【实例】用cmd 引用 java 生成 conll文件(stanford-corenlp)
2018-03-01 13:32
591 查看
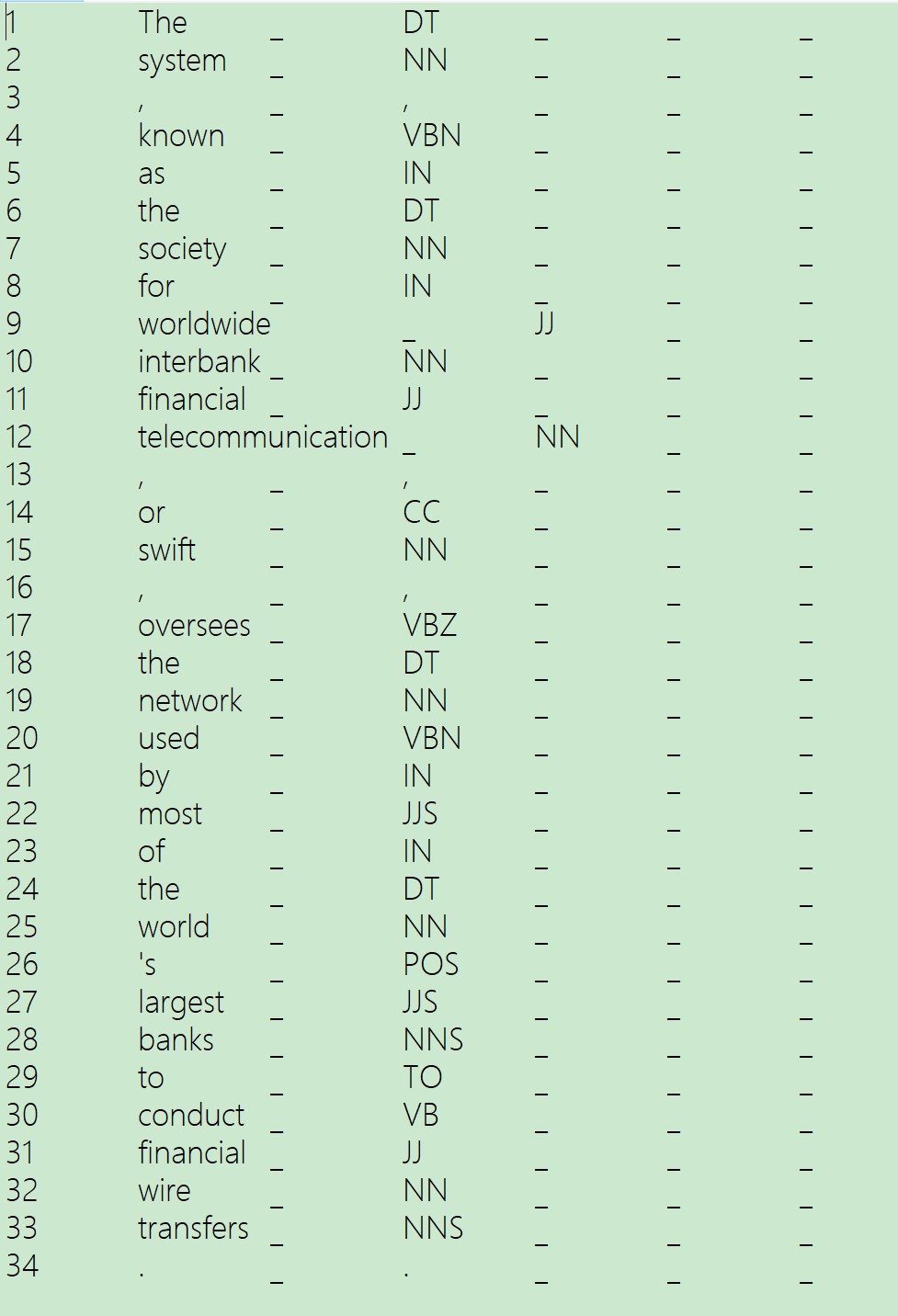
java -cp "*" -Xmx500m edu.stanford.nlp.pipeline.StanfordCoreNLP -annotators tokenize,ssplit,pos -file english.txt -outputFormat conll
-----------------------------------------------------------------------------------
E:\cornlp\stanford-corenlp-full-2018-01-31>java -cp "*" -Xmx500m edu.stanford.nlp.pipeline.StanfordCoreNLP -annotators tokenize,ssplit,pos -file english.txt -outputFormat conll
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator tokenize
[main] INFO edu.stanford.nlp.pipeline.TokenizerAnnotator - No tokenizer type provided. Defaulting to PTBTokenizer.
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator ssplit
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator pos
[main] INFO edu.stanford.nlp.tagger.maxent.MaxentTagger - Loading POS tagger from edu/stanford/nlp/models/pos-tagger/english-left3words/english-left3words-distsim.tagger ... done [2.0 sec].
Processing file E:\cornlp\stanford-corenlp-full-2018-01-31\english.txt ... writing to E:\cornlp\stanford-corenlp-full-2018-01-31\english.txt.conll
Annotating file E:\cornlp\stanford-corenlp-full-2018-01-31\english.txt ... done [0.3 sec].
Annotation pipeline timing information:
TokenizerAnnotator: 0.2 sec.
WordsToSentencesAnnotator: 0.0 sec.
POSTaggerAnnotator: 0.1 sec.
TOTAL: 0.3 sec. for 34 tokens at 133.9 tokens/sec.
Pipeline setup: 2.1 sec.
Total time for StanfordCoreNLP pipeline: 2.5 sec.
------------------------------------------------------------------------------------
--------------------------------------------------------------------
E:\cornlp\stanford-corenlp-full-2018-01-31>java -cp "*" -Xmx500m edu.stanford.nlp.pipeline.StanfordCoreNLP -annotators tokenize,ssplit,pos -encoding utf-8 /file a.txt -outputFormat conll
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator tokenize
[main] INFO edu.stanford.nlp.pipeline.TokenizerAnnotator - No tokenizer type provided. Defaulting to PTBTokenizer.
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator ssplit
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator pos
[main] INFO edu.stanford.nlp.tagger.maxent.MaxentTagger - Loading POS tagger from edu/stanford/nlp/models/pos-tagger/english-left3words/english-left3words-distsim.tagger ... done [2.2 sec].
Entering interactive shell. Type q RETURN or EOF to quit.
NLP> StanfordCoreNLP(r'E:/cornlp/stanford-corenlp-full-2018-01-31/',lang='zh')
1 StanfordCoreNLP _ NN _ _ _
2 -LRB- _ -LRB- _ _ _
3 r _ NN _ _ _
4 ` _ `` _ _ _
5 E _ NN _ _ _
6 : _ : _ _ _
7 / _ : _ _ _
8 cornlp/stanford-corenlp-full _ JJ _ _ _
9 -2018-01-31 _ CD _ _ _
10 / _ : _ _ _
11 ' _ '' _ _ _
12 , _ , _ _ _
13 lang _ NN _ _ _
14 = _ JJ _ _ _
15 ` _ `` _ _ _
16 zh _ NN _ _ _
17 ' _ '' _ _ _
18 -RRB- _ -RRB- _ _ _
NLP>
-----------------------------------------------------------------------------------
E:\cornlp\stanford-corenlp-full-2018-01-31>java -cp "*" -Xmx500m edu.stanford.nlp.pipeline.StanfordCoreNLP -annotators tokenize,ssplit,pos -file english.txt -outputFormat conll
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator tokenize
[main] INFO edu.stanford.nlp.pipeline.TokenizerAnnotator - No tokenizer type provided. Defaulting to PTBTokenizer.
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator ssplit
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator pos
[main] INFO edu.stanford.nlp.tagger.maxent.MaxentTagger - Loading POS tagger from edu/stanford/nlp/models/pos-tagger/english-left3words/english-left3words-distsim.tagger ... done [2.0 sec].
Processing file E:\cornlp\stanford-corenlp-full-2018-01-31\english.txt ... writing to E:\cornlp\stanford-corenlp-full-2018-01-31\english.txt.conll
Annotating file E:\cornlp\stanford-corenlp-full-2018-01-31\english.txt ... done [0.3 sec].
Annotation pipeline timing information:
TokenizerAnnotator: 0.2 sec.
WordsToSentencesAnnotator: 0.0 sec.
POSTaggerAnnotator: 0.1 sec.
TOTAL: 0.3 sec. for 34 tokens at 133.9 tokens/sec.
Pipeline setup: 2.1 sec.
Total time for StanfordCoreNLP pipeline: 2.5 sec.
------------------------------------------------------------------------------------
--------------------------------------------------------------------
E:\cornlp\stanford-corenlp-full-2018-01-31>java -cp "*" -Xmx500m edu.stanford.nlp.pipeline.StanfordCoreNLP -annotators tokenize,ssplit,pos -encoding utf-8 /file a.txt -outputFormat conll
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator tokenize
[main] INFO edu.stanford.nlp.pipeline.TokenizerAnnotator - No tokenizer type provided. Defaulting to PTBTokenizer.
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator ssplit
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator pos
[main] INFO edu.stanford.nlp.tagger.maxent.MaxentTagger - Loading POS tagger from edu/stanford/nlp/models/pos-tagger/english-left3words/english-left3words-distsim.tagger ... done [2.2 sec].
Entering interactive shell. Type q RETURN or EOF to quit.
NLP> StanfordCoreNLP(r'E:/cornlp/stanford-corenlp-full-2018-01-31/',lang='zh')
1 StanfordCoreNLP _ NN _ _ _
2 -LRB- _ -LRB- _ _ _
3 r _ NN _ _ _
4 ` _ `` _ _ _
5 E _ NN _ _ _
6 : _ : _ _ _
7 / _ : _ _ _
8 cornlp/stanford-corenlp-full _ JJ _ _ _
9 -2018-01-31 _ CD _ _ _
10 / _ : _ _ _
11 ' _ '' _ _ _
12 , _ , _ _ _
13 lang _ NN _ _ _
14 = _ JJ _ _ _
15 ` _ `` _ _ _
16 zh _ NN _ _ _
17 ' _ '' _ _ _
18 -RRB- _ -RRB- _ _ _
NLP>

相关文章推荐
- Java生成CSV文件实例详解
- 关于动态生成WML文件的一个Java实例(3)
- Java生成和解析XML格式文件和字符串的实例代码【dom4j中的SAXReader对象读取并解析xml文件】
- Java生成和解析XML格式文件和字符串的实例代码
- Java生成CSV文件实例详解
- 实现poi方式生成excel文件和web类根据路径生成java实例的反射技术的springmvc方法的方法
- Java生成和解析XML格式文件和字符串的实例代码
- Java Web开发实例(三) 3.新建菜单和引用CSS文件
- Java生成压缩文件的实例代码
- java--通过DOM4J方式生成rss文件简单实例
- 关于动态生成WML文件的一个Java实例(1)
- java生成csv文件实例
- Java生成CSV文件实例详解
- Java生成和解析XML格式文件和字符串的实例代码
- java+JNI 生成包头文件与调用实例
- cmd javah 找不到类文件 javac 编译java文件 找不到符号(把class文件生成.h文件)
- POI以SAX方式解析Excel2007大文件(包含空单元格的处理) Java生成CSV文件实例详解
- 使用cmd编译java文件成功生成class,但是不能执行
- Java生成和解析XML格式文件和字符串的实例代码
- Java生成和解析XML格式文件和字符串的实例代码