spark产生背景及特点
2018-03-02 17:44
411 查看
spark的产生背景以其特点
1、产生背景:
MapReduce编程的不便性:
1)繁杂:开发一个作业,既要写Map,又要写Reduce和驱动类。当需求变动要改变大量的代码
2)效率低:MapReduce基于进程,进程的启动和销毁要花费时间。
I/O频繁:网络I/O和磁盘I/O频繁
每个任务都必须排序,但其实有些任务排序是不必要的
3)不适合作迭代处理
4)不适合作实时处理
#spark基于线程,线程直接从线程池中获取即可。
#MapReduce也可以基于内存,但有一定限度。
2、spark概述及特点
Apache Spark is a fast and general engine for large-scale data processing。
Apache Spark 是一个快速的处理大规模数据的通用工具。它是一个基于内存计算框架。
特点:
快速:Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk。
易用:Write applications quickly in Java, Scala, Python, R。Spark offers over 80 high-level operators
that make it easy to build parallel apps. And you can use it interactively from the Scala, Python and R shells
运行范围广:Spark runs on Hadoop, Mesos, Kubernetes, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.
通用:Combine SQL, streaming, and complex analytics。
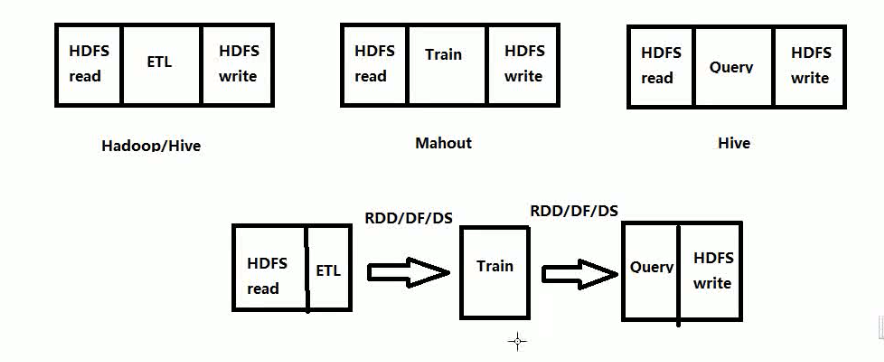
分别用hadoop和spark实现机器学习的框架
#问题1:spark在什么场景比不上MapReduce? http://developer.51cto.com/art/201602/505847.htm http://blog.csdn.net/sunspeedzy/article/details/69062802
#问题2:spark sql和sql的区别?
#spark-1.6.0
1:主版本,主版本的更改往往意味着API的改变
6:次版本,次版本的更改往往意味着新特性的添加,有时也伴随着API的更改
0:末版本,末版本的更改网往往伴随着新特性的添加
注意:我们选择版本往往不建议选择末版本为0的版本,这个版本由于没有对新添加的特性进行bug的修复,会有很多的bug
#spark开发语言变迁(15年to16年)
SQL:36%to44%
java:31%to29%
python:58%to62%
scala:71%to65%
R:18%to20%
#spark源码:github.com/apache/spark/
源码中有很多的例子,这些例子在工作中可以直接用哦
1、产生背景:
MapReduce编程的不便性:
1)繁杂:开发一个作业,既要写Map,又要写Reduce和驱动类。当需求变动要改变大量的代码
2)效率低:MapReduce基于进程,进程的启动和销毁要花费时间。
I/O频繁:网络I/O和磁盘I/O频繁
每个任务都必须排序,但其实有些任务排序是不必要的
3)不适合作迭代处理
4)不适合作实时处理
#spark基于线程,线程直接从线程池中获取即可。
#MapReduce也可以基于内存,但有一定限度。
2、spark概述及特点
Apache Spark is a fast and general engine for large-scale data processing。
Apache Spark 是一个快速的处理大规模数据的通用工具。它是一个基于内存计算框架。
特点:
快速:Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk。
易用:Write applications quickly in Java, Scala, Python, R。Spark offers over 80 high-level operators
that make it easy to build parallel apps. And you can use it interactively from the Scala, Python and R shells
运行范围广:Spark runs on Hadoop, Mesos, Kubernetes, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.
通用:Combine SQL, streaming, and complex analytics。
分别用hadoop和spark实现机器学习的框架
#问题1:spark在什么场景比不上MapReduce? http://developer.51cto.com/art/201602/505847.htm http://blog.csdn.net/sunspeedzy/article/details/69062802
#问题2:spark sql和sql的区别?
#spark-1.6.0
1:主版本,主版本的更改往往意味着API的改变
6:次版本,次版本的更改往往意味着新特性的添加,有时也伴随着API的更改
0:末版本,末版本的更改网往往伴随着新特性的添加
注意:我们选择版本往往不建议选择末版本为0的版本,这个版本由于没有对新添加的特性进行bug的修复,会有很多的bug
#spark开发语言变迁(15年to16年)
SQL:36%to44%
java:31%to29%
python:58%to62%
scala:71%to65%
R:18%to20%
#spark源码:github.com/apache/spark/
源码中有很多的例子,这些例子在工作中可以直接用哦

相关文章推荐
- 第26课:电光石火间从根本上理解Spark中Sort-Based Shuffle产生的内幕及其tungsten-sort 背景解密
- Spark商业案例与性能调优实战100课》第26课:电光石火间从根本上理解Spark中Sort-Based Shuffle产生的内幕及其tungsten-sort 背景解密
- 学习日记:ajax的产生的背景、原理、特点与应用
- 回车符号和换行符号产生背景
- C# 产生验证码 利用背景图片绘制
- Spark 特点
- sqoop产生背景及概述
- 从零开始写《企业IT部门运维辅助web系统》_1.需求产生的背景
- spark的wordcount产生多少个RDD
- static define const inline的产生背景与区别
- RFID生产现场管理解决方案产生背景
- 一、C语言的产生和发展及特点
- Hadoop 产生背景
- Spark特点
- 004 矩阵理论的产生:背景、矩阵问题(矩阵逆阵理论、矩阵秩的理论);矩阵逆阵(定义、存在性、求法)
- 数学归纳法产生的历史背景
- 编译原理的各个阶段及其功能 && clang产生背景
- Hadoop系列之一:大数据存储及处理平台产生的背景
- YARN产生背景