基于scrapy框架下爬取智联招聘--并把信息存储下来
2018-03-02 18:00
337 查看
1.在之前爬取的JobSpider中的Terminal终端中,直接创建新的文件
scrapy genspider zlzp baidu.com
2.开始解析数据
1) 先大致规划一下需要几个函数
2) 函数1跳转到函数2使用 yield scrapy.Request(url,callback,meta,dont_filter)# -*- coding: utf-8 -*-
import scrapy
from ..items import JobspiderItem
# 智联招聘信息获取
class ZlzpSpider(scrapy.Spider):
name = 'zlzp'
allowed_domains = ['zhaopin.com']
start_urls = [
'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%E5%8C%97%E4%BA%AC%2B%E4%B8%8A%E6%B5%B7%2B%E5%B9%BF%E5%B7%9E%2B%E6%B7%B1%E5%9C%B3%2B%E6%AD%A6%E6%B1%89&kw=python&p=1&isadv=0',
'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%E5%8C%97%E4%BA%AC%2B%E4%B8%8A%E6%B5%B7%2B%E5%B9%BF%E5%B7%9E%2B%E6%B7%B1%E5%9C%B3%2B%E6%AD%A6%E6%B1%89&kw=php&p=1&isadv=0',
'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%E5%8C%97%E4%BA%AC%2B%E4%B8%8A%E6%B5%B7%2B%E5%B9%BF%E5%B7%9E%2B%E6%B7%B1%E5%9C%B3%2B%E6%AD%A6%E6%B1%89&kw=html&p=1&isadv=0'
]
def parse(self, response):
yield scrapy.Request(
url=response.url,
callback=self.parse_job_info,
meta={},
dont_filter=True,
)
def parse_job_info(self, response):
"""
解析工作信息
:param response:
:return:
"""
zl_table_list = response.xpath("//div[@id='newlist_list_content_table']/table[@class='newlist']")
for zl_table in zl_table_list[1:]:
# tbody 是网页自动生成的 运行起来看效果/或者右键查看源码
# zl_td_list = zl_table.xpath("tr[1]/td")
# 问题:td 数不是5个,会报错--索引越界
# td1 = zl_table_list[0]
# td2 = zl_table_list[1]
# td3 = zl_table_list[2]
# td4 = zl_table_list[3]
# td5 = zl_table_list[4]
# 查找元素尽量用xpath定位,少用索引,因为有可能出现索引越界错误
# 只有在不明确错误时使用异常捕获
# //text()获取标签内所有文本
# extract()把列表里的元素转换成文本,本身还是列表
# extract_first('默认值')把列表里的元素转换成文本并取出第一个,如果取不到,返回默认值
td1 = zl_table.xpath("tr/td[@class='zwmc']/div/a//text()").extract()
# map返回的是一个列表 td1 = list(map(str.strip, td1))
td1 = map(str.strip, td1)
job_name = "".join(td1).replace(",", "/")
# strip()只能清除两端的
fan_kui_lv = zl_table.xpath("tr/td[@class='fk_lv']/span/text()").extract_first('没有反馈率').strip()
job_company_name = zl_table.xpath("tr/td[@class='gsmc']/a[1]/text()").extract_first('没有公司名称').strip()
job_salary = zl_table.xpath("tr/td[@class='zwyx']/text()").extract_first('面议').strip()
job_place = zl_table.xpath("tr/td[@class='gzdd']/text()").extract_first('没有工作地点').strip()
print(job_name, fan_kui_lv, job_company_name, job_salary, job_place)
item = JobspiderItem()
item['job_name'] = job_name
item['job_company_name'] = job_company_name
item['job_place'] = job_place
item['job_salary'] = job_salary
item['job_time'] = "没有时间"
item['job_type'] = "智联招聘"
item['fan_kui_lv'] = fan_kui_lv
yield item
yield scrapy.Request(
url=response.url,
callback=self.parse_next_page,
meta={},
dont_filter=True,
)
def parse_next_page(self, response):
"""
解析下一页
:param response:
:return:
"""
# //div[@class='pagesDown']/ul/li/a[text()='下一页']/@href
next_page = response.xpath(" //a[text()='下一页']/@href").extract_first('没有下一页')
if next_page:
yield scrapy.Request(
url=next_page,
callback=self.parse_job_info,
meta={},
dont_filter=True,
)
3.其他的不用设置,直接利用JobSpider中存在的文件
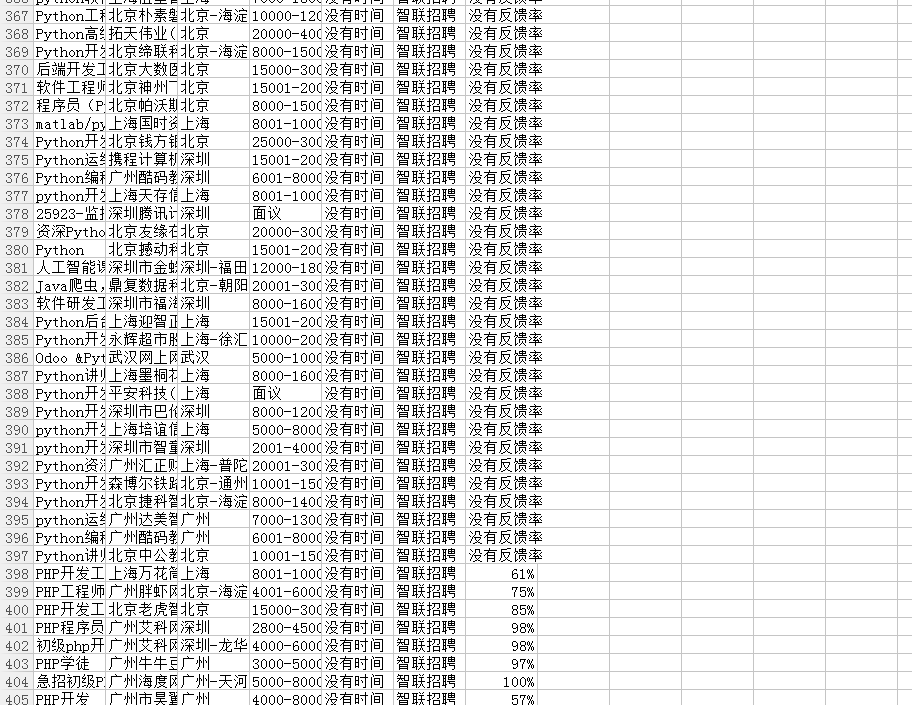
4.运行结果如下:
scrapy genspider zlzp baidu.com
2.开始解析数据
1) 先大致规划一下需要几个函数
2) 函数1跳转到函数2使用 yield scrapy.Request(url,callback,meta,dont_filter)# -*- coding: utf-8 -*-
import scrapy
from ..items import JobspiderItem
# 智联招聘信息获取
class ZlzpSpider(scrapy.Spider):
name = 'zlzp'
allowed_domains = ['zhaopin.com']
start_urls = [
'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%E5%8C%97%E4%BA%AC%2B%E4%B8%8A%E6%B5%B7%2B%E5%B9%BF%E5%B7%9E%2B%E6%B7%B1%E5%9C%B3%2B%E6%AD%A6%E6%B1%89&kw=python&p=1&isadv=0',
'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%E5%8C%97%E4%BA%AC%2B%E4%B8%8A%E6%B5%B7%2B%E5%B9%BF%E5%B7%9E%2B%E6%B7%B1%E5%9C%B3%2B%E6%AD%A6%E6%B1%89&kw=php&p=1&isadv=0',
'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%E5%8C%97%E4%BA%AC%2B%E4%B8%8A%E6%B5%B7%2B%E5%B9%BF%E5%B7%9E%2B%E6%B7%B1%E5%9C%B3%2B%E6%AD%A6%E6%B1%89&kw=html&p=1&isadv=0'
]
def parse(self, response):
yield scrapy.Request(
url=response.url,
callback=self.parse_job_info,
meta={},
dont_filter=True,
)
def parse_job_info(self, response):
"""
解析工作信息
:param response:
:return:
"""
zl_table_list = response.xpath("//div[@id='newlist_list_content_table']/table[@class='newlist']")
for zl_table in zl_table_list[1:]:
# tbody 是网页自动生成的 运行起来看效果/或者右键查看源码
# zl_td_list = zl_table.xpath("tr[1]/td")
# 问题:td 数不是5个,会报错--索引越界
# td1 = zl_table_list[0]
# td2 = zl_table_list[1]
# td3 = zl_table_list[2]
# td4 = zl_table_list[3]
# td5 = zl_table_list[4]
# 查找元素尽量用xpath定位,少用索引,因为有可能出现索引越界错误
# 只有在不明确错误时使用异常捕获
# //text()获取标签内所有文本
# extract()把列表里的元素转换成文本,本身还是列表
# extract_first('默认值')把列表里的元素转换成文本并取出第一个,如果取不到,返回默认值
td1 = zl_table.xpath("tr/td[@class='zwmc']/div/a//text()").extract()
# map返回的是一个列表 td1 = list(map(str.strip, td1))
td1 = map(str.strip, td1)
job_name = "".join(td1).replace(",", "/")
# strip()只能清除两端的
fan_kui_lv = zl_table.xpath("tr/td[@class='fk_lv']/span/text()").extract_first('没有反馈率').strip()
job_company_name = zl_table.xpath("tr/td[@class='gsmc']/a[1]/text()").extract_first('没有公司名称').strip()
job_salary = zl_table.xpath("tr/td[@class='zwyx']/text()").extract_first('面议').strip()
job_place = zl_table.xpath("tr/td[@class='gzdd']/text()").extract_first('没有工作地点').strip()
print(job_name, fan_kui_lv, job_company_name, job_salary, job_place)
item = JobspiderItem()
item['job_name'] = job_name
item['job_company_name'] = job_company_name
item['job_place'] = job_place
item['job_salary'] = job_salary
item['job_time'] = "没有时间"
item['job_type'] = "智联招聘"
item['fan_kui_lv'] = fan_kui_lv
yield item
yield scrapy.Request(
url=response.url,
callback=self.parse_next_page,
meta={},
dont_filter=True,
)
def parse_next_page(self, response):
"""
解析下一页
:param response:
:return:
"""
# //div[@class='pagesDown']/ul/li/a[text()='下一页']/@href
next_page = response.xpath(" //a[text()='下一页']/@href").extract_first('没有下一页')
if next_page:
yield scrapy.Request(
url=next_page,
callback=self.parse_job_info,
meta={},
dont_filter=True,
)
3.其他的不用设置,直接利用JobSpider中存在的文件
4.运行结果如下:

相关文章推荐
- scrapy框架下爬取51job网站信息,并存储到表格中
- scrapy框架下的两个爬虫分工合作爬取智联招聘所有职位信息。
- 关于scrapy爬取51job网以及智联招聘信息存储文件的设置
- 基于Flex和J2EE的信息管理系统基础框架 Pomer
- Scrapy:Python3版本上安装数据挖掘必备的scrapy框架详细攻略(二最完整爬取网页内容信息攻略)——Jason niu
- 一.BeautifulSoup 多进程抓取智联招聘信息,并且存储到mongodb
- Python基于Flask框架配置依赖包信息的项目迁移部署
- 爬虫框架Scrapy实战之批量抓取招聘信息--附源码
- Python爬虫框架Scrapy实战之定向批量获取职位招聘信息
- Scrapy框架结合Spynner采集需进行js,ajax动态加载的网页并提取网页信息(以采集微信公众号文章列表为例)
- 利用Scrapy框架爬取博客信息并存到mysql数据库
- Scrapy框架学习 - 爬取Boss直聘网Python职位信息
- 小项目-数据爬取篇:scrapy框架,手机网页,工作信息存入MongoDB,代理ip中间件
- 基于Struts和hibernate框架的学生信息管理系统
- Python爬虫框架Scrapy实战教程---定向批量获取职位招聘信息
- Scrapy框架结合Spynner采集需进行js,ajax动态加载的网页并提取网页信息(以采集微信公众号文章列表为例)
- 基于python3.5的scrapy框架搭建(二)
- 基于Scrapy框架的python网络爬虫(1)
- Scrapy框架的爬虫代码(封装,存储)和运作爬虫的逻辑分析和注意事项
- 基于Python的scrapy框架的广州天气爬虫源码下载