
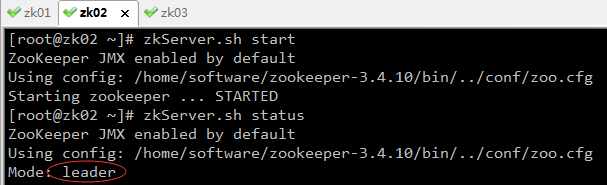
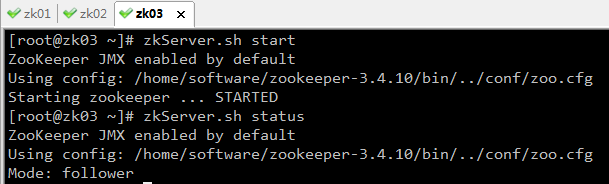
启动StartEngine1_01,运行结果如下:

原因是我们并没有创建/engine1节点:
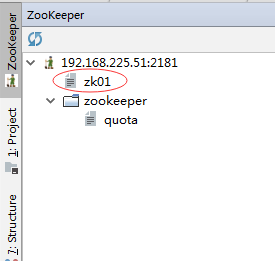
所以,创建/engine1/node01节点会失败。
修改ZkConnectRunner代码:
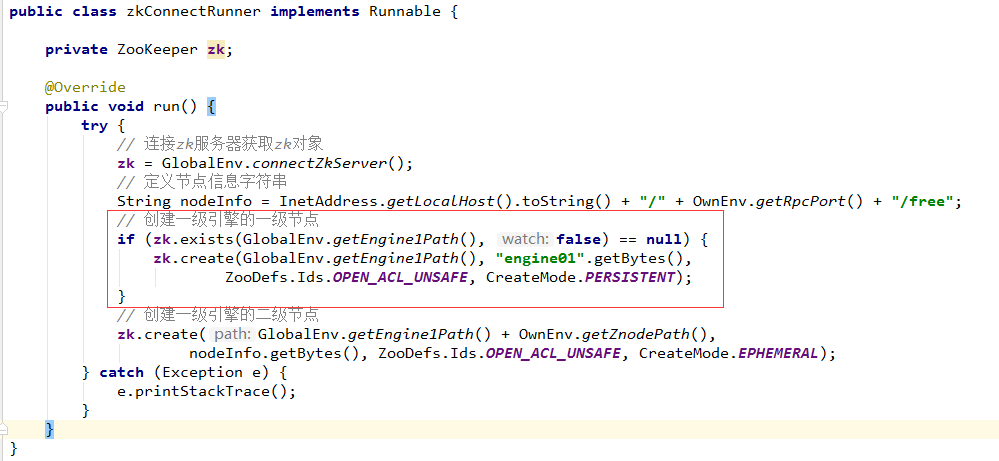
此时,运行程序StartEngine1_01,结果如下:
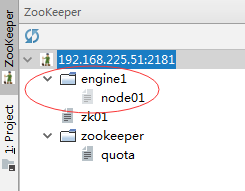
利用ZooKeeper插件查看:
6、创建rpc服务器端接收jobtracker客户端传递过来的任务接收jobtracker传来的FileSplit,所以要用对应的协议接口:RpcFileSplit,此外还有实现类(即拿到FileSplit之后要怎么处理。)(1)创建协议接口实现类RpcFileSplitImpl
package net.hw.rpc;
import net.hw.common.OwnEnv;
import org.apache.avro.AvroRemoteException;
import rpc.domain.FileSplit;
import rpc.service.RpcFileSplit;
public class RpcFileSplitImpl implements RpcFileSplit {
@Override
public Void sendFileSplit(FileSplit fileSplit) throws AvroRemoteException {
// 提示用户收到jobtracker派发的任务
System.out.println("一级引擎01节点收到jobtracker发送过来的" + fileSplit);
// 将收到的文件切片对象添加到一级引擎的文件切片队列
OwnEnv.getSplitQueue().add(fileSplit);
return null;
}
}(2)编写RpcServerRunner线程类
package net.hw.rpc;
import net.hw.common.OwnEnv;
import org.apache.avro.ipc.NettyServer;
import org.apache.avro.ipc.specific.SpecificResponder;
import rpc.service.RpcFileSplit;
import java.net.InetSocketAddress;
public class RpcServerRunner implements Runnable{
@Override
public void run() {
// 创建NettyServer对象
NettyServer server = new NettyServer(new SpecificResponder(RpcFileSplit.class, new RpcFileSplitImpl()),
new InetSocketAddress(OwnEnv.getRpcPort()));
// 提示用户
System.out.println("一级引擎01节点的RPC服务启动了~");
}
}(3)修改StartEngine1_01类,将线程追加到线程池中
1、创建ZkConnectRunner类,获取两个一级引擎的节点数据(ip和port)
package net.hw.zk;
import net.hw.common.GlobalEnv;
import org.apache.zookeeper.ZooKeeper;
import java.util.List;
public class ZkConnectRunner implements Runnable {
private ZooKeeper zk;
@Override
public void run() {
try {
// 连接zk服务器
zk = GlobalEnv.connectZkServer();
// 获取一级引擎根节点(/engine1)下所有子节点
List<String> childPaths = zk.getChildren(GlobalEnv.getEngine1Path(), null);
// 遍历所有子节点
for (String childPath : childPaths) {
// 启动发送文件切片的线程
new Thread(new RpcClientRunner(childPath, zk)).start();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}2、创建RpcCilentRunner线程类,负责向一级引擎发送文件切片
package net.hw.rpc;
import net.hw.common.GlobalEnv;
import org.apache.avro.ipc.NettyTransceiver;
import org.apache.avro.ipc.specific.SpecificRequestor;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.ZooKeeper;
import rpc.domain.FileSplit;
import rpc.service.RpcFileSplit;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.Proxy;
public class RpcClientRunner implements Runnable {
private String childPath;
private ZooKeeper zk;
public RpcClientRunner(String childPath, ZooKeeper zk) {
this.childPath = childPath;
this.zk = zk;
}
@Override
public void run() {
// 输出一级引擎子节点路径
System.out.println("childPath: " + childPath);
try {
// 获取一级引擎子节点数据
byte[] data = zk.getData(GlobalEnv.getEngine1Path() + "/" + childPath, null, null);
// 封装得到子节点信息(ip/port/free)
String info = new String(data);
// 输出子节点信息
System.out.println("info: " + info);
// 通过拆分拿到rpc服务器端(一级引擎)的ip和port
String ip = info.split("/")[1];
int port = Integer.parseInt(info.split("/")[2]);
// 创建NettyTransceiver对象
NettyTransceiver transceiver = new NettyTransceiver(new InetSocketAddress(ip, port));
// 获取文件切片RPC客户端代理
RpcFileSplit proxy = SpecificRequestor.getClient(RpcFileSplit.class, transceiver);
// 从文件切片队列里获取一个文件切片
FileSplit split = GlobalEnv.getFileSplitQueue().take();
// 将该文件切片发送到RPC服务器端(一级引擎)
proxy.sendFileSplit(split);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}3、修改StartJobTracker类,添加发送切片的线程
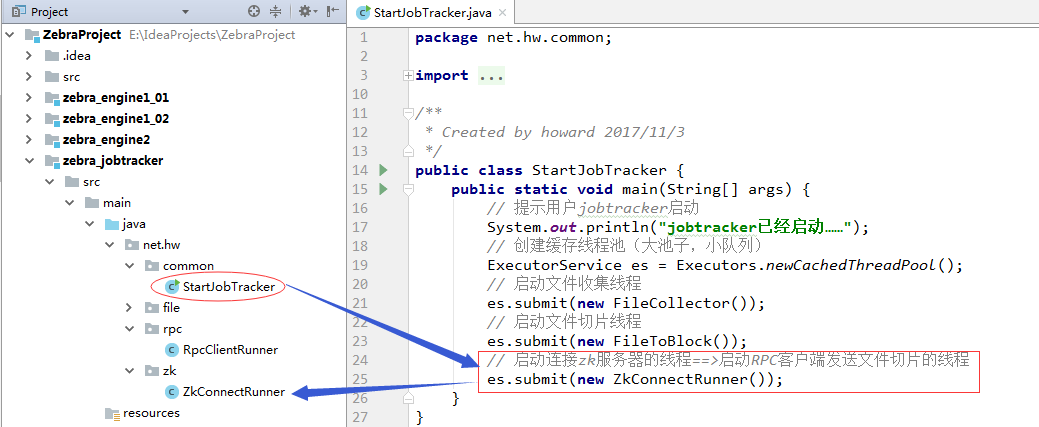
4、测试jobtracer能否将任务发送到一级引擎(1)先启动一级引擎的StartEngine1_01(作为rpc服务器端)
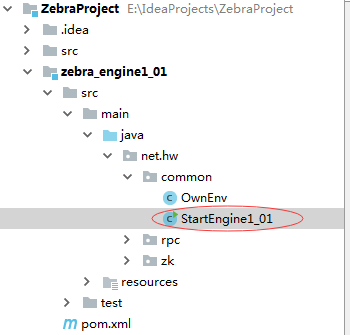
运行结果如下:
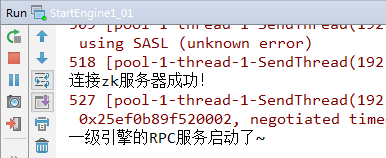
注意:日志标识文件一定要存在,表明日志文件尚未处理,否则根据我们程序的逻辑,jobtracker收集不到日志文件。
(2)再启动jobtracker的StartJobTracker(作为rpc客户端)

运行结果如下:
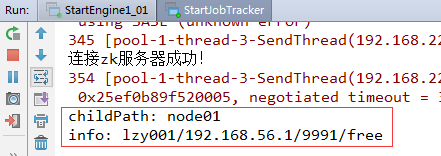
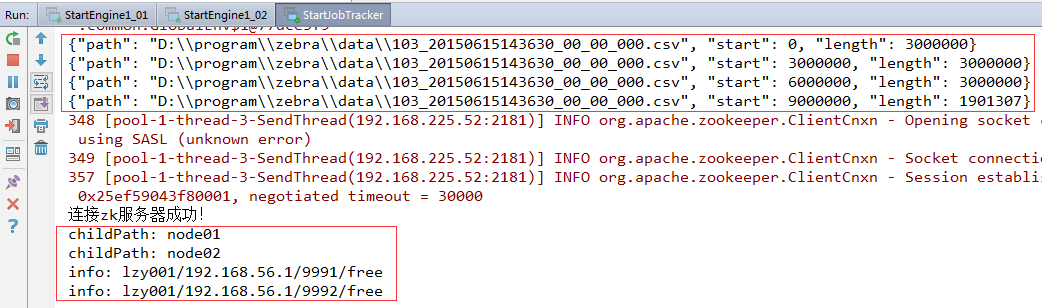
读取到了zk服务器上/engine1/的子结点node01,包括该节点上保存的一级引擎作为RPC服务器的ip地址和端口信息,一级引擎该节点目前的状态(free:空闲)。
jobtracker作为RPC客户端,已经连接了作为RPC服务器端的一级引擎,那么,此时切换到一级引擎的控制台看看,是否jobtracker完成了将文件切片发送到一级引擎的任务。

目前,jobtracker只发送了一个文件切片到一级引擎,如何才能将所有文件切片发送到一级引擎呢?大家课后完成此任务。
五、zebra_engine1_02模块V1.0
1、修改pom.xml文件,添加对项目ZebraProject的依赖
2、创建ownenv.properties文件
3、编写OwnEven类,读取ownenv.properties属性文件
package net.hw.common;
import rpc.domain.FileSplit;
import rpc.domain.HttpAppHost;
import java.io.InputStream;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class OwnEnv {
/**
* rpc通信端口
*/
private static int rpcPort;
/**
* 一级引擎在zk服务器上的节点路径
*/
private static String znodePath;
/**
* 文件切片链式阻塞队列
*/
private static BlockingQueue<FileSplit> splitQueue = new LinkedBlockingQueue<FileSplit>();
/**
* zebra业务对象链式阻塞队列
*/
private static BlockingQueue<Map<CharSequence, HttpAppHost>> mapQueue = new LinkedBlockingQueue<>();
/**
* 静态代码块,只执行一次
*/
static {
try {
initParam();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 加载属性文件,获取参数值
*/
public static void initParam() throws Exception{
// 定义属性对象
Properties properties = new Properties();
// 获取资源作为输入流
InputStream in = GlobalEnv.class.getResourceAsStream("/ownenv.properties");
// 将输入流数据加载到属性对象
properties.load(in);
// 关闭输入流
in.close();
// 从属性对象中读取属性
if (properties.containsKey("zebra.rpcport")) {
rpcPort = Integer.parseInt(properties.getProperty("zebra.rpcport"));
}
if (properties.containsKey("zebra.zk.znodepath")) {
znodePath = properties.getProperty("zebra.zk.znodepath");
}
}
public static int getRpcPort() {
return rpcPort;
}
public static void setRpcPort(int rpcPort) {
OwnEnv.rpcPort = rpcPort;
}
public static String getZnodePath() {
return znodePath;
}
public static void setZnodePath(String znodePath) {
OwnEnv.znodePath = znodePath;
}
public static BlockingQueue<FileSplit> getSplitQueue() {
return splitQueue;
}
public static BlockingQueue<Map<CharSequence, HttpAppHost>> getMapQueue() {
return mapQueue;
}
}4、编写ZkConnectRunner,负责一级引擎节点创建
package net.hw.zk;
import net.hw.common.GlobalEnv;
import net.hw.common.OwnEnv;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import java.net.InetAddress;
public class ZkConnectRunner implements Runnable {
private ZooKeeper zk;
@Override
public void run() {
try {
// 连接zk服务器获取zk对象
zk = GlobalEnv.connectZkServer();
// 定义节点信息字符串
String nodeInfo = InetAddress.getLocalHost().toString() + "/" + OwnEnv.getRpcPort() + "/free";
// 创建一级引擎的一级节点
if (zk.exists(GlobalEnv.getEngine1Path(), false) == null) {
zk.create(GlobalEnv.getEngine1Path(), "engine01".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
// 创建一级引擎的二级节点
zk.create(GlobalEnv.getEngine1Path() + OwnEnv.getZnodePath(),
nodeInfo.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e) {
e.printStackTrace();
}
}
}5、创建RpcFileSplitImpl类,实现RpcFileSplit接口

package net.hw.rpc;
import net.hw.common.OwnEnv;
import org.apache.avro.AvroRemoteException;
import rpc.domain.FileSplit;
import rpc.service.RpcFileSplit;
public class RpcFileSplitImpl implements RpcFileSplit {
@Override
public Void sendFileSplit(FileSplit fileSplit) throws AvroRemoteException {
// 提示用户收到jobtracker派发的任务
System.out.println("一级引擎02节点收到jobtracker发送过来的" + fileSplit);
// 将收到的文件切片对象添加到一级引擎的文件切片队列
OwnEnv.getSplitQueue().add(fileSplit);
return null;
}
}顺带修改一下zebra_engine1_01里的RpcFileSplitImpl类代码:
6、创建RpcServerRunner类
package net.hw.rpc;
import net.hw.common.OwnEnv;
import org.apache.avro.ipc.NettyServer;
import org.apache.avro.ipc.specific.SpecificResponder;
import rpc.service.RpcFileSplit;
import java.net.InetSocketAddress;
public class RpcServerRunner implements Runnable{
@Override
public void run() {
// 创建NettyServer对象
NettyServer server = new NettyServer(new SpecificResponder(RpcFileSplit.class, new RpcFileSplitImpl()),
new InetSocketAddress(OwnEnv.getRpcPort()));
// 提示用户
System.out.println("一级引擎02节点的RPC服务启动了~");
}
}顺带修改一下zebra_engine1_01里的RpcServerRunner代码:
7、创建StartEngine1_02类,利用线程池启动ZkConnectRunner线程和RpcServerRunner线程

package net.hw.common;
import net.hw.rpc.RpcServerRunner;
import net.hw.zk.ZkConnectRunner;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class StartEngine1_02 {
public static void main(String[] args) {
// 创建缓存线程池(大池子,小队列)
ExecutorService es = Executors.newCachedThreadPool();
// 启动连接zk服务器线程类
es.submit(new ZkConnectRunner());
// 启动一级引擎接收jobtrackerp派发任务的线程类
es.submit(new RpcServerRunner());
}
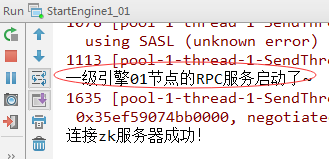
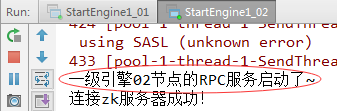
}8、测试一级引擎两个节点能否收到jobtracker发送的文件切片(1)启动StartEngine1_01和StartEngine1_02
(2)启动StartJobTracker
(3)切换到StartEngine1_01和StartEngine1_02的控制台

一级引擎01节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 0, "length": 3000000}

一级引擎02节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 3000000, "length": 3000000}
到目前为止,jobtracker将四个文件切片中的第一个切片发送给了一级引擎01节点,将第二个切片发送给了一级引擎02节点,还有两个文件切片没有发送,因此,我们需要去修改jobtracker里的RpcClientRunner代码,可以让所有文件切片都发送到一级引擎。
9、修改zebra_jobtracker模块的RpcClientRunner
package net.hw.rpc;
import net.hw.common.GlobalEnv;
import org.apache.avro.AvroRemoteException;
import org.apache.avro.ipc.NettyTransceiver;
import org.apache.avro.ipc.specific.SpecificRequestor;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import rpc.domain.FileSplit;
import rpc.service.RpcFileSplit;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.Proxy;
import java.util.concurrent.CountDownLatch;
public class RpcClientRunner implements Runnable {
private String childPath;
private ZooKeeper zk;
public RpcClientRunner(String childPath, ZooKeeper zk) {
this.childPath = childPath;
this.zk = zk;
}
@Override
public void run() {
// 输出一级引擎子节点路径
System.out.println("childPath: " + childPath);
try {
// 获取一级引擎子节点数据
final byte[][] data = {zk.getData(GlobalEnv.getEngine1Path() + "/" + childPath, null, null)};
// 封装得到子节点信息(ip/port/free)
String info = new String(data[0]);
// 输出子节点信息
System.out.println("info: " + info);
// 通过拆分拿到rpc服务器端(一级引擎)的ip和port
String ip = info.split("/")[1];
int port = Integer.parseInt(info.split("/")[2]);
// 创建NettyTransceiver对象
NettyTransceiver transceiver = new NettyTransceiver(new InetSocketAddress(ip, port));
// 获取文件切片RPC客户端代理
final RpcFileSplit proxy = SpecificRequestor.getClient(RpcFileSplit.class, transceiver);
// 从文件切片队列里获取一个文件切片
FileSplit split = GlobalEnv.getFileSplitQueue().take();
// 将该文件切片发送到RPC服务器端(一级引擎)
proxy.sendFileSplit(split);
// 持续监听一级引擎对应节点状态变化
while (true) {
final CountDownLatch cdl = new CountDownLatch(1);
zk.getData(GlobalEnv.getEngine1Path() + "/" + childPath, new Watcher() {
@Override
public void process(WatchedEvent event) {
// 如果节点数据发生变化就获取节点数据进行判断
if (event.getType() == Event.EventType.NodeDataChanged) {
try {
// 获取节点数据
byte[] data = zk.getData(GlobalEnv.getEngine1Path() + "/" + childPath, null, null);
// 获取节点状态
String state = new String(data).split("/")[3];
// 输出节点状态
System.out.println("监听节点状态:" + state);
// 如果节点状态是free,那么就要发送文件切片
if (state.equals("free")) {
// 获取文件切片对象(理解为什么要用poll方法而不用remove和take)
FileSplit split = GlobalEnv.getFileSplitQueue().poll();
// 如果切片非空,那么就发送
if (split != null) {
proxy.sendFileSplit(split);
}
}
cdl.countDown();
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (AvroRemoteException e) {
e.printStackTrace();
}
}
}
}, null);
// 利用闭锁await方法产生阻塞,只能当监听到节点数据状态发生变化,才会消除阻塞
cdl.await();
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
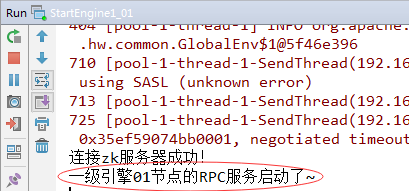
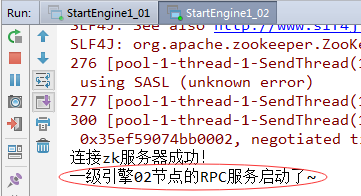
}10、测试一级引擎两个节点能否收到jobtracker发送的全部文件切片(1)启动StartEngine1_01和StartEngine1_02
(2)启动StartJobTracker
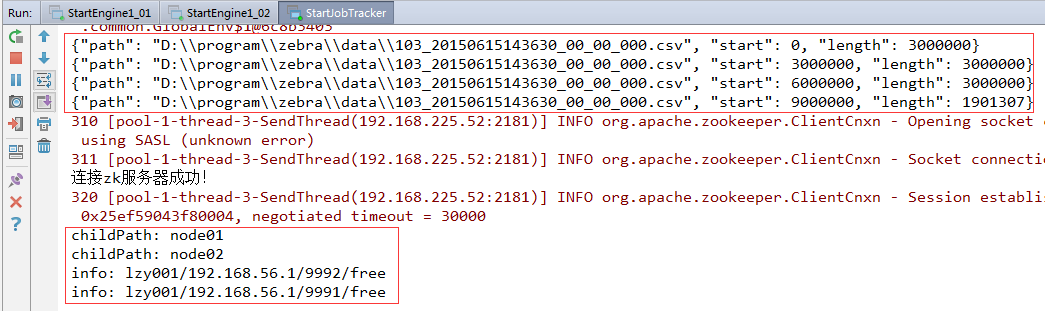
(3)切换到StartEngine1_01和StartEngine1_02的控制台


结果还是一样,仍有两个文件切片没有发送,因为一级引擎两个节点的状态目前都没有变化,都是free,只有在我们要写的一级引擎的MapperRunner代码根据业务修改了节点状态之后,才能监听到节点状态变化,从而将切片队列里其他剩余的切片给发送了。
六、zebra_engine1_01模块V1.1添加功能:读取文件切片,按|分割,提取所需字段进行封装,封装成map对象,然后利用rpc通信将它发送到二级引擎。1、创建MapperRunner类,负责读取文件切片,按|分割、封装成zebra业务对象
package net.hw.mapper;
import net.hw.common.OwnEnv;
import net.hw.zk.ZkConnectRunner;
import rpc.domain.FileSplit;
import rpc.domain.HttpAppHost;
import java.io.*;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.util.HashMap;
import java.util.Map;
public class MapperRunner implements Runnable {
@Override
public void run() {
try {
while (true) {
//保存切块内容处理合并后的信息(后添加)
Map<CharSequence, HttpAppHost> map = new HashMap<>();
FileSplit split = OwnEnv.getSplitQueue().take();
//将节点状态改为busy
ZkConnectRunner.setBusy();
File file = new File(split.getPath().toString());
long start = split.getStart();
long end = start + split.getLength();
//有可能切块后,考虑到不一定都是从行首、行尾切
//所以需要追溯start和end,均采用向前追溯的方式
FileInputStream in = new FileInputStream(file);
FileChannel fc = in.getChannel();
if (start != 0) {
long headPosition = start;
while (true) {
ByteBuffer buff = ByteBuffer.allocate(1);
fc.position(headPosition);
fc.read(buff);
if (new String(buff.array()).equals("\n")) {
start = headPosition + 1;
break;
} else {
headPosition--;
}
}
}
if (end != file.length()) {
long tailPosition = end;
while (true) {
ByteBuffer buf = ByteBuffer.allocate(1);
fc.position(tailPosition);
fc.read(buf);
if (new String(buf.array()).equals("\n")) {
end = tailPosition;
break;
} else {
tailPosition--;
}
}
}
//start和end处理完后,读取本次切块的所有行
ByteBuffer buffer = ByteBuffer.allocate((int) (end - start));
fc.position(start);
fc.read(buffer);
//一行行进行读取
BufferedReader br = new BufferedReader(
new InputStreamReader(
new ByteArrayInputStream(buffer.array())));
String line = null;
while ((line = br.readLine()) != null) {
String data[] = line.split("\\|");
//以下代码从业务说明文档的业务字段处理逻辑处拷贝
HttpAppHost hah = new HttpAppHost();
String reportTime = file.getPath().toString().split("_")[1];
hah.setReportTime(reportTime);
//上网小区的id
hah.setCellid(data[16]);
//应用大类
hah.setAppType(Integer.parseInt(data[22]));
//应用子类
hah.setAppSubtype(Integer.parseInt(data[23]));
//用户ip
hah.setUserIP(data[26]);
//用户port
hah.setUserPort(Integer.parseInt(data[28]));
//访问的服务ip
hah.setAppServerIP(data[30]);
//访问的服务port
hah.setAppServerPort(Integer.parseInt(data[32]));
//域名
hah.setHost(data[58]);
int appTypeCode = Integer.parseInt(data[18]);
String transStatus = data[54];
//业务逻辑处理
if (hah.getCellid() == null || hah.getCellid().equals("")) {
hah.setCellid("000000000");
}
//如果状态码103,就把尝试请求次数设为1
if (appTypeCode == 103) {
hah.setAttempts(1);
}
//如果状态码103,并且传输码包括这么多……,就把接收次数设置为1
if (appTypeCode == 103 && "10,11,12,13,14,15,32,33,34,35,36,37,38,48,49,50,51,52,53,54,55,199,200,201,202,203,204,205 ,206,302,304,306".contains(transStatus)) {
hah.setAccepts(1);
} else {
hah.setAccepts(0);
}
//如果是103,就设置用户发生的上传流量,后续后统计每个用户产生的总的上传流量
if (appTypeCode == 103) {
hah.setTrafficUL(Long.parseLong(data[33]));
}
//如果是103,设置下行流量
if (appTypeCode == 103) {
hah.setTrafficDL(Long.parseLong(data[34]));
}
//如果是103,设置重传上行流量
if (appTypeCode == 103) {
hah.setRetranUL(Long.parseLong(data[39]));
}
//如果是103,设置重传下行流量
if (appTypeCode == 103) {
hah.setRetranDL(Long.parseLong(data[40]));
}
//如果是103,设置用户的传输延迟
if (appTypeCode == 103) {
hah.setTransDelay(Long.parseLong(data[20]) - Long.parseLong(data[19]));
}
//标识用户的key
CharSequence key = hah.getReportTime() + "|" + hah.getAppType() + "|" + hah.getAppSubtype() + "|" + hah.getUserIP() + "|" + hah.getUserPort() + "|" + hah.getAppServerIP() + "|" + hah.getAppServerPort() + "|" + hah.getHost() + "|" + hah.getCellid();
// hah=>map
if (map.containsKey(key)) {
HttpAppHost mapHah = map.get(key);
mapHah.setAccepts(mapHah.getAccepts() + hah.getAccepts());
mapHah.setAttempts(mapHah.getAttempts() + hah.getAttempts());
mapHah.setTrafficUL(mapHah.getTrafficUL() + hah.getTrafficUL());
mapHah.setTrafficDL(mapHah.getTrafficDL() + hah.getTrafficDL());
mapHah.setRetranUL(mapHah.getRetranUL() + hah.getRetranUL());
mapHah.setRetranDL(mapHah.getRetranDL() + hah.getRetranDL());
mapHah.setTransDelay(mapHah.getTransDelay() + hah.getTransDelay());
map.put(key, mapHah);
} else {
map.put(key, hah);
}
//拷贝结束
}
//将map保存到队列中
OwnEnv.getMapQueue().add(map);
//将节点状态改为free
ZkConnectRunner.setFree();
System.out.println("map.size=" + map.size());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}说明:进入业务对象封装工作,节点状态设置为busy,此时不能接收jobtracker发送的切片;然后等到封装工作完成,节点状态设置为free,此时又可以接收jobtracker发送的文件切片。
下面,我们在ZkConnectRunner类定义两个静态方法setBusy和setFree,用于设置一级引擎节点状态。
2、修改ZkConnectRunner类,添加两个静态方法
package net.hw.zk;
import net.hw.common.GlobalEnv;
import net.hw.common.OwnEnv;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import java.net.InetAddress;
public class ZkConnectRunner implements Runnable {
private static ZooKeeper zk;
@Override
public void run() {
try {
// 连接zk服务器获取zk对象
zk = GlobalEnv.connectZkServer();
// 定义节点信息字符串
String nodeInfo = InetAddress.getLocalHost().toString() + "/" + OwnEnv.getRpcPort() + "/free";
// 创建一级引擎的一级节点
if (zk.exists(GlobalEnv.getEngine1Path(), false) == null) {
zk.create(GlobalEnv.getEngine1Path(), "engine01".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
// 创建一级引擎的二级节点
zk.create(GlobalEnv.getEngine1Path() + OwnEnv.getZnodePath(),
nodeInfo.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e) {
e.printStackTrace();
}
}
public static void setBusy() throws Exception {
// 定义节点信息字符串
String nodeInfo = InetAddress.getLocalHost().toString() + "/" + OwnEnv.getRpcPort() + "/busy";
// 更新节点数据
zk.setData(GlobalEnv.getEngine1Path() + OwnEnv.getZnodePath(), nodeInfo.getBytes(), -1);
}
public static void setFree() throws Exception {
// 定义节点信息字符串
String nodeInfo = InetAddress.getLocalHost().toString() + "/" + OwnEnv.getRpcPort() + "/free";
// 更新节点数据
zk.setData(GlobalEnv.getEngine1Path() + OwnEnv.getZnodePath(), nodeInfo.getBytes(), -1);
}
}3、修改StartEngine1_01类
4、创建RpcClientRunner,负责向二级引擎发送处理后的map对于一级引擎与二级引擎之间的RPC通信,一级引擎是RPC客户端,二级引擎是RPC服务器端。
一级引擎相对于jobtracker是RPC服务器端,但相对于二级引擎又是RPC客户端。
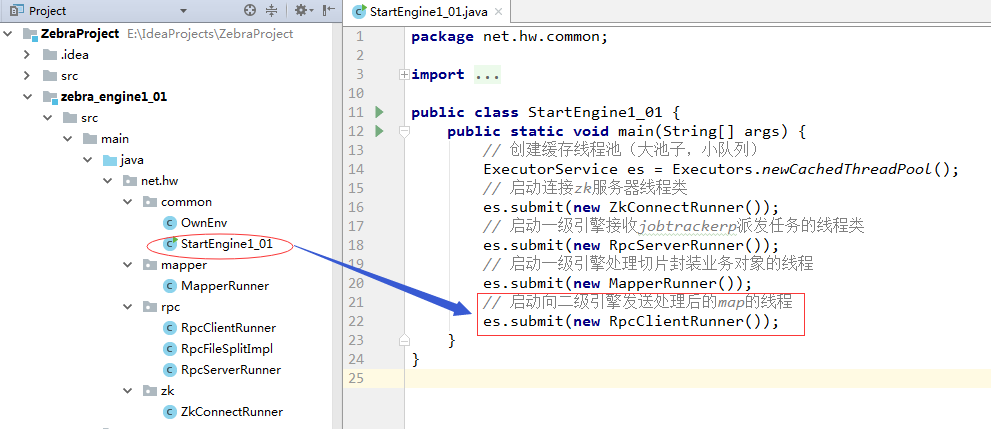
七、zebra_engine1_02模块V1.11、修改ZkConnectRunnet类,添加两个静态方法
2、创建MapperRunner类
package net.hw.mapper;
import net.hw.common.OwnEnv;
import net.hw.zk.ZkConnectRunner;
import rpc.domain.FileSplit;
import rpc.domain.HttpAppHost;
import java.io.*;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.util.HashMap;
import java.util.Map;
public class MapperRunner implements Runnable {
@Override
public void run() {
try {
while (true) {
//保存切块内容处理合并后的信息(后添加)
Map<CharSequence, HttpAppHost> map = new HashMap<>();
FileSplit split = OwnEnv.getSplitQueue().take();
//将节点状态改为busy
ZkConnectRunner.setBusy();
File file = new File(split.getPath().toString());
long start = split.getStart();
long end = start + split.getLength();
//有可能切块后,考虑到不一定都是从行首、行尾切
//所以需要追溯start和end,均采用向前追溯的方式
FileInputStream in = new FileInputStream(file);
FileChannel fc = in.getChannel();
if (start != 0) {
long headPosition = start;
while (true) {
ByteBuffer buff = ByteBuffer.allocate(1);
fc.position(headPosition);
fc.read(buff);
if (new String(buff.array()).equals("\n")) {
start = headPosition + 1;
break;
} else {
headPosition--;
}
}
}
if (end != file.length()) {
long tailPosition = end;
while (true) {
ByteBuffer buf = ByteBuffer.allocate(1);
fc.position(tailPosition);
fc.read(buf);
if (new String(buf.array()).equals("\n")) {
end = tailPosition;
break;
} else {
tailPosition--;
}
}
}
//start和end处理完后,读取本次切块的所有行
ByteBuffer buffer = ByteBuffer.allocate((int) (end - start));
fc.position(start);
fc.read(buffer);
//一行行进行读取
BufferedReader br = new BufferedReader(
new InputStreamReader(
new ByteArrayInputStream(buffer.array())));
String line = null;
while ((line = br.readLine()) != null) {
String data[] = line.split("\\|");
//以下代码从业务说明文档的业务字段处理逻辑处拷贝
HttpAppHost hah = new HttpAppHost();
String reportTime = file.getPath().toString().split("_")[1];
hah.setReportTime(reportTime);
//上网小区的id
hah.setCellid(data[16]);
//应用大类
hah.setAppType(Integer.parseInt(data[22]));
//应用子类
hah.setAppSubtype(Integer.parseInt(data[23]));
//用户ip
hah.setUserIP(data[26]);
//用户port
hah.setUserPort(Integer.parseInt(data[28]));
//访问的服务ip
hah.setAppServerIP(data[30]);
//访问的服务port
hah.setAppServerPort(Integer.parseInt(data[32]));
//域名
hah.setHost(data[58]);
int appTypeCode = Integer.parseInt(data[18]);
String transStatus = data[54];
//业务逻辑处理
if (hah.getCellid() == null || hah.getCellid().equals("")) {
hah.setCellid("000000000");
}
//如果状态码103,就把尝试请求次数设为1
if (appTypeCode == 103) {
hah.setAttempts(1);
}
//如果状态码103,并且传输码包括这么多……,就把接收次数设置为1
if (appTypeCode == 103 && "10,11,12,13,14,15,32,33,34,35,36,37,38,48,49,50,51,52,53,54,55,199,200,201,202,203,204,205 ,206,302,304,306".contains(transStatus)) {
hah.setAccepts(1);
} else {
hah.setAccepts(0);
}
//如果是103,就设置用户发生的上传流量,后续后统计每个用户产生的总的上传流量
if (appTypeCode == 103) {
hah.setTrafficUL(Long.parseLong(data[33]));
}
//如果是103,设置下行流量
if (appTypeCode == 103) {
hah.setTrafficDL(Long.parseLong(data[34]));
}
//如果是103,设置重传上行流量
if (appTypeCode == 103) {
hah.setRetranUL(Long.parseLong(data[39]));
}
//如果是103,设置重传下行流量
if (appTypeCode == 103) {
hah.setRetranDL(Long.parseLong(data[40]));
}
//如果是103,设置用户的传输延迟
if (appTypeCode == 103) {
hah.setTransDelay(Long.parseLong(data[20]) - Long.parseLong(data[19]));
}
//标识用户的key
CharSequence key = hah.getReportTime() + "|" + hah.getAppType() + "|" + hah.getAppSubtype() + "|" + hah.getUserIP() + "|" + hah.getUserPort() + "|" + hah.getAppServerIP() + "|" + hah.getAppServerPort() + "|" + hah.getHost() + "|" + hah.getCellid();
// hah=>map
if (map.containsKey(key)) {
HttpAppHost mapHah = map.get(key);
mapHah.setAccepts(mapHah.getAccepts() + hah.getAccepts());
mapHah.setAttempts(mapHah.getAttempts() + hah.getAttempts());
mapHah.setTrafficUL(mapHah.getTrafficUL() + hah.getTrafficUL());
mapHah.setTrafficDL(mapHah.getTrafficDL() + hah.getTrafficDL());
mapHah.setRetranUL(mapHah.getRetranUL() + hah.getRetranUL());
mapHah.setRetranDL(mapHah.getRetranDL() + hah.getRetranDL());
mapHah.setTransDelay(mapHah.getTransDelay() + hah.getTransDelay());
map.put(key, mapHah);
} else {
map.put(key, hah);
}
//拷贝结束
}
//将map保存到队列中
OwnEnv.getMapQueue().add(map);
//将节点状态改为free
ZkConnectRunner.setFree();
System.out.println("map.size=" + map.size());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}3、创建RpcClientRunner类
package net.hw.rpc; import net.hw.common.GlobalEnv; import net.hw.common.OwnEnv; import org.apache.avro.ipc.NettyTransceiver; import org.apache.avro.ipc.specific.SpecificRequestor; import org.apache.zookeeper.ZooKeeper; import rpc.service.RpcSendHttpAppHost; import java.net.InetSocketAddress; public class RpcClientRunner implements Runnable { private ZooKeeper zk; @Override public void run() { try { // 获取zk对象 zk = GlobalEnv.connectZkServer(); // 获取二级引擎节点数据 byte[] data = zk.getData(GlobalEnv.getEngine2Path(), null, null); // 封装成字符串 String info = new String(data); // 获取二级引擎ip和port String ip = info.split("/")[1]; int port = Integer.parseInt(info.split("/")[2]); // 创建网络收发器 NettyTransceiver transceiver = new NettyTransceiver(new InetSocketAddress(ip, port)); // 创建RPC通信客户端代理 RpcSendHttpAppHost proxy = SpecificRequestor.getClient(RpcSendHttpAppHost.class, transceiver); // 向二级引擎发送处理后的map while (true) { proxy.sendHttpAppHostMap(OwnEnv.getMapQueue().take()); } } catch (Exception e) { e.printStackTrace(); } } }4、修改StartEngine1_02类
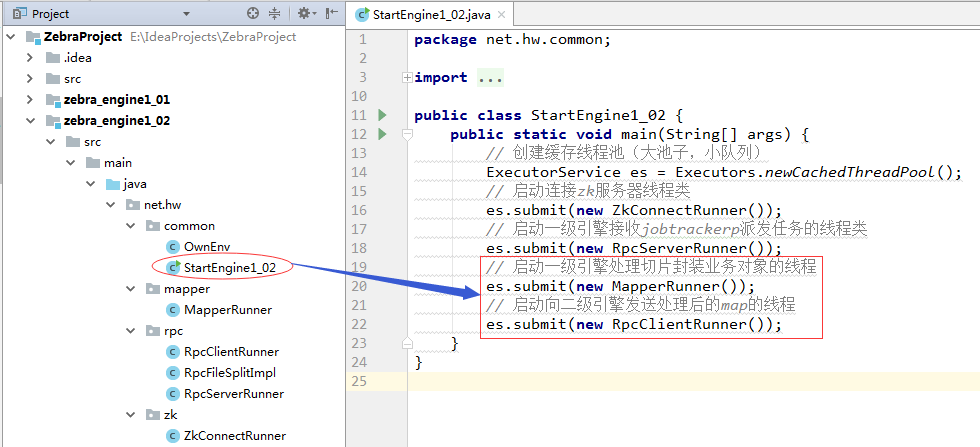
5、测试一级引擎能否收到jobtracker发送的全部文件切片
(1)启动StartEngine1_01和StartEngine1_02
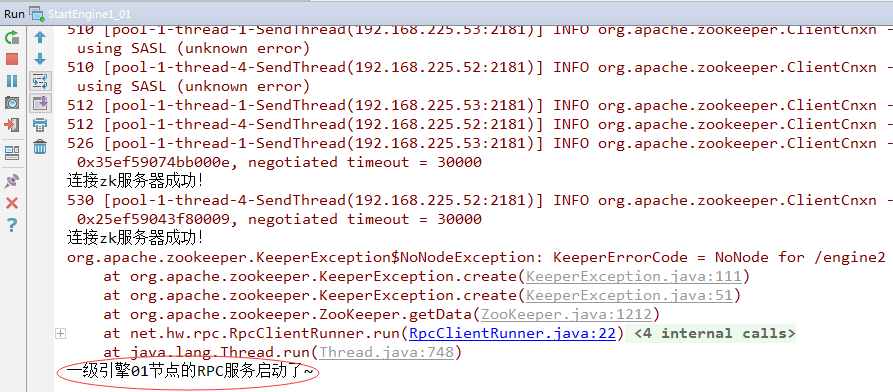

(2)启动StartJobTracker
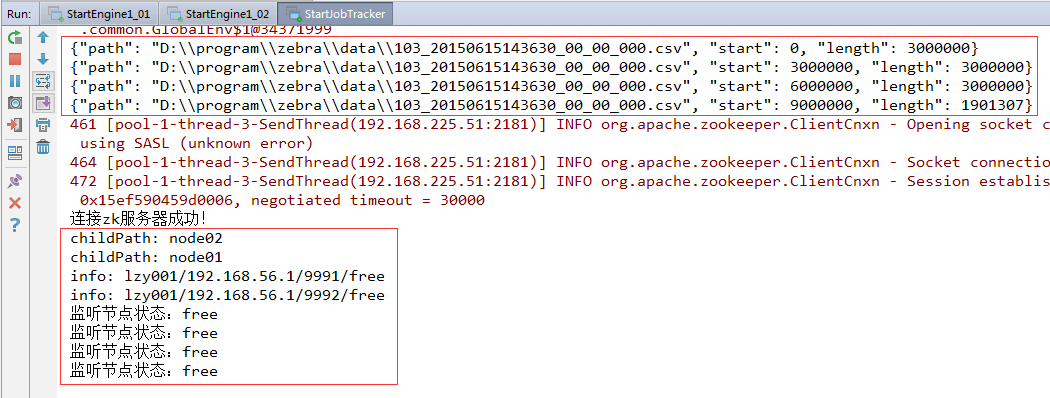
(3)切换到StartEngine1_01和StartEngine1_02的控制台
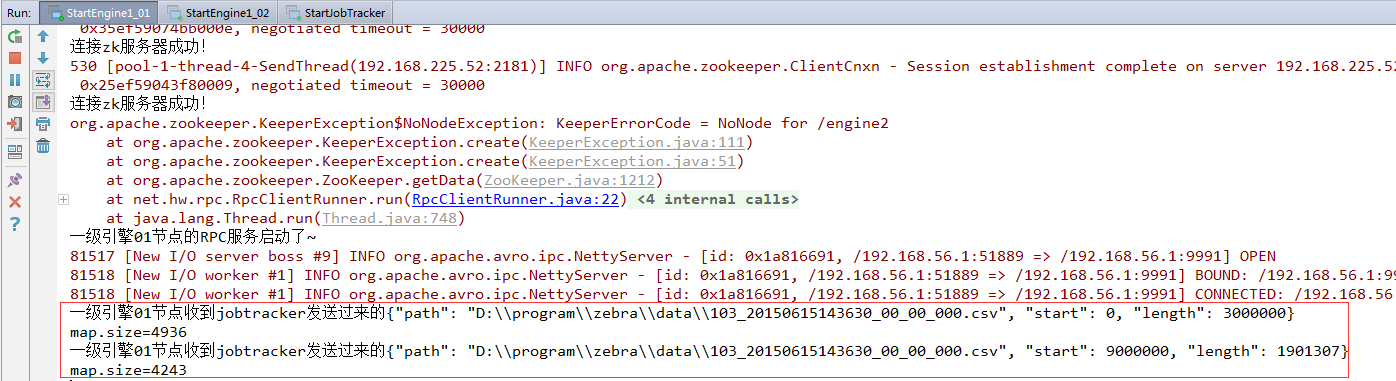
一级引擎01节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 0, "length": 3000000}map.size=4936一级引擎01节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 9000000, "length": 1901307}map.size=4243
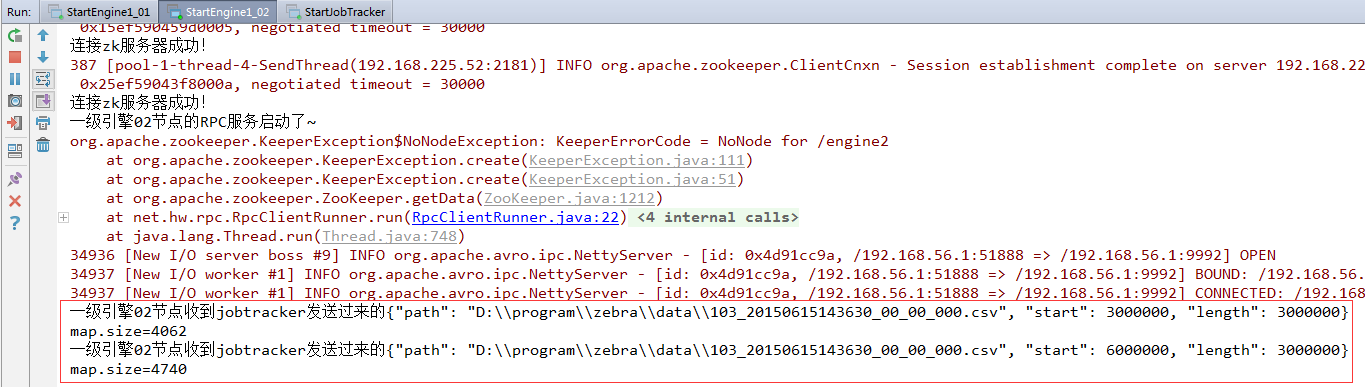
一级引擎02节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 3000000, "length": 3000000}map.size=4062一级引擎02节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 6000000, "length": 3000000}map.size=4740
结果分析:一级引擎两个节点收到jobtracker发送的四个切片(全部切片),01节点收到两个文件切片(第1个和第4个),02节点收到两个文件切片(第2个和第3个)。
错误信息:org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode = NoNode for /engine2
错误原因:还没有编写二级引擎模块代码,没有创建二级引擎节点/engine2。
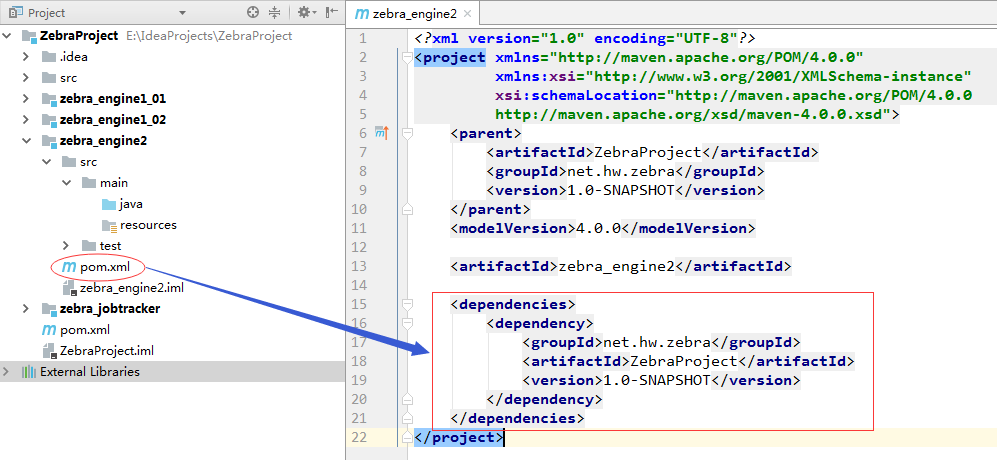
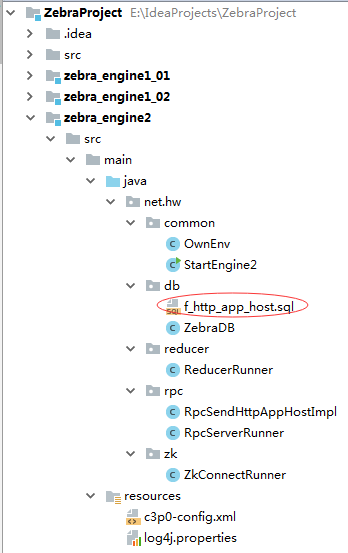
八、二级引擎zebra_engine2模块1、修改pom.xml文件,添加对父工程ZebraProject的依赖
2、创建ZkConnectRunner,负责创建二级引擎节点
package net.hw.zk;
import net.hw.common.GlobalEnv;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import java.net.InetAddress;
public class ZkConnectRunner implements Runnable {
private ZooKeeper zk;
@Override
public void run() {
try {
// 获取zk连接对象
zk = GlobalEnv.connectZkServer();
// 定义节点信息字符串
String nodeInfo = InetAddress.getLocalHost().toString() + "/8888";
// 创建二级引擎节点
zk.create(GlobalEnv.getEngine2Path(), nodeInfo.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e) {
e.printStackTrace();
}
}
}3、创建OwnEnv类
package net.hw.common;
import rpc.domain.HttpAppHost;
import java.util.Map;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class OwnEnv {
private static BlockingQueue<Map<CharSequence, HttpAppHost>> mapQueue = new LinkedBlockingQueue<Map<CharSequence, HttpAppHost>>();
public static BlockingQueue<Map<CharSequence, HttpAppHost>> getMapQueue() {
return mapQueue;
}
}4、创建ReducerRunner类
package net.hw.reducer;
import net.hw.common.OwnEnv;
import net.hw.db.ZebraDB;
import rpc.domain.HttpAppHost;
import java.util.HashMap;
import java.util.Map;
public class ReducerRunner implements Runnable {
private Map<String, HttpAppHost> resultMap = new HashMap<>();
@Override
public void run() {
while (true) {
// 从二级引擎的map队列中取出要进行归并的map对象(理解为什么要用poll方法)
Map<CharSequence, HttpAppHost> reduceMap = OwnEnv.getMapQueue().poll();
// 如果取完map队列中的元素,说明归并工作完成,跳出循环
if (reduceMap == null) {
System.out.println("二级引擎归并工作完成,跳出循环~");
break;
}
// 对reduceMap对象进行归并操作(遍历reduceMap的entrySet)
for (Map.Entry<CharSequence, HttpAppHost> entry : reduceMap.entrySet()) {
// 获取用户标识
String key = entry.getKey().toString();
// 获取用户对应的业务对象
HttpAppHost hah = entry.getValue();
// 判断resultMap中是否存在该key
if (resultMap.containsKey(key)) {
// 从resultMap中获取该key对应的业务对象
HttpAppHost map = resultMap.get(key);
// 设置map的属性值(累加)
map.setAccepts(map.getAccepts() + hah.getAccepts());
map.setAttempts(map.getAttempts() + hah.getAttempts());
map.setTrafficUL(map.getTrafficUL() + hah.getTrafficUL());
map.setTrafficDL(map.getTrafficDL() + hah.getTrafficDL());
map.setRetranUL(map.getRetranUL() + hah.getRetranUL());
map.setRetranDL(map.getRetranDL() + hah.getRetranDL());
map.setTransDelay(map.getTransDelay() + hah.getTransDelay());
} else {
resultMap.put(key, hah);
}
}
}
// 归并工作完成,提示用户
System.out.println("归并后的map:" + resultMap.size());
// 数据落地,将处理后的map数据保存到数据库
ZebraDB.toDb(resultMap);
}
}5、创建RpcSendHttpAppHostImpl类
package net.hw.rpc;
import net.hw.common.OwnEnv;
import net.hw.reducer.ReducerRunner;
import org.apache.avro.AvroRemoteException;
import rpc.domain.HttpAppHost;
import rpc.service.RpcSendHttpAppHost;
import java.util.Map;
public class RpcSendHttpAppHostImpl implements RpcSendHttpAppHost{
@Override
public Void sendHttpAppHost(HttpAppHost httpAppHost) throws AvroRemoteException {
return null;
}
@Override
public Void sendHttpAppHostMap(Map<CharSequence, HttpAppHost> hahMap) throws AvroRemoteException {
// 提示用户收到一级引擎发送过来的map
System.out.println("二级引擎收到了一级引擎传递过来的map:" + hahMap.size());
// 将收到的map添加到二级引擎的map队列
OwnEnv.getMapQueue().add(hahMap);
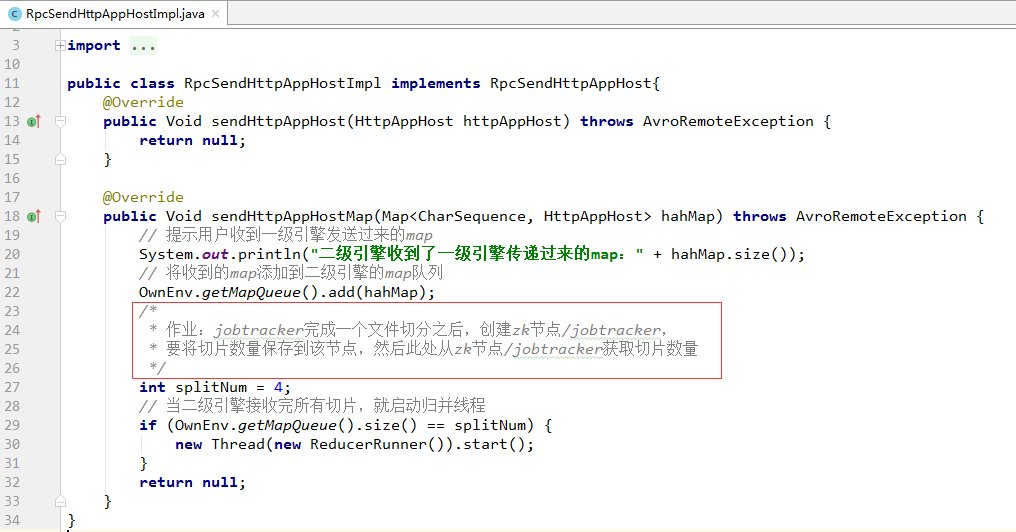
/*
* 作业:jobtracker完成一个文件切分之后,创建zk节点/jobtracker,
* 要将切片数量保存到该节点,然后此处从zk节点/jobtracker获取切片数量
*/
int splitNum = 4;
// 当二级引擎接收完所有切片,就启动归并线程
if (OwnEnv.getMapQueue().size() == splitNum) {
new Thread(new ReducerRunner()).start();
}
return null;
}
}6、创建RpcServerRunner
package net.hw.rpc;
import org.apache.avro.ipc.NettyServer;
import org.apache.avro.ipc.specific.SpecificResponder;
import rpc.service.RpcSendHttpAppHost;
import java.net.InetSocketAddress;
public class RpcServerRunner implements Runnable {
@Override
public void run() {
// 创建NettyServer对象
NettyServer server = new NettyServer(new SpecificResponder(RpcSendHttpAppHost.class,
new RpcSendHttpAppHostImpl()), new InetSocketAddress(8888));
}
}7、创建数据库连接池配置文件c3p0-config.xml
<?xml version="1.0" ?>
<c3p0-config>
<default-config>
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql:///zebra</property>
<property name="user">root</property>
<property name="password">root</property>
</default-config>
</c3p0-config>8、创建日志属性文件log4j.properties
log4j.rootLogger = error,D,stdout
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
log4j.appender.D=org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File=logs/log.log
log4j.appender.D.Append=true
log4j.appender.D.Threshold=DEBUG
log4j.appender.D.layout=org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n9、创建ZebraDB类,让二级引擎处理的数据落地到数据库

package net.hw.db;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import rpc.domain.HttpAppHost;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Map;
public class ZebraDB {
private static ComboPooledDataSource source = new ComboPooledDataSource();
public static void toDb(Map<String, HttpAppHost> reduceMap) {
Connection conn = null;
try {
conn = source.getConnection();
conn.setAutoCommit(false);
String sql = "insert into f_http_app_host values (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)";
PreparedStatement ps = conn.prepareStatement(sql);
int i = 0;
for (Map.Entry<String, HttpAppHost> entry : reduceMap.entrySet()) {
HttpAppHost hah = entry.getValue();
String reportTime = hah.getReportTime().toString();
String year = reportTime.substring(0, 4);
String month = reportTime.substring(4, 6);
String day = reportTime.substring(6, 8);
reportTime = year + "-" + month + "-" + day;
ps.setDate(1, java.sql.Date.valueOf(reportTime));
ps.setInt(2, hah.getAppType());
ps.setInt(3, hah.getAppSubtype());
ps.setString(4, hah.getUserIP().toString());
ps.setInt(5, hah.getUserPort());
ps.setString(6, hah.getAppServerIP().toString());
ps.setInt(7, hah.getAppServerPort());
ps.setString(8, hah.getHost().toString());
ps.setString(9, hah.getCellid().toString());
ps.setLong(10, hah.getAttempts());
ps.setLong(11, hah.getAccepts());
ps.setLong(12, hah.getTrafficUL());
ps.setLong(13, hah.getTrafficDL());
ps.setLong(14, hah.getRetranUL());
ps.setLong(15, hah.getRetranDL());
ps.setLong(16, 1l);
ps.setLong(17, hah.getTransDelay());
ps.addBatch();
i++;
if (i % 1000 == 0) {
ps.executeBatch();
ps.clearBatch();
}
}
//防止有残余的信息没有处理
ps.executeBatch();
conn.commit();
} catch (Exception e) {
try {
conn.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
e.printStackTrace();
} finally {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
conn = null;
e.printStackTrace();
} finally {
conn = null;
}
}
}
System.out.println("数据已经全部写到数据库里。");
}
}10、创建StartEngine2类,通过线程池来启动线程
package net.hw.common;
import net.hw.rpc.RpcServerRunner;
import net.hw.zk.ZkConnectRunner;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
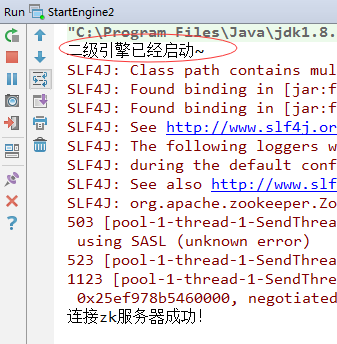
public class StartEngine2 {
public static void main(String[] args) {
// 提示用户
System.out.println("二级引擎已经启动~");
// 创建缓存线程池(大池子,小队列)
ExecutorService es = Executors.newCachedThreadPool();
// 启动连接zk服务器的线程
es.submit(new ZkConnectRunner());
// 启动RPC服务器端线程
es.submit(new RpcServerRunner());
}
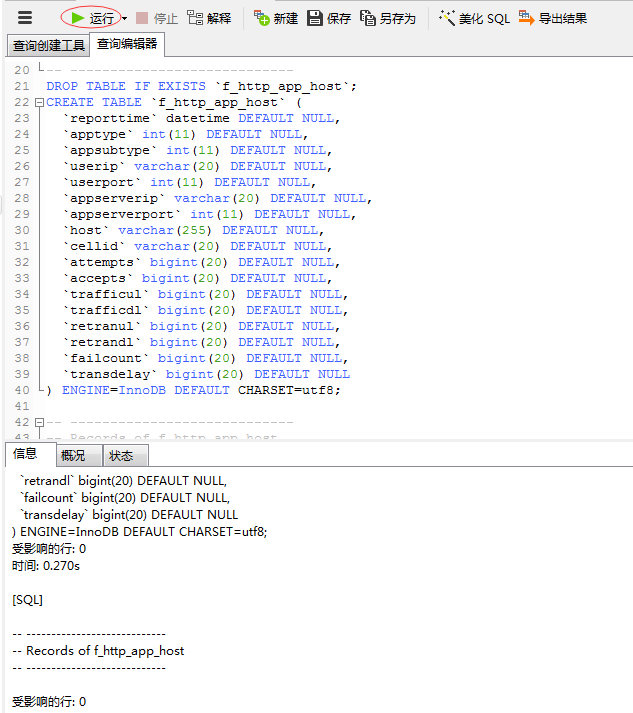
}11、创建数据库zebra,导入建表脚本(1)创建zebra数据库
(2)利用建表脚本创建表
/*
Navicat MySQL Data Transfer
Source Server : mysql
Source Server Version : 50544
Source Host : localhost:3306
Source Database : zebra
Target Server Type : MYSQL
Target Server Version : 50544
File Encoding : 65001
Date: 2016-10-25 23:49:02
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for `f_http_app_host`
-- ----------------------------
DROP TABLE IF EXISTS `f_http_app_host`;
CREATE TABLE `f_http_app_host` (
`reporttime` datetime DEFAULT NULL,
`apptype` int(11) DEFAULT NULL,
`appsubtype` int(11) DEFAULT NULL,
`userip` varchar(20) DEFAULT NULL,
`userport` int(11) DEFAULT NULL,
`appserverip` varchar(20) DEFAULT NULL,
`appserverport` int(11) DEFAULT NULL,
`host` varchar(255) DEFAULT NULL,
`cellid` varchar(20) DEFAULT NULL,
`attempts` bigint(20) DEFAULT NULL,
`accepts` bigint(20) DEFAULT NULL,
`trafficul` bigint(20) DEFAULT NULL,
`trafficdl` bigint(20) DEFAULT NULL,
`retranul` bigint(20) DEFAULT NULL,
`retrandl` bigint(20) DEFAULT NULL,
`failcount` bigint(20) DEFAULT NULL,
`transdelay` bigint(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of f_http_app_host
-- ----------------------------新建查询,执行查询:
测试整个zebra项目
1、启动二级引擎StartEngine2
2、启动两个一级引擎StartEngine1_01和StartEngine1_02
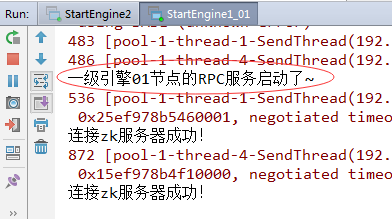

3、启动StartJobTracker
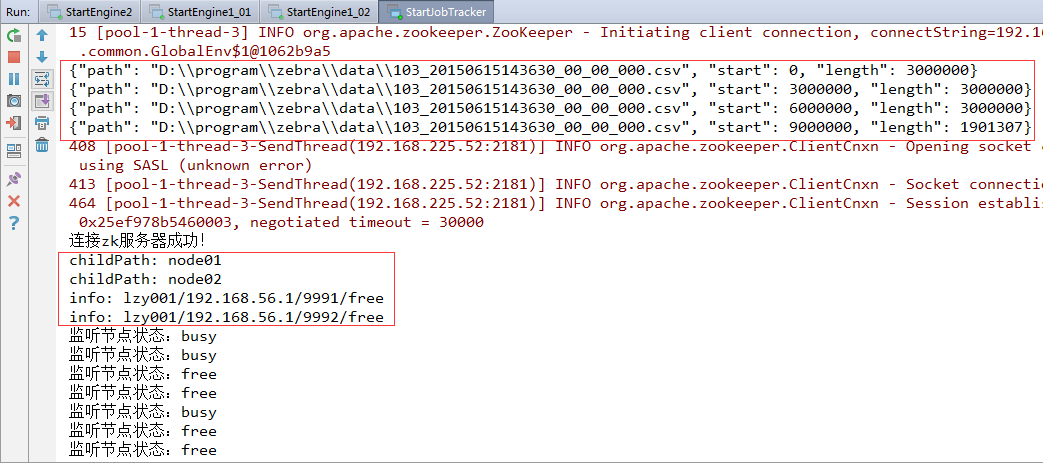
4、切换到StartEngine1_01的控制台

一级引擎01节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 3000000, "length": 3000000}一级引擎01节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 9000000, "length": 1901307}map.size=4062map.size=4243
5、切换到StartEngine1_02的控制台

一级引擎02节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 0, "length": 3000000}一级引擎02节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 6000000, "length": 3000000}map.size=4936map.size=4740
6、切换到StartEngine2的控制台

7、打开数据库zebra,查看是否有17980条记录在表里

九、课后作业jobtracker完成一个文件切分之后,创建zk节点/jobtracker,要将切片数量保存到该节点,然后从zk节点/jobtracker获取切片数量。
第一部分 Zebra项目概述一、Zebra项目介绍二、日志数据结构分析三、数据以| 分割后,每个数据项的含义四、Zebra项目整体架构(一)技术架构(二)工程架构五、Zebra业务说明六、Zebra项目设计思想
第二部分 Zebra项目实施过程一、创建Maven项目ZebraProject二、zebra_jobtracker模块V1.0三、zebra_engine1_01模块V1.0四、zebra_jobtracker模块V1.1五、zebra_engine1_02模块V1.0六、zebra_engine1_01模块V1.1七、zebra_engine1_02模块V1.1八、二级引擎zebra_engine2模块
第一部分 Zebra项目概述一、Zebra项目介绍
如图所示,电信运营商的用户通过连接到互联网中的各种网络设备访问一个网站时,其访问信息会通过基站在网络中传递,基站可以收集所有用户的访问日志数据。
Zebra项目是对电信运营商收集的用户上网数据进行分析的一个应用程序。通过分析得到的结果可以展现不同小区的上网详情。
二、日志数据结构分析日志里的某一条数据(以下为一整行数据,以| 为分割符):533||11|93287887015245963|6||||1|100.82.254.88|100.82.98.100|2152|2152|13849|147855076||||103|1409649427963|1409649428488|1|15|999||0|10.83.124.18||60914|0|137.175.9.211||80|734|329|4|2|0|0|0|0|221|29|0|0|20|221|12600|1260|1|0|1|3|6|200|221|221|255|559955.com|/tu/31322.JPG|559955.com|Mozilla/5.0 (Linux; Android 4.3; zh-cn; SAMSUNG-SM-G7108V_TD Release/02.15.2014 Browser/AppleWebKit537.36 Build/JSS15J) AppleWebkit/537.36 (KHTML, like Gecko) Version/1.5 Mobile Safari/537.36||http://www.701111.com/||0|0|0|0|||3|0|525|0|0|1:734/329
三、数据以| 分割后,每个数据项的含义(仅展示项目里用到的字段数据)
这是需要处理的每行数据中的字段,通过对这些数据的处理,可以得到不同小区的上网详情数据。具体来说,就是把一段时间内的同一个小区内访问同一网站、同一个ip的访问累计起来,就可以得到某小区内对某网站的访问详情。
四、Zebra项目整体架构(一)技术架构1、maven利用Maven工程来管理项目。主要是利用Maven来管理jar包,以及利用maven生成avro的rpc方法及序列化对象。2、avro利用avro实现对象的序列化以及节点间的rpc通信。3、zookeeper利用zookeeper达到分布式环境的协调服务。
(二)工程架构
1、ZebraProject工程① 管理整个项目的pom.xml文件② 定义全局变量参数③ 定义avro相关的avsc文件及avdl文件
2、zebra_jobtracker模块① 定时扫描是否有待处理文件② 根据用户定义的参数,对文件进行逻辑切块。③ 根据文件切块数量生成对应的任务数量。(一个文件块相当于一个任务)④ 将任务分发给一级引擎节点(TaskTracker )去处理。并通过zookeeper监控TaskTracker的状态来决定任务分配
3、zebra_engine1模块① 接收jobtracker发来的任务,根据任务进行对文件的处理② 将文件数据进行清洗和整理。(根据zebra要求的业务逻辑进行数据整理)③ 将处理完的数据发给二级引擎,二级引擎做最后的合并④ 通过zookeeper,注册自身节点信息状态,便于集群其他机器监控继而做相关的业务逻辑处理
4、zebra_engine2模块① 接收(一个或多个)一级引擎发来的数据。② 对数据进行归并处理③ 将最后处理的数据结果落地(写文件或写数据库)
五、Zebra业务说明1、数据项含义
2、应用大类说明
3、应用小类说明
4、业务字段处理逻辑
HttpAppHost hah = new HttpAppHost();
hah.setReportTime(reportTime);
//上网小区的id
hah.setCellid(data[16]);
//应用大类
hah.setAppType(Integer.parseInt(data[22]));
//应用子类
hah.setAppSubtype(Integer.parseInt(data[23]));
//用户ip
hah.setUserIP(data[26]);
//用户port
hah.setUserPort(Integer.parseInt(data[28]));
//访问的服务ip
hah.setAppServerIP(data[30]);
//访问的服务port
hah.setAppServerPort(Integer.parseInt(data[32]));
//域名
hah.setHost(data[58]);
int appTypeCode = Integer.parseInt(data[18]);
String transStatus = data[54];
//业务逻辑处理
if (hah.getCellid() == null || hah.getCellid().equals("")) {
hah.setCellid("000000000");
}
//如果状态码103,就把尝试请求次数设为1
if (appTypeCode == 103) {
hah.setAttempts(1);
}
//如果状态码103,并且传输码包括这么多……,就把接收次数设置为1
if (appTypeCode == 103 && "10,11,12,13,14,15,32,33,34,35,36,37,38,48,49,50,51,52,53,54,55,199,200,201,202,203,204,205 ,206,302,304,306".contains(transStatus)) {
hah.setAccepts(1);
} else {
hah.setAccepts(0);
}
//如果是103,就设置用户发生的上传流量,后续后统计每个用户产生的总的上传流量
if (appTypeCode == 103) {
hah.setTrafficUL(Long.parseLong(data[33]));
}
//如果是103,设置下行流量
if (appTypeCode == 103) {
hah.setTrafficDL(Long.parseLong(data[34]));
}
//如果是103,设置重传上行流量
if (appTypeCode == 103) {
hah.setRetranUL(Long.parseLong(data[39]));
}
//如果是103,设置重传下行流量
if (appTypeCode == 103) {
hah.setRetranDL(Long.parseLong(data[40]));
}
//如果是103,设置用户的传输延迟
if (appTypeCode == 103) {
hah.setTransDelay(Long.parseLong(data[20]) - Long.parseLong(data[19]));
}
//标识用户的key
CharSequence key = hah.getReportTime() + "|" + hah.getAppType() + "|" + hah.getAppSubtype() + "|" + hah.getUserIP() + "|" + hah.getUserPort() + "|" + hah.getAppServerIP() + "|" + hah.getAppServerPort() + "|" + hah.getHost() + "|" + hah.getCellid();
//hah=>map
if (map.containsKey(key)) {
HttpAppHost mapHah = map.get(key);
mapHah.setAccepts(mapHah.getAccepts() + hah.getAccepts());
mapHah.setAttempts(mapHah.getAttempts() + hah.getAttempts());
mapHah.setTrafficUL(mapHah.getTrafficUL() + hah.getTrafficUL());
mapHah.setTrafficDL(mapHah.getTrafficDL() + hah.getTrafficDL());
mapHah.setRetranUL(mapHah.getRetranUL() + hah.getRetranUL());
mapHah.setRetranDL(mapHah.getRetranDL() + hah.getRetranDL());
mapHah.setTransDelay(mapHah.getTransDelay() + hah.getTransDelay());
map.put(key, mapHah);
} else {
map.put(key, hah);
}5、zebra业务说明zebra项目最开始阶段会对日志文件进行分析统计,然后把最后结果落地到数据库里。总表f_http_app_host:
建表语句:
CREATE TABLE F_HTTP_APP_HOST ( reporttime DATETIME, apptype INT, appsubtype INT, userip VARCHAR(20), userport INT, appserverip VARCHAR(20), appserverport INT, host VARCHAR(255), cellid VARCHAR(20), attempts BIGINT, accepts BIGINT, trafficul BIGINT, trafficdl BIGINT, retranul BIGINT, retrandl BIGINT, failcount BIGINT, transdelay BIGINT );
后期可能会根据统计出来的数据进行业务拆分,形成几个不同的维度进行查询:(1)应用欢迎度;(2)各网站表现;(3)小区Http上网能力;(4)小区上网喜好。
(1)应用欢迎度表说明
建表语句:
CREATE TABLE D_H_HTTP_APPTYPE ( hourid DATETIME, apptype INT, appsubtype INT, attempts BIGINT, accepts BIGINT, succratio BIGINT, trafficul BIGINT, trafficdl BIGINT, totaltraffic BIGINT, retranul BIGINT, retrandl BIGINT, retrantraffic BIGINT, failcount BIGINT, transdelay BIGINT );(2)各网站表现表说明
建表语句:
CREATE TABLE D_H_HTTP_HOST ( hourid DATETIME, host VARCHAR(255), appserverip VARCHAR(20), attempts BIGINT, accepts BIGINT, succratio BIGINT, trafficul BIGINT, trafficdl BIGINT, totaltraffic BIGINT, retranul BIGINT, retrandl BIGINT, retrantraffic BIGINT, failcount BIGINT, transdelay BIGINT );(3)小区HTTP上网能力表
建表语句:
CREATE TABLE D_H_HTTP_CELLID ( hourid DATETIME, cellid VARCHAR(20), attempts BIGINT, accepts BIGINT, succratio BIGINT, trafficul BIGINT, trafficdl BIGINT, totaltraffic BIGINT, retranul BIGINT, retrandl BIGINT, retrantraffic BIGINT, failcount BIGINT, transdelay BIGINT );(4)小区上网喜好表
建表语句:
CREATE TABLE D_H_HTTP_CELLID_HOST ( hourid DATETIME, cellid VARCHAR(20), host VARCHAR(255), attempts BIGINT, accepts BIGINT, succratio BIGINT, trafficul BIGINT, trafficdl BIGINT, totaltraffic BIGINT, retranul BIGINT, retrandl BIGINT, retrantraffic BIGINT, failcount BIGINT, transdelay BIGINT );六、Zebra项目设计思想1、单机思想Zebra项目采用单机思想进行数据处理(1)读取日志文件(2)一行一行读取日志文件(3)按|分割(4)根据业务规则,做字段的封装(5)统计每个用户产生的总流量(6)数据落地
日志文件103_20150615143630_00_00_000.csv:10.3MB
该日志文件总共有20802条记录。
2、四个进程职责jobtracker——>一级引擎01、一级引擎02——>二级引擎
说明:在RPC中,传数据的一端是客户端、接收数据的一端是服务器端。
(1)jobtracker的职责读取日志文件,做逻辑切分,切4块(每块3M)
通过rpc将task分给一级引擎,通过监听节点的状态变化做任务分发
(2)一级引擎01、02的职责处理task对应的日志数据
按照zebra业务规则做数据封装(Map)
通过rpc将数据传给二级引擎
(2)二级引擎的职责:接收一级引擎处理过的数据
等待一级引擎处理完后再做数据归并
3、重要的分区思想
第二部分 Zebra项目实施过程
一、创建Maven项目ZebraProject
1、添加四个子模块(1)添加zebra_jobtracker子模块
(2)添加zebra_engine1_01子模块
(3)添加zebra_engine1_02子模块
(4)添加zebra_engine2子模块
2、修改ZebraProject的pom.xml文件,添加依赖和插件
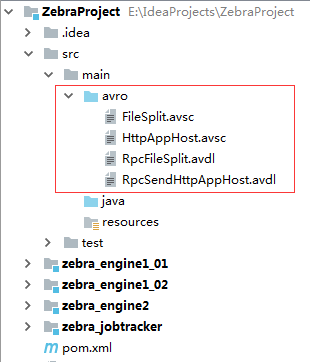
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>net.hw.zebra</groupId> <artifactId>ZebraProject</artifactId> <packaging>pom</packaging> <version>1.0-SNAPSHOT</version> <modules> <module>zebra_jobtracker</module> <module>zebra_engine1_01</module> <module>zebra_engine1_02</module> <module>zebra_engine2</module> </modules> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <compiler-plugin.version>2.3.2</compiler-plugin.version> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.10</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>1.6.4</version> <scope>compile</scope> </dependency> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.10</version> </dependency> <dependency> <groupId>org.apache.avro</groupId> <artifactId>avro</artifactId> <version>1.7.5</version> </dependency> <dependency> <groupId>org.apache.avro</groupId> <artifactId>avro-ipc</artifactId> <version>1.7.5</version> </dependency> <!-- c3p0 --> <dependency> <groupId>c3p0</groupId> <artifactId>c3p0</artifactId> <version>0.9.1.2</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.44</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>${compiler-plugin.version}</version> <configuration> <source>1.7</source> <target>1.7</target> </configuration> </plugin> <plugin> <groupId>org.apache.avro</groupId> <artifactId>avro-maven-plugin</artifactId> <version>1.7.5</version> <executions> <execution> <id>schemas</id> <phase>generate-sources</phase> <goals> <goal>schema</goal> <goal>protocol</goal> <goal>idl-protocol</goal> </goals> <configuration> <sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory> <outputDirectory>${project.basedir}/src/main/java/</outputDirectory> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>3、在main目录创建源目录avro,添加协议文件和模式文件
(1)FileSplit.avsc(文件切片模式文件) { "namespace": "rpc.domain", "type": "record", "name": "FileSplit", "fields": [ {"name": "path", "type": ["string", "null"]}, {"name": "start", "type": ["long", "null"]}, {"name": "length", "type": ["long", "null"]} ]}
字段说明:path: 待处理文件的位置start: 处理的文件切片(逻辑切片)的起始位置length: 处理的文件切片的长度(字节为单位)
(2)HttpAppHost.avsc(Zebra业务对象模式文件){ "namespace": "rpc.domain", "type": "record", "name": "HttpAppHost", "fields": [ {"name": "reportTime", "type": ["string", "null"]}, {"name": "cellid", "type": ["string", "null"]}, {"name": "appType", "type": ["int", "null"]}, {"name": "appSubtype", "type": ["int", "null"]}, {"name": "userIP", "type": ["string", "null"]}, {"name": "userPort", "type": ["int", "null"]}, {"name": "appServerIP", "type": ["string", "null"]}, {"name": "appServerPort", "type": ["int", "null"]}, {"name": "host", "type": ["string", "null"]}, {"name": "attempts", "type": ["int", "null"]}, {"name": "accepts", "type": ["int", "null"]}, {"name": "trafficUL", "type": ["long", "null"]}, {"name": "trafficDL", "type": ["long", "null"]}, {"name": "retranUL", "type": ["long", "null"]}, {"name": "retranDL", "type": ["long", "null"]}, {"name": "transDelay", "type": ["long", "null"]} ]}
(3)RpcFileSplit.avdl(发送文件切片的协议文件)
@namespace("rpc.service")
protocol RpcFileSplit{
import schema "FileSplit.avsc";
void sendFileSplit(rpc.domain.FileSplit fileSplit);
}(4)RpcSendHttpAppHost.avdl(发送Zebra业务对象的协议文件)
@namespace("rpc.service")
protocol RpcSendHttpAppHost{
import schema "HttpAppHost.avsc";
void sendHttpAppHost(rpc.domain.HttpAppHost httpAppHost);
void sendHttpAppHostMap(map<rpc.domain.HttpAppHost> hahMap);
}4、利用avro插件基于模式文件和协议文件生成相应的类和接口右击pom.xml,单击Maven—>Generate Sources and Update Folders:
生成了序列化类FileSplit和HttpAppHost,RPC服务接口RpcFileSplit和RpcSendHttpAppHost。
5、配置全局的属性文件env.properties
# 日志文件所在目录
zebra.dir=D:\\program\\zebra\\data
# 30秒扫描一次
zebra.scanninginterval=30000
# 文件切片大小为3MB
zebra.blocksize=3000000
# zk服务器的ip:port
zebra.zk.serverip=192.168.225.51:2181,192.168.225.52:2181,192.168.225.53:2181
# 会话超时时长
zebra.zk.sessiontimeout=30000
# jobtracker节点路径
zebra.zk.jobtrackerpath=/jobtracker
# 一级引擎节点路径
zebra.zk.engine1path=/engine1
# 二级引擎节点路径
zebra.zk.engine2path=/engine2查看zk服务器集群的ip地址:
6、创建GlobalEnv类定义全局变量,读取env.properties属性文件
package net.hw.common;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import rpc.domain.FileSplit;
import java.io.File;
import java.io.InputStream;
import java.util.Properties;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.LinkedBlockingDeque;
/**
* Created by howard on 2017/11/3
*
* 定义全局变量,读取属性文件
*/
public class GlobalEnv {
/**
* 日志文件目录
*/
private static String dir;
/**
* 扫描时间间隔
*/
private static long scanningInterval;
/**
* 文件切片大小
*/
private static long blockSize;
/**
* zk服务器ip地址
*/
private static String zkServerIp;
/**
* 连接zk服务的会话超时
*/
private static int sessionTimeout;
/**
* jobtracker节点路径
*/
private static String jobTrackerPath;
/**
* 一级引擎节点路径
*/
private static String engine1Path;
/**
* 二级引擎节点路径
*/
private static String engine2Path;
/**
* 文件链式阻塞队列(收集日志文件先保存到该队列供后续处理)
*/
private static BlockingQueue<File> fileQueue = new LinkedBlockingDeque<File>();
/**
* 文件切片链式阻塞队列(将每个文件切成若干片保存到该队列供后续处理)
*/
private static BlockingQueue<FileSplit> fileSplitQueue = new LinkedBlockingDeque<FileSplit>();
/**
* 静态代码块,只执行一次
*/
static {
try {
initParam();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 加载属性文件,获取参数值
*/
public static void initParam() throws Exception {
// 定义属性对象
Properties properties = new Properties();
// 获取资源作为输入流
InputStream in = GlobalEnv.class.getResourceAsStream("/env.properties");
// 将输入流数据加载到属性对象
properties.load(in);
// 关闭输入流
in.close();
// 从属性对象中读取属性
if (properties.containsKey("zebra.dir")) {
dir = properties.getProperty("zebra.dir");
}
if (properties.containsKey("zebra.scanninginterval")) {
scanningInterval = Long.parseLong(properties.getProperty("zebra.scanninginterval"));
}
if (properties.containsKey("zebra.blocksize")) {
blockSize = Long.parseLong(properties.getProperty("zebra.blocksize"));
}
if (properties.containsKey("zebra.zk.serverip")) {
zkServerIp = properties.getProperty("zebra.zk.serverip");
}
if (properties.containsKey("zebra.zk.sessiontimeout")) {
sessionTimeout = Integer.parseInt(properties.getProperty("zebra.zk.sessiontimeout"));
}
if (properties.containsKey("zebra.zk.jobtrackerpath")) {
jobTrackerPath = properties.getProperty("zebra.zk.jobtrackerpath");
}
if (properties.containsKey("zebra.zk.engine1path")) {
engine1Path = properties.getProperty("zebra.zk.engine1path");
}
if (properties.containsKey("zebra.zk.engine2path")) {
engine2Path = properties.getProperty("zebra.zk.engine2path");
}
}
/**
* 连接zk服务器获取ZooKeeper对象
*/
public static ZooKeeper connectZkServer() throws Exception {
final CountDownLatch cdl = new CountDownLatch(1);
ZooKeeper zk = new ZooKeeper(zkServerIp, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
if (event.getState() == Event.KeeperState.SyncConnected) {
System.out.println("连接zk服务器成功!");
cdl.countDown();
}
}
});
cdl.await();
return zk;
}
public static String getDir() {
return dir;
}
public static void setDir(String dir) {
GlobalEnv.dir = dir;
}
public static long getScanningInterval() {
return scanningInterval;
}
public static void setScanningInterval(long scanningInterval) {
GlobalEnv.scanningInterval = scanningInterval;
}
public static long getBlockSize() {
return blockSize;
}
public static void setBlockSize(long blockSize) {
GlobalEnv.blockSize = blockSize;
}
public static String getZkServerIp() {
return zkServerIp;
}
public static void setZkServerIp(String zkServerIp) {
GlobalEnv.zkServerIp = zkServerIp;
}
public static int getSessionTimeout() {
return sessionTimeout;
}
public static void setSessionTimeout(int sessionTimeout) {
GlobalEnv.sessionTimeout = sessionTimeout;
}
public static String getJobTrackerPath() {
return jobTrackerPath;
}
public static void setJobTrackerPath(String jobTrackerPath) {
GlobalEnv.jobTrackerPath = jobTrackerPath;
}
public static String getEngine1Path() {
return engine1Path;
}
public static void setEngine1Path(String engine1Path) {
GlobalEnv.engine1Path = engine1Path;
}
public static String getEngine2Path() {
return engine2Path;
}
public static void setEngine2Path(String engine2Path) {
GlobalEnv.engine2Path = engine2Path;
}
public static BlockingQueue<File> getFileQueue() {
return fileQueue;
}
public static BlockingQueue<FileSplit> getFileSplitQueue() {
return fileSplitQueue;
}
}二、zebra_jobtracker模块V1.0作用:作为资源调度者。获取日志文件放入文件队列,从文件队列里取出文件,进行文件切分,然后文件切片放入文件切片队列。
1、修改pom.xml文件,添加对ZebraProject的依赖
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>ZebraProject</artifactId> <groupId>net.hw.zebra</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>zebra_jobtracker</artifactId> <dependencies> <dependency> <groupId>net.hw.zebra</groupId> <artifactId>ZebraProject</artifactId> <version>1.0-SNAPSHOT</version> </dependency> </dependencies> </project>2、编写FileCollector类作用:收集日志文件的线程类
package net.hw.file;
import net.hw.common.GlobalEnv;
import java.io.File;
/**
* Created by howard on 2017/11/3
*/
public class FileCollector implements Runnable {
@Override
public void run() {
// 获取日志文件目录
File dir = new File(GlobalEnv.getDir());
// 获取日志文件目录下所有文件
File[] files = dir.listFiles();
// 遍历所有文件
for (File file : files) {
// 处理后缀名为ctr的标识文件,表明对应的日志文件尚未处理
if (file.getName().endsWith(".ctr")) {
// 获取对应的日志文件名
String logFileName = file.getName().split(".ctr")[0] + ".csv";
// 创建日志文件对象
File logFile = new File(dir, logFileName);
// 将日志文件添加到文件队列中,等待后续处理
GlobalEnv.getFileQueue().add(logFile);
// 删除标识文件,表明对应的日志文件已经处理
file.delete();
}
}
// 每隔指定时间收集一次日志
try {
Thread.sleep(GlobalEnv.getScanningInterval());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}3、编写FileToBlock类作用:该线程类从文件队列(全局的fileQueue对象)里拿日志文件,然后对它进行逻辑切分(假切,不会生成切块文件)[10.3MB: 0~3MB; 3MB~6MB; 6MB~9M; 9M~10.3M],切分后将相关数据封装到FileSplit对象里,然后将FileSplit对象添加到文件切片队列(全局的fileSplitQueue对象)里,等待后续处理。
package net.hw.file;
import net.hw.common.GlobalEnv;
import rpc.domain.FileSplit;
import java.io.File;
/**
* Created by howard on 2017/11/3
*/
public class FileToBlock implements Runnable{
@Override
public void run() {
while (true) {
try {
// 从文件队列中获取日志文件,用take()方法,没有日志文件就会产生阻塞
File file = GlobalEnv.getFileQueue().take();
// 获取文件长度
long length = file.length();
// 计算切片数量
long num = length % GlobalEnv.getBlockSize() == 0 ? length / GlobalEnv.getBlockSize() : length / GlobalEnv.getBlockSize() + 1;
// 遍历全部切片,封装成FileSplit对象,添加到文件切片队列
for (int i = 0; i < num; i++) {
// 创建文件切片对象
FileSplit split = new FileSplit();
// 设置文件切片路径
split.setPath(file.getPath());
// 设置文件切片起点
split.setStart(i * GlobalEnv.getBlockSize());
// 设置文件切片长度
if (i == num - 1) {
split.setLength(length - split.getStart());
} else {
split.setLength(GlobalEnv.getBlockSize());
}
// 将切片添加到文件切片队列里
GlobalEnv.getFileSplitQueue().add(split);
// 输出切片信息
System.out.println(split);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}4、编写StartJobTrakcer类——利用线程池启动线程
package net.hw.common;
import net.hw.file.FileCollector;
import net.hw.file.FileToBlock;
import net.hw.rpc.RpcClientRunner;
import net.hw.zk.ZkConnectRunner;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* Created by howard 2017/11/3
*/
public class StartJobTracker {
public static void main(String[] args) {
// 提示用户jobtracker启动
System.out.println("jobtracker已经启动……");
// 创建缓存线程池(大池子,小队列)
ExecutorService es = Executors.newCachedThreadPool();
// 启动文件收集线程
es.submit(new FileCollector());
// 启动文件切片线程
es.submit(new FileToBlock());
// 启动连接zk服务器的线程==>启动RPC客户端发送文件切片的线程
es.submit(new ZkConnectRunner());
}
}运行程序,结果如下:
并且该日志文件所对应的标识文件(*.ctr)被删除了,表明此日志文件已被处理。通过标识文件可以避免日志文件被重复处理。
查看日志文件属性:
10.3MB的日志文件,按3MB来切,得到四个文件切片:{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 0, "length": 3000000}{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 3000000, "length": 3000000}{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 6000000, "length": 3000000}{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 9000000, "length": 1901307}三、zebra_engine1_01模块V1.0作用:接收jobtracker发来的任务,根据任务进行对文件的处理;将文件数据进行清洗和整理;将处理完的数据发给二级引擎;通过zookeeper,注册自身节点信息状态,便于集群其他机器监控继而做相关的业务逻辑处理。
1、修改pom.xml文件,添加对父工程ZebraProject的依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent>
<artifactId>ZebraProject</artifactId>
<groupId>net.hw.zebra</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>zebra_engine1_01</artifactId>
<dependencies>
<dependency>
<groupId>net.hw.zebra</groupId>
<artifactId>ZebraProject</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
</project>2、编写ownenv.properties文件
3、编写ownenv类,定义变量并且读取ownenv.properties属性文件
package net.hw.common;
import rpc.domain.FileSplit;
import rpc.domain.HttpAppHost;
import java.io.InputStream;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class OwnEnv {
/**
* rpc通信端口
*/
private static int rpcPort;
/**
* 一级引擎在zk服务器上的节点路径
*/
private static String znodePath;
/**
* 文件切片链式阻塞队列
*/
private static BlockingQueue<FileSplit> splitQueue = new LinkedBlockingQueue<FileSplit>();
/**
* zebra业务对象链式阻塞队列
*/
private static BlockingQueue<Map<CharSequence, HttpAppHost>> mapQueue = new LinkedBlockingQueue<>();
/**
* 静态代码块,只执行一次
*/
static {
try {
initParam();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 加载属性文件,获取参数值
*/
public static void initParam() throws Exception{
// 定义属性对象
Properties properties = new Properties();
// 获取资源作为输入流
InputStream in = GlobalEnv.class.getResourceAsStream("/ownenv.properties");
// 将输入流数据加载到属性对象
properties.load(in);
// 关闭输入流
in.close();
// 从属性对象中读取属性
if (properties.containsKey("zebra.rpcport")) {
rpcPort = Integer.parseInt(properties.getProperty("zebra.rpcport"));
}
if (properties.containsKey("zebra.zk.znodepath")) {
znodePath = properties.getProperty("zebra.zk.znodepath");
}
}
public static int getRpcPort() {
return rpcPort;
}
public static void setRpcPort(int rpcPort) {
OwnEnv.rpcPort = rpcPort;
}
public static String getZnodePath() {
return znodePath;
}
public static void setZnodePath(String znodePath) {
OwnEnv.znodePath = znodePath;
}
public static BlockingQueue<FileSplit> getSplitQueue() {
return splitQueue;
}
public static BlockingQueue<Map<CharSequence, HttpAppHost>> getMapQueue() {
return mapQueue;
}
}如何将切块后的任务使用rpc传递给一级引擎?
对于jobtracker与一级引擎而言,一级引擎是rpc服务器端,jobtracker是rpc的客户端。在jobtracker模块中需要知道一级引擎的ip和端口号,这些信息又在一级引擎中,那么在jobtracker中如何获取这些信息呢?
解决方案:让一级引擎创建节点/node01,并将一级引擎服务器的ip和端口保存到节点数据中。
4、编写ZkConnectRunner,负责一级引擎节点创建
作用:为一级引擎在zk服务器上创建节点,保存一级引擎的ip和port。
package net.hw.zk;
import net.hw.common.GlobalEnv;
import net.hw.common.OwnEnv;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import java.net.InetAddress;
public class ZkConnectRunner implements Runnable {
private ZooKeeper zk;
@Override
public void run() {
try {
// 连接zk服务器获取zk对象
zk = GlobalEnv.connectZkServer();
// 定义节点信息字符串
String nodeInfo = InetAddress.getLocalHost().toString() + "/" + OwnEnv.getRpcPort() + "/free";
// 创建节点
zk.create(GlobalEnv.getEngine1Path() + OwnEnv.getZnodePath(), nodeInfo.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e) {
e.printStackTrace();
}
}
}5、创建StartEngine1_01类,利用线程池启动ZkConnectRunner线程package net.hw.common;
import net.hw.zk.zkConnectRunner;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class StartEngine1_01 {
public static void main(String[] args) {
// 创建缓存线程池(大池子,小队列)
ExecutorService es = Executors.newCachedThreadPool();
// 启动连接zk服务器线程类
es.submit(new ZkConnectRunner());
}
}注意:为了项目正常运行,启动zk服务器集群。启动StartEngine1_01,运行结果如下:
原因是我们并没有创建/engine1节点:
所以,创建/engine1/node01节点会失败。
修改ZkConnectRunner代码:
此时,运行程序StartEngine1_01,结果如下:
利用ZooKeeper插件查看:
6、创建rpc服务器端接收jobtracker客户端传递过来的任务接收jobtracker传来的FileSplit,所以要用对应的协议接口:RpcFileSplit,此外还有实现类(即拿到FileSplit之后要怎么处理。)(1)创建协议接口实现类RpcFileSplitImpl
package net.hw.rpc;
import net.hw.common.OwnEnv;
import org.apache.avro.AvroRemoteException;
import rpc.domain.FileSplit;
import rpc.service.RpcFileSplit;
public class RpcFileSplitImpl implements RpcFileSplit {
@Override
public Void sendFileSplit(FileSplit fileSplit) throws AvroRemoteException {
// 提示用户收到jobtracker派发的任务
System.out.println("一级引擎01节点收到jobtracker发送过来的" + fileSplit);
// 将收到的文件切片对象添加到一级引擎的文件切片队列
OwnEnv.getSplitQueue().add(fileSplit);
return null;
}
}(2)编写RpcServerRunner线程类
package net.hw.rpc;
import net.hw.common.OwnEnv;
import org.apache.avro.ipc.NettyServer;
import org.apache.avro.ipc.specific.SpecificResponder;
import rpc.service.RpcFileSplit;
import java.net.InetSocketAddress;
public class RpcServerRunner implements Runnable{
@Override
public void run() {
// 创建NettyServer对象
NettyServer server = new NettyServer(new SpecificResponder(RpcFileSplit.class, new RpcFileSplitImpl()),
new InetSocketAddress(OwnEnv.getRpcPort()));
// 提示用户
System.out.println("一级引擎01节点的RPC服务启动了~");
}
}(3)修改StartEngine1_01类,将线程追加到线程池中
package net.hw.common;
import net.hw.rpc.RpcServerRunner;
import net.hw.zk.zkConnectRunner;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class StartEngine1_01 {
public static void main(String[] args) {
// 创建缓存线程池(大池子,小队列)
ExecutorService es = Executors.newCachedThreadPool();
// 启动连接zk服务器线程类
es.submit(new zkConnectRunner());
// 启动一级引擎接收jobtrackerp派发任务的线程类
es.submit(new RpcServerRunner());
}
}四、zebra_jobtracker模块V1.11、创建ZkConnectRunner类,获取两个一级引擎的节点数据(ip和port)
package net.hw.zk;
import net.hw.common.GlobalEnv;
import org.apache.zookeeper.ZooKeeper;
import java.util.List;
public class ZkConnectRunner implements Runnable {
private ZooKeeper zk;
@Override
public void run() {
try {
// 连接zk服务器
zk = GlobalEnv.connectZkServer();
// 获取一级引擎根节点(/engine1)下所有子节点
List<String> childPaths = zk.getChildren(GlobalEnv.getEngine1Path(), null);
// 遍历所有子节点
for (String childPath : childPaths) {
// 启动发送文件切片的线程
new Thread(new RpcClientRunner(childPath, zk)).start();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}2、创建RpcCilentRunner线程类,负责向一级引擎发送文件切片
package net.hw.rpc;
import net.hw.common.GlobalEnv;
import org.apache.avro.ipc.NettyTransceiver;
import org.apache.avro.ipc.specific.SpecificRequestor;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.ZooKeeper;
import rpc.domain.FileSplit;
import rpc.service.RpcFileSplit;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.Proxy;
public class RpcClientRunner implements Runnable {
private String childPath;
private ZooKeeper zk;
public RpcClientRunner(String childPath, ZooKeeper zk) {
this.childPath = childPath;
this.zk = zk;
}
@Override
public void run() {
// 输出一级引擎子节点路径
System.out.println("childPath: " + childPath);
try {
// 获取一级引擎子节点数据
byte[] data = zk.getData(GlobalEnv.getEngine1Path() + "/" + childPath, null, null);
// 封装得到子节点信息(ip/port/free)
String info = new String(data);
// 输出子节点信息
System.out.println("info: " + info);
// 通过拆分拿到rpc服务器端(一级引擎)的ip和port
String ip = info.split("/")[1];
int port = Integer.parseInt(info.split("/")[2]);
// 创建NettyTransceiver对象
NettyTransceiver transceiver = new NettyTransceiver(new InetSocketAddress(ip, port));
// 获取文件切片RPC客户端代理
RpcFileSplit proxy = SpecificRequestor.getClient(RpcFileSplit.class, transceiver);
// 从文件切片队列里获取一个文件切片
FileSplit split = GlobalEnv.getFileSplitQueue().take();
// 将该文件切片发送到RPC服务器端(一级引擎)
proxy.sendFileSplit(split);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}3、修改StartJobTracker类,添加发送切片的线程
4、测试jobtracer能否将任务发送到一级引擎(1)先启动一级引擎的StartEngine1_01(作为rpc服务器端)
运行结果如下:
注意:日志标识文件一定要存在,表明日志文件尚未处理,否则根据我们程序的逻辑,jobtracker收集不到日志文件。
(2)再启动jobtracker的StartJobTracker(作为rpc客户端)
运行结果如下:
读取到了zk服务器上/engine1/的子结点node01,包括该节点上保存的一级引擎作为RPC服务器的ip地址和端口信息,一级引擎该节点目前的状态(free:空闲)。
jobtracker作为RPC客户端,已经连接了作为RPC服务器端的一级引擎,那么,此时切换到一级引擎的控制台看看,是否jobtracker完成了将文件切片发送到一级引擎的任务。
目前,jobtracker只发送了一个文件切片到一级引擎,如何才能将所有文件切片发送到一级引擎呢?大家课后完成此任务。
五、zebra_engine1_02模块V1.0
1、修改pom.xml文件,添加对项目ZebraProject的依赖
2、创建ownenv.properties文件
3、编写OwnEven类,读取ownenv.properties属性文件
package net.hw.common;
import rpc.domain.FileSplit;
import rpc.domain.HttpAppHost;
import java.io.InputStream;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class OwnEnv {
/**
* rpc通信端口
*/
private static int rpcPort;
/**
* 一级引擎在zk服务器上的节点路径
*/
private static String znodePath;
/**
* 文件切片链式阻塞队列
*/
private static BlockingQueue<FileSplit> splitQueue = new LinkedBlockingQueue<FileSplit>();
/**
* zebra业务对象链式阻塞队列
*/
private static BlockingQueue<Map<CharSequence, HttpAppHost>> mapQueue = new LinkedBlockingQueue<>();
/**
* 静态代码块,只执行一次
*/
static {
try {
initParam();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 加载属性文件,获取参数值
*/
public static void initParam() throws Exception{
// 定义属性对象
Properties properties = new Properties();
// 获取资源作为输入流
InputStream in = GlobalEnv.class.getResourceAsStream("/ownenv.properties");
// 将输入流数据加载到属性对象
properties.load(in);
// 关闭输入流
in.close();
// 从属性对象中读取属性
if (properties.containsKey("zebra.rpcport")) {
rpcPort = Integer.parseInt(properties.getProperty("zebra.rpcport"));
}
if (properties.containsKey("zebra.zk.znodepath")) {
znodePath = properties.getProperty("zebra.zk.znodepath");
}
}
public static int getRpcPort() {
return rpcPort;
}
public static void setRpcPort(int rpcPort) {
OwnEnv.rpcPort = rpcPort;
}
public static String getZnodePath() {
return znodePath;
}
public static void setZnodePath(String znodePath) {
OwnEnv.znodePath = znodePath;
}
public static BlockingQueue<FileSplit> getSplitQueue() {
return splitQueue;
}
public static BlockingQueue<Map<CharSequence, HttpAppHost>> getMapQueue() {
return mapQueue;
}
}4、编写ZkConnectRunner,负责一级引擎节点创建
package net.hw.zk;
import net.hw.common.GlobalEnv;
import net.hw.common.OwnEnv;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import java.net.InetAddress;
public class ZkConnectRunner implements Runnable {
private ZooKeeper zk;
@Override
public void run() {
try {
// 连接zk服务器获取zk对象
zk = GlobalEnv.connectZkServer();
// 定义节点信息字符串
String nodeInfo = InetAddress.getLocalHost().toString() + "/" + OwnEnv.getRpcPort() + "/free";
// 创建一级引擎的一级节点
if (zk.exists(GlobalEnv.getEngine1Path(), false) == null) {
zk.create(GlobalEnv.getEngine1Path(), "engine01".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
// 创建一级引擎的二级节点
zk.create(GlobalEnv.getEngine1Path() + OwnEnv.getZnodePath(),
nodeInfo.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e) {
e.printStackTrace();
}
}
}5、创建RpcFileSplitImpl类,实现RpcFileSplit接口
package net.hw.rpc;
import net.hw.common.OwnEnv;
import org.apache.avro.AvroRemoteException;
import rpc.domain.FileSplit;
import rpc.service.RpcFileSplit;
public class RpcFileSplitImpl implements RpcFileSplit {
@Override
public Void sendFileSplit(FileSplit fileSplit) throws AvroRemoteException {
// 提示用户收到jobtracker派发的任务
System.out.println("一级引擎02节点收到jobtracker发送过来的" + fileSplit);
// 将收到的文件切片对象添加到一级引擎的文件切片队列
OwnEnv.getSplitQueue().add(fileSplit);
return null;
}
}顺带修改一下zebra_engine1_01里的RpcFileSplitImpl类代码:
6、创建RpcServerRunner类
package net.hw.rpc;
import net.hw.common.OwnEnv;
import org.apache.avro.ipc.NettyServer;
import org.apache.avro.ipc.specific.SpecificResponder;
import rpc.service.RpcFileSplit;
import java.net.InetSocketAddress;
public class RpcServerRunner implements Runnable{
@Override
public void run() {
// 创建NettyServer对象
NettyServer server = new NettyServer(new SpecificResponder(RpcFileSplit.class, new RpcFileSplitImpl()),
new InetSocketAddress(OwnEnv.getRpcPort()));
// 提示用户
System.out.println("一级引擎02节点的RPC服务启动了~");
}
}顺带修改一下zebra_engine1_01里的RpcServerRunner代码:
7、创建StartEngine1_02类,利用线程池启动ZkConnectRunner线程和RpcServerRunner线程
package net.hw.common;
import net.hw.rpc.RpcServerRunner;
import net.hw.zk.ZkConnectRunner;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class StartEngine1_02 {
public static void main(String[] args) {
// 创建缓存线程池(大池子,小队列)
ExecutorService es = Executors.newCachedThreadPool();
// 启动连接zk服务器线程类
es.submit(new ZkConnectRunner());
// 启动一级引擎接收jobtrackerp派发任务的线程类
es.submit(new RpcServerRunner());
}
}8、测试一级引擎两个节点能否收到jobtracker发送的文件切片(1)启动StartEngine1_01和StartEngine1_02
(2)启动StartJobTracker
(3)切换到StartEngine1_01和StartEngine1_02的控制台
一级引擎01节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 0, "length": 3000000}
一级引擎02节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 3000000, "length": 3000000}
到目前为止,jobtracker将四个文件切片中的第一个切片发送给了一级引擎01节点,将第二个切片发送给了一级引擎02节点,还有两个文件切片没有发送,因此,我们需要去修改jobtracker里的RpcClientRunner代码,可以让所有文件切片都发送到一级引擎。
9、修改zebra_jobtracker模块的RpcClientRunner
package net.hw.rpc;
import net.hw.common.GlobalEnv;
import org.apache.avro.AvroRemoteException;
import org.apache.avro.ipc.NettyTransceiver;
import org.apache.avro.ipc.specific.SpecificRequestor;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import rpc.domain.FileSplit;
import rpc.service.RpcFileSplit;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.Proxy;
import java.util.concurrent.CountDownLatch;
public class RpcClientRunner implements Runnable {
private String childPath;
private ZooKeeper zk;
public RpcClientRunner(String childPath, ZooKeeper zk) {
this.childPath = childPath;
this.zk = zk;
}
@Override
public void run() {
// 输出一级引擎子节点路径
System.out.println("childPath: " + childPath);
try {
// 获取一级引擎子节点数据
final byte[][] data = {zk.getData(GlobalEnv.getEngine1Path() + "/" + childPath, null, null)};
// 封装得到子节点信息(ip/port/free)
String info = new String(data[0]);
// 输出子节点信息
System.out.println("info: " + info);
// 通过拆分拿到rpc服务器端(一级引擎)的ip和port
String ip = info.split("/")[1];
int port = Integer.parseInt(info.split("/")[2]);
// 创建NettyTransceiver对象
NettyTransceiver transceiver = new NettyTransceiver(new InetSocketAddress(ip, port));
// 获取文件切片RPC客户端代理
final RpcFileSplit proxy = SpecificRequestor.getClient(RpcFileSplit.class, transceiver);
// 从文件切片队列里获取一个文件切片
FileSplit split = GlobalEnv.getFileSplitQueue().take();
// 将该文件切片发送到RPC服务器端(一级引擎)
proxy.sendFileSplit(split);
// 持续监听一级引擎对应节点状态变化
while (true) {
final CountDownLatch cdl = new CountDownLatch(1);
zk.getData(GlobalEnv.getEngine1Path() + "/" + childPath, new Watcher() {
@Override
public void process(WatchedEvent event) {
// 如果节点数据发生变化就获取节点数据进行判断
if (event.getType() == Event.EventType.NodeDataChanged) {
try {
// 获取节点数据
byte[] data = zk.getData(GlobalEnv.getEngine1Path() + "/" + childPath, null, null);
// 获取节点状态
String state = new String(data).split("/")[3];
// 输出节点状态
System.out.println("监听节点状态:" + state);
// 如果节点状态是free,那么就要发送文件切片
if (state.equals("free")) {
// 获取文件切片对象(理解为什么要用poll方法而不用remove和take)
FileSplit split = GlobalEnv.getFileSplitQueue().poll();
// 如果切片非空,那么就发送
if (split != null) {
proxy.sendFileSplit(split);
}
}
cdl.countDown();
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (AvroRemoteException e) {
e.printStackTrace();
}
}
}
}, null);
// 利用闭锁await方法产生阻塞,只能当监听到节点数据状态发生变化,才会消除阻塞
cdl.await();
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}10、测试一级引擎两个节点能否收到jobtracker发送的全部文件切片(1)启动StartEngine1_01和StartEngine1_02
(2)启动StartJobTracker
(3)切换到StartEngine1_01和StartEngine1_02的控制台
结果还是一样,仍有两个文件切片没有发送,因为一级引擎两个节点的状态目前都没有变化,都是free,只有在我们要写的一级引擎的MapperRunner代码根据业务修改了节点状态之后,才能监听到节点状态变化,从而将切片队列里其他剩余的切片给发送了。
六、zebra_engine1_01模块V1.1添加功能:读取文件切片,按|分割,提取所需字段进行封装,封装成map对象,然后利用rpc通信将它发送到二级引擎。1、创建MapperRunner类,负责读取文件切片,按|分割、封装成zebra业务对象
package net.hw.mapper;
import net.hw.common.OwnEnv;
import net.hw.zk.ZkConnectRunner;
import rpc.domain.FileSplit;
import rpc.domain.HttpAppHost;
import java.io.*;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.util.HashMap;
import java.util.Map;
public class MapperRunner implements Runnable {
@Override
public void run() {
try {
while (true) {
//保存切块内容处理合并后的信息(后添加)
Map<CharSequence, HttpAppHost> map = new HashMap<>();
FileSplit split = OwnEnv.getSplitQueue().take();
//将节点状态改为busy
ZkConnectRunner.setBusy();
File file = new File(split.getPath().toString());
long start = split.getStart();
long end = start + split.getLength();
//有可能切块后,考虑到不一定都是从行首、行尾切
//所以需要追溯start和end,均采用向前追溯的方式
FileInputStream in = new FileInputStream(file);
FileChannel fc = in.getChannel();
if (start != 0) {
long headPosition = start;
while (true) {
ByteBuffer buff = ByteBuffer.allocate(1);
fc.position(headPosition);
fc.read(buff);
if (new String(buff.array()).equals("\n")) {
start = headPosition + 1;
break;
} else {
headPosition--;
}
}
}
if (end != file.length()) {
long tailPosition = end;
while (true) {
ByteBuffer buf = ByteBuffer.allocate(1);
fc.position(tailPosition);
fc.read(buf);
if (new String(buf.array()).equals("\n")) {
end = tailPosition;
break;
} else {
tailPosition--;
}
}
}
//start和end处理完后,读取本次切块的所有行
ByteBuffer buffer = ByteBuffer.allocate((int) (end - start));
fc.position(start);
fc.read(buffer);
//一行行进行读取
BufferedReader br = new BufferedReader(
new InputStreamReader(
new ByteArrayInputStream(buffer.array())));
String line = null;
while ((line = br.readLine()) != null) {
String data[] = line.split("\\|");
//以下代码从业务说明文档的业务字段处理逻辑处拷贝
HttpAppHost hah = new HttpAppHost();
String reportTime = file.getPath().toString().split("_")[1];
hah.setReportTime(reportTime);
//上网小区的id
hah.setCellid(data[16]);
//应用大类
hah.setAppType(Integer.parseInt(data[22]));
//应用子类
hah.setAppSubtype(Integer.parseInt(data[23]));
//用户ip
hah.setUserIP(data[26]);
//用户port
hah.setUserPort(Integer.parseInt(data[28]));
//访问的服务ip
hah.setAppServerIP(data[30]);
//访问的服务port
hah.setAppServerPort(Integer.parseInt(data[32]));
//域名
hah.setHost(data[58]);
int appTypeCode = Integer.parseInt(data[18]);
String transStatus = data[54];
//业务逻辑处理
if (hah.getCellid() == null || hah.getCellid().equals("")) {
hah.setCellid("000000000");
}
//如果状态码103,就把尝试请求次数设为1
if (appTypeCode == 103) {
hah.setAttempts(1);
}
//如果状态码103,并且传输码包括这么多……,就把接收次数设置为1
if (appTypeCode == 103 && "10,11,12,13,14,15,32,33,34,35,36,37,38,48,49,50,51,52,53,54,55,199,200,201,202,203,204,205 ,206,302,304,306".contains(transStatus)) {
hah.setAccepts(1);
} else {
hah.setAccepts(0);
}
//如果是103,就设置用户发生的上传流量,后续后统计每个用户产生的总的上传流量
if (appTypeCode == 103) {
hah.setTrafficUL(Long.parseLong(data[33]));
}
//如果是103,设置下行流量
if (appTypeCode == 103) {
hah.setTrafficDL(Long.parseLong(data[34]));
}
//如果是103,设置重传上行流量
if (appTypeCode == 103) {
hah.setRetranUL(Long.parseLong(data[39]));
}
//如果是103,设置重传下行流量
if (appTypeCode == 103) {
hah.setRetranDL(Long.parseLong(data[40]));
}
//如果是103,设置用户的传输延迟
if (appTypeCode == 103) {
hah.setTransDelay(Long.parseLong(data[20]) - Long.parseLong(data[19]));
}
//标识用户的key
CharSequence key = hah.getReportTime() + "|" + hah.getAppType() + "|" + hah.getAppSubtype() + "|" + hah.getUserIP() + "|" + hah.getUserPort() + "|" + hah.getAppServerIP() + "|" + hah.getAppServerPort() + "|" + hah.getHost() + "|" + hah.getCellid();
// hah=>map
if (map.containsKey(key)) {
HttpAppHost mapHah = map.get(key);
mapHah.setAccepts(mapHah.getAccepts() + hah.getAccepts());
mapHah.setAttempts(mapHah.getAttempts() + hah.getAttempts());
mapHah.setTrafficUL(mapHah.getTrafficUL() + hah.getTrafficUL());
mapHah.setTrafficDL(mapHah.getTrafficDL() + hah.getTrafficDL());
mapHah.setRetranUL(mapHah.getRetranUL() + hah.getRetranUL());
mapHah.setRetranDL(mapHah.getRetranDL() + hah.getRetranDL());
mapHah.setTransDelay(mapHah.getTransDelay() + hah.getTransDelay());
map.put(key, mapHah);
} else {
map.put(key, hah);
}
//拷贝结束
}
//将map保存到队列中
OwnEnv.getMapQueue().add(map);
//将节点状态改为free
ZkConnectRunner.setFree();
System.out.println("map.size=" + map.size());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}说明:进入业务对象封装工作,节点状态设置为busy,此时不能接收jobtracker发送的切片;然后等到封装工作完成,节点状态设置为free,此时又可以接收jobtracker发送的文件切片。
下面,我们在ZkConnectRunner类定义两个静态方法setBusy和setFree,用于设置一级引擎节点状态。
2、修改ZkConnectRunner类,添加两个静态方法
package net.hw.zk;
import net.hw.common.GlobalEnv;
import net.hw.common.OwnEnv;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import java.net.InetAddress;
public class ZkConnectRunner implements Runnable {
private static ZooKeeper zk;
@Override
public void run() {
try {
// 连接zk服务器获取zk对象
zk = GlobalEnv.connectZkServer();
// 定义节点信息字符串
String nodeInfo = InetAddress.getLocalHost().toString() + "/" + OwnEnv.getRpcPort() + "/free";
// 创建一级引擎的一级节点
if (zk.exists(GlobalEnv.getEngine1Path(), false) == null) {
zk.create(GlobalEnv.getEngine1Path(), "engine01".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
// 创建一级引擎的二级节点
zk.create(GlobalEnv.getEngine1Path() + OwnEnv.getZnodePath(),
nodeInfo.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e) {
e.printStackTrace();
}
}
public static void setBusy() throws Exception {
// 定义节点信息字符串
String nodeInfo = InetAddress.getLocalHost().toString() + "/" + OwnEnv.getRpcPort() + "/busy";
// 更新节点数据
zk.setData(GlobalEnv.getEngine1Path() + OwnEnv.getZnodePath(), nodeInfo.getBytes(), -1);
}
public static void setFree() throws Exception {
// 定义节点信息字符串
String nodeInfo = InetAddress.getLocalHost().toString() + "/" + OwnEnv.getRpcPort() + "/free";
// 更新节点数据
zk.setData(GlobalEnv.getEngine1Path() + OwnEnv.getZnodePath(), nodeInfo.getBytes(), -1);
}
}3、修改StartEngine1_01类
4、创建RpcClientRunner,负责向二级引擎发送处理后的map对于一级引擎与二级引擎之间的RPC通信,一级引擎是RPC客户端,二级引擎是RPC服务器端。
一级引擎相对于jobtracker是RPC服务器端,但相对于二级引擎又是RPC客户端。
package net.hw.rpc;
import net.hw.common.GlobalEnv;
import net.hw.common.OwnEnv;
import org.apache.avro.ipc.NettyTransceiver;
import org.apache.avro.ipc.specific.SpecificRequestor;
import org.apache.zookeeper.ZooKeeper;
import rpc.service.RpcSendHttpAppHost;
import java.net.InetSocketAddress;
public class RpcClientRunner implements Runnable {
private ZooKeeper zk;
@Override
public void run() {
try {
// 获取zk对象
zk = GlobalEnv.connectZkServer();
// 获取二级引擎节点数据
byte[] data = zk.getData(GlobalEnv.getEngine2Path(), null, null);
// 封装成字符串
String info = new String(data);
// 获取二级引擎ip和port
String ip = info.split("/")[1];
int port = Integer.parseInt(info.split("/")[2]);
// 创建网络收发器
NettyTransceiver transceiver = new NettyTransceiver(new InetSocketAddress(ip, port));
// 创建RPC通信客户端代理
RpcSendHttpAppHost proxy = SpecificRequestor.getClient(RpcSendHttpAppHost.class, transceiver);
// 向二级引擎发送处理后的map
while (true) {
proxy.sendHttpAppHostMap(OwnEnv.getMapQueue().take());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}5、修改StartEngine1_01类,将RpcClientRunner线程添加到线程池七、zebra_engine1_02模块V1.11、修改ZkConnectRunnet类,添加两个静态方法
2、创建MapperRunner类
package net.hw.mapper;
import net.hw.common.OwnEnv;
import net.hw.zk.ZkConnectRunner;
import rpc.domain.FileSplit;
import rpc.domain.HttpAppHost;
import java.io.*;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.util.HashMap;
import java.util.Map;
public class MapperRunner implements Runnable {
@Override
public void run() {
try {
while (true) {
//保存切块内容处理合并后的信息(后添加)
Map<CharSequence, HttpAppHost> map = new HashMap<>();
FileSplit split = OwnEnv.getSplitQueue().take();
//将节点状态改为busy
ZkConnectRunner.setBusy();
File file = new File(split.getPath().toString());
long start = split.getStart();
long end = start + split.getLength();
//有可能切块后,考虑到不一定都是从行首、行尾切
//所以需要追溯start和end,均采用向前追溯的方式
FileInputStream in = new FileInputStream(file);
FileChannel fc = in.getChannel();
if (start != 0) {
long headPosition = start;
while (true) {
ByteBuffer buff = ByteBuffer.allocate(1);
fc.position(headPosition);
fc.read(buff);
if (new String(buff.array()).equals("\n")) {
start = headPosition + 1;
break;
} else {
headPosition--;
}
}
}
if (end != file.length()) {
long tailPosition = end;
while (true) {
ByteBuffer buf = ByteBuffer.allocate(1);
fc.position(tailPosition);
fc.read(buf);
if (new String(buf.array()).equals("\n")) {
end = tailPosition;
break;
} else {
tailPosition--;
}
}
}
//start和end处理完后,读取本次切块的所有行
ByteBuffer buffer = ByteBuffer.allocate((int) (end - start));
fc.position(start);
fc.read(buffer);
//一行行进行读取
BufferedReader br = new BufferedReader(
new InputStreamReader(
new ByteArrayInputStream(buffer.array())));
String line = null;
while ((line = br.readLine()) != null) {
String data[] = line.split("\\|");
//以下代码从业务说明文档的业务字段处理逻辑处拷贝
HttpAppHost hah = new HttpAppHost();
String reportTime = file.getPath().toString().split("_")[1];
hah.setReportTime(reportTime);
//上网小区的id
hah.setCellid(data[16]);
//应用大类
hah.setAppType(Integer.parseInt(data[22]));
//应用子类
hah.setAppSubtype(Integer.parseInt(data[23]));
//用户ip
hah.setUserIP(data[26]);
//用户port
hah.setUserPort(Integer.parseInt(data[28]));
//访问的服务ip
hah.setAppServerIP(data[30]);
//访问的服务port
hah.setAppServerPort(Integer.parseInt(data[32]));
//域名
hah.setHost(data[58]);
int appTypeCode = Integer.parseInt(data[18]);
String transStatus = data[54];
//业务逻辑处理
if (hah.getCellid() == null || hah.getCellid().equals("")) {
hah.setCellid("000000000");
}
//如果状态码103,就把尝试请求次数设为1
if (appTypeCode == 103) {
hah.setAttempts(1);
}
//如果状态码103,并且传输码包括这么多……,就把接收次数设置为1
if (appTypeCode == 103 && "10,11,12,13,14,15,32,33,34,35,36,37,38,48,49,50,51,52,53,54,55,199,200,201,202,203,204,205 ,206,302,304,306".contains(transStatus)) {
hah.setAccepts(1);
} else {
hah.setAccepts(0);
}
//如果是103,就设置用户发生的上传流量,后续后统计每个用户产生的总的上传流量
if (appTypeCode == 103) {
hah.setTrafficUL(Long.parseLong(data[33]));
}
//如果是103,设置下行流量
if (appTypeCode == 103) {
hah.setTrafficDL(Long.parseLong(data[34]));
}
//如果是103,设置重传上行流量
if (appTypeCode == 103) {
hah.setRetranUL(Long.parseLong(data[39]));
}
//如果是103,设置重传下行流量
if (appTypeCode == 103) {
hah.setRetranDL(Long.parseLong(data[40]));
}
//如果是103,设置用户的传输延迟
if (appTypeCode == 103) {
hah.setTransDelay(Long.parseLong(data[20]) - Long.parseLong(data[19]));
}
//标识用户的key
CharSequence key = hah.getReportTime() + "|" + hah.getAppType() + "|" + hah.getAppSubtype() + "|" + hah.getUserIP() + "|" + hah.getUserPort() + "|" + hah.getAppServerIP() + "|" + hah.getAppServerPort() + "|" + hah.getHost() + "|" + hah.getCellid();
// hah=>map
if (map.containsKey(key)) {
HttpAppHost mapHah = map.get(key);
mapHah.setAccepts(mapHah.getAccepts() + hah.getAccepts());
mapHah.setAttempts(mapHah.getAttempts() + hah.getAttempts());
mapHah.setTrafficUL(mapHah.getTrafficUL() + hah.getTrafficUL());
mapHah.setTrafficDL(mapHah.getTrafficDL() + hah.getTrafficDL());
mapHah.setRetranUL(mapHah.getRetranUL() + hah.getRetranUL());
mapHah.setRetranDL(mapHah.getRetranDL() + hah.getRetranDL());
mapHah.setTransDelay(mapHah.getTransDelay() + hah.getTransDelay());
map.put(key, mapHah);
} else {
map.put(key, hah);
}
//拷贝结束
}
//将map保存到队列中
OwnEnv.getMapQueue().add(map);
//将节点状态改为free
ZkConnectRunner.setFree();
System.out.println("map.size=" + map.size());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}3、创建RpcClientRunner类
package net.hw.rpc; import net.hw.common.GlobalEnv; import net.hw.common.OwnEnv; import org.apache.avro.ipc.NettyTransceiver; import org.apache.avro.ipc.specific.SpecificRequestor; import org.apache.zookeeper.ZooKeeper; import rpc.service.RpcSendHttpAppHost; import java.net.InetSocketAddress; public class RpcClientRunner implements Runnable { private ZooKeeper zk; @Override public void run() { try { // 获取zk对象 zk = GlobalEnv.connectZkServer(); // 获取二级引擎节点数据 byte[] data = zk.getData(GlobalEnv.getEngine2Path(), null, null); // 封装成字符串 String info = new String(data); // 获取二级引擎ip和port String ip = info.split("/")[1]; int port = Integer.parseInt(info.split("/")[2]); // 创建网络收发器 NettyTransceiver transceiver = new NettyTransceiver(new InetSocketAddress(ip, port)); // 创建RPC通信客户端代理 RpcSendHttpAppHost proxy = SpecificRequestor.getClient(RpcSendHttpAppHost.class, transceiver); // 向二级引擎发送处理后的map while (true) { proxy.sendHttpAppHostMap(OwnEnv.getMapQueue().take()); } } catch (Exception e) { e.printStackTrace(); } } }4、修改StartEngine1_02类
5、测试一级引擎能否收到jobtracker发送的全部文件切片
(1)启动StartEngine1_01和StartEngine1_02
(2)启动StartJobTracker
(3)切换到StartEngine1_01和StartEngine1_02的控制台
一级引擎01节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 0, "length": 3000000}map.size=4936一级引擎01节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 9000000, "length": 1901307}map.size=4243
一级引擎02节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 3000000, "length": 3000000}map.size=4062一级引擎02节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 6000000, "length": 3000000}map.size=4740
结果分析:一级引擎两个节点收到jobtracker发送的四个切片(全部切片),01节点收到两个文件切片(第1个和第4个),02节点收到两个文件切片(第2个和第3个)。
错误信息:org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode = NoNode for /engine2
错误原因:还没有编写二级引擎模块代码,没有创建二级引擎节点/engine2。
八、二级引擎zebra_engine2模块1、修改pom.xml文件,添加对父工程ZebraProject的依赖
2、创建ZkConnectRunner,负责创建二级引擎节点
package net.hw.zk;
import net.hw.common.GlobalEnv;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import java.net.InetAddress;
public class ZkConnectRunner implements Runnable {
private ZooKeeper zk;
@Override
public void run() {
try {
// 获取zk连接对象
zk = GlobalEnv.connectZkServer();
// 定义节点信息字符串
String nodeInfo = InetAddress.getLocalHost().toString() + "/8888";
// 创建二级引擎节点
zk.create(GlobalEnv.getEngine2Path(), nodeInfo.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e) {
e.printStackTrace();
}
}
}3、创建OwnEnv类
package net.hw.common;
import rpc.domain.HttpAppHost;
import java.util.Map;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class OwnEnv {
private static BlockingQueue<Map<CharSequence, HttpAppHost>> mapQueue = new LinkedBlockingQueue<Map<CharSequence, HttpAppHost>>();
public static BlockingQueue<Map<CharSequence, HttpAppHost>> getMapQueue() {
return mapQueue;
}
}4、创建ReducerRunner类
package net.hw.reducer;
import net.hw.common.OwnEnv;
import net.hw.db.ZebraDB;
import rpc.domain.HttpAppHost;
import java.util.HashMap;
import java.util.Map;
public class ReducerRunner implements Runnable {
private Map<String, HttpAppHost> resultMap = new HashMap<>();
@Override
public void run() {
while (true) {
// 从二级引擎的map队列中取出要进行归并的map对象(理解为什么要用poll方法)
Map<CharSequence, HttpAppHost> reduceMap = OwnEnv.getMapQueue().poll();
// 如果取完map队列中的元素,说明归并工作完成,跳出循环
if (reduceMap == null) {
System.out.println("二级引擎归并工作完成,跳出循环~");
break;
}
// 对reduceMap对象进行归并操作(遍历reduceMap的entrySet)
for (Map.Entry<CharSequence, HttpAppHost> entry : reduceMap.entrySet()) {
// 获取用户标识
String key = entry.getKey().toString();
// 获取用户对应的业务对象
HttpAppHost hah = entry.getValue();
// 判断resultMap中是否存在该key
if (resultMap.containsKey(key)) {
// 从resultMap中获取该key对应的业务对象
HttpAppHost map = resultMap.get(key);
// 设置map的属性值(累加)
map.setAccepts(map.getAccepts() + hah.getAccepts());
map.setAttempts(map.getAttempts() + hah.getAttempts());
map.setTrafficUL(map.getTrafficUL() + hah.getTrafficUL());
map.setTrafficDL(map.getTrafficDL() + hah.getTrafficDL());
map.setRetranUL(map.getRetranUL() + hah.getRetranUL());
map.setRetranDL(map.getRetranDL() + hah.getRetranDL());
map.setTransDelay(map.getTransDelay() + hah.getTransDelay());
} else {
resultMap.put(key, hah);
}
}
}
// 归并工作完成,提示用户
System.out.println("归并后的map:" + resultMap.size());
// 数据落地,将处理后的map数据保存到数据库
ZebraDB.toDb(resultMap);
}
}5、创建RpcSendHttpAppHostImpl类
package net.hw.rpc;
import net.hw.common.OwnEnv;
import net.hw.reducer.ReducerRunner;
import org.apache.avro.AvroRemoteException;
import rpc.domain.HttpAppHost;
import rpc.service.RpcSendHttpAppHost;
import java.util.Map;
public class RpcSendHttpAppHostImpl implements RpcSendHttpAppHost{
@Override
public Void sendHttpAppHost(HttpAppHost httpAppHost) throws AvroRemoteException {
return null;
}
@Override
public Void sendHttpAppHostMap(Map<CharSequence, HttpAppHost> hahMap) throws AvroRemoteException {
// 提示用户收到一级引擎发送过来的map
System.out.println("二级引擎收到了一级引擎传递过来的map:" + hahMap.size());
// 将收到的map添加到二级引擎的map队列
OwnEnv.getMapQueue().add(hahMap);
/*
* 作业:jobtracker完成一个文件切分之后,创建zk节点/jobtracker,
* 要将切片数量保存到该节点,然后此处从zk节点/jobtracker获取切片数量
*/
int splitNum = 4;
// 当二级引擎接收完所有切片,就启动归并线程
if (OwnEnv.getMapQueue().size() == splitNum) {
new Thread(new ReducerRunner()).start();
}
return null;
}
}6、创建RpcServerRunner
package net.hw.rpc;
import org.apache.avro.ipc.NettyServer;
import org.apache.avro.ipc.specific.SpecificResponder;
import rpc.service.RpcSendHttpAppHost;
import java.net.InetSocketAddress;
public class RpcServerRunner implements Runnable {
@Override
public void run() {
// 创建NettyServer对象
NettyServer server = new NettyServer(new SpecificResponder(RpcSendHttpAppHost.class,
new RpcSendHttpAppHostImpl()), new InetSocketAddress(8888));
}
}7、创建数据库连接池配置文件c3p0-config.xml
<?xml version="1.0" ?>
<c3p0-config>
<default-config>
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql:///zebra</property>
<property name="user">root</property>
<property name="password">root</property>
</default-config>
</c3p0-config>8、创建日志属性文件log4j.properties
log4j.rootLogger = error,D,stdout
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
log4j.appender.D=org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File=logs/log.log
log4j.appender.D.Append=true
log4j.appender.D.Threshold=DEBUG
log4j.appender.D.layout=org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n9、创建ZebraDB类,让二级引擎处理的数据落地到数据库
package net.hw.db;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import rpc.domain.HttpAppHost;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Map;
public class ZebraDB {
private static ComboPooledDataSource source = new ComboPooledDataSource();
public static void toDb(Map<String, HttpAppHost> reduceMap) {
Connection conn = null;
try {
conn = source.getConnection();
conn.setAutoCommit(false);
String sql = "insert into f_http_app_host values (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)";
PreparedStatement ps = conn.prepareStatement(sql);
int i = 0;
for (Map.Entry<String, HttpAppHost> entry : reduceMap.entrySet()) {
HttpAppHost hah = entry.getValue();
String reportTime = hah.getReportTime().toString();
String year = reportTime.substring(0, 4);
String month = reportTime.substring(4, 6);
String day = reportTime.substring(6, 8);
reportTime = year + "-" + month + "-" + day;
ps.setDate(1, java.sql.Date.valueOf(reportTime));
ps.setInt(2, hah.getAppType());
ps.setInt(3, hah.getAppSubtype());
ps.setString(4, hah.getUserIP().toString());
ps.setInt(5, hah.getUserPort());
ps.setString(6, hah.getAppServerIP().toString());
ps.setInt(7, hah.getAppServerPort());
ps.setString(8, hah.getHost().toString());
ps.setString(9, hah.getCellid().toString());
ps.setLong(10, hah.getAttempts());
ps.setLong(11, hah.getAccepts());
ps.setLong(12, hah.getTrafficUL());
ps.setLong(13, hah.getTrafficDL());
ps.setLong(14, hah.getRetranUL());
ps.setLong(15, hah.getRetranDL());
ps.setLong(16, 1l);
ps.setLong(17, hah.getTransDelay());
ps.addBatch();
i++;
if (i % 1000 == 0) {
ps.executeBatch();
ps.clearBatch();
}
}
//防止有残余的信息没有处理
ps.executeBatch();
conn.commit();
} catch (Exception e) {
try {
conn.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
e.printStackTrace();
} finally {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
conn = null;
e.printStackTrace();
} finally {
conn = null;
}
}
}
System.out.println("数据已经全部写到数据库里。");
}
}10、创建StartEngine2类,通过线程池来启动线程
package net.hw.common;
import net.hw.rpc.RpcServerRunner;
import net.hw.zk.ZkConnectRunner;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class StartEngine2 {
public static void main(String[] args) {
// 提示用户
System.out.println("二级引擎已经启动~");
// 创建缓存线程池(大池子,小队列)
ExecutorService es = Executors.newCachedThreadPool();
// 启动连接zk服务器的线程
es.submit(new ZkConnectRunner());
// 启动RPC服务器端线程
es.submit(new RpcServerRunner());
}
}11、创建数据库zebra,导入建表脚本(1)创建zebra数据库
(2)利用建表脚本创建表
/*
Navicat MySQL Data Transfer
Source Server : mysql
Source Server Version : 50544
Source Host : localhost:3306
Source Database : zebra
Target Server Type : MYSQL
Target Server Version : 50544
File Encoding : 65001
Date: 2016-10-25 23:49:02
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for `f_http_app_host`
-- ----------------------------
DROP TABLE IF EXISTS `f_http_app_host`;
CREATE TABLE `f_http_app_host` (
`reporttime` datetime DEFAULT NULL,
`apptype` int(11) DEFAULT NULL,
`appsubtype` int(11) DEFAULT NULL,
`userip` varchar(20) DEFAULT NULL,
`userport` int(11) DEFAULT NULL,
`appserverip` varchar(20) DEFAULT NULL,
`appserverport` int(11) DEFAULT NULL,
`host` varchar(255) DEFAULT NULL,
`cellid` varchar(20) DEFAULT NULL,
`attempts` bigint(20) DEFAULT NULL,
`accepts` bigint(20) DEFAULT NULL,
`trafficul` bigint(20) DEFAULT NULL,
`trafficdl` bigint(20) DEFAULT NULL,
`retranul` bigint(20) DEFAULT NULL,
`retrandl` bigint(20) DEFAULT NULL,
`failcount` bigint(20) DEFAULT NULL,
`transdelay` bigint(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of f_http_app_host
-- ----------------------------新建查询,执行查询:
测试整个zebra项目
1、启动二级引擎StartEngine2
2、启动两个一级引擎StartEngine1_01和StartEngine1_02
3、启动StartJobTracker
4、切换到StartEngine1_01的控制台
一级引擎01节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 3000000, "length": 3000000}一级引擎01节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 9000000, "length": 1901307}map.size=4062map.size=4243
5、切换到StartEngine1_02的控制台
一级引擎02节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 0, "length": 3000000}一级引擎02节点收到jobtracker发送过来的{"path": "D:\\program\\zebra\\data\\103_20150615143630_00_00_000.csv", "start": 6000000, "length": 3000000}map.size=4936map.size=4740
6、切换到StartEngine2的控制台
7、打开数据库zebra,查看是否有17980条记录在表里
九、课后作业jobtracker完成一个文件切分之后,创建zk节点/jobtracker,要将切片数量保存到该节点,然后从zk节点/jobtracker获取切片数量。

相关文章推荐
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
- 联想ERP项目实施案例分析(7):数据切换与模拟上线
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
- Hadoop之网站日志分析项目案例(二)数据清洗(笔记22)
- 联想ERP项目实施案例分析(6):用户培训和数据准备
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
- 大数据技术学习笔记之网站流量日志分析项目:Flume日志采集系统1
- 实习笔记——如何把实验室科研数据分析项目变成能部署到生产环境中的工程
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
- 联想ERP项目实施案例分析(5):系统测试和数据清理
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
- C++ Primer 学习笔记_40_STL实践与分析(14)--概要、先来看看算法【上】
- 用data.DataReader读取股价数据并分析--python学习笔记17
- 统计学方法与数据分析学习笔记1
- 重要的Python库(利用Python进行数据分析笔记)
- 网上图书商城项目学习笔记-025分类管理模块分析及查询所有分类实现
- 分析:ERP实施项目中体系管理部门的角色[转]
- Python数据分析常用函数笔记