OpenCV3.3中K-Means聚类接口简介及使用
2018-02-28 09:09
495 查看
OpenCV3.3中给出了K-均值聚类(K-Means)的实现,即接口cv::kmeans,接口的声明在include/opencv2/core.hpp文件中,实现在modules/core/src/kmeans.cpp文件中,其中:
下面对此接口中的参数作个简单说明:
(1)、data:为cv::Mat类型,每行代表一个样本,即特征,即mat.cols=特征长度,mat.rows=样本数,数据类型仅支持float;
(2)、K:指定聚类时划分为几类;
(3)、bestLabels:为cv::Mat类型,是一个长度为(样本数,1)的矩阵,即mat.cols=1,mat.rows=样本数;为K-Means算法的结果输出,指定每一个样本聚类到哪一个label中;
(4)、criteria:TermCriteria类,算法进行迭代时终止的条件,可以指定最大迭代次数,也可以指定预期的精度,也可以这两种同时指定;
(5)、attempts:指定K-Means算法执行的次数,每次算法执行的结果是不一样的,选择最好的那次结果输出;
(6)、flags:初始化均值点的方法,目前支持三种:KMEANS_RANDOM_CENTERS、KMEANS_PP_CENTERS、KMEANS_USE_INITIAL_LABELS;
(7)、centers:为cv::Mat类型,输出最终的均值点,mat.cols=特征长度,mat.rols=K.
一般当attempts和TermCriteria中迭代次数值越大时,聚类效果越好。
关于K-Means聚类的简介可以参考: http://blog.csdn.net/fengbingchun/article/details/79276668
以下是从数据集MNIST中提取的40幅图像,0,1,2,3四类各20张,如下图:

关于MNIST的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/49611549
测试代码如下:#include "opencv.hpp"
#include <string>
#include <vector>
#include <memory>
#include <algorithm>
#include <opencv2/opencv.hpp>
#include <opencv2/ml.hpp>
#include "common.hpp"
///////////////////////////////// K-Means ///////////////////////////////
int test_opencv_kmeans()
{
const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };
cv::Mat tmp = cv::imread(image_path + "0_1.jpg", 0);
CHECK(tmp.data != nullptr && tmp.channels() == 1);
const int samples_number{ 80 }, every_class_number{ 20 }, categories_number{ samples_number / every_class_number};
cv::Mat samples_data(samples_number, tmp.rows * tmp.cols, CV_32FC1);
cv::Mat labels(samples_number, 1, CV_32FC1);
float* p1 = reinterpret_cast<float*>(labels.data);
for (int i = 1; i <= every_class_number; ++i) {
static const std::vector<std::string> digit{ "0_", "1_", "2_", "3_" };
CHECK(digit.size() == categories_number);
static const std::string suffix{ ".jpg" };
for (int j = 0; j < categories_number; ++j) {
std::string image_name = image_path + digit[j] + std::to_string(i) + suffix;
cv::Mat image = cv::imread(image_name, 0);
CHECK(!image.empty() && image.channels() == 1);
image.convertTo(image, CV_32FC1);
image = image.reshape(0, 1);
tmp = samples_data.rowRange((i - 1) * categories_number + j, (i - 1) * categories_number + j + 1);
image.copyTo(tmp);
p1[(i - 1) * categories_number + j] = j;
}
}
const int K{ 4 }, attemps{ 100 };
const cv::TermCriteria term_criteria = cv::TermCriteria(cv::TermCriteria::EPS + cv::TermCriteria::COUNT, 100, 0.01);
cv::Mat labels_, centers_;
double value = cv::kmeans(samples_data, K, labels_, term_criteria, attemps, cv::KMEANS_RANDOM_CENTERS, centers_);
fprintf(stdout, "K = %d, attemps = %d, iter count = %d, compactness measure = %f\n",
K, attemps, term_criteria.maxCount, value);
CHECK(labels_.rows == samples_number);
int* p2 = reinterpret_cast<int*>(labels_.data);
for (int i = 1; i <= every_class_number; ++i) {
for (int j = 0; j < categories_number; ++j) {
fprintf(stdout, " %d ", *p2++);
}
fprintf(stdout, "\n");
}
return 0;
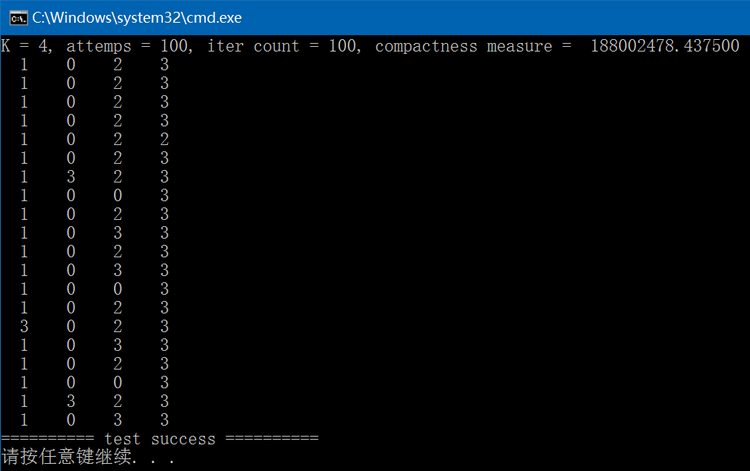
} 执行结果如下:下图中每一列表示期望是同一个label。
GitHub: https://github.com/fengbingchun/NN_Test
下面对此接口中的参数作个简单说明:
(1)、data:为cv::Mat类型,每行代表一个样本,即特征,即mat.cols=特征长度,mat.rows=样本数,数据类型仅支持float;
(2)、K:指定聚类时划分为几类;
(3)、bestLabels:为cv::Mat类型,是一个长度为(样本数,1)的矩阵,即mat.cols=1,mat.rows=样本数;为K-Means算法的结果输出,指定每一个样本聚类到哪一个label中;
(4)、criteria:TermCriteria类,算法进行迭代时终止的条件,可以指定最大迭代次数,也可以指定预期的精度,也可以这两种同时指定;
(5)、attempts:指定K-Means算法执行的次数,每次算法执行的结果是不一样的,选择最好的那次结果输出;
(6)、flags:初始化均值点的方法,目前支持三种:KMEANS_RANDOM_CENTERS、KMEANS_PP_CENTERS、KMEANS_USE_INITIAL_LABELS;
(7)、centers:为cv::Mat类型,输出最终的均值点,mat.cols=特征长度,mat.rols=K.
一般当attempts和TermCriteria中迭代次数值越大时,聚类效果越好。
关于K-Means聚类的简介可以参考: http://blog.csdn.net/fengbingchun/article/details/79276668
以下是从数据集MNIST中提取的40幅图像,0,1,2,3四类各20张,如下图:
关于MNIST的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/49611549
测试代码如下:#include "opencv.hpp"
#include <string>
#include <vector>
#include <memory>
#include <algorithm>
#include <opencv2/opencv.hpp>
#include <opencv2/ml.hpp>
#include "common.hpp"
///////////////////////////////// K-Means ///////////////////////////////
int test_opencv_kmeans()
{
const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };
cv::Mat tmp = cv::imread(image_path + "0_1.jpg", 0);
CHECK(tmp.data != nullptr && tmp.channels() == 1);
const int samples_number{ 80 }, every_class_number{ 20 }, categories_number{ samples_number / every_class_number};
cv::Mat samples_data(samples_number, tmp.rows * tmp.cols, CV_32FC1);
cv::Mat labels(samples_number, 1, CV_32FC1);
float* p1 = reinterpret_cast<float*>(labels.data);
for (int i = 1; i <= every_class_number; ++i) {
static const std::vector<std::string> digit{ "0_", "1_", "2_", "3_" };
CHECK(digit.size() == categories_number);
static const std::string suffix{ ".jpg" };
for (int j = 0; j < categories_number; ++j) {
std::string image_name = image_path + digit[j] + std::to_string(i) + suffix;
cv::Mat image = cv::imread(image_name, 0);
CHECK(!image.empty() && image.channels() == 1);
image.convertTo(image, CV_32FC1);
image = image.reshape(0, 1);
tmp = samples_data.rowRange((i - 1) * categories_number + j, (i - 1) * categories_number + j + 1);
image.copyTo(tmp);
p1[(i - 1) * categories_number + j] = j;
}
}
const int K{ 4 }, attemps{ 100 };
const cv::TermCriteria term_criteria = cv::TermCriteria(cv::TermCriteria::EPS + cv::TermCriteria::COUNT, 100, 0.01);
cv::Mat labels_, centers_;
double value = cv::kmeans(samples_data, K, labels_, term_criteria, attemps, cv::KMEANS_RANDOM_CENTERS, centers_);
fprintf(stdout, "K = %d, attemps = %d, iter count = %d, compactness measure = %f\n",
K, attemps, term_criteria.maxCount, value);
CHECK(labels_.rows == samples_number);
int* p2 = reinterpret_cast<int*>(labels_.data);
for (int i = 1; i <= every_class_number; ++i) {
for (int j = 0; j < categories_number; ++j) {
fprintf(stdout, " %d ", *p2++);
}
fprintf(stdout, "\n");
}
return 0;
} 执行结果如下:下图中每一列表示期望是同一个label。
GitHub: https://github.com/fengbingchun/NN_Test

相关文章推荐
- OpenCV3.3中 K-最近邻法(KNN)接口简介及使用
- OpenCV3.3中决策树(Decision Tree)接口简介及使用
- 使用scipy进行层次聚类和k-means聚类
- 使用Orange进行数据挖掘之聚类分析(2)------K-means
- OpenCV3.3中支持向量机(Support Vector Machines, SVM)实现简介及使用
- 使用 Spark MLlib 做 K-means 聚类分析
- 使用 Spark MLlib 做 K-means 聚类分析
- skfuzzy.cmeans与sklearn.KMeans聚类效果对比以及使用方法
- CGI简介(Peercast使用的动态网页编程接口)
- Android SDK 百度地图通过poi城市内检索简介接口的使用
- OpenCV3.3中主成分分析(Principal Components Analysis, PCA)接口简介及使用
- MATLAB K-means聚类的介绍与使用
- Jsoncpp编程接口及使用方法简介
- 使用canopy生成和k-means聚类对新闻进行聚类
- PHP接口简介及使用
- soapUI工具使用方法、简介、接口测试
- Postman Postman接口测试工具使用简介
- 使用DeepLearning4J进行K-Means聚类
- 使用 Spark MLlib 做 K-means 聚类分析
- Spark 实战,第 4 部分: 使用 Spark MLlib 做 K-means 聚类分析